深入研究一下MySQL原理篇之InnoDB資料頁

不同型別的頁簡介
它是InnoDB管理儲存空間的基本單位,一個頁的大小一般是16KB。InnoDB為了不同的目的而設計了許多種不同型別的頁,比如存放表空間頭部資訊的頁,存放Insert Buffer資訊的頁,存放INODE資訊的頁,存放undo紀錄檔資訊的頁等等等等。當然了,如果我說的這些名詞你一個都沒有聽過,就當我放了個屁吧~ 不過這沒有一毛錢關係,我們今兒個也不準備說這些型別的頁,我們聚焦的是那些存放我們表中記錄的那種型別的頁,官方稱這種存放記錄的頁為索引(INDEX)頁,鑑於我們還沒有了解過索引是個什麼東西,而這些表中的記錄就是我們日常口中所稱的資料,所以目前還是叫這種存放記錄的頁為資料頁吧。
資料頁結構的快速瀏覽
資料頁代表的這塊16KB大小的儲存空間可以被劃分為多個部分,不同部分有不同的功能,各個部分如圖所示:
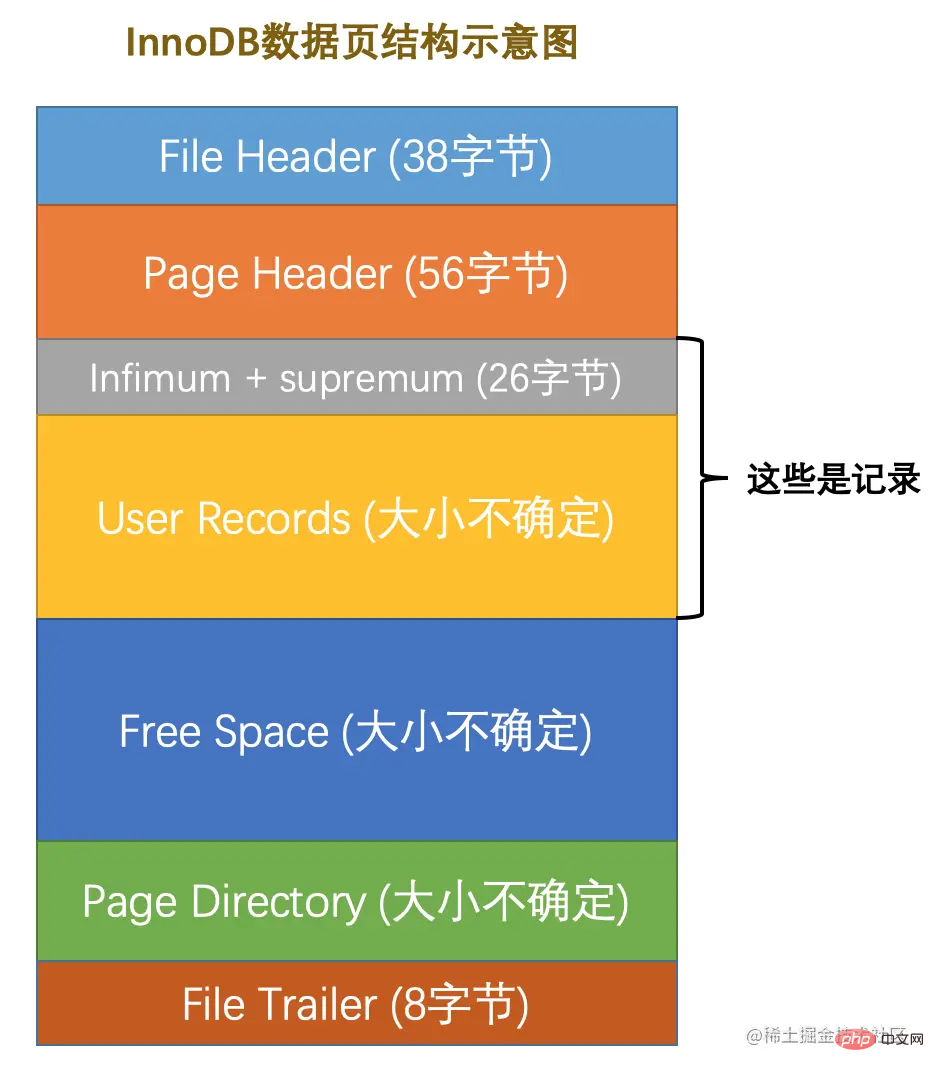
從圖中可以看出,一個InnoDB資料頁的儲存空間大致被劃分成了7個部分,有的部分佔用的位元組數是確定的,有的部分佔用的位元組數是不確定的。下邊我們用表格的方式來大致描述一下這7個部分都儲存一些啥內容(快速的瞅一眼就行了,後邊會詳細嘮叨的):
| 名稱 | 中文名 | 佔用空間大小 | 簡單描述 |
|---|---|---|---|
File Header | 檔案頭部 | 38位元組 | 頁的一些通用資訊 |
Page Header | 頁面頭部 | 56位元組 | 資料頁專有的一些資訊 |
Infimum + Supremum | 最小記錄和最大記錄 | 26位元組 | 兩個虛擬的行記錄 |
User Records | 使用者記錄 | 不確定 | 實際儲存的行記錄內容 |
Free Space | 空閒空間 | 不確定 | 頁中尚未使用的空間 |
Page Directory | 頁面目錄 | 不確定 | 頁中的某些記錄的相對位置 |
File Trailer | 檔案尾部 | 8位元組 | 校驗頁是否完整 |
記錄在頁中的儲存
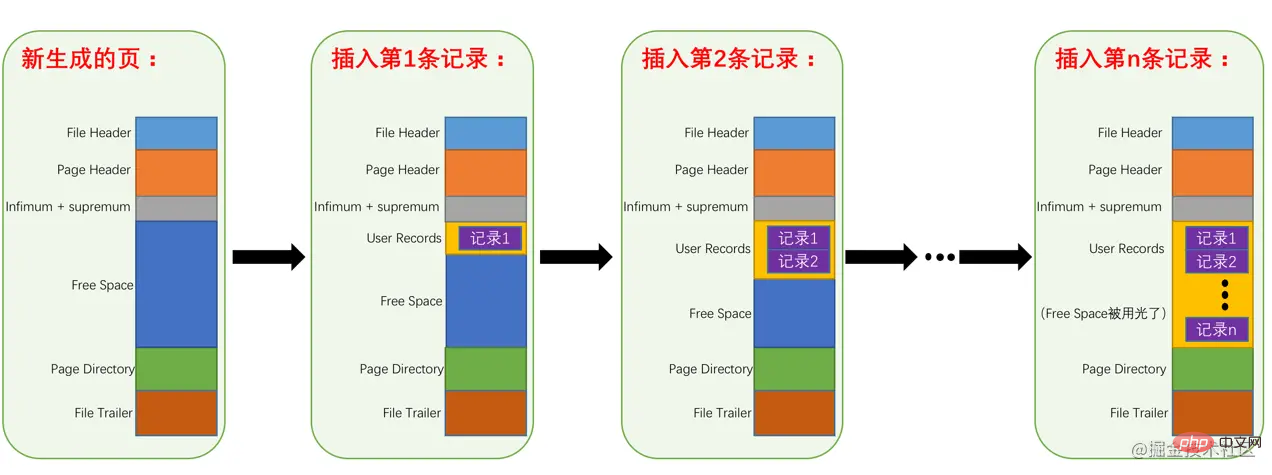
在頁的7個組成部分中,我們自己儲存的記錄會按照我們指定的行格式儲存到User Records部分。但是在一開始生成頁的時候,其實並沒有User Records這個部分,每當我們插入一條記錄,都會從Free Space部分,也就是尚未使用的儲存空間中申請一個記錄大小的空間劃分到User Records部分,當Free Space部分的空間全部被User Records部分替代掉之後,也就意味著這個頁使用完了,如果還有新的記錄插入的話,就需要去申請新的頁了,這個過程的圖示如下:
為了更好的管理在User Records中的這些記錄,InnoDB可費了一番力氣呢,在哪費力氣了呢?不就是把記錄按照指定的行格式一條一條擺在User Records部分麼?其實這話還得從記錄行格式的記錄頭資訊中說起。
記錄頭資訊的祕密
為了故事的順利發展,我們先建立一個表:
