MySQL炒雞詳細常用語法語句
2020-10-25 15:01:06
MySQL經典語法炒雞詳細
MySQL引言
引言:為了學習方便,本文章搭配資料庫檔案學習,方便學習者結合例子進行深入的掌握,更加深刻印象
連結:https://pan.baidu.com/s/1dQfXgCiyC2fs2MV9iXutjg
提取碼:20c5
1.登入MySQL資料庫
mysql -u root -p
1.1 exit; //退出關閉資料庫
一、資料庫操作相關
2.查詢所有資料庫
show databases;
3.建立資料庫
create database 資料庫名;
4.檢視資料庫的字元集
show create database 資料庫名;
5.建立資料庫且給定字元集
create database 資料庫名 character set utf8/gbk;
6.刪除資料庫
drop database 資料庫名;
7.使用某一個資料庫
use 資料庫名;
8.資料庫匯入匯出
匯入:source e:/MySQL/lianxi/tables.sql (匯入資料庫前先建立個資料庫,再use,進行匯入這個資料庫)
匯出:mysqldump -u root -p 資料庫名 表名 > C:\path\path\dump.sql ----路徑
Windows 的斜杆是 \ ,Linux 的斜杆是 /
二、表相關
8.建立資料表(先use 資料庫名,再新增資料表)
create table 資料表名(欄位名 型別,欄位名 型別);
9.查詢當前資料表
show create table 資料表名;
10.建立資料表並且給定表引擎和字元集
create table 資料表名(欄位名 型別) engine=myisam/innodb charset=utf8/gbk;
11.檢視資料表所有欄位
desc 資料表名
12.刪除資料表
drop table 資料表名;
13.檢視當前資料庫的所有資料表(先use 資料庫名,再檢視)
show tables;
13.1清空資料表所有資料 (刪除表並創新表 自增數值清零)
truncate table 資料表名;
14.修改資料表名
rename table 資料表原名 to 新資料表名;
15.修改資料表的表引擎和字元集
alter table 資料表名 engine=myisam/innodb charset=utf8/gbk;
修改當前資料庫字元集(先use 當前資料庫)
alter database 資料庫名 character set 'utf8';
16.資料表新增欄位
16-1.alter table 表名 add 欄位名 資料型別; //資料表欄位末尾新增
16-2.alter table 表名 add 欄位名 資料型別 first; //資料表字元首位新增
16-3.alter table 表名 add 欄位名 資料型別 after 欄位名; //資料表某欄位後面新增
17.刪除表欄位
alter table 表名 drop 欄位名;
18.修改欄位名和型別
alter table 表名 change 原名 新名 新型別;
19.修改欄位型別和位置
alter table 表名 modify 欄位名 新型別 first/after xxx;
三、資料相關
20.全表插入資料
insert into 表名 values (值1,值2);
21.指定欄位格式
insert into 表名 (欄位1,欄位2) values(值1,值2);
批次插入
21-1:insert into 表名 values (值1,值2,值3),(值1,值2,值3),(值1,值2,值3),(值1,值2,值3);
insert into 表名 (欄位1,欄位2) values(值1,值2),(值1,值2),(值1,值2);
22.查詢資料表的資料(先use 資料庫名,再檢視)
select 欄位 from 表名;
select 欄位1,欄位2 from 表名;
select * from 表名 where 條件;
22_1. is null 和 is not null, 查詢為空(null),和不為空的。
select ename from emp where mgr is not null;//查詢所有名字,且mgr不能為null的資料表emp
22_2. 加別名
select ename as '姓名',sal as '工資' from emp;
select ename '姓名',sal '工資' from emp;
select ename 姓名,sal 工資 from emp;
22_3. 去重複 distinct
select distinct job from emp;
22_4. 比較運運算元
> < = >= <= !=和<>
注:資料量大時,加\G就行了。
22_5.
