從滑動視窗到YOLO、Transformer:目標檢測的技術革新
本文全面回顧了目標檢測技術的演進歷程,從早期的滑動視窗和特徵提取方法到深度學習的興起,再到YOLO系列和Transformer的創新應用。通過對各階段技術的深入分析,展現了計算機視覺領域的發展趨勢和未來潛力。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
一、早期方法:滑動視窗和特徵提取
在深度學習方法主導目標檢測之前,滑動視窗和特徵提取技術在這一領域中發揮了關鍵作用。通過理解這些技術的基本原理和實現方式,我們可以更好地把握目標檢測技術的演進脈絡。
滑動視窗機制
工作原理
- 基本概念: 滑動視窗是一種在整個影象區域內移動的固定大小的視窗。它逐步掃描影象,提取視窗內的畫素資訊用於目標檢測。
- 程式碼範例: 展示如何在Python中實現基礎的滑動視窗機制。
import cv2
import numpy as np
def sliding_window(image, stepSize, windowSize):
# 遍歷影象中的每個視窗
for y in range(0, image.shape[0], stepSize):
for x in range(0, image.shape[1], stepSize):
# 提取當前視窗
yield (x, y, image[y:y + windowSize[1], x:x + windowSize[0]])
# 範例:在一張影象上應用滑動視窗
image = cv2.imread('example.jpg')
winW, winH = 64, 64
for (x, y, window) in sliding_window(image, stepSize=8, windowSize=(winW, winH)):
# 在此處可以進行目標檢測處理
pass
特徵提取方法
HOG(Histogram of Oriented Gradients)
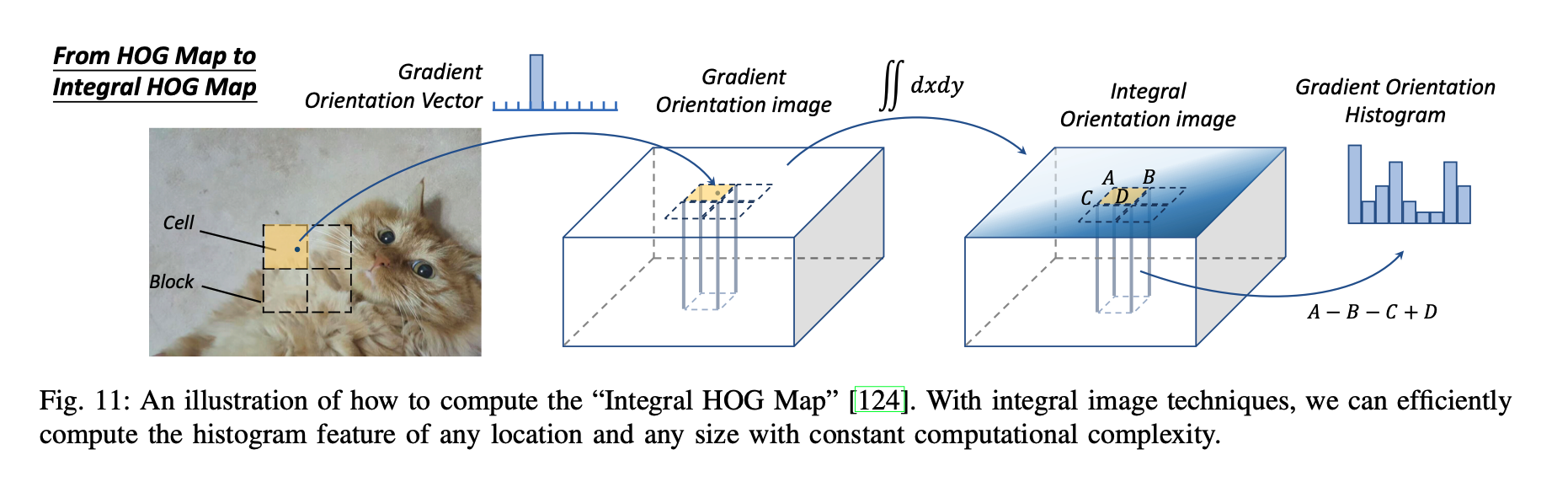
- 原理概述: HOG特徵描述器通過計算影象區域性區域內梯度的方向和大小來提取特徵,這些特徵對於描述物件的形狀非常有效。
- 程式碼實現: 展示如何使用Python和OpenCV庫提取HOG特徵。
from skimage.feature import hog
from skimage import data, exposure
# 讀取影象
image = data.astronaut()
# 計算HOG特徵和HOG影象
fd, hog_image = hog(image, orientations=8, pixels_per_cell=(16, 16),
cells_per_block=(1, 1), visualize=True, channel_axis=-1)
# 顯示HOG影象
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10))
cv2.imshow('HOG Image', hog_image_rescaled)
cv2.waitKey(0)
SIFT(Scale-Invariant Feature Transform)
- 工作原理: SIFT通過檢測和描述影象中的關鍵點來實現對影象特徵的尺度不變描述,使得它在物體識別和影象匹配中非常有效。
- 程式碼範例: 展示如何使用Python和OpenCV實現SIFT特徵檢測和描述。
import cv2
# 讀取影象
image = cv2.imread('example.jpg')
# 初始化SIFT檢測器
sift = cv2.SIFT_create()