mysql> CREATE TABLE page_demo(
-> c1 INT,
-> c2 INT,
-> c3 VARCHAR(10000),
-> PRIMARY KEY (c1)
-> ) CHARSET=ascii ROW_FORMAT=Compact;
Query OK, 0 rows affected (0.03 sec)這個新建立的page_demo表有3個列,其中c1和c2列是用來儲存整數的,c3列是用來儲存字串的。需要注意的是,我們把 c1 列指定為主鍵,所以在具體的行格式中InnoDB就沒必要為我們去建立那個所謂的 row_id 隱藏列了。而且我們為這個表指定了ascii字元集以及Compact的行格式。所以這個表中記錄的行格式示意圖就是這樣的:
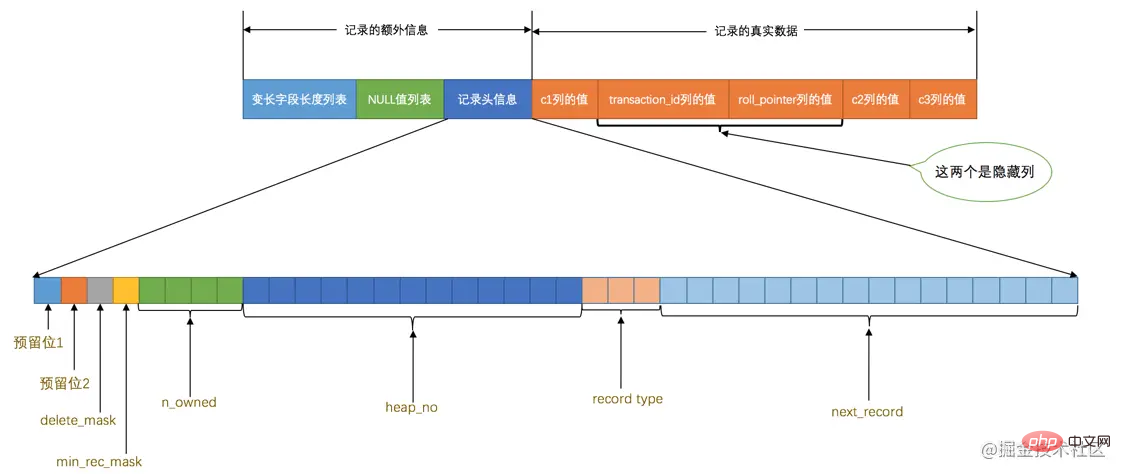
從圖中可以看到,我們特意把記錄頭資訊的5個位元組的資料給標出來了,說明它很重要,我們再次先把這些記錄頭資訊中各個屬性的大體意思瀏覽一下(我們目前使用Compact行格式進行演示):
| 名稱 | 大小(單位:bit) | 描述 |
|---|---|---|
預留位1 | 1 | 沒有使用 |
預留位2 | 1 | 沒有使用 |
delete_mask | 1 | 標記該記錄是否被刪除 |
min_rec_mask | 1 | B+樹的每層非葉子節點中的最小記錄都會新增該標記 |
n_owned | 4 | 表示當前記錄擁有的記錄數 |
heap_no | 13 | 表示當前記錄在記錄堆的位置資訊 |
record_type | 3 | 表示當前記錄的型別,0表示普通記錄,1表示B+樹非葉節點記錄,2表示最小記錄,3表示最大記錄 |
next_record | 16 | 表示下一條記錄的相對位置 |
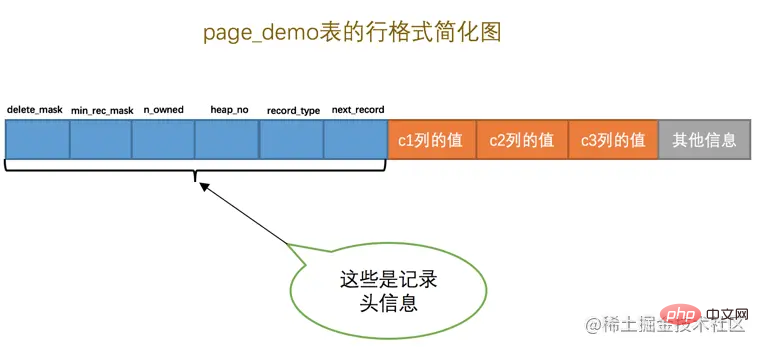
由於我們現在主要在嘮叨記錄頭資訊的作用,所以為了大家理解上的方便,我們只在page_demo表的行格式演示圖中畫出有關的頭資訊屬性以及c1、c2、c3列的資訊(其他資訊沒畫不代表它們不存在啊,只是為了理解上的方便在圖中省略了~),簡化後的行格式示意圖就是這樣:
下邊我們試著向page_demo表中插入幾條記錄:
mysql> INSERT INTO page_demo VALUES(1, 100, 'aaaa'), (2, 200, 'bbbb'), (3, 300, 'cccc'), (4, 400, 'dddd'); Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0
為了方便大家分析這些記錄在頁的User Records部分中是怎麼表示的,我把記錄中頭資訊和實際的列資料都用十進位制表示出來了(其實是一堆二進位制位),所以這些記錄的示意圖就是:
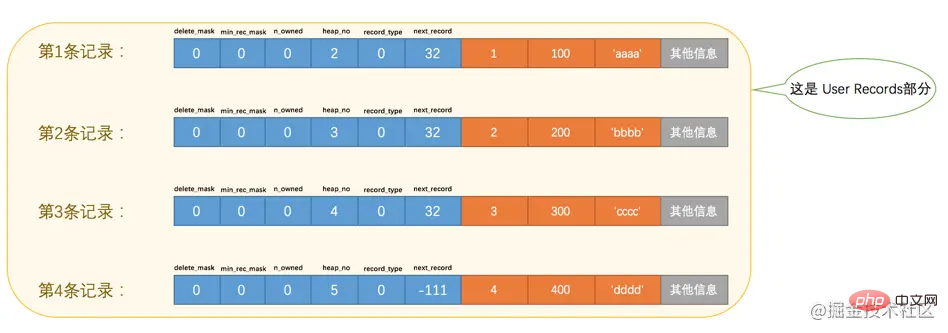
看這個圖的時候需要注意一下,各條記錄在User Records中儲存的時候並沒有空隙,這裡只是為了大家觀看方便才把每條記錄單獨畫在一行中。我們對照著這個圖來看看記錄頭資訊中的各個屬性是啥意思:
delete_mask這個屬性標記著當前記錄是否被刪除,佔用1個二進位制位,值為
0的時候代表記錄並沒有被刪除,為1的時候代表記錄被刪除掉了。啥?被刪除的記錄還在
頁中麼?是的,擺在檯面上的和背地裡做的可能大相徑庭,你以為它刪除了,可它還在真實的磁碟上[攤手](忽然想起冠希~)。這些被刪除的記錄之所以不立即從磁碟上移除,是因為移除它們之後把其他的記錄在磁碟上重新排列需要效能消耗,所以只是打一個刪除標記而已,所有被刪除掉的記錄都會組成一個所謂的垃圾連結串列,在這個連結串列中的記錄佔用的空間稱之為所謂的可重用空間,之後如果有新記錄插入到表中的話,可能把這些被刪除的記錄佔用的儲存空間覆蓋掉。min_rec_maskB+樹的每層非葉子節點中的最小記錄都會新增該標記,什麼是個
B+樹?什麼是個非葉子節點?好吧,等會再聊這個問題。反正我們自己插入的四條記錄的min_rec_mask值都是0,意味著它們都不是B+樹的非葉子節點中的最小記錄。n_owned這個暫時保密,稍後它是主角~
heap_no這個屬性表示當前記錄在本
頁中的位置,從圖中可以看出來,我們插入的4條記錄在本頁中的位置分別是:2、3、4、5。是不是少了點啥?是的,怎麼不見heap_no值為0和1的記錄呢?這其實是設計
InnoDB的大叔們玩的一個小把戲,他們自動給每個頁裡邊兒加了兩個記錄,由於這兩個記錄並不是我們自己插入的,所以有時候也稱為偽記錄或者虛擬記錄。這兩個偽記錄一個代表最小記錄,一個代表最大記錄,等一下哈~,記錄可以比大小麼?是的,記錄也可以比大小,對於一條完整的記錄來說,比較記錄的大小就是比較
主鍵的大小。比方說我們插入的4行記錄的主鍵值分別是:1、2、3、4,這也就意味著這4條記錄的大小從小到大依次遞增。但是不管我們向
頁中插入了多少自己的記錄,設計InnoDB的大叔們都規定他們定義的兩條偽記錄分別為最小記錄與最大記錄。這兩條記錄的構造十分簡單,都是由5位元組大小的記錄頭資訊和8位元組大小的一個固定的部分組成的,如圖所示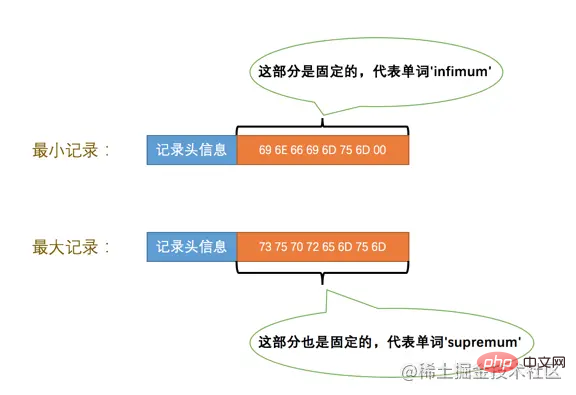
由於這兩條記錄不是我們自己定義的記錄,所以它們並不存放在
頁的User Records部分,他們被單獨放在一個稱為Infimum + Supremum的部分,如圖所示:
從圖中我們可以看出來,最小記錄和最大記錄的
heap_no值分別是0和1,也就是說它們的位置最靠前。record_type這個屬性表示當前記錄的型別,一共有4種型別的記錄,
0表示普通記錄,1表示B+樹非葉節點記錄,2表示最小記錄,3表示最大記錄。從圖中我們也可以看出來,我們自己插入的記錄就是普通記錄,它們的record_type值都是0,而最小記錄和最大記錄的record_type值分別為2和3。至於
record_type為1的情況,我們之後在說索引的時候會重點強調的。next_record這玩意兒非常重要,它表示從當前記錄的真實資料到下一條記錄的真實資料的地址偏移量。比方說第一條記錄的
