從 Cloud-Native Relational DB 看資料庫設計
論文內容:Amazon Aurora: Design Considerations for HighThroughput Cloud-Native Relational Databases
裡面介紹了一種雲原生的關係型資料庫 Aurora 的體系結構,以及導致該體系結構的設計考慮因素。我覺得和普通的傳統 mysql 的資料庫架構模型,最顯著的不同是將 redo processing(重做處理)推到一個多租戶向外擴充套件的儲存服務,這是為Aurora專門構建的。文中描述這樣做如何不僅減少網路流量,而且還允許快速崩潰恢復,在不丟失資料的情況下故障轉移到副本,以及容錯、自修復儲存。
首先我們先從簡單的傳統資料庫如何一步一步的演變到 Aurora 的架構的。
一、EBS的由來和Aurora的背景歷史
在雲服務中,其實伺服器最早的時候就是一個作業系統再掛載一個模擬的硬碟 disk volum。類似於這樣下面的結構,這樣做是避免了單機的故障,因為如果硬碟是直接在雲伺服器上的,如果此機器故障,那麼直接全部資料不可用,並且就算有資料備份機制,在故障和恢復期間也會導致缺失一段時間的資料。
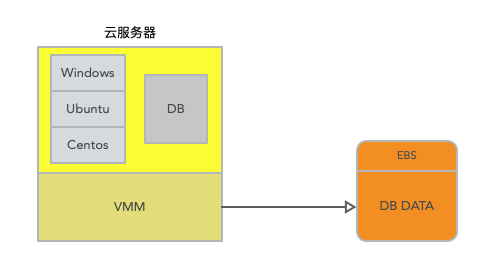
在雲服務中掛載一個硬碟,並且同時也是容錯的且支援持久化儲存的服務,這個服務就是EBS。EBS全稱是Elastic Block Store。從雲伺服器範例來看,EBS就是一個硬碟,你可以像一個普通的硬碟一樣去格式化它,就像一個類似於ext3格式的檔案系統或者任何其他你喜歡的Linux檔案系統。但是在實現上,EBS底層是一對互為副本的儲存伺服器。隨著EBS的推出,你可以租用一個EBS volume。一個EBS volume看起來就像是一個普通的硬碟一樣,但卻是由一對互為副本EBS伺服器實現,每個EBS伺服器本地有一個硬碟。所以,現在你執行了一個資料庫,相應的EC2範例將一個EBS volume掛載成自己的硬碟。當資料庫執行寫磁碟操作時,資料會通過網路送到EBS伺服器。
但是明顯的,單單一塊 EBS 是不足以提供令人滿意的資料一致性,和故障恢復容錯,所以在 EBS 中都是使用 chain Replication(鏈式複製)來保證一致性的,具體的可以看上一期的關於 zookeeper 的文章,裡面有詳細的描述。
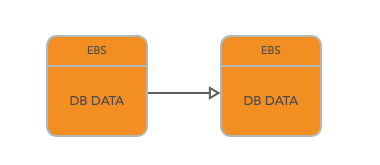
這兩個EBS伺服器會使用Chain Replication 進行復制。所以寫請求首先會寫到第一個EBS伺服器,之後寫到第二個EBS伺服器,然後從第二個EBS伺服器,EC2範例可以得到回覆。當讀資料的時候,因為這是一個Chain Replication,EC2範例會從第二個EBS伺服器讀取資料。
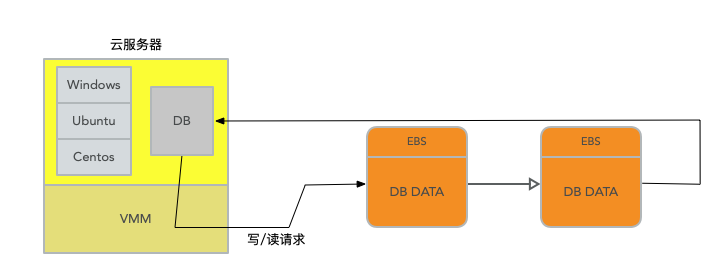
所以現在,執行在EC2範例上的資料庫有了可用性。因為現在有了一個儲存系統可以在伺服器宕機之後,仍然能持有資料。如果資料庫所在的伺服器掛了,你可以啟動另一個EC2範例,併為其掛載同一個EBS volume,再啟動資料庫。新的資料庫可以看到所有前一個資料庫留下來的資料,就像你把硬碟從一個機器拔下來,再插入到另一個機器一樣。所以EBS非常適合需要長期儲存資料的場景,比如說資料庫。