# 檢測SIFT特徵
keypoints, descriptors = sift.detectAndCompute(image, None)
# 在影象上繪製關鍵點
sift_image = cv2.drawKeypoints(image, keypoints, None)
# 顯示結果
cv2.imshow('SIFT Features', sift_image)
cv2.waitKey(0)
通過這些程式碼範例,我們不僅可以理解滑動視窗和特徵提取技術的理論基礎,還可以直觀地看到它們在實際應用中的表現。這些早期方法雖然在當今深度學習的背景下顯得簡單,但它們在目標檢測技術的發展歷程中扮演了不可或缺的角色。
二、深度學習的興起:CNN在目標檢測中的應用
深度學習,尤其是折積神經網路(CNN)在目標檢測領域的應用,標誌著這一領域的一次革命。CNN的引入不僅顯著提高了檢測的準確率,而且在處理速度和效率上也取得了質的飛躍。
CNN的基本概念
折積層
- 原理概述: 折積層通過學習濾波器(或稱折積核)來提取影象的區域性特徵。這些特徵對於理解影象的內容至關重要。
- 程式碼範例: 使用Python和PyTorch實現基礎的折積層。
import torch
import torch.nn as nn
# 定義一個簡單的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
def forward(self, x):
x = nn.functional.relu(self.conv1(x))
return x
# 範例:初始化模型並應用於一個隨機影象
model = SimpleCNN()
input_image = torch.rand(1, 3, 32, 32) # 隨機生成一個影象
output = model(input_image)
R-CNN及其變種
R-CNN(Regions with CNN features)
- 架構解析: R-CNN通過從影象中提取一系列候選區域(通常使用選擇性搜尋演演算法),然後獨立地對每個區域執行CNN來提取特徵,最後對這些特徵使用分類器(如SVM)進行分類。
- 程式碼範例: 展示R-CNN的基本思路。
import torchvision.models as models
import torchvision.transforms as transforms
# 載入預訓練的CNN模型
cnn_model = models.vgg16(pretrained=True).features
# 假設region_proposals是一個函數,它返回影象中的候選區域
for region in region_proposals(input_image):
# 將每個區域轉換為CNN模型需要的尺寸和型別
region_transformed = transforms.functional.resize(region, (224, 224))
region_transformed = transforms.functional.to_tensor(region_transformed)
# 提取特徵
feature_vector = cnn_model(region_transformed.unsqueeze(0))
# 在這裡可以使用一個分類器來處理特徵向量
Fast R-CNN
- 改進點: Fast R-CNN通過引入ROI(Region of Interest)Pooling層來提高效率,該層允許網路在單個傳遞中對整個影象進行操作,同時還能處理不同大小的候選區域。
- 程式碼實現: 展示如何使用PyTorch實現Fast R-CNN。
import torch
from torchvision.ops import RoIPool