next_record值為32,意味著從第一條記錄的真實資料的地址處向後找32個位元組便是下一條記錄的真實資料。如果你熟悉資料結構的話,就立即明白了,這其實是個連結串列,可以通過一條記錄找到它的下一條記錄。但是需要注意注意再注意的一點是,下一條記錄指得並不是按照我們插入順序的下一條記錄,而是按照主鍵值由小到大的順序的下一條記錄。而且規定 Infimum記錄(也就是最小記錄) 的下一條記錄就是本頁中主鍵值最小的使用者記錄,而本頁中主鍵值最大的使用者記錄的下一條記錄就是 Supremum記錄(也就是最大記錄) ,為了更形象的表示一下這個next_record起到的作用,我們用箭頭來替代一下next_record中的地址偏移量: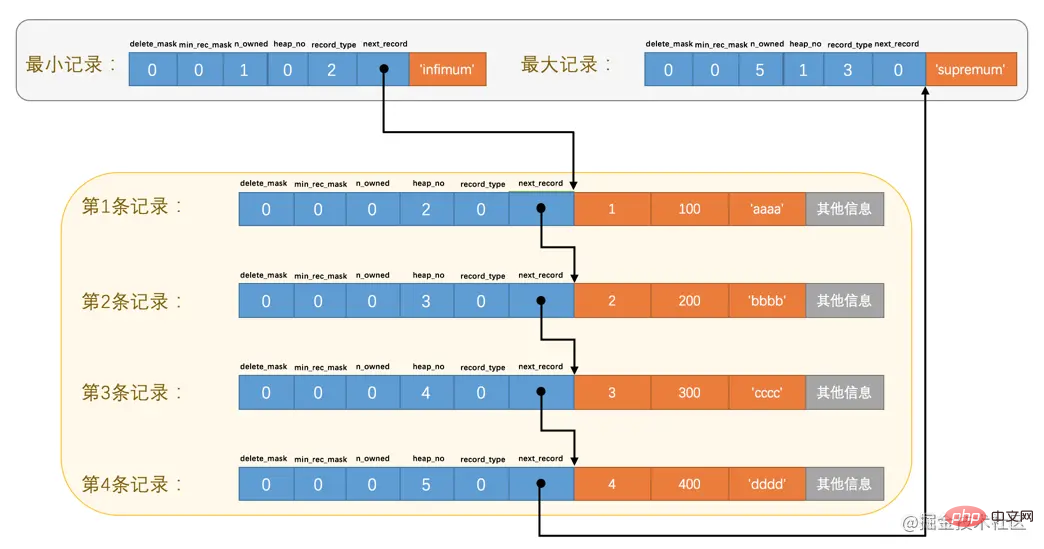
從圖中可以看出來,我們的記錄按照主鍵從小到大的順序形成了一個單連結串列。
最大記錄的next_record的值為0,這也就是說最大記錄是沒有下一條記錄了,它是這個單連結串列中的最後一個節點。如果從中刪除掉一條記錄,這個連結串列也是會跟著變化的,比如我們把第2條記錄刪掉:mysql> DELETE FROM page_demo WHERE c1 = 2; Query OK, 1 row affected (0.02 sec)
刪掉第2條記錄後的示意圖就是:
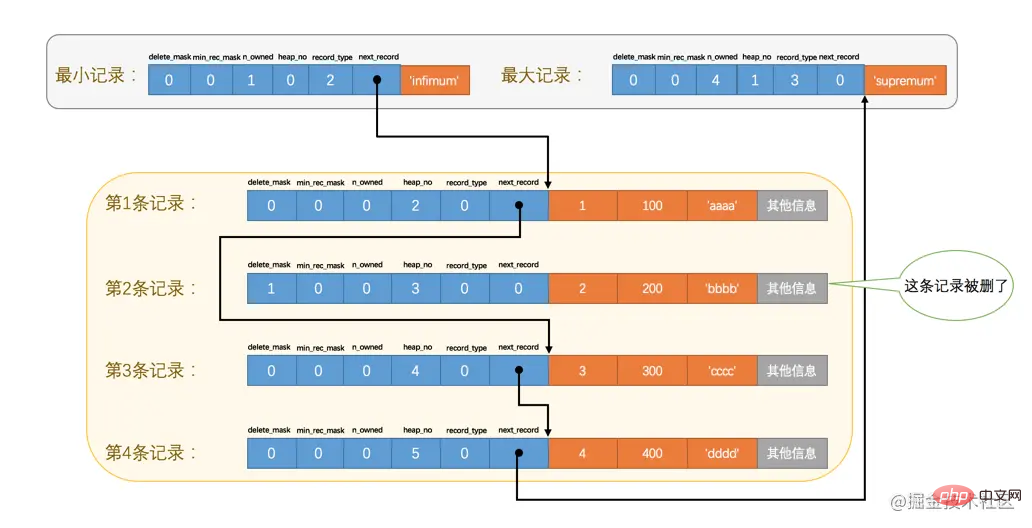
從圖中可以看出來,刪除第2條記錄前後主要發生了這些變化:
- 第2條記錄並沒有從儲存空間中移除,而是把該條記錄的
delete_mask值設定為1。 - 第2條記錄的
next_record值變為了0,意味著該記錄沒有下一條記錄了。 - 第1條記錄的
next_record指向了第3條記錄。 - 還有一點你可能忽略了,就是
最大記錄的n_owned值從5變成了4,關於這一點的變化我們稍後會詳細說明的。
所以,不論我們怎麼對頁中的記錄做增刪改操作,InnoDB始終會維護一條記錄的單連結串列,連結串列中的各個節點是按照主鍵值由小到大的順序連線起來的。
- 第2條記錄並沒有從儲存空間中移除,而是把該條記錄的
再來看一個有意思的事情,因為主鍵值為2的記錄被我們刪掉了,但是儲存空間卻沒有回收,如果我們再次把這條記錄插入到表中,會發生什麼事呢?
mysql> INSERT INTO page_demo VALUES(2, 200, 'bbbb'); Query OK, 1 row affected (0.00 sec)
我們看一下記錄的儲存情況:
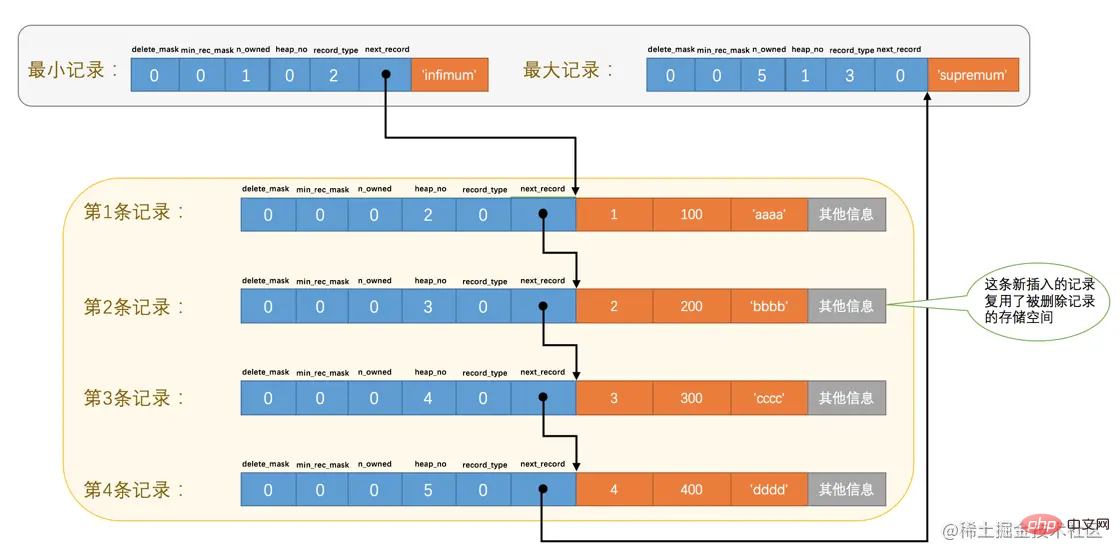
從圖中可以看到,InnoDB並沒有因為新記錄的插入而為它申請新的儲存空間,而是直接複用了原來被刪除記錄的儲存空間。
Page Directory(頁目錄)
現在我們瞭解了記錄在頁中按照主鍵值由小到大順序串聯成一個單連結串列,那如果我們想根據主鍵值查詢頁中的某條記錄該咋辦呢?比如說這樣的查詢語句:
SELECT * FROM page_demo WHERE c1 = 3;