儘管 EBS 做到了上層DB操作和資料底層的結構,用論文中的描述來說就是,儘管每個範例仍然包含傳統核心的大部分元件(查詢處理器、事務、鎖定、緩衝區快取、存取方法和復原管理),但一些功能(重做紀錄檔、持久儲存、崩潰恢復和備份/恢復)被解除安裝到儲存服務中,為這改進提供了基礎。
那麼,問題來了,這樣的架構有什麼問題嗎?它仍然有自己所存在的問題的。
- 第一,如果你在EBS上執行一個資料庫,那麼最終會有大量的資料通過網路來傳遞。論文的圖2中,就有對在一個Network Storage System之上執行資料庫所需要的大量寫請求的抱怨。所以,如果在EBS上執行了一個資料庫,會產生大量的網路流量。在論文中有暗示,除了網路的限制之外,還有CPU和儲存空間的限制。在Aurora論文中,花費了大量的精力來降低資料庫產生的網路負載,同時看起來相對來說不太關心CPU和儲存空間的消耗。所以也可以理解成他們認為網路負載更加重要。
- 另一個問題是,EBS的容錯性不是很好。出於效能的考慮,Amazon總是將EBS volume的兩個副本存放在同一個資料中心。所以,如果一個副本故障了,那沒問題,因為可以切換到另一個副本,但是如果整個資料中心掛了,那就沒轍了。很明顯,大部分客戶還是希望在資料中心故障之後,資料還是能保留的。資料中心故障有很多原因,或許網路連線斷了,或許資料中心著火了,或許整個建築斷電了。使用者總是希望至少有選擇的權利,在一整個資料中心掛了的時候,可以選擇花更多的錢,來保留住資料。 但是Amazon描述的卻是,EC2範例和兩個EBS副本都執行在一個AZ(Availability Zone)。
因為 chain replication 的結構導致瞭如果不放在同一個 AZ 分割區中,那麼效能會非常低,響應跨區了必定會請求時間增加。放在同一個 AZ 中,又會導致如果一個機房出現災害,資料庫的容錯幾乎為零。在此基礎上對儲存結構進行了改進,如下。
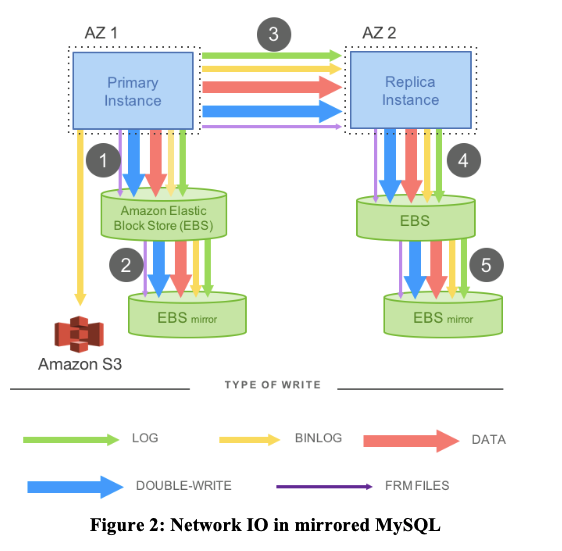
資料庫中事務的一致性保證是通過 log 來進行儲存的,也就是說即使 EBS 的儲存系統出現了落盤故障,那麼 DB 也能通過 log 的重做機制來恢復故障前的事務,並且決定是否提交或復原,這叫做故障可恢復事務(Crash Recoverable Transaction)。所以在 mysql 基礎上,結合Amazon自己的基礎設施,Amazon為其雲使用者開發了改進版的資料庫,叫做RDS(Relational Database Service)。儘管論文不怎麼討論RDS,但是論文中的圖2基本上是對RDS的描述。RDS是第一次嘗試將資料庫在多個AZ之間做複製,這樣就算整個資料中心掛了,你還是可以從另一個AZ重新獲得資料而不丟失任何寫操作。
對於RDS來說,有且僅有一個EC2範例作為資料庫。這個資料庫將它的data page和WAL Log儲存在EBS,而不是對應伺服器的本地硬碟。當資料庫執行了寫Log或者寫page操作時,這些寫請求實際上通過網路傳送到了EBS伺服器。所有這些伺服器都在一個AZ中。