1.and,&& 需要同時滿足多個條件時使用
2.or,|| 需要滿足多個條件中某一個條件時使用
多個or用in ,例子:select sal,comm from emp where ename in('james','king','ford');
in ,not in
3.between x and y (包括xy)
例子:select * from emp where sal>=1000 and sal<=2000;
select * from emp where sal between 1000 and 2000;
4.模糊語句
like , not like _ 表示單個未知, % 表示0個或多個未知
SELECT 欄位 FROM 表 WHERE 某欄位 Like '條件'
4.1 [ ] :表示括號內所列字元中的一個(類似正規表示式)。指定一個字元、字串或範圍,要求所匹配物件為它們中的任一個
比如 SELECT * FROM [user] WHERE u_name LIKE '[張李王]三'
將找出「張三」、「李三」、「王三」(而不是「張李王三」);
如 [ ] 內有一系列字元(01234、abcde之類的)則可略寫為「0-4」、「a-e」
SELECT * FROM [user] WHERE u_name LIKE '老[1-9]'
將找出「老1」、「老2」、……、「老9」;
4.2 [^ ] :表示不在括號所列之內的單個字元。其取值和 [] 相同,但它要求所匹配物件為指定字元以外的任一個字元。
比如 SELECT * FROM [user] WHERE u_name LIKE '[^張李王]三'
將找出不姓「張」、「李」、「王」的「趙三」、「孫三」等;
22_6. 排序
order by 欄位名 asc/desc; ----asc升序,desc降序
例子:查詢所有員工資訊按照部門編號升序排序,工資降序。
SELECT * FROM emp ORDER BY deptno,sal DESC;
22_7. 分頁查詢
limit 跳過的條數,請求的條數(每頁的條數)
例子:1.查詢員工表工資最高的前五條資料
select * from emp order by sal desc limit 0,5;
第二頁資料
select * from emp order by sal desc limit 5,5;
limit (頁數-1)*每條的條數,每頁的條數
22_8.concat()函數 -----可以將字串進行拼接
1.1例子:
查詢商品表,顯示商品名稱,單價(價格:xx元)
select title,concat('價格:',price,'元') from t_item;
22_9.計算 + - * / %,mod()
2.1例子:
查詢員工的姓名,工資,年終獎(年終獎=工資*5)
select ename,sal,sal*5 年終獎 from emp;
22_10.日期相關函數
1.獲取系統當前日期+時間
select now();
2.獲取當前年月日 和 時分秒
select curdate(),curtime();
3.從完整的年月日時分秒中 提取年月日 和 提取時分秒
select date(now());
select time(now());
4.從完整的年月日時分秒中提取時間分量 extract
select extract(year/month/day/hour/minute/second from now());
5.日期格式化 date_format()
date_format(時間,格式);
%Y 四位年 %y 兩位年 %m 兩位月 %c 一位月 %d 日
%H 24小時 %h 12小時 %i 分 %s 秒
例子:把預設的時間格式轉為 年月日時分秒
select date_format(now(),'%Y年%m月%d日 %H時%i分%s秒');
6.把非標準時間格式轉出標準格式 str_to_date();
str_to_date(字串時間,格式);
select str_to_date('14.08.2019 08:00:00','%d.%m.%Y %H:%i:%s');
22_11.分組查詢
1.group by 欄位名,欄位名 ----(要對誰進行分組就寫誰的欄位名)
1-1例子:
1.查詢emp表中每個部門的編號,人數,工資總和,最後根據部門分組且根據人數進行升序排列,如果人數一致,根據工資總和降序排列。
select deptno,count(*),sum(sal) from emp group by deptno order by count(*),sum(sal) desc;
加別名:select deptno,count(*) c ,sum(sal) s from emp group by deptno order by c,s desc;
2.查詢工資在1000~3000之間的員工資訊,每個部門的編號,平均工資,最低工資,最高工資,根據平均工資進行升序排列。
select deptno,avg(sal),min(sal),max(sal) from emp where sal between 1000 and 3000 group by deptno order by avg(sal);
3.查詢含有上級領導的員工,每個職業的人數,工資的總和,平均工資,最低工資,最後根據人數進行降序排序,如果人數一致,根據平均工資進行升序排序。