最笨的辦法:從Infimum記錄(最小記錄)開始,沿著連結串列一直往後找,總有一天會找到(或者找不到[攤手]),在找的時候還能投機取巧,因為連結串列中各個記錄的值是按照從小到大順序排列的,所以當連結串列的某個節點代表的記錄的主鍵值大於你想要查詢的主鍵值時,你就可以停止查詢了,因為該節點後邊的節點的主鍵值依次遞增。
這個方法在頁中儲存的記錄數量比較少的情況用起來也沒啥問題,比方說現在我們的表裡只有4條自己插入的記錄,所以最多找4次就可以把所有記錄都遍歷一遍,但是如果一個頁中儲存了非常多的記錄,這麼查詢對效能來說還是有損耗的,所以我們說這種遍歷查詢這是一個笨辦法。但是設計InnoDB的大叔們是什麼人,他們能用這麼笨的辦法麼,當然是要設計一種更6的查詢方式嘍,他們從書的目錄中找到了靈感。
我們平常想從一本書中查詢某個內容的時候,一般會先看目錄,找到需要查詢的內容對應的書的頁碼,然後到對應的頁碼檢視內容。設計InnoDB的大叔們為我們的記錄也製作了一個類似的目錄,他們的製作過程是這樣的:
將所有正常的記錄(包括最大和最小記錄,不包括標記為已刪除的記錄)劃分為幾個組。
每個組的最後一條記錄(也就是組內最大的那條記錄)的頭資訊中的
n_owned屬性表示該記錄擁有多少條記錄,也就是該組內共有幾條記錄。將每個組的最後一條記錄的地址偏移量單獨提取出來按順序儲存到靠近
頁的尾部的地方,這個地方就是所謂的Page Directory,也就是頁目錄(此時應該返回頭看看頁面各個部分的圖)。頁面目錄中的這些地址偏移量被稱為槽(英文名:Slot),所以這個頁面目錄就是由槽組成的。
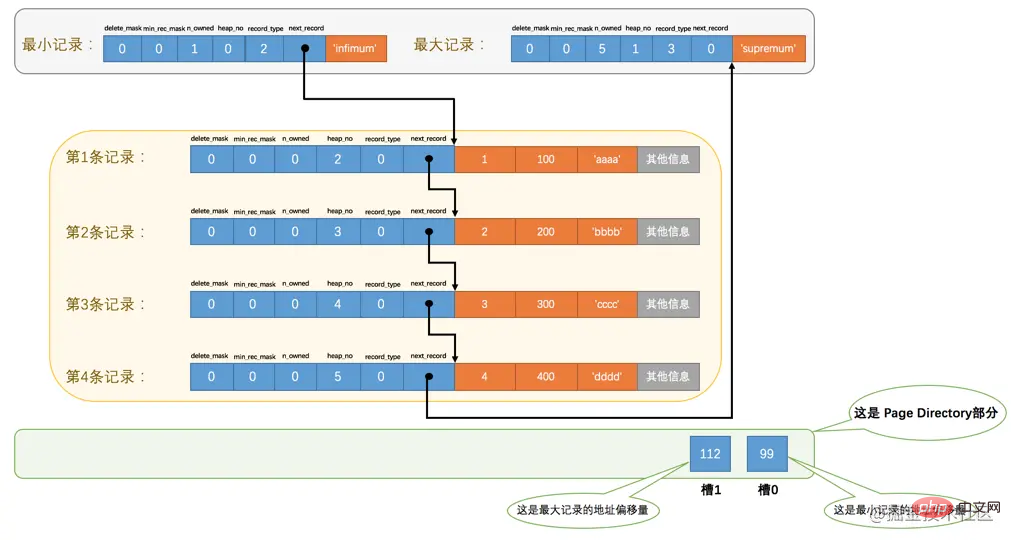
比方說現在的page_demo表中正常的記錄共有6條,InnoDB會把它們分成兩組,第一組中只有一個最小記錄,第二組中是剩餘的5條記錄,看下邊的示意圖:
從這個圖中我們需要注意這麼幾點:
現在
頁目錄部分中有兩個槽,也就意味著我們的記錄被分成了兩個組,槽1中的值是112,代表最大記錄的地址偏移量(就是從頁面的0位元組開始數,數112個位元組);槽0中的值是99,代表最小記錄的地址偏移量。注意最小和最大記錄的頭資訊中的
n_owned屬性- 最小記錄的
n_owned值為1,這就代表著以最小記錄結尾的這個分組中只有1條記錄,也就是最小記錄本身。 - 最大記錄的
n_owned值為5,這就代表著以最大記錄結尾的這個分組中只有5條記錄,包括最大記錄本身還有我們自己插入的4條記錄。
- 最小記錄的
99和112這樣的地址偏移量很不直觀,我們用箭頭指向的方式替代數位,這樣更易於我們理解,所以修改後的示意圖就是這樣:
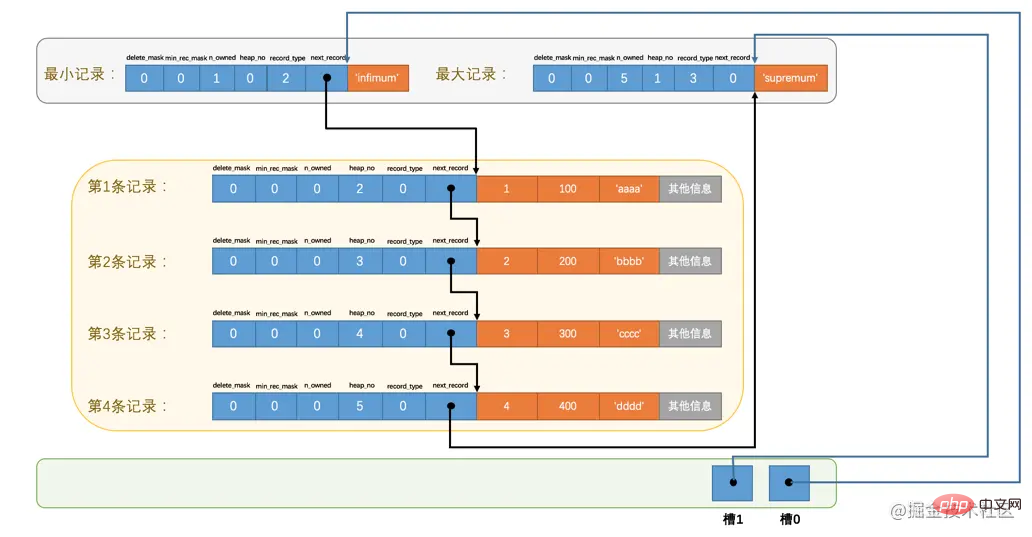
哎呀,咋看上去怪怪的,這麼亂的圖對於我這個強迫症真是不能忍,那我們就暫時不管各條記錄在儲存裝置上的排列方式了,單純從邏輯上看一下這些記錄和頁目錄的關係:
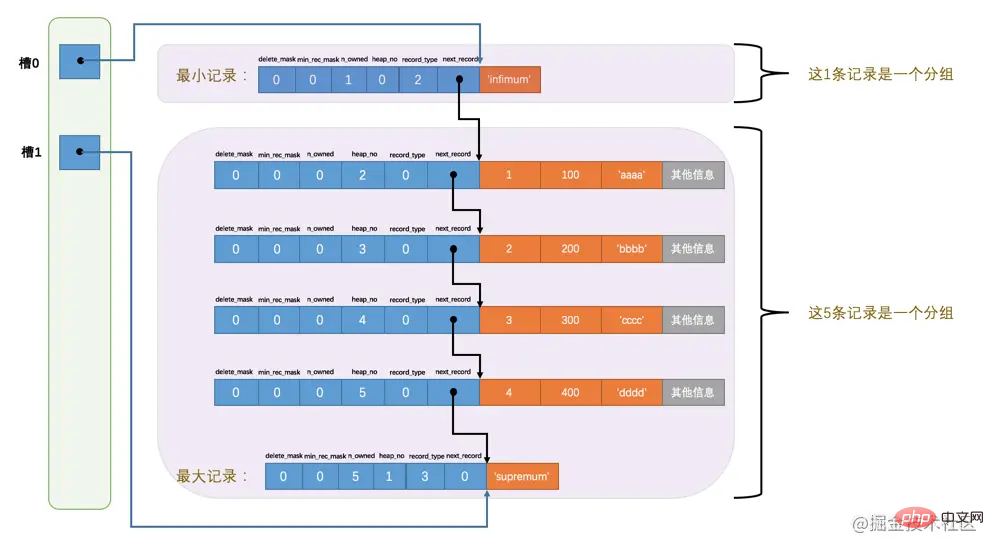
這樣看就順眼多了嘛!為什麼最小記錄的n_owned值為1,而最大記錄的n_owned值為5呢,這裡頭有什麼貓膩麼?