每一次資料庫軟體執行一個寫操作,Amazon會自動的,對資料庫無感知的,將寫操作拷貝傳送到另一個資料中心的AZ中。從論文的圖2來看,可以發現這是另一個EC2範例,它的工作就是執行與主資料庫相同的操作。所以,AZ2的副資料庫會將這些寫操作拷貝AZ2對應的EBS伺服器。
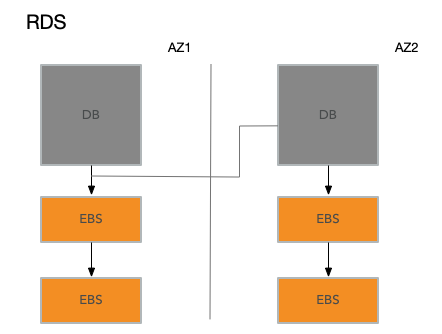
在RDS的架構中,也就是上圖中,每一次寫操作,例如資料庫追加紀錄檔或者寫磁碟的page,資料除了傳送給AZ1的兩個EBS副本之外,還需要通過網路傳送到位於AZ2的副資料庫。副資料庫接下來會將資料再傳送給AZ2的兩個獨立的EBS副本。之後,AZ2的副資料庫會將寫入成功的回覆返回給AZ1的主資料庫,主資料庫看到這個回覆之後,才會認為寫操作完成了。
RDS這種架構提供了更好的容錯性。因為現在在一個其他的AZ中,有了資料庫的一份完整的實時的拷貝。這個拷貝可以看到所有最新的寫請求。即使AZ1發生火災都燒掉了,你可以在AZ2的一個新的範例中繼續執行資料庫,而不丟失任何資料
二、將 redo log 放在儲存層完成
在論文中,上面描述的主備 MySQL 模型是不可取的,不僅因為資料是如何寫入的,還因為資料寫入的內容。首先,在圖一的步驟1、3和5是順序的和同步的,但是從庫的資料延遲是必然的,因為許多寫操作是順序的。如果出現網路抖動,那麼主備的資料延遲會被放大,因為即使是在非同步寫操作中,也必須等待最慢的操作,使系統受制於 MySQL 用於主從同步中的網路IO。從分散式系統的角度來看,上面的架構模型需要四個 EBS 都確認寫仲裁commit之後資料才得以保證,這樣容易受到失敗和異常值效能的影響。其次,OLTP應用程式的使用者操作會導致許多不同型別的寫操作,這些寫操作通常以多種方式表示相同的資訊——例如,為了防止儲存基礎設施中的分頁撕裂,會對雙寫緩衝區進行寫操作。如果是單單的紀錄檔同步,不同單機沒有辦法保證是可以共用記憶體的,那麼雙寫緩衝區進行寫操作類似的操作可能會導致資料短暫的不一致,雖然通過紀錄檔可以保證資料最終一致性。
所以 Aurora 提出的解決方案就是 Offloading Redo Processing to Storage,將 redo log 交給儲存層進行同步。
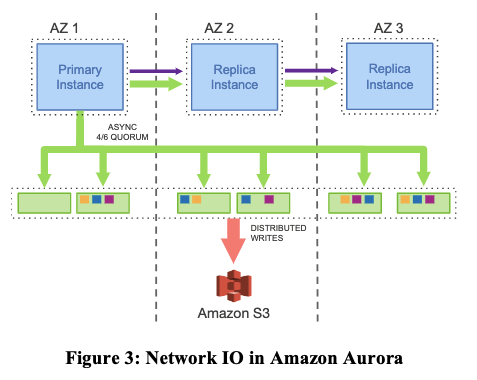
相比於上面的圖1,這裡簡化了在雲服務範例中生成 data page 也就是資料頁生成所需要的 Double-write 和 FRM files,只有 redo log 的儲存,不用考慮在每一層 EBS 中都通過網路io去同步除 log 之外的資料。沒有頁面從資料庫層寫入,沒有用於後臺寫入,沒有用於檢查點,也沒有用於快取取出。
從之前的簡單資料庫模型可以看出,每一條Log條目只有幾十個位元組那麼多,也就是存一下舊的數值,新的數值,所以Log條目非常小。然而,當一個資料庫要寫本地磁碟時,它更新的是data page,這裡的資料是巨大的,雖然在論文裡沒有說,但是我認為至少是8k位元組那麼多。所以,對於每一次事務,需要通過網路傳送多個8k位元組的page資料。而Aurora只是向更多的副本傳送了少量的Log條目。因為Log條目的大小比8K位元組小得多,所以在網路效能上這裡就勝出了。這是Aurora的第一個特點,只傳送Log條目(包括 binglog 和 redolog)。
