Redis快取穿透和快取雪崩的分析與解決方案
2020-10-29 11:00:51
一般情況下快取和DB存取的關係
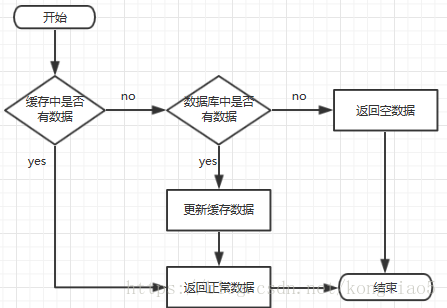
快取穿透
指查詢一個一定不存在的資料,由於快取中沒有該查詢物件(快取始終無法命中對應的資料),這時會去資料庫查詢資料,如果資料庫中也沒有對應的資料也無法寫入快取,在這種情況下,每一次查詢不存在資料的請求都將去查詢資料庫,這就是快取穿透。
造成影響:
當在高並行的情況下,快取穿透可能會拖慢資料庫,進而拖慢整個系統,甚至宕機。
解決辦法:
當在快取中無法命中對應資料時,且存取資料庫也沒有查詢到目標資料,這時向快取中存入空結果。這樣的情況下,每一次查詢首先判斷redis中是否有目標資料(即exist(String key)),key存在就直接返回快取結果,即使快取結果是空值。
快取雪崩
當大量快取在同一時間段內失效的時候,會在這段時間內引發大量資料庫存取查詢,給資料庫帶來較大的壓力。
解決辦法:
- 在資料庫存取層面,加鎖/佇列式的穿行存取
- 分析系統快取實際情況(包括使用者使用場景等),設計分佈較為均勻的失效時間。
- 資料預熱,在能遇見的並行高峰來臨前,提前均勻的、有計劃的更新快取資料,防止在並行高峰期出現快取大量失效的情況。
- 設定業務熱點資料永不過期,只做快取更新操作
- 在分散式資料庫的情況下,將熱點資料均勻分佈,分散快取雪崩後帶來的單個資料庫存取壓力
- 存取限流(最不推薦)
這裡比較推薦通過使用 2 、3 、4 方法來預防解決快取雪崩問題,加鎖或者是佇列式的存取控制,一定會帶來效能的損耗,能提前避免的問題就儘量提前避免,最好不要等到意外發生了再做補救。
合理加鎖
雙重檢測鎖:
public User selectById(String id) {
User user = (User) hash.get(id);
if (null == user) {
synchronized (this) {
//這裡多一次快取的檢查是關鍵
user = (User) hash.get(id);
if (null == user) {
user = //...查詢資料庫
hash.put("user", user);
}
}
}
return user;
}優點:當高並行,且快取過期,又沒有做熱點資料預熱的條件下,第一個執行緒訪獲得了鎖物件,其他執行緒處於等待;在第一個執行緒查詢資料庫的時間內,大量執行緒擠壓,當第一個執行緒的DB查詢結果設定快取後,其他擠壓等待獲得鎖物件的執行緒依次拿到了鎖,這時最關鍵的一步來了,再一次的檢查快取可以避免擠壓的這些執行緒去做不必要的資料庫存取。