是的,設計InnoDB的大叔們對每個分組中的記錄條數是有規定的:對於最小記錄所在的分組只能有 1 條記錄,最大記錄所在的分組擁有的記錄條數只能在 1~8 條之間,剩下的分組中記錄的條數範圍只能在是 4~8 條之間。所以分組是按照下邊的步驟進行的:
初始情況下一個資料頁裡只有最小記錄和最大記錄兩條記錄,它們分屬於兩個分組。
之後每插入一條記錄,都會從
頁目錄中找到主鍵值比本記錄的主鍵值大並且差值最小的槽,然後把該槽對應的記錄的n_owned值加1,表示本組內又新增了一條記錄,直到該組中的記錄數等於8個。在一個組中的記錄數等於8個後再插入一條記錄時,會將組中的記錄拆分成兩個組,一個組中4條記錄,另一個5條記錄。這個過程會在
頁目錄中新增一個槽來記錄這個新增分組中最大的那條記錄的偏移量。
由於現在page_demo表中的記錄太少,無法演示新增了頁目錄之後加快查詢速度的過程,所以再往page_demo表中新增一些記錄:
mysql> INSERT INTO page_demo VALUES(5, 500, 'eeee'), (6, 600, 'ffff'), (7, 700, 'gggg'), (8, 800, 'hhhh'), (9, 900, 'iiii'), (10, 1000, 'jjjj'), (11, 1100, 'kkkk'), (12, 1200, 'llll'), (13, 1300, 'mmmm'), (14, 1400, 'nnnn'), (15, 1500, 'oooo'), (16, 1600, 'pppp'); Query OK, 12 rows affected (0.00 sec) Records: 12 Duplicates: 0 Warnings: 0
哈,我們一口氣又往表中新增了12條記錄,現在頁裡邊就一共有18條記錄了(包括最小和最大記錄),這些記錄被分成了5個組,如圖所示:
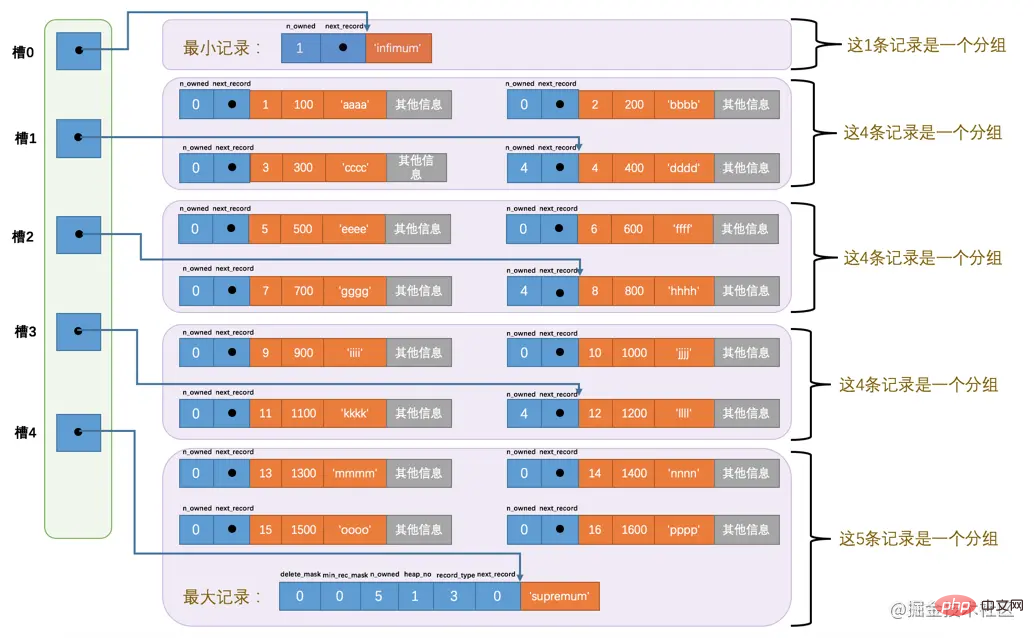
因為把16條記錄的全部資訊都畫在一張圖裡太佔地方,讓人眼花繚亂的,所以只保留了使用者記錄頭資訊中的n_owned和next_record屬性,也省略了各個記錄之間的箭頭,我沒畫不等於沒有啊!現在看怎麼從這個頁目錄中查詢記錄。因為各個槽代表的記錄的主鍵值都是從小到大排序的,所以我們可以使用所謂的二分法來進行快速查詢。5個槽的編號分別是:0、1、2、3、4,所以初始情況下最低的槽就是low=0,最高的槽就是high=4。比方說我們想找主鍵值為6的記錄,過程是這樣的:
計算中間槽的位置:
(0+4)/2=2,所以檢視槽2對應記錄的主鍵值為8,又因為8 > 6,所以設定high=2,low保持不變。重新計算中間槽的位置:
(0+2)/2=1,所以檢視槽1對應的主鍵值為4,又因為4 < 6,所以設定low=1,high保持不變。因為
high - low的值為1,所以確定主鍵值為6的記錄在槽2對應的組中。此刻我們需要找到槽2中主鍵值最小的那條記錄,然後沿著單向連結串列遍歷槽2中的記錄。但是我們前邊又說過,每個槽對應的記錄都是該組中主鍵值最大的記錄,這裡槽2對應的記錄是主鍵值為8的記錄,怎麼定位一個組中最小的記錄呢?別忘了各個槽都是挨著的,我們可以很輕易的拿到槽1對應的記錄(主鍵值為4),該條記錄的下一條記錄就是槽2中主鍵值最小的記錄,該記錄的主鍵值為5。所以我們可以從這條主鍵值為5的記錄出發,遍歷槽2中的各條記錄,直到找到主鍵值為6的那條記錄即可。由於一個組中包含的記錄條數只能是1~8條,所以遍歷一個組中的記錄的代價是很小的。
所以在一個資料頁中查詢指定主鍵值的記錄的過程分為兩步:
通過二分法確定該記錄所在的槽,並找到該槽所在分組中主鍵值最小的那條記錄。
通過記錄的
next_record屬性遍歷該槽所在的組中的各個記錄。
Page Header(頁面頭部)
設計InnoDB的大叔們為了能得到一個資料頁中儲存的記錄的狀態資訊,比如本頁中已經儲存了多少條記錄,第一條記錄的地址是什麼,頁目錄中儲存了多少個槽等等,特意在頁中定義了一個叫Page Header的部分,它是頁結構的第二部分,這個部分佔用固定的56個位元組,專門儲存各種狀態資訊,具體各個位元組都是幹嘛的看下錶:
| 名稱 | 佔用空間大小 | 描述 |
|---|---|---|
PAGE_N_DIR_SLOTS | 2位元組 | 在頁目錄中的槽數量 |
PAGE_HEAP_TOP | 2位元組 | 還未使用的空間最小地址,也就是說從該地址之後就是Free Space |
PAGE_N_HEAP | 2位元組 | 本頁中的記錄的數量(包括最小和最大記錄以及標記為刪除的記錄) |
PAGE_FREE | 2位元組 | 第一個已經標記為刪除的記錄地址(各個已刪除的記錄通過next_record也會組成一個單連結串列,這個單連結串列中的記錄可以被重新利用) |
