分散式儲存系統之Ceph基礎
Ceph基礎概述
Ceph是一個物件式儲存系統,所謂物件式儲存是指它把每一個待管理的資料流(比如一個檔案)切分成一到多個固定大小的物件資料,並以其為原子單元完成資料的存取;物件資料的底層儲存服務由多個主機組成的儲存叢集;該叢集被稱之為RADOS(Reliable Automatic Distributed Object Store)叢集;翻譯成中文就是可靠的、自動化分散式物件儲存系統;
Ceph架構
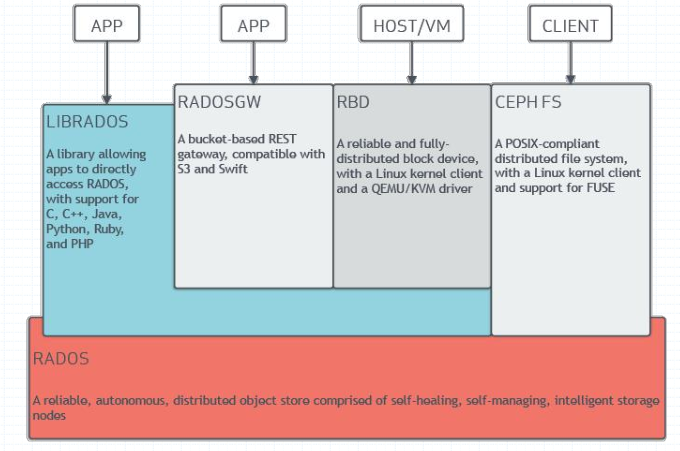
提示:librados是RADOS儲存叢集的API,它支援C、C++、java、python和php等變成語言;RADOSGW、RBD、CEPHFS都是RADOS儲存服務的客戶介面;它們分別把rados儲存服務介面librados從不同角度做了進一步的抽象,因而各自適用於不同的應用場景;RADOSGW是將底層rados儲存服務抽象為以RESTful風格介面提供物件儲存服務,適用於存取物件資料的介面,比如web服務;RBD是將底層RADOS儲存服務抽象為塊裝置的儲存裝置;主要用於虛擬化,比如給虛擬機器器提供硬碟;CEPHFS是將底層RADOS抽象為一個檔案系統介面,供其他主機使用;
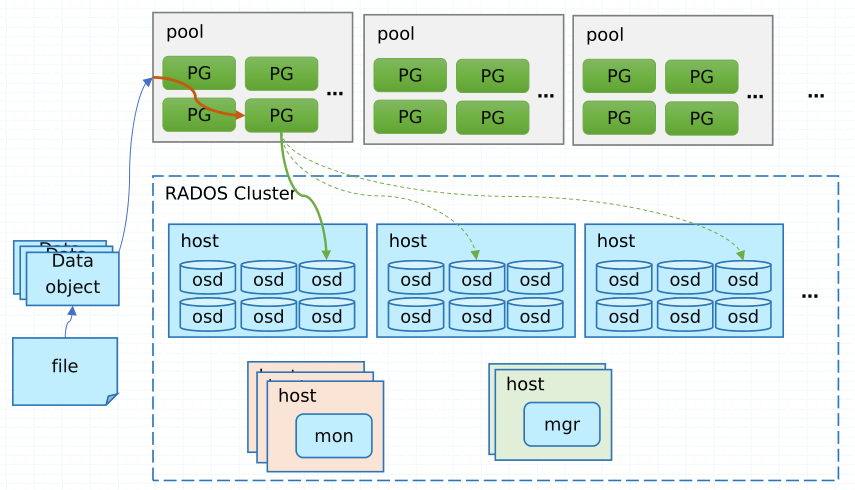
提示:RADOS叢集主要由Monitors、Managers、Ceph OSDs、Ceph MDSs這幾個元件組成;其中Monitor主要作用是監控整個叢集的狀態,健康與否等;它擁有整個叢集的執行圖(monitor map、manager map、OSD map、和CRUSH map);除此之外,它還負責維護叢集各元件之間以及使用者端接入RADOS叢集存取資料時的認證資訊和實行認證;簡單講mon元件就是管理和維護其他元件狀態以及接入RADOS叢集的認證資訊並實行認證,一旦mon元件所在主機宕機,那麼整個叢集將不可用;有點類似k8s裡的etcd;所以為實現冗餘和高可用性,通常在叢集我們部署大於1的奇數個mon(因為它使用Paxos協定,為防止網路分割區等原因,保證服務的正常可用);manager元件主要負責跟蹤執行時指標和Ceph叢集的當前狀態,包括儲存利用率,當前效能指標和系統負載等,Ceph叢集資訊,包括基於web的Ceph管理器儀表板和REST API。高可用性通常需要至少兩個mgr元件。