針對海量資料的儲存與存取瓶頸的解決方案
背景
在當今這個時代,人們對網際網路的依賴程度非常高,也因此產生了大量的資料,企業視這些資料為瑰寶。而這些被視為瑰寶的資料為我們的系統帶來了很大的煩惱。這些海量資料的儲存與存取成為了系統設計與使用的瓶頸,而這些資料往往儲存在資料庫中,傳統的資料庫存在著先天的不足,即單機(單庫)效能瓶頸,並且擴充套件起來非常的困難。在當今的這個巨量資料時代,我們急需解決這個問題 。如果單機資料庫易於擴充套件,資料可切分,就可以避免這些問題,但是當前的這些資料庫廠商,包括開源的資料庫MySQL在內,提供這些服務都是需要收費的,所以我們轉向一些第三方的軟體,使用這些軟體做資料的切分,將原本在一臺資料庫上的資料,分散到多臺資料庫當中,降低每一個單體資料庫的負載。那麼我們如何做資料切分呢?
資料切分
資料切分,簡單的說,就是通過某種條件,將我們之前儲存在一臺資料庫上的資料,分散到多臺資料庫中,從而達到降低單臺資料庫負載的效果。資料切分,根據其切分的規則,大致分為兩種型別,垂直切分和水平切分。
垂直切分
垂直切分就是按照不同的表或者Schema切分到不同的資料庫中,比如:在我們的課程中,訂單表(order) 和商品表(product) 在同一個資料庫中,而我們現在要對其切分,使得訂單表(order) 和商品表(product) 分別落到不同的物理機中的不同的資料庫中,使其完全隔離,從而達到降低資料庫負載的效果。如圖所示:
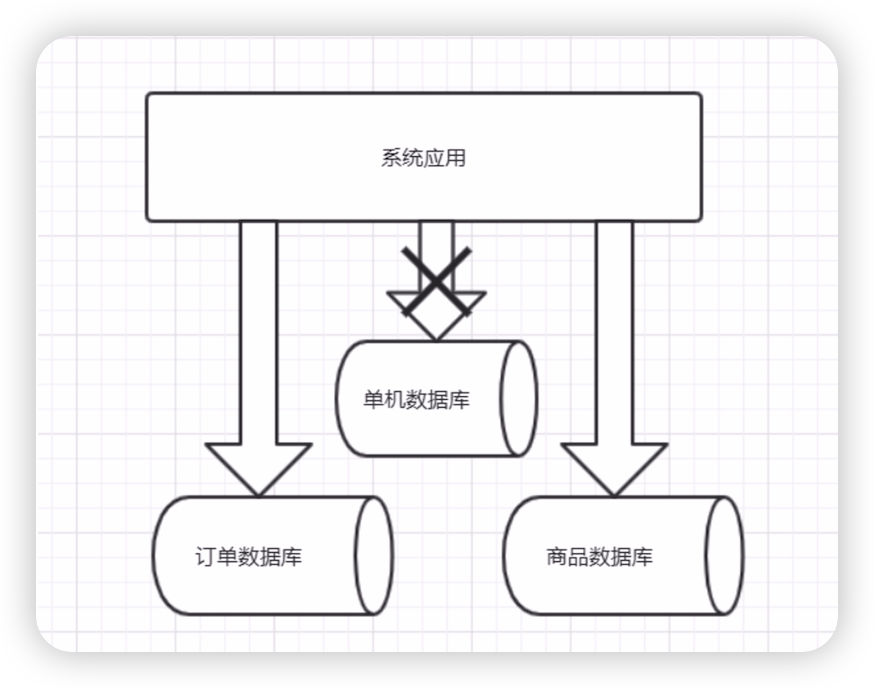
垂直切分的特點就是規則簡單,易於實施,可以根據業務模組進行劃分,各個業務之間耦合性低,相互影響也較小。
一個架構設計較好的應用系統,其總體功能肯定是有多個不同的功能模組組成的。每一個功能模組對應著資料庫裡的一系列表。例如在咱們的課程當中,商品功能模組對應的表包括:類目、屬性、屬性值、品牌、商品、sku等表。而在訂單模組中,對應的表包括:訂單、訂單明細、訂單收貨地址、訂單紀錄檔等。如圖所示:
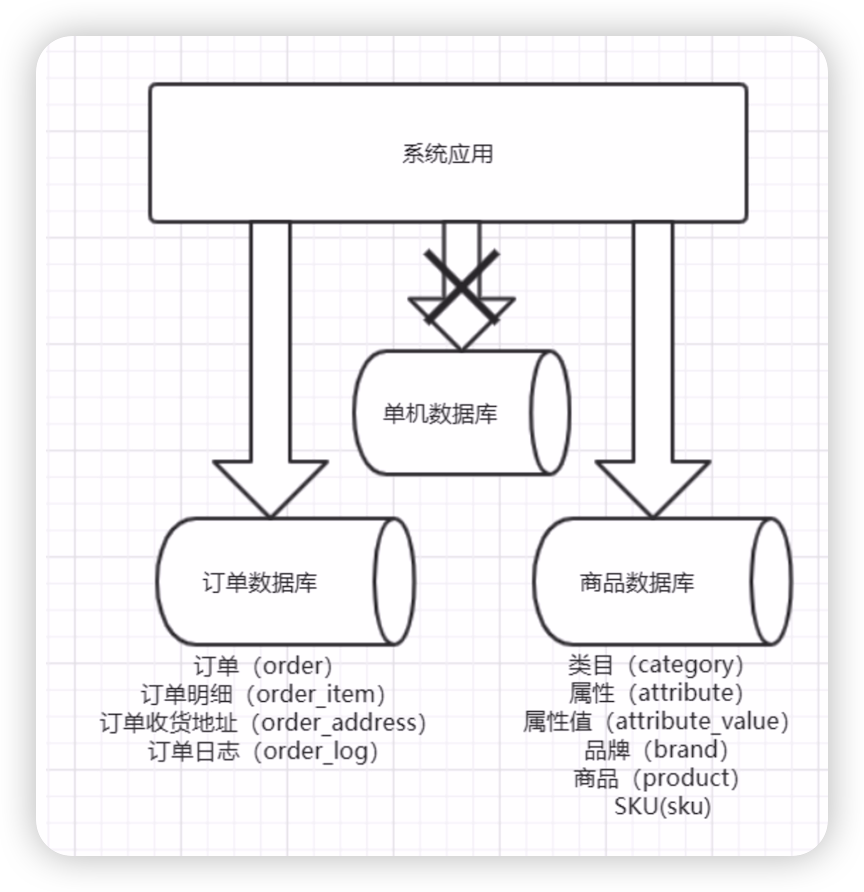