# 假設cnn_features是CNN對整個影象提取的特徵
cnn_features = cnn_model(input_image)
# 假設rois是一個張量,其中包含候選區域的座標
rois = torch.tensor([[0, x1, y1, x2, y2], ...]) # 第一個元素是影象索引,後四個是座標
# 建立一個ROI池化層
roi_pool = RoIPool(output_size=(7, 7), spatial_scale=1.0)
# 應用ROI池化
pooled_features = roi_pool(cnn_features, rois)
Faster R-CNN
- 創新之處: Faster R-CNN在Fast R-CNN的基礎上進一步創新,通過引入區域提案網路(RPN),使得候選區域的生成過程也能通過學習得到優化。
- **程式碼概
述:** 展示Faster R-CNN中RPN的基本工作原理。
class RPN(nn.Module):
def __init__(self, anchor_generator, head):
super(RPN, self).__init__()
self.anchor_generator = anchor_generator
self.head = head
def forward(self, features, image_shapes):
# 生成錨點
anchors = self.anchor_generator(features, image_shapes)
# 對每個錨點應用頭網路,得到區域提案
objectness, pred_bbox_deltas = self.head(features)
proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)
return proposals
通過這一部分的內容,我們不僅能夠深入理解深度學習在目標檢測中的應用,特別是CNN及其衍生模型的設計理念和實現方式,而且可以通過程式碼範例直觀地看到這些技術在實踐中的應用。這些知識對於理解目標檢測技術的現代發展至關重要。
三、現代方法:YOLO系列
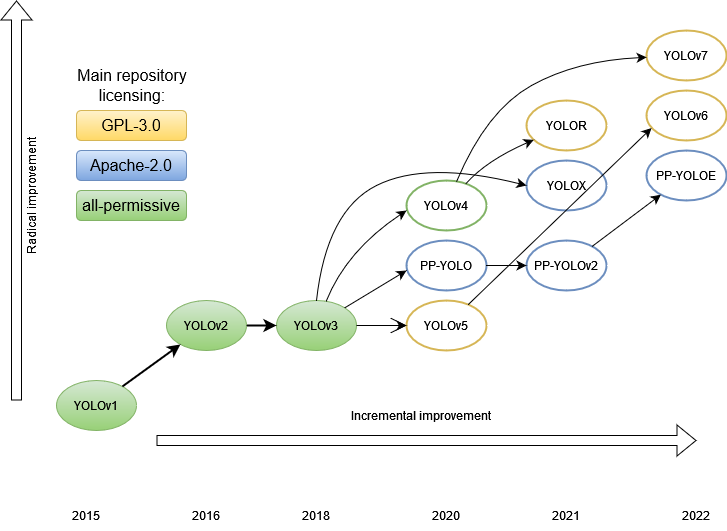
隨著目標檢測技術的不斷進步,YOLO(You Only Look Once)系列作為現代目標檢測方法的代表,憑藉其獨特的設計理念和優越的效能,在實時目標檢測領域中取得了顯著的成就。
YOLO的設計哲學
YOLO的基本原理
- 核心思想: YOLO將目標檢測任務視為一個單一的迴歸問題,直接從影象畫素到邊界框座標和類別概率的對映。這種設計使得YOLO能夠在單次模型執行中完成整個檢測流程,大大提高了處理速度。
- 架構簡介: YOLO使用單個折積神經網路同時預測多個邊界框和類別概率,將整個檢測流程簡化為一個步驟。
YOLO的創新點
- 統一化框架: YOLO創新性地將多個檢測任務合併為一個統一的框架,顯著提高了速度和效率。
- 實時效能: 由於其獨特的設計,YOLO可以在保持高精度的同時實現接近實時的檢測速度,特別適合需要快速響應的應用場景。
YOLO系列的發展
YOLOv1
- 架構特點: YOLOv1通過將影象劃分為網格,並在每個網格中預測多個邊界框和置信度,從而實現快速且有效的檢測。
- 程式碼概覽: 展示YOLOv1模型的基本架構。
import torch.nn as nn
class YOLOv1(nn.Module):
def __init__(self, grid_size=7, num_boxes=2, num_classes=20):
super(YOLOv1, self).__init__()