OSD元件是儲存資料,處理資料複製、恢復、再平衡,並提供一些監視資訊的元件;Ceph通過檢查其他Ceph OSD程序來監控和管理心跳;通常為了高可用和冗餘,至少需要3個ceph osd(即3塊硬碟,ceph為了每一個osd能夠被單獨使用和管理,每一個osd都會有一個單獨的守護行程ceph-osd來管理,即伺服器上有多少個osd,就會有多少個ceph-osd程序,一個ceph-osd程序就對應一個osd,一個osd就對應一塊磁碟裝置);MDS是ceph後設資料服務元件,主要實現分散式檔案系統的控制層面,資料和後設資料的存取依然由RADOS負責,即使用者使用cephfs檔案系統存取資料,使用者儲存的檔案的後設資料該怎麼存放、怎麼管理等都由MDS元件負責;當然如果我們沒有使用cephfs檔案系統的必要,對應mds元件也可以不用部署;所以mds元件不是必須元件;
Ceph資料抽象介面(使用者端中間層)
Ceph儲存叢集提供了基礎的物件資料儲存服務,使用者端可基於RADOS協定和librados API直接與儲存系統互動進行物件資料存取; librados提供了存取RADOS儲存叢集支援非同步通訊的API介面,支援對叢集中物件資料的直接並行存取,使用者可通過支援的程式語言開發自定義使用者端程式通過RADOS協定與儲存系統進行互動;使用者端應用程式必須與librados繫結方可連線到RADOS儲存叢集,因此,使用者必須事先安裝librados及其依賴後才能編寫使用librados的應用程式; librados API本身是用C ++編寫的,它額外支援C、Python、Java和PHP等開發介面;當然,並非所有使用者都有能力自定義開發介面以接入RADOS儲存叢集的需要,為此,Ceph也原生提供了幾個較高階別的使用者端介面,它們分別是RADOS GateWay(RGW)、ReliableBlock Device(RBD)和MDS(MetaData Server),分別為使用者提供RESTful、塊和POSIX檔案系統介面;
Ceph檔案系統
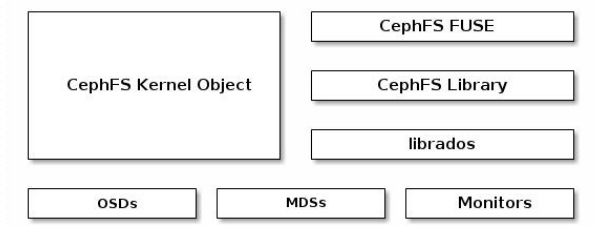
不同於傳統檔案系統的地方是,CephFS MDS在設計的初衷之一即高度可延伸的能力,其實現機制中,資料由使用者端以分散式方式通過多路OSD直接儲存於RADOS系統,而後設資料則由MDS組織管理後仍然儲存於RADOS系統之上; MDS僅是實現了分散式檔案系統的控制平面,資料和後設資料的存取依然由RADOS負責;CephFS依賴於獨立執行的守護行程ceph-mds向用戶端提供服務;
Ceph塊裝置

儲存領域中,「塊(block)」是進行資料存取的主要形式,塊裝置也於是成為了主流的裝置形式,因此,RBD虛擬塊裝置也就成了Ceph之上廣為人知及非常受歡迎的存取介面;RBD的服務介面無須依賴於特定的守護行程,只要使用者端主機有對應核心模組librbd,就可以通過ceph RBD 介面使用;
