【導讀】和AI進行無障礙的對話,是什麼樣的體驗?你或許能夠在這篇文章裡找到答案!百度全新發布PLATO-XL,引數達到了110億,超過之前最大的對話模型 Blender,是當前最大規模的中英文對話生成模型,並再次重新整理了開放域對話效果。
很難相信,以上是AI與人交流的真實對話記錄。近日,百度釋出新一代對話生成模型 PLATO-XL,一舉超過Facebook Blender、谷歌Meena和微軟DialoGPT,成為全球首個百億引數中英文對話預訓練模型,再次重新整理了開放域對話效果,開啟了對話模型的想象空間。
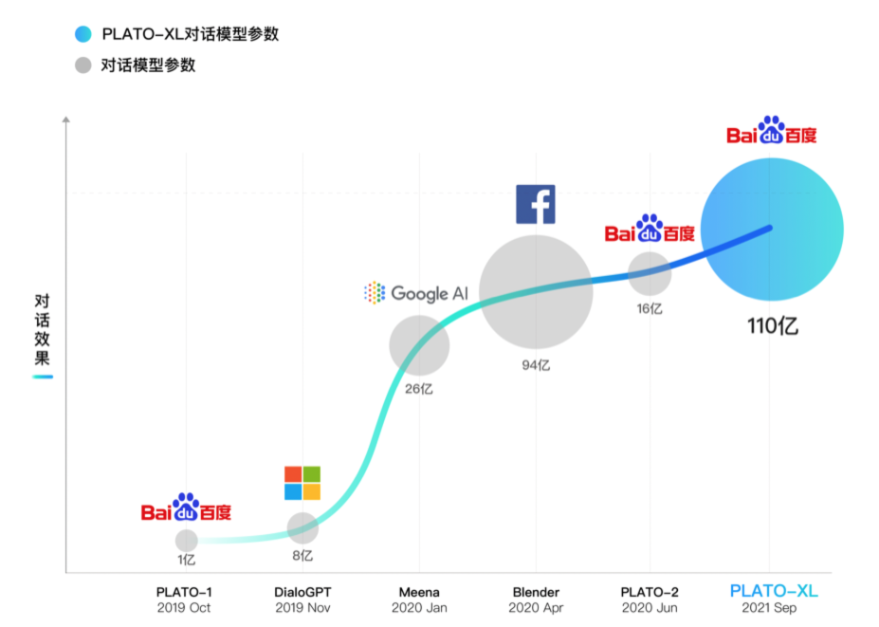
儘管大規模引數的模型在自然語言處理領域如雨後春筍出現,並且在多個自然語言理解和生成任務上取得了很多成果,但多輪開放域對話的主動性和常識性問題一直無法很好解決。百度NLP於2019年10月預釋出了通用領域的對話生成預訓練模型PLATO,在ACL 2020正式展示。2020年升級為超大規模模型PLATO-2,引數規模擴大到16億,涵蓋中英文版本,可就開放域話題深度暢聊。如今,百度全新發布PLATO-XL,引數規模首次突破百億達到110億,是當前最大規模的中英文對話生成模型。
論文名稱:
PLATO-XL:Exploring the Large-scale Pre-training of Dialogue Generation
論文地址:
https://arxiv.org/abs/2109.09519
PLATO-XL,全球首個百億引數對話預訓練生成模型
讓機器進行像人一樣有邏輯、有知識、有情感的對話,一直是人機智慧互動的重要技術挑戰;另一方面,開放域對話能力是實現機器人情感陪伴、智慧陪護、智慧助理的核心,被寄予了很高的期望。
預訓練技術大幅提升了模型對大規模無標註資料的學習能力,如何更高效、充分的利用大規模資料提升開放域對話能力,成為主流的研究方向。
從谷歌Meena、Facebook Blender到百度PLATO,開放域對話效果不斷提升。在全球對話技術頂級比賽DSTC-9上,百度PLATO-2創造了一個基礎模型取得5項不同對話任務第一的歷史性成績。
如今,百度釋出PLATO-XL,引數達到了110億,超過之前最大的對話模型Blender(最高94億引數),是當前最大規模的中英文對話生成模型,並再次重新整理了開放域對話效果。
百度PLATO一直有其獨特的從資料到模型結構到訓練方式上的創新。PLATO-1, PLATO-2不僅重新整理了開放域對話效果,也具有非常好的引數價效比,即在同等引數規模下效果超越其他模型。PLATO-XL在引數規模達到新高的同時,其對話效果也不出意外地再次達到新高。下面,我們將展開介紹PLATO-XL模型的核心技術特點。
PLATO-XL模型:更高引數價效比,大幅提升訓練效果
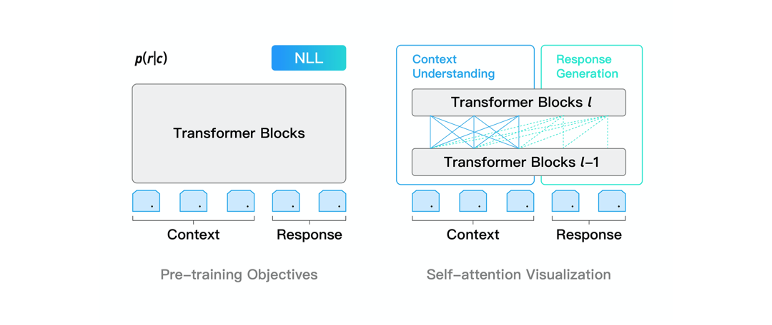
PLATO-XL網路架構上承襲了PLATO unified transformer結構,可同時進行對話理解和回覆生成的聯合建模,引數價效比很高。通過靈活的注意力機制,模型對上文進行了雙向編碼,充分利用和理解上文資訊;對回覆進行了單向解碼,適應回覆生成的auto-regressive特性。此外,unified transformer結構在對話上訓練效率很高,這是由於對話樣本長短不一,訓練過程中padding補齊會帶來大量的無效計算,unified transformer可以對輸入樣本進行有效的排序,大幅提升訓練效率。
為了進一步改善對話模型有時候自相矛盾的問題,PLATO-XL引入了多角色感知的輸入表示,以提升多輪對話上的一致性。對話模型所用的預訓練語料大多是社交媒體對話,通常有多個使用者參與,表述和交流一些觀點和內容。在訓練時,模型較難區分對話上文中不同角度的觀點和資訊,容易產生一些自相矛盾的回覆。針對社交媒體對話多方參與的特點,PLATO-XL進行了多角色感知的預訓練,對多輪對話中的各個角色進行清晰區分,輔助模型生成更加連貫、一致的回覆。
PLATO-XL包括中英文2個對話模型,預訓練語料規模達到千億級token,模型規模高達110億引數。PLATO-XL也是完全基於百度自主研發的