# 網路層定義
# ...
def forward(self, x):
# 網路前向傳播
# ...
return x
# 範例化模型
model = YOLOv1()
YOLOv2 和 YOLOv3
- 改進點: YOLOv2和YOLOv3進一步優化了模型架構,引入了錨點機制和多尺度檢測,提高了模型對不同大小目標的檢測能力。
- 程式碼概覽: 展示YOLOv2或YOLOv3模型的錨點機制。
# YOLOv2和YOLOv3使用預定義的錨點來改進邊界框的預測
anchors = [[116, 90], [156, 198], [373, 326]] # 範例錨點尺寸
YOLOv4 和 YOLOv5
- 最新進展: YOLOv4和YOLOv5在保持YOLO系列高速度的特點基礎上,進一步提高了檢測精度和魯棒性。YOLOv5特別注重於易用性和訓練效率的提升。
- 程式碼概覽: 介紹YOLOv5的模型載入和使用。
import torch
# 載入預訓練的YOLOv5模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# 應用模型進行目標檢測
imgs = ['path/to/image.jpg'] # 影象路徑
results = model(imgs)
YOLO系列的發展不僅展示了目標檢測技術的前沿動態,也為實時視訊分析、無人駕駛汽車等多個應用領域提供了強大的技術支援。通過對YOLO系列的深入理解,可以更全面地掌握現代目標檢測技術的發展趨勢和應用場景。
四、Transformer在目標檢測中的應用
近年來,Transformer模型原本設計用於自然語言處理任務,但其獨特的結構和工作機制也被證明在計算機視覺領域,特別是目標檢測中,具有巨大的潛力。Transformer在目標檢測中的應用開啟了一個新的研究方向,為這一領域帶來了新的視角和方法。
Transformer的基礎知識
自注意力機制
- 核心原理: Transformer的核心是自注意力機制,它允許模型在處理一個元素時,同時考慮到輸入序列中的所有其他元素,從而捕捉全域性依賴關係。
- 在視覺任務中的應用: 在目標檢測中,這意味著模型可以同時考慮影象中所有區域的資訊,有助於更好地理解場景和物件之間的關係。
Transformer的架構
- 編碼器和解碼器: 標準的Transformer模型包含編碼器和解碼器,每個部分都由多個相同的層組成,每層包含自注意力機制和前饋神經網路。
Transformer在目標檢測中的應用
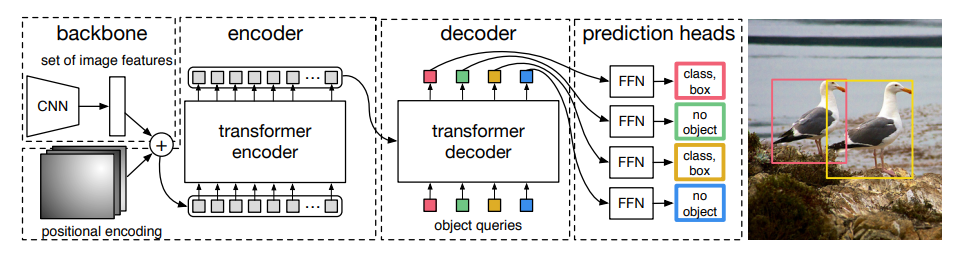
DETR(Detection Transformer)
- 模型介紹: DETR是將Transformer應用於目標檢測的先驅之作。它使用一個標準的Transformer編碼器-解碼器架構,並在輸出端引入了特定數量的學習物件查詢,以直接預測目標的類別和邊界框。
- 程式碼概覽: 展示如何使用DETR進行目標檢測。
import torch
from models.detr import DETR
# 初始化DETR模型
model = DETR(num_classes=91, num_queries=100)
model.eval()