Ceph物件閘道器
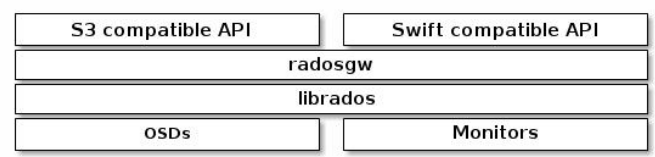
Ceph物件閘道器是一個建立在librados之上的物件儲存介面為應用程式提供的Ceph儲存叢集的RESTful閘道器。Ceph物件儲存支援兩個介面s3和Swift;Ceph物件儲存使用Ceph物件閘道器守護行程(radosgw),它是一個HTTP伺服器,用於與Ceph儲存叢集互動;RGW依賴於在RADOS叢集基礎上獨立執行的守護行程(ceph-radosgw)基於http或https協定提供相關的API服務,不過,通常僅在需要以REST物件形式存取資料時才部署RGW;
管理節點(admin host)
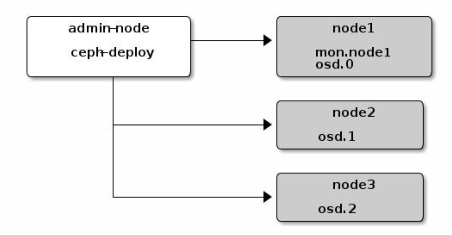
Ceph的常用管理介面是一組命令列工具程式,例如rados、ceph、rbd等命令,管理員可以從某個特定的MON節點執行管理操作,但也有人更傾向於使用專用的管理節點;事實上,專用的管理節點有助於在Ceph相關的程式升級或硬體維護期間為管理員提供一個完整的、獨立的並隔離於儲存叢集之外的操作環境,從而避免因重啟或意外中斷而導致維護操作異常中斷;
儲存池、PG(Placement Group)和OSD(Object Store Device)之間的關係
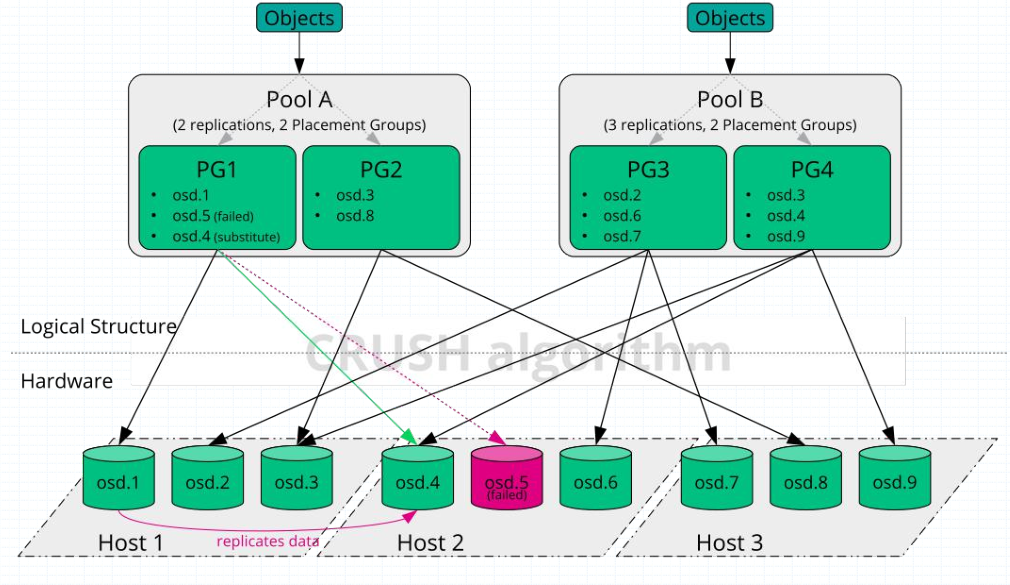
提示:儲存在Ceph儲存系統之上的資料,都會先由Ceph將對應資料切分等額大小的物件資料,然後將這些資料儲存到對應的儲存池中;儲存池主要作用是向外界展示叢集的邏輯分割區;對於每個儲存池,我們可以定義一組規則,比如每個物件資料需要有多少個副本存在;PG是Placement Group的縮寫,歸置組;它是一個虛擬的概念,主要作用是用於將物件資料對映到osd上而存在的,物件資料具體通過那個pg存放在那個osd上,這個是根據ceph的crush演演算法動態對映的;我們可以理解為根據儲存池中PG的數量,結合一致性hash將物件資料動態對映至PG上,然後PG根據osd數量結合一致性hash動態對映到不同的磁碟上;我們在建立儲存池的時候就必須指定一定數量的PG;如上圖所示,我們將資料儲存到儲存池B中,那麼對應資料就會根據儲存池B中的規則進行儲存,即3個副本;在儲存池B中只有2個歸置組,兩個歸置組分別對應了不同的OSD;如果將資料儲存到PG3上,那麼對應資料就會在osd2\6\7分別儲存一份以做備份;如果將資料儲存到PG4上,這對應資料就會被分發到osd3\4\9上進行儲存;