select job,count(*) c,sum(sal),avg(sal) a,min(sal) from emp where mgr is not null group by job order by c desc,a;
4.查詢每個部門每個主管的手下人數。
select deptno,mgr,count(*) from emp where mgr is not null group by deptno,mgr;
5.查詢每個部門的平均工資,要平均工資大於2000。
select deptno,avg(sal) a from emp group by deptno having a>2000;
(having後面可以寫普通字元條件,但是不建議這麼做,having一般要和分組查詢結合使用,後面寫聚合函數的條件,having寫在分組查詢的後面)
6.查詢每個分類category_id的平均單價,要求平均單價低於100
select category_id,avg(price) a from t_item group by category_id having a<100;
7.查詢分類category_id為238和917的平均單價
select category_id,avg(price) a from t_item where category_id in(238,917) group by category_id;
8.查詢emp表中每個部門的平均工資高於2000的部門變你好,部門人數,平均工資,最後根據平均工資降序排序
select deptno,avg(sal),count(*) a from emp group by deptno having a>2000 order by a desc;
9.查詢emp表中工資1000~3000之間的員工,每個部門的編號,工資總和,平均工資,過濾掉平均工資低於2000的部門,按照平均工資進行升序排序
select deptno,sum(sal),avg(sal) a from emp where sal between 1000 and 3000 group by deptno having a>=2000 order by a;
10.查詢emp表中職位不是以s開頭,每個職位的名字,人數,工資總和,最後工作,過濾掉平均工資3000的職位,根據人數升序排序,如果人數一致則工資總和降序排序。
select ename,count(*) c,sum(sal) s,max(sal) a from emp where job not like 'S%' group by job having avg(sal)!=3000 order by c,s desc;
11.查詢emp表中每年入職的人數
SELECT EXTRACT(YEAR FROM HIREdate) YEAR,COUNT(*) FROM emp GROUP BY YEAR;
12.查詢每個部門的最高平均工資
select deptno,avg(sal) a from emp group by deptno order by a desc limit 0,1;
22_12.子巢狀語句
1.1例子:
1.查詢emp中工資最高的員工資訊
select * from emp where sal=(select max(sal) from emp);
2.查詢emp表中工資大於平均工資的所有員工的資訊
select * from emp where sal>(select avg(sal) from emp);
3.查詢工資高於20號部門的最高工資的員工資訊。
select * from emp where sal>(select max(sal) from emp where deptno=20);
4.查詢和Jones相同工作(job)的其他員工資訊
select * from emp where job=(select job from emp where ename='jones') and ename!='jones';
5.查詢工資最低的員工的同事們的資訊(同事=相同job,即:相同工作的員工資訊)
select min(sal) from emp
select job form emp where sal=(select min(sal) from emp)
select * from emp where job=(select job from emp where sal=(select min(sal) from emp)) and sal!=(select min(sal) from emp);
6.查詢最後入職的員工資訊
select max(hiredate) from emp;
select * from emp where hiredate=(select max(hiredate) from emp);
7.查詢名字為King的部門編號和部門名稱
select deptno,dname from dept where deptno=(select deptno from emp where ename='King');
8.查詢有員工的部門資訊
select distinct deptno from emp;
select * from dept where deptno in(select distinct deptno from emp);
9.查詢平均工資最高的部門資訊
9.1先找到最高平均工資
select avg(sal) a from emp group by deptno order by a desc limit 0,1;
9.2通過最高平均工資得到部門編號