EBS是一個非常通用的儲存系統,它模擬了磁碟,只需要支援讀寫資料塊。EBS不理解除了資料塊以外的其他任何事物。而這裡的儲存系統理解使用它的資料庫的Log。所以這裡,Aurora將通用的儲存去掉了,取而代之的是一個應用客製化的(Application-Specific)儲存系統。
另一件重要的事情是,Aurora並不需要6個副本都確認了寫入才能繼續執行操作。相應的,只要Quorum形成了,也就是任意4個副本確認寫入了,資料庫就可以繼續執行操作。所以,當我們想要執行寫入操作時,如果有一個AZ下線了,或者AZ的網路連線太慢了,或者只是伺服器響應太慢了,Aurora可以忽略最慢的兩個伺服器,或者已經掛掉的兩個伺服器,它只需要6個伺服器中的任意4個確認寫入,就可以繼續執行。所以這裡的Quorum是Aurora使用的另一個聰明的方法。通過這種方法,Aurora可以有更多的副本,更多的AZ,但是又不用付出大的效能代價,因為它永遠也不用等待所有的副本,只需要等待6個伺服器中最快的4個伺服器即可。
Quorum系統要求,任意你要傳送寫請求的W個伺服器,必須與任意接收讀請求的R個伺服器有重疊。這意味著,R加上W必須大於N( 至少滿足R + W = N + 1 ),這樣任意W個伺服器至少與任意R個伺服器有一個重合。
假設有三臺伺服器,並且每個伺服器只儲存一個物件:
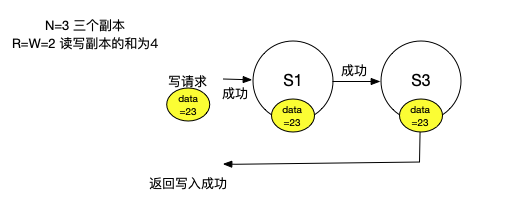
我們傳送了一個寫請求,想將我們的物件設定成23。為了能夠執行寫請求,我們需要至少將寫請求傳送到W個伺服器。我們假設在這個系統中,R和W都是2,N是3。為了執行一個寫請求,我們需要將新的數值23傳送到至少2個伺服器上。所以,或許我們的寫請求傳送到了S1和S3。所以,它們現在知道了我們物件的數值是23。
如果某人發起讀請求,讀請求會至少檢查R個伺服器。在這個設定中,R也是2。這裡的R個伺服器可能包含了並沒有看到之前寫請求的伺服器(S2),但同時也至少還需要一個其他伺服器來湊齊2個伺服器。這意味著,任何讀請求都至少會包含一個看到了之前寫請求的伺服器。
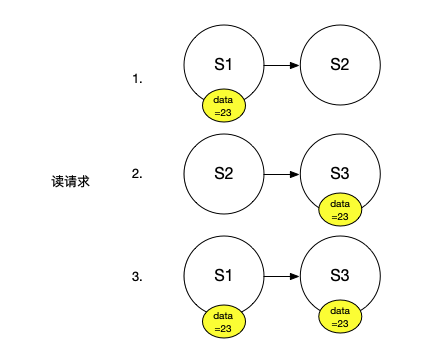
這是Quorum系統的要求,Read Quorum必須至少與Write Quorum有一個伺服器是重合的。所以任何讀請求可以從至少一個看見了之前寫請求的伺服器得到回覆。
這裡還有一個關鍵的點,使用者端讀請求可能會得到R個不同的結果,現在的問題是,使用者端如何知道從R個伺服器得到的R個結果中,哪一個是正確的呢?通過不同結果出現的次數來投票(Vote)在這是不起作用的,因為我們只能確保Read Quorum必須至少與Write Quorum有一個伺服器是重合的,這意味著使用者端向R個伺服器傳送讀請求,可能只有一個伺服器返回了正確的結果。對於一個有6個副本的系統,可能Read Quorum是4,那麼你可能得到了4個回覆,但是隻有一個與之前寫請求重合的伺服器能將正確的結果返回,所以這裡不能使用投票。在Quorum系統中使用的是版本號(Version)。所以,每一次執行寫請求,你需要將新的數值與一個增加的版本號繫結。之後,使用者端傳送讀請求,從Read Quorum得到了一些回覆,使用者端可以直接使用其中的最高版本號的數值。