# 假設input_image是預處理過的影象張量
with torch.no_grad():
outputs = model(input_image)
# outputs包含預測的類別和邊界框
Transformer與CNN的結合
- 結合方式: 一些研究開始探索將Transformer與傳統的CNN結合,以利用CNN在特徵提取方面的優勢,同時藉助Transformer處理長距離依賴的能力。
- 範例介紹: 例如,一些方法在CNN提取的特徵圖上應用Transformer模組,以增強對影象中不同區域間相互作用的理解。
前沿研究和趨勢
- 研究動態: 目前,許多研究團隊正在探索如何更有效地將Transformer應用於目標檢測,包括改進其在處理不同尺度物件上的能力,以及提高其訓練和推理效率。
- 潛在挑戰: 儘管Transformer在目標檢測中顯示出巨大潛力,但如何平衡其計算複雜性和效能,以及如何進一步改進其對小尺寸目標的檢測能力,仍然是當前的研究熱點。
通過對Transformer在目標檢測中的應用的深入瞭解,我們不僅能夠把握這一新興領域的最新發展動態,還能從中窺見計算機視覺領域未來可能的發展方向。Transformer的這些創新應用為目標檢測技術的發展提供了新的動力和靈感。
總結
本篇文章全面回顧了目標檢測技術的演變歷程,從早期的滑動視窗和特徵提取方法,到深度學習的興起,尤其是CNN在目標檢測中的革命性應用,再到近年來YOLO系列和Transformer在這一領域的創新實踐。這一旅程不僅展示了目標檢測技術的發展脈絡,還反映了計算機視覺領域不斷進步的動力和方向。
技術領域的一個獨特洞見是,目標檢測的發展與計算能力的提升、資料可用性的增加、以及演演算法創新緊密相關。從早期依賴手工特徵的方法,到今天的深度學習和Transformer,我們看到了技術演進與時代背景的深度融合。
-
計算能力的提升: 早期目標檢測技術的侷限性在很大程度上源於有限的計算資源。隨著計算能力的增強,複雜且計算密集的模型(如深度折積網路)變得可行,這直接推動了目標檢測效能的飛躍。
-
資料的重要性: 大量高質量標註資料的可用性,尤其是公開資料集如ImageNet、COCO等,為訓練更精確的模型提供了基礎。資料的多樣性和豐富性是深度學習方法成功的關鍵。
-
演演算法的創新: 從R-CNN到YOLO,再到Transformer,每一次重大的技術飛躍都伴隨著演演算法上的創新。這些創新不僅提高了檢測的精度和速度,還擴充套件了目標檢測的應用範圍。
-
跨領域的融合: Transformer的成功應用顯示了跨領域技術融合的巨大潛力。最初為自然語言處理設計的模型,經過適當的調整和優化,竟在視覺任務中也展現出卓越的效能,這啟示我們在未來的研究中應保持對跨學科方法的開放性和創新性。
總的來說,目標檢測技術的發展是計算機視覺領域不斷進步和創新精神的體現。隨著技術的不斷進步,我們期待目標檢測在更多領域發揮關鍵作用,例如在自動駕駛、醫療影像分析、智慧監控等領域。展望未來,目標檢測技術的進一步發展無疑將繼續受益於計算能力的提升、更大規模和多樣性的資料集,以及跨領域的演演算法創新。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。