select deptno from emp group by deptno having avg(sal)=(select avg(sal) a from emp group by deptno order by a desc limit 0,1);
9.3通過部門編號得到部門資訊
select * from dept where deptno in(select deptno from emp group by deptno having avg(sal)=(select avg(sal) a from emp group by deptno order by a desc limit 0,1));
22_13.子查詢建立表
1.例子:
1.1:create table emp_10 as (select * from emp where deptno=10); -----把查詢到的資料存到一個新建立的資料表
22_14.子查詢虛擬表(當成虛擬包必須有別名)
1.例子:
1.1:select ename from (select * from emp where deptno=10) newtable;
22_15.關聯查詢:等值連線和內連線,外連線(同時查詢多張表的資料的查詢方式)
1.等值連線
格式:select * from A,B where A.x=B.x and A.age=10;
1.1例子:
1.查詢每個員工的姓名和所屬部門的名字
select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno;
2.查詢部門地點在new york的 部門名稱以及該部門下所有的員工姓名
select d.dname,e.ename from emp e,dept d where e.deptno=d.deptno and d.loc='new york';
2.內連線
格式:select * from A join B on A.x=B.x where A.age=10;
2.1例子:
select e.ename,d.dname from emp e join dept d on e.deptno=d.deptno;
3.外連線(左外,右外)
格式:select * from A left/right join B on A.x=B.x where A.age=18;
3.1例子:查詢所有的部門名稱和對應的員工姓名(外連線)
select d.dname,e.ename
from emp e right join dept d on e.deptno=d.deptno;
總結:如果查詢的資料時兩張表的交集資料
22_16.組連線 group_concat
1).例子一:查詢每個部門的員工姓名和對應的工資,要求一個部門的資訊顯示到一行
select deptno,group_concat(ename,':',sal) from emp group by deptno;
2).例子二:
create table student(id int primary key auto_increment, name varchar(10),subject varchar(10),score varchar(10));
insert into student values(null,'張三','語文','66'),(null,'張三','數學','77'),(null,'張三','英語','55'),(null,'張三','計算機','81'),(null,'李四','語文','59'),(null,'李四','數學','88'),(null,'李四','英語','78'),(null,'張三','計算機','95'),(null,'王虎','語文','75'),(null,'王虎','數學','54'),(null,'王虎','英語','89'),(null,'王虎','計算機','75');
-- 查詢每個人的平均分,從大到小排序
select name '姓名',avg(score)'平均分' from student group by name order by '平均分';
-- 每個人的名字,科目,成績 一行顯示出來
select name,group_concat(subject,':',score) 各科成績 from student group by `name`;
-- 查詢每個人的最高分和最低分
select name,max(score)最高分,min(score)最低分 from student group by name;
-- 查詢每個人不及格的科目以及分數,不及格的科目數量
select name 姓名,group_concat(subject,':',score)不及格科目,count(*)門數 from student where score<60 group by name;
23.修改資料
update 表名 set 欄位名=值 where 條件;
例子:update person set name='bbb' where name='xxx';
24.刪除資料
delete from 表名 where 條件;
25.解決中文欄位出現亂碼
set 欄位名(中文varchar) gbk;
四、約束
1.主鍵約束
主鍵:用於表示資料唯一性的欄位稱為主鍵。-----create table t1(id int primary key,name varchar(10));