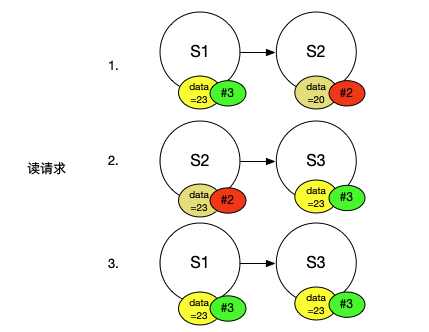
假設剛剛的例子中,S2有一箇舊的數值20。每一個伺服器都有一個版本號,S1和S3是版本3,因為它們看到了相同的寫請求,所以它們的版本號是相同的。同時我們假設沒有看到前一個寫請求的S2的版本號是2。之後使用者端從S2和S3讀取資料,得到了兩個不同結果,它們有著不同的版本號,使用者端會挑選版本號最高的結果。
相比Chain Replication,這裡的優勢是可以輕易的剔除暫時故障、失聯或者慢的伺服器。實際上,這裡是這樣工作的,當你執行寫請求時,你會將新的數值和對應的版本號給所有N個伺服器,但是隻會等待W個伺服器確認。類似的,對於讀請求,你可以將讀請求傳送給所有的伺服器,但是隻等待R個伺服器返回結果。因為你只需要等待R個伺服器,這意味著在最快的R個伺服器返回了之後,你就可以不用再等待慢伺服器或者故障伺服器超時。
除此之外,Quorum系統可以調整讀寫的效能。通過調整Read Quorum和Write Quorum,可以使得系統更好的支援讀請求或者寫請求。對於前面的例子,我們可以假設Write Quorum是3,每一個寫請求必須被所有的3個伺服器所確認。這樣的話,Read Quorum可以只是1。所以,如果你想要提升讀請求的效能,在一個3個伺服器的Quorum系統中,你可以設定R為1,W為3,這樣讀請求會快得多,因為它只需要等待一個伺服器的結果,但是代價是寫請求執行的比較慢。如果你想要提升寫請求的效能,可以設定R為3,W為1,這意味著可能只有1個伺服器有最新的數值,但是因為使用者端會諮詢3個伺服器,3個伺服器其中一個肯定包含了最新的數值。
當R為1,W為3時,寫請求就不再是容錯的了,同樣,當R為3,W為1時,讀請求不再是容錯的,因為對於讀請求,所有的伺服器都必須線上才能執行成功。所以在實際場景中,你不會想要這麼設定,你或許會與Aurora一樣,使用更多的伺服器,將N變大,然後再權衡Read Quorum和Write Quorum。
在 Aurora 的 Quorum 系統中,N=6,W=4,R=3。W等於4意味著,當一個AZ徹底下線時,剩下2個AZ中的4個伺服器仍然能完成寫請求。R等於3意味著,當一個AZ和一個其他AZ的伺服器下線時,剩下的3個伺服器仍然可以完成讀請求。當3個伺服器下線了,系統仍然支援讀請求,仍然可以返回當前的狀態,但是卻不能支援寫請求。所以,當3個伺服器掛了,現在的Quorum系統有足夠的伺服器支援讀請求,並據此重建更多的副本,但是在新的副本建立出來替代舊的副本之前,系統不能支援寫請求。同時,Quorum系統可以剔除暫時的慢副本。
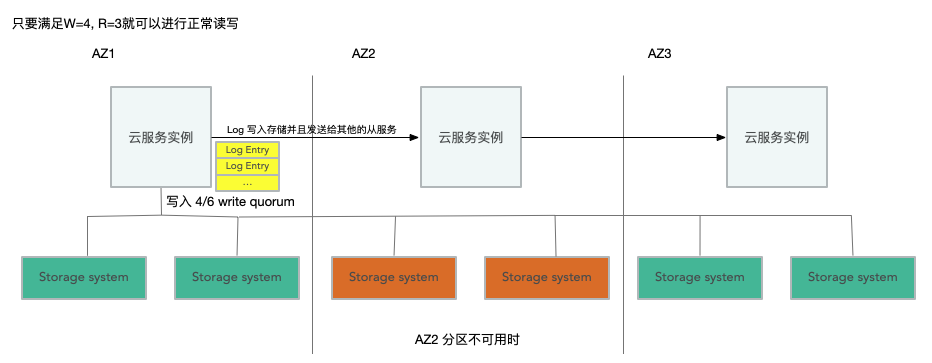
在論文中說明了這樣做帶來的提升,相對於傳統 mysql 映象,事務執行提高了了35倍。得到這樣的提升,文中解釋有幾點:
- 第一通過減少需要傳輸的資料,優化網路I/0,來獲得效能上的提示。如圖,對於 RDS 來說,儲存系統儲存的只需要 log entry 就行了,並不需要像 EBS 一樣每個節點都進行額外的 data page 讀寫。這是一個能正確理解 log 的儲存系統,具體怎麼實現的文中倒是沒有說