PAGE_GARBAGE | 2位元組 | 已刪除記錄佔用的位元組數 |
PAGE_LAST_INSERT | 2位元組 | 最後插入記錄的位置 |
PAGE_DIRECTION | 2位元組 | 記錄插入的方向 |
PAGE_N_DIRECTION | 2位元組 | 一個方向連續插入的記錄數量 |
PAGE_N_RECS | 2位元組 | 該頁中記錄的數量(不包括最小和最大記錄以及被標記為刪除的記錄) |
PAGE_MAX_TRX_ID | 8位元組 | 修改當前頁的最大事務ID,該值僅在二級索引中定義 |
PAGE_LEVEL | 2位元組 | 當前頁在B+樹中所處的層級 |
PAGE_INDEX_ID | 8位元組 | 索引ID,表示當前頁屬於哪個索引 |
PAGE_BTR_SEG_LEAF | 10位元組 | B+樹葉子段的頭部資訊,僅在B+樹的Root頁定義 |
PAGE_BTR_SEG_TOP | 10位元組 | B+樹非葉子段的頭部資訊,僅在B+樹的Root頁定義 |
如果大家認真看過前邊的文章,從PAGE_N_DIR_SLOTS到PAGE_LAST_INSERT以及PAGE_N_RECS的意思大家一定是清楚的,如果不清楚,對不起,你應該回頭再看一遍前邊的文章。剩下的狀態資訊看不明白不要著急,飯要一口一口吃,東西要一點一點學(一定要稍安勿躁哦,不要被這些名詞嚇到)。在這裡我們先嘮叨一下PAGE_DIRECTION和PAGE_N_DIRECTION的意思:
PAGE_DIRECTION假如新插入的一條記錄的主鍵值比上一條記錄的主鍵值大,我們說這條記錄的插入方向是右邊,反之則是左邊。用來表示最後一條記錄插入方向的狀態就是
PAGE_DIRECTION。PAGE_N_DIRECTION假設連續幾次插入新記錄的方向都是一致的,
InnoDB會把沿著同一個方向插入記錄的條數記下來,這個條數就用PAGE_N_DIRECTION這個狀態表示。當然,如果最後一條記錄的插入方向改變了的話,這個狀態的值會被清零重新統計。
至於我們沒提到的那些屬性,我沒說是因為現在不需要大家知道。不要著急,當我們學完了後邊的內容,你再回頭看,一切都是那麼清晰。
File Header(檔案頭部)
上邊嘮叨的Page Header是專門針對資料頁記錄的各種狀態資訊,比方說頁裡頭有多少個記錄了呀,有多少個槽了呀。我們現在描述的File Header針對各種型別的頁都通用,也就是說不同型別的頁都會以File Header作為第一個組成部分,它描述了一些針對各種頁都通用的一些資訊,比方說這個頁的編號是多少,它的上一個頁、下一個頁是誰啦吧啦吧啦~ 這個部分佔用固定的38個位元組,是由下邊這些內容組成的:
| 名稱 | 佔用空間大小 | 描述 |
|---|---|---|
FIL_PAGE_SPACE_OR_CHKSUM | 4位元組 | 頁的校驗和(checksum值) |
FIL_PAGE_OFFSET | 4位元組 | 頁號 |
FIL_PAGE_PREV | 4位元組 | 上一個頁的頁號 |
FIL_PAGE_NEXT | 4位元組 | 下一個頁的頁號 |
FIL_PAGE_LSN | 8位元組 | 頁面被最後修改時對應的紀錄檔序列位置(英文名是:Log Sequence Number) |
FIL_PAGE_TYPE | 2位元組 | 該頁的型別 |
FIL_PAGE_FILE_FLUSH_LSN | 8位元組 | 僅在系統表空間的一個頁中定義,代表檔案至少被重新整理到了對應的LSN值 |
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4位元組 | 頁屬於哪個表空間 |
對照著這個表格,我們看幾個目前比較重要的部分:
FIL_PAGE_SPACE_OR_CHKSUM這個代表當前頁面的校驗和(checksum)。啥是個校驗和?就是對於一個很長很長的位元組串來說,我們會通過某種演演算法來計算一個比較短的值來代表這個很長的位元組串,這個比較短的值就稱為
校驗和。這樣在比較兩個很長的位元組串之前先比較這兩個長位元組串的校驗和,如果校驗和都不一樣兩個長位元組串肯定是不同的,所以省去了直接比較兩個比較長的位元組串的時間損耗。FIL_PAGE_OFFSET每一個
頁都有一個單獨的頁號,就跟你的身份證號碼一樣,InnoDB通過頁號來可以唯一定位一個頁。FIL_PAGE_TYPE這個代表當前