約束:就是建立表的時候給欄位新增的限制條件
2.主鍵約束:插入資料必須是唯一且非空的
create table t1(id int primary key,name varchar(10));
insert into t1 values(1,'劉備');
insert into t1 values(1,'劉備’); //報錯 不能重複
insert into t1 values(null,'劉備'); //報錯 不能為null
3.刪除主鍵(若有自增auto_increment,先刪除自增auto_increment,再刪除主鍵)
alter table 表名 change 欄位 欄位 型別;
alter table 表名 drop primary key;
新增主鍵(在新增主鍵之前,必須先把重複的id刪除掉。)
alter table 表名 add primary key(欄位);
alter table 表名 modify 欄位 型別 auto_increment primary key; ------修改欄位為自增,並設定為主鍵
4.非空約束:
欄位的值不能為null
create table 表名 (id int, name varchar(10)not null);
5.唯一約束 unique
欄位的值不能重複
create table 表名 (id int, age int unique);
6.預設約束 default
給欄位設定預設值
create table 表名 (id int, age int default 20);
insert into 表名 values(1,10);
insert into 表名 (id) values(2); --------預設值生效
7.外來鍵約束
外來鍵:用於建立關係的欄位
外來鍵約束:為了保證兩張表之間建立正確的關係,外來鍵欄位的值可以為null,可以重複,
不能是另外一張表中不存在的資料,建立好關係後被依賴的資料不能先刪除,
被依賴的表不能先刪除。
格式:constraint 約束名稱 foreign key(外來鍵欄位名) references 被依賴的表名(被依賴的欄位名);
五、主鍵約束+自增
自增數只增不減
從歷史最大值基礎上+1
1.create table t2(id int primary key auto_increment,name varchar(10));
insert into t2 values(null,'豬八戒');//1
insert into t2 values(null,'豬八戒');//2
insert into t2 values(10,'豬八戒');//10
insert into t2 values(null,'豬八戒');//11
六、註釋
create table t3(id int primary key auto_increment comment '主鍵欄位',name varchar(10) comment '這是姓名');
七、事務
事務是資料庫中執行同一業務多條sql語句的工作單位,可以保證多條SQL語句全部執行成功或者全部執行失敗,不會出現部分成功部分失敗的執行。
事務相關指令:
1.開始事務 begin;
2.提交事務 commit;
3.回滾事務 rollback;
4.儲存回滾點 savepoint;
八、資料庫資料型別
1.整數型
int(m) ----m表示顯示長度,需要結合zerofill關鍵字使用。
bigint(m) ----- create table t_int(id int(5) zerofill);
insert into t_int values(18);
2.浮點數
double(m,d) ---m代表總長度 ---d代表小數長度 25.321 m=5 d=3
decimal超高度精度浮點數,當涉及超高精度運算時使用
3.字串
char(m) 固定長度 執行效率高 最大長度255
varchar(m)可變長度 節省資源 最大65535 超高255位建議使用text, text可變長度 最大65535
4.日期
date 只能儲存年月日
time只能儲存時分秒
datetime最大值9999-12-31 預設值為null
timestamp 最大值2038-1-19 預設值 當前系統時間
九、資料庫匯入匯出
匯入:source e:/MySQL/data/tables.sql -----------(windows系統)
## 十、IFNULL() 函數 10.1. IFNULL() 函數用於判斷第一個表示式是否為 NULL, 如果為 NULL 則返回第二個引數的值,如果不為 NULL 則返回第一個引數的值。
ifnull();
age = ifnull(x,y); 如果x值為null則age=y 如果x不為null則age=x
例子:把emp資料表中的獎金為null的改為0
update emp set comm = ifnull(comm,0);
十一、聚合函數(不能寫在where條件後面)
求和 平均數 最大值 最小值 計數
1.求和:sum
sum(求和的欄位)
2.平均值:avg
avg(欄位)
3.最大值:max
max(欄位)
4.最小值:min
min(欄位)
5.計數:count
count(欄位)
一般寫count(*),只有涉及null值時才使用欄位名
十二、字串相關函數(從1開始)
1.char_length(str)獲取字串的長度
select ename,char_length(ename) from emp;