- 儲存系統中通過 write quorum 的優化,可以讓系統在提升系統容錯的同時,對寫操作也有一定的提升,可以讓其忽略最慢的寫入節點,響應儘可能快的完成返回
- 持久化的重做記錄應用程式發生在儲存層,連續地、非同步地並分佈在整個儲存系統中,也就是說只要有序列化的 log 紀錄檔,必定能生成 data page,必定能在 crash 之後重做
三、Aurora 的讀寫記憶體
Aurora中的寫請求並不是像一個經典的Quorum系統一樣直接更新資料。對於Aurora來說,它的寫請求從來不會覆蓋任何資料,它的寫請求只會在當前Log中追加條目(Append Entries)。所以,Aurora使用Quorum只是在資料庫執行事務並行出新的Log記錄時,確保Log記錄至少出現在4個儲存伺服器上,之後才能提交事務。所以,Aurora 的Write Quorum的實際意義是,每個新的Log記錄必須至少追加在4個儲存伺服器中,之後才可以認為寫請求完成了。當Aurora執行到事務的結束,並且在回覆給使用者端說事務已經提交之前,Aurora必須等待Write Quorum的確認,也就是4個儲存伺服器的確認,組成事務的每一條Log都成功寫入了。
這裡的儲存伺服器接收Log條目,這是它們看到的寫請求。它們並沒有從資料庫伺服器獲得到新的data page,它們得到的只是用來描述data page更新的Log條目。
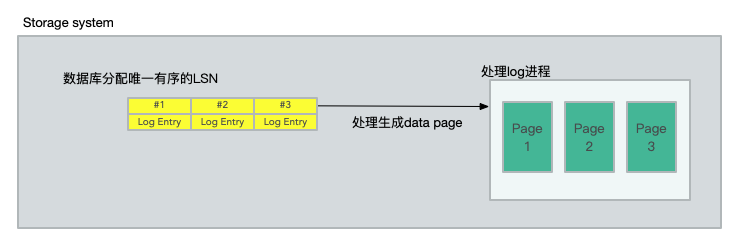
每個事務生成自己的重做紀錄檔記錄。資料庫為每條紀錄檔記錄分配一個唯一的有序LSN,但有一個約束,即LSN分配的值不能大於當前 VDL 和一個稱為LSN分配限制(LAL)的常數(當前設定為1000萬)的總和。這個限制可以確保資料庫不會比儲存系統超前太多,並在儲存或網路無法跟上的情況下,抑制傳入的寫操作。
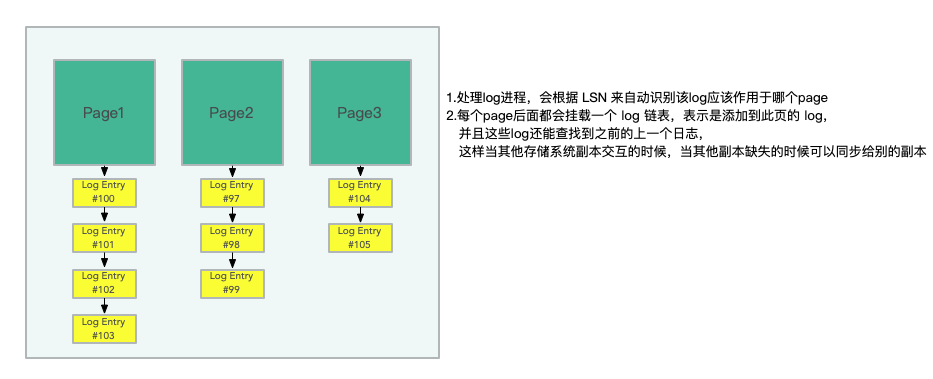
在內部實際上也是類似於髒寫,當一個 log 的 LSN 進行共識演演算法儲存在大多數節點上後,就可以將此紀錄檔應用到 page cache 上了。這個紀錄檔點稱之為 Consistency Point LSNs.(CPL)
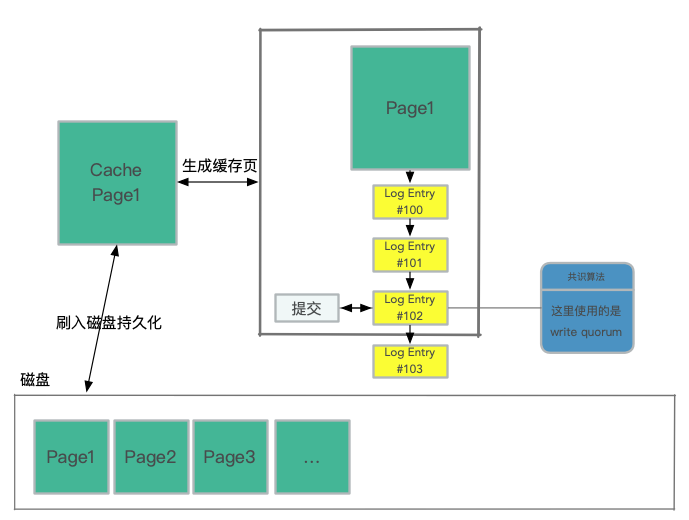
這裡的刷入磁碟持久化是非同步執行的,cache page 就是最新建立的 page,所有新增的紀錄檔條目都會找到對應的 page 來生成對應的最新的 page,哪怕是當系統持久化page之前儲存系統 crash 了,它也能依據 log 來自動恢復 page。這裡稱儲存系統中持久化的最大的 LSN 為 Volume Durable LSN(VDL),在圖中就是 #102 。
在提交 commit 時,事務提交是非同步完成。當用戶端提交事務時,處理提交請求的執行緒通過將其「commit LSN」記錄為等待提交的單獨事務列表的一部分,從而將事務放到一邊,然後繼續執行其他工作。與WAL協定等價的協定基於完成提交,當且僅當最新的VDL大於或等於事務的提交LSN。隨著VDL的增加,資料庫會識別等待提交的符合條件的事務,並使用專用執行緒向等待的使用者端傳送提交確認。工作執行緒不會暫停提交,它們只是拉出其他掛起的請求並繼續處理。