File Store 和 Blue Store
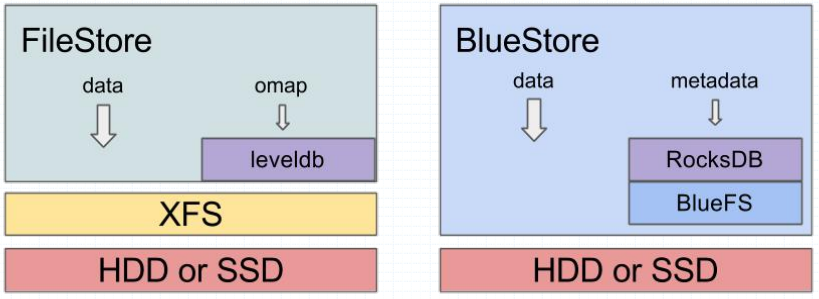
什麼是file store呢?file store是傳統ceph儲存物件的方法,它依賴於xfs檔案系統(ext4有bug和缺陷,會導致資料丟失,所以ceph只支援xfs上使用file store);通過上述的描述,我們知道ceph不管是什麼使用者端提交的物件資料,最終都會儲存到osd所在主機的硬碟上;那麼問題來了,osd所在主機的磁碟是怎麼被osd管理的呢?傳統ceph是將對應磁碟格式化分割區掛載在osd所在主機的檔案系統,被osd所在主機以一個目錄的形式表示;即使用者儲存的物件資料,最後會被存放為一個檔案的形式存放在osd所在主機的磁碟上;這也意味著我們需要存放檔案本身的後設資料和資料;除此之外物件本身也有資料和後設資料,那麼物件本身的資料和後設資料是怎麼存放的呢?file store是是將物件的後設資料存放在leveldb(早期ceph版本)中,資料存放在檔案系統的資料區;簡單講file store就是將物件的後設資料存放在leveldb中,資料存放在osd所在主機的檔案系統的資料區中,中間有檔案系統做轉換的過程;而blue store將osd所在主機的磁碟不格式化分割區,而是直接用裸裝置硬碟被osd識別和管理;在osd所在主機對應osd程序會將自己管理的磁碟中一小部分格式化為bluefs檔案系統,用於安裝使用rocksdb;即使用者端提交的物件資料,物件本身的後設資料會被存放在rocksdb中,資料會被直接存放在磁碟上(由osd程序直接管理資料格式等,不會存放為檔案);rocksdb為了管理它自己本身的資料持久化,它也會維護一個紀錄檔檔案,類似redis的aof;這樣一來blue store的方式儲存物件資料,在磁碟上就會存在三種資料,第一種是物件本身的資料,第二種是物件的後設資料,第三種就是rocksdb的紀錄檔檔案;ceph為了使儲存的資料更高效,它支援將blue store方式的三種資料分別存放不同的磁碟,如下圖

提示:如果是單塊硬碟,那沒得說三種資料直接存入到一塊磁碟上;如果是兩塊磁碟,我們可以將blue store的紀錄檔資料和物件後設資料存放在一個高效能的磁碟上,如nvme,ssd上,將物件資料存放在一個大的機械硬碟上;當然也可以將blue store的紀錄檔檔案存放在高效能磁碟上,物件的後設資料和資料存放在機械硬碟上;如果有三塊硬碟,我們可以將blue store的紀錄檔資料存放在高效能磁碟上,比如512M的nvme的磁碟;使用1G或2G的ssd來儲存物件的後設資料;用機械硬碟來儲存物件資料;