2.instr(str,substr) 獲取substr在str中出現的位置 從1開始
select instr('abcdefg','d');
3.insert(str,start,length,newstr); 插入
select insert('abcdefg',3,2,'m');
4.lower(str) upper(str) 轉小寫 轉大寫
select lower('NBa'),upper('NBa');
5.trim(str) 去兩端空白
select trim(' a b ');
6.left(str,index) 從左邊擷取
7.right(str,index) 從右邊擷取
8.substring(str,index,?length) 從指定位置擷取
select left('abcdef',2);
select right('abcdef',2);
select substring('abcdef',3,2);
select substring('abcdef',3);
9.repeat(str,count) 重複
select repeat('ab',3); //ababab
10.replace(str,old,new) 替換
select replace('This is mysql','my','your'); //This is yoursql
11.reverse() 反轉
select reverse('abc'); //cba
十三、數學相關的函數
1.floor(num) 向下取整
select floor(3.84); //3
2.round(num) 四捨五入
select round(3.8); //4
3.round(num,m) 四捨五入並保留幾位小數 (m代表保留幾位小數)
select round(3.8679,2); //3.87
4.truncate(num,m) 非四捨五入並保留幾位小數 (m代表保留幾位小數)
select truncate(3.8679,2); //3.86
5.rand() 亂數0~1
例子1:獲取0~5的隨機整數
select floor(rand()*6);
例子2:獲取0~10的隨機整數
select floor(rand()*11);
十四、分類
1.DDL資料定義語言: create drop alter truncate 不支援事務
2.DML資料操作語言: insert delete update select 支援事務
3.DQL資料查詢語言: select
4.TCL事務控制語言: begin commit rollbakc savepoint
5.DCL資料控制語言: 分配使用者許可權相關SQL
十五、檢視
一、試圖和表都是資料庫中的物件,檢視可以理解為一張虛擬的表,檢視本質就是取代了一段SQL查詢語句。
作用:可以起到SQL語句重用的作用,提高開發效率,還可以隱藏敏感資訊。
1.建立檢視
create view 檢視名 as (子查詢);
2.刪除檢視
drop view 檢視名
3.修改檢視
create or replace view 檢視名 as (子查詢);
4.檢視別名
如果建立檢視的子查詢中使用了別名,那麼對檢視進行操作時只會使用別名
3.例子:
create view v_emp_30 as (select ename name,sal from emp where deptno=30);
二、檢視的分類:
1.簡單檢視:建立檢視時的子查詢不包含:去重、函數、分組、關聯查詢建立的檢視稱為簡單檢視,可以對簡單檢視進行增刪改查操作
2.複雜檢視:和簡單檢視相反,只能對複雜檢視進行查詢操作。
三、資料汙染:往檢視中插入一條檢視中不可見但是在原表中可見的資料稱為資料汙染
通過with check option 關鍵字避免出現資料汙染現象。
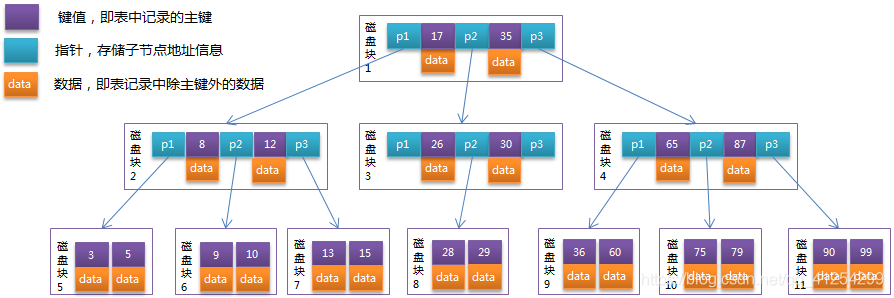
十六、索引
一、索引是資料庫中用於提高查詢效率的技術,工作原理類似目錄
有利也有弊,如果資料量比較小,有索引反而會降低查詢效率
1.建立索引
格式:create index 資料庫名 on 表名(欄位名(?欄位長度));
create index i_item_title on item2(title);
select * from item2 where title='100';
索引越多,不好,因為索引會佔磁碟空間。
2.檢視索引
格式:show index from 表名;
show index from item2;
3.刪除索引
格式:drop index 索引名 on 表名;
drop index i_item_title on item2;
4.複合索引
通過多個欄位建立的索引稱為複合索引
create index i_item_title_price on item2(title,price);
十七、事務
一、資料庫中執行同一業務多條sql語句的工作單元,可以保證多條sql全部執行成功或全部執行失敗
1)事務的ACID特性,此特性是保證事務正確執行的四大基本元素
Atomicity: 原子性:最小不可拆分,保證全部成功或全部失敗
Consistency: 一致性:從一個一致性狀態到另外一個一致性狀態
Isolation: 隔離性:多個事務之間互不影響
Durability: 永續性:提交事務後資料持久儲存在磁碟中
2)事務相關指令:
1.開始事務 begin;
2.提交事務 commit;
3.回滾事務 rollback;
4.儲存回滾點 savepoint;