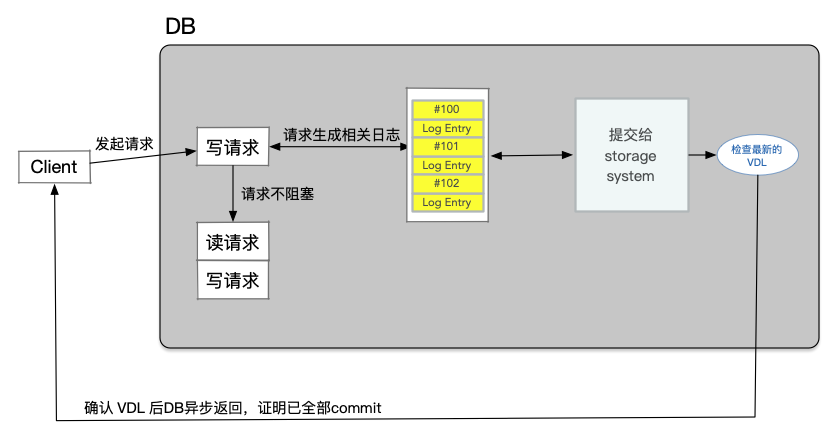
在資料庫伺服器寫入的是Log條目,但是讀取的是page。這也是與Quorum系統不一樣的地方。Quorum系統通常讀寫的資料都是相同的。除此之外,在一個普通的操作中,資料庫伺服器可以避免觸發Quorum Read。資料庫伺服器會記錄每一個儲存伺服器接收了多少Log。所以,首先,Log條目都有類似12345這樣的編號,當資料庫伺服器傳送一條新的Log條目給所有的儲存伺服器,儲存伺服器接收到它們會返回說,我收到了第79號和之前所有的Log。資料庫伺服器會記錄這裡的數位,或者說記錄每個儲存伺服器收到的最高連續的Log條目號。這樣的話,當一個資料庫伺服器需要執行讀操作,它只會挑選擁有最新Log的儲存伺服器,然後只向那個伺服器傳送讀取page的請求。所以,資料庫伺服器執行了Quorum Write,但是卻沒有執行Quorum Read。因為它知道哪些儲存伺服器有最新的資料,然後可以直接從其中一個讀取資料。這樣的代價小得多,因為這裡唯讀了一個副本,而不用讀取Quorum數量的副本。
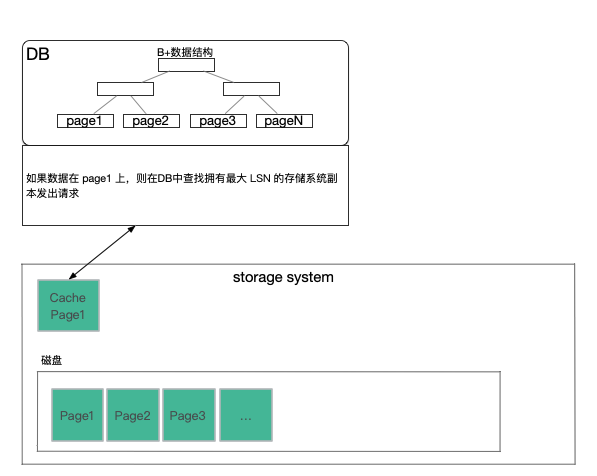
假設資料庫伺服器執行在某個EC2範例,如果相應的硬體故障了,資料庫伺服器也會隨之崩潰。在Amazon的基礎設施有一些監控系統可以檢測到Aurora資料庫伺服器崩潰,之後Amazon會自動的啟動一個EC2範例,在這個範例上啟動資料庫軟體,並告訴新啟動的資料庫:你的資料存放在那6個儲存伺服器中,請清除儲存在這些副本中的任何未完成的事務,之後再繼續工作。這時,Aurora會使用Quorum的邏輯來執行讀請求。因為之前資料庫伺服器故障的時候,它極有可能處於執行某些事務的中間過程。所以當它故障了,它的狀態極有可能是它完成並提交了一些事務,並且相應的Log條目存放於Quorum系統。同時,它還在執行某些其他事務的過程中,這些事務也有一部分Log條目存放在Quorum系統中,但是因為資料庫伺服器在執行這些事務的過程中崩潰了,這些事務永遠也不可能完成。對於這些未完成的事務,我們可能會有這樣一種場景,第一個副本有第101個Log條目,第二個副本有第102個Log條目,第三個副本有第104個Log條目,但是沒有一個副本持有第103個Log條目。
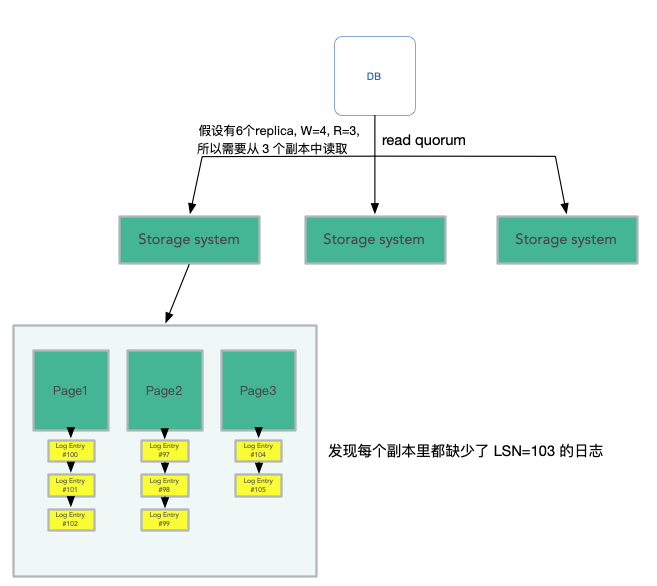
所以故障之後,新的資料庫伺服器需要恢復,它會執行Quorum Read,找到第一個缺失的Log序號,所以會找到 LSN=103 的紀錄檔缺失了。
這時,資料庫伺服器會給所有的儲存伺服器傳送訊息說:請丟棄103及之後的所有Log條目。103及之後的Log條目必然不會包含已提交的事務,因為我們知道只有當一個事務的所有Log條目存在於Write Quorum時,這個事務才會被commit,所以對於已經commit的事務我們肯定可以看到相應的Log。這裡我們只會丟棄未commit事務對應的Log條目。
三、資料分片(Protection Group)