頁的型別,我們前邊說過,InnoDB為了不同的目的而把頁分為不同的型別,我們上邊介紹的其實都是儲存記錄的資料頁,其實還有很多別的型別的頁,具體如下表:型別名稱 十六進位制 描述 FIL_PAGE_TYPE_ALLOCATED0x0000 最新分配,還沒使用 FIL_PAGE_UNDO_LOG0x0002 Undo紀錄檔頁 FIL_PAGE_INODE0x0003 段資訊節點 FIL_PAGE_IBUF_FREE_LIST0x0004 Insert Buffer空閒列表 FIL_PAGE_IBUF_BITMAP0x0005 Insert Buffer點陣圖 FIL_PAGE_TYPE_SYS0x0006 系統頁 FIL_PAGE_TYPE_TRX_SYS0x0007 事務系統資料 FIL_PAGE_TYPE_FSP_HDR0x0008 表空間頭部資訊 FIL_PAGE_TYPE_XDES0x0009 擴充套件描述頁 FIL_PAGE_TYPE_BLOB0x000A 溢位頁 FIL_PAGE_INDEX0x45BF 索引頁,也就是我們所說的 資料頁我們存放記錄的資料頁的型別其實是
FIL_PAGE_INDEX,也就是所謂的索引頁。至於啥是個索引,且聽下回分解~FIL_PAGE_PREV和FIL_PAGE_NEXT我們前邊強調過,
InnoDB都是以頁為單位存放資料的,有時候我們存放某種型別的資料佔用的空間非常大(比方說一張表中可以有成千上萬條記錄),InnoDB可能不可以一次性為這麼多資料分配一個非常大的儲存空間,如果分散到多個不連續的頁中儲存的話需要把這些頁關聯起來,FIL_PAGE_PREV和FIL_PAGE_NEXT就分別代表本頁的上一個和下一個頁的頁號。這樣通過建立一個雙向連結串列把許許多多的頁就都串聯起來了,而無需這些頁在物理上真正連著。需要注意的是,並不是所有型別的頁都有上一個和下一個頁的屬性,不過我們本集中嘮叨的資料頁(也就是型別為FIL_PAGE_INDEX的頁)是有這兩個屬性的,所以所有的資料頁其實是一個雙連結串列,就像這樣: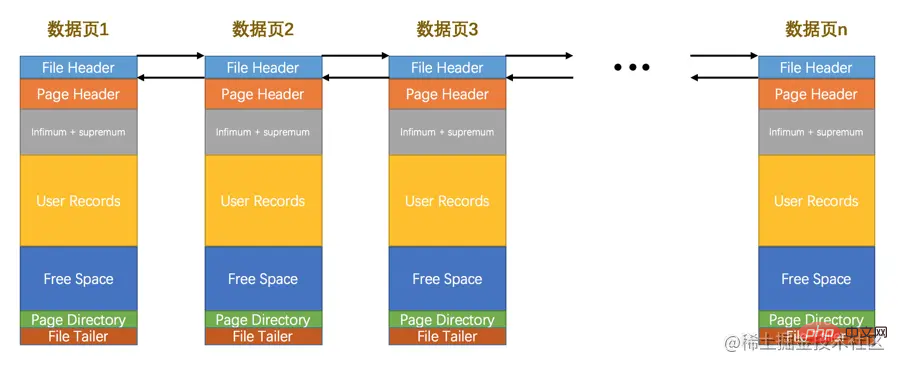
關於File Header的其他屬性我們暫時用不到,等用到的時候再提哈~
File Trailer
我們知道InnoDB儲存引擎會把資料儲存到磁碟上,但是磁碟速度太慢,需要以頁為單位把資料載入到記憶體中處理,如果該頁中的資料在記憶體中被修改了,那麼在修改後的某個時間需要把資料同步到磁碟中。但是在同步了一半的時候中斷電了咋辦,這不是莫名尷尬麼?為了檢測一個頁是否完整(也就是在同步的時候有沒有發生只同步一半的尷尬情況),設計InnoDB的大叔們在每個頁的尾部都加了一個File Trailer部分,這個部分由8個位元組組成,可以分成2個小部分:
前4個位元組代表頁的校驗和
這個部分是和
File Header中的校驗和相對應的。每當一個頁面在記憶體中修改了,在同步之前就要把它的校驗和算出來,因為File Header在頁面的前邊,所以校驗和會被首先同步到磁碟,當完全寫完時,校驗和也會被寫到頁的尾部,如果完全同步成功,則頁的首部和尾部的校驗和應該是一致的。如果寫了一半兒斷電了,那麼在File Header中的校驗和就代表著已經修改過的頁,而在File Trailer中的校驗和代表著原先的頁,二者不同則意味著同步中間出了錯。後4個位元組代表頁面被最後修改時對應的紀錄檔序列位置(LSN)
這個部分也是為了校驗頁的完整性的,只不過我們目前還沒說
LSN是個什麼意思,所以大家可以先不用管這個屬性。
這個File Trailer與File Header類似,都是所有型別的頁通用的。
總結
InnoDB為了不同的目的而設計了不同型別的頁,我們把用於存放記錄的頁叫做
資料頁。一個資料頁可以被大致劃分為7個部分,分別是
File Header,表示頁的一些通用資訊,佔固定的38位元組。Page Header,表示資料頁專有的一些資訊,佔固定的56個位元組。Infimum + Supremum,兩個虛擬的偽記錄,分別表示頁中的最小和最大記錄,佔固定的26個位元組。User Records:真實儲存我們插入的記錄的部分,大小不固定。Free Space:頁中尚未使用的部分,大小不確定。Page Directory:頁中的某些記錄相對位置,也就是各個槽在頁面中的地址偏移量,大小不固定,插入的記錄越多,這個部分佔用的空間越多。File Trailer:用於檢驗頁是否完整的部分,佔用固定的8個位元組。
每個記錄的頭資訊中都有一個
next_record屬性,從而使頁中的所有記錄串聯成一個單連結串列。InnoDB會把頁中的記錄劃分為若干個組,每個組的最後一個記錄的地址偏移量作為一個槽,存放在Page Directory中,所以在一個頁中根據主鍵查詢記錄是非常快的,分為兩步:通過二分法確定該記錄所在的槽。
通過記錄的next_record屬性遍歷該槽所在的組中的各個記錄。
每個資料頁的
File Header部分都有上一個和下一個頁的編號,所以所有的資料頁會組成一個雙連結串列。為保證從記憶體中同步到磁碟的頁的完整性,在頁的首部和尾部都會儲存頁中資料的校驗和和頁面最後修改時對應的
LSN值,如果首部和尾部的校驗和和LSN值校驗不成功的話,就說明同步過程出現了問題。
推薦學習:
以上就是深入研究一下MySQL原理篇之InnoDB資料頁的詳細內容,更多請關注TW511.COM其它相關文章!