為了能支援超過10TB資料的大型資料庫。Amazon的做法是將資料庫的資料,分割儲存到多組儲存伺服器上,假設每一組都是6個副本,分割出來的每一份資料是10GB。所以,如果一個資料庫需要20GB的資料,那麼這個資料庫會使用2個PG(Protection Group),其中一半的10GB資料在一個PG中,包含了6個儲存伺服器作為副本,另一半的10GB資料儲存在另一個PG中,這個PG可能包含了不同的6個儲存伺服器作為副本。
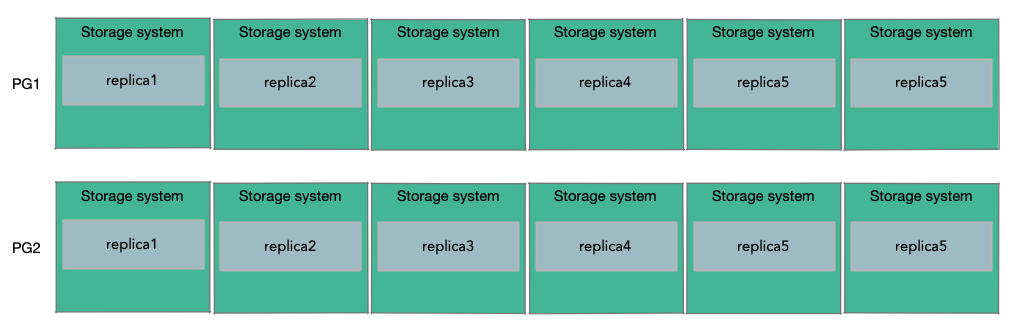
Sharding之後,Log該如何處理就不是那麼直觀了。如果有多個Protection Group,該如何分割Log呢?答案是,當Aurora需要傳送一個Log條目時,它會檢視Log所修改的資料,並找到儲存了這個資料的Protection Group,並把Log條目只傳送給這個Protection Group對應的6個儲存伺服器。這意味著,每個Protection Group只儲存了部分data page和所有與這些data page關聯的Log條目。所以每個Protection Group儲存了所有data page的一個子集,以及這些data page相關的Log條目。
如果其中一個儲存伺服器掛了,我們期望儘可能快的用一個新的副本替代它。因為如果4個副本掛了,我們將不再擁有Read Quorum,我們也因此不能建立一個新的副本。所以我們想要在一個副本掛了以後,儘可能快的生成一個新的副本。表面上看,每個儲存伺服器存放了某個資料庫的某個某個Protection Group對應的10GB資料,但實際上每個儲存伺服器可能有1-2塊幾TB的磁碟,上面儲存了屬於數百個Aurora範例的10GB資料塊。所以在儲存伺服器上,可能總共會有10TB的資料,當它故障時,它帶走的不僅是一個資料庫的10GB資料,同時也帶走了其他數百個資料庫的10GB資料。所以生成的新副本,不是僅僅要恢復一個資料庫的10GB資料,而是要恢復儲存在原來伺服器上的整個10TB的資料。
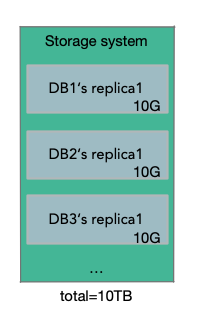
當節點副本掛了的情況,這裡應該避免的是通過一個儲存服務節點,去拷貝所有的資料到新的副本節點上。
對於所有的Protection Group對應的資料塊,都會有類似的副本。這種模式下,如果一個儲存伺服器掛了,假設上面有100個資料塊,現在的替換策略是:找到100個不同的儲存伺服器,其中的每一個會被分配一個資料塊,也就是說這100個儲存伺服器,每一個都會加入到一個新的Protection Group中。所以相當於,每一個儲存伺服器只需要負責恢復10GB的資料。所以在建立新副本的時候,我們有了100個儲存伺服器。
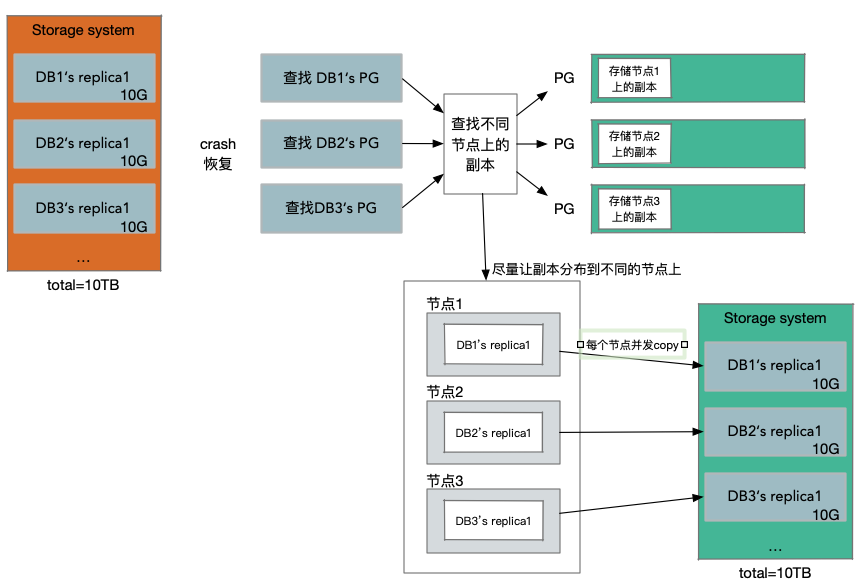
假設有足夠多的伺服器,這裡的伺服器大概率不會有重合,同時假設我們有足夠的頻寬,現在我們可以以100的並行,並行的拷貝1TB的資料,這隻需要10秒左右。如果只在兩個伺服器之間拷貝,正常拷貝1TB資料需要1000秒左右。
這就是Aurora使用的副本恢復策略,它意味著,如果一個伺服器掛了,它可以並行的,快速的在數百臺伺服器上恢復。如果大量的伺服器掛了,可能不能正常工作,但是如果只有一個伺服器掛了,Aurora可以非常快的重新生成副本。