在架構設計中,各個功能模組之間的互動越統一、越少越好。這樣,系統模組之間的耦合度會很低,各個系統模組的可延伸性、可維護性也會大大提高。這樣的系統,實現資料的垂直切分就會很容易。
但是,在實際的系統架構設計中,有一些表很難做到完全的獨立,往往存在跨庫join的現象。還是上面的例子,比如我們接到了一個需求,要求查詢某一個類目產生了多少訂單,如果在單體資料庫中,我們直接連表查詢就可以了。但是現在垂直切分成了兩個資料庫,跨庫連表查詢是十分影響效能的,也不推薦這樣用,只能通過介面去調取服務,這樣系統的複雜度又升高了。對於這種很難做到完全獨立的表,作為系統架構設計人員,就要去做平衡,是資料庫讓步於業務,將這些表放在一個資料庫當中?還是拆分成多個資料庫,業務之間通過介面來呼叫呢?在系統初期,資料量比較小,資源也有限,往往會選擇放在一個資料庫當中。而隨著業務的發展,資料量達到了一定的規模,就有必要去進行資料的垂直切分了。而如何進行切分,切分到什麼程度,則是對架構師的一個艱難的考驗。
下面我們來看看垂直切分的優缺點:
優點:
- 拆分後業務清晰,拆分規則明確;
- 系統之間容易擴充套件和整合;
- 資料維護簡單
缺點:
- 部分業務表無法join,只能通過介面呼叫,提升了系統的複雜度;
- 跨庫事務難以處理;
- 垂直切分後,某些業務資料過於龐大,仍然存在單體效能瓶頸;
正如缺點中的最後一條所說,當某一個業務模組的資料暴增時,仍然存在著單機效能缺陷。還是之前的例子,如果出現了一個爆款商品,訂單量急劇上升,達到了單機效能瓶頸,那麼你所有和訂單相關的業務都要受到影響。這時我們就要用到水平切分。
水平切分
水平切分相比垂直切分,更為複雜。它需要將一個表中的資料,根據某種規則拆分到不同的資料庫中,例如:訂單尾號為奇數的訂單放在了訂單資料庫1中,而訂單尾號為偶數的訂單放在了訂單資料庫2中。這樣,原本存在一個資料庫中的訂單資料,被水平的切分成了兩個資料庫。在查詢訂單資料時,我們還要根據訂單的尾號,判斷這個訂單在資料庫1中,還是在資料庫2中,然後將這條SQL語句傳送到正確的資料庫中,查出訂單。水平切分的架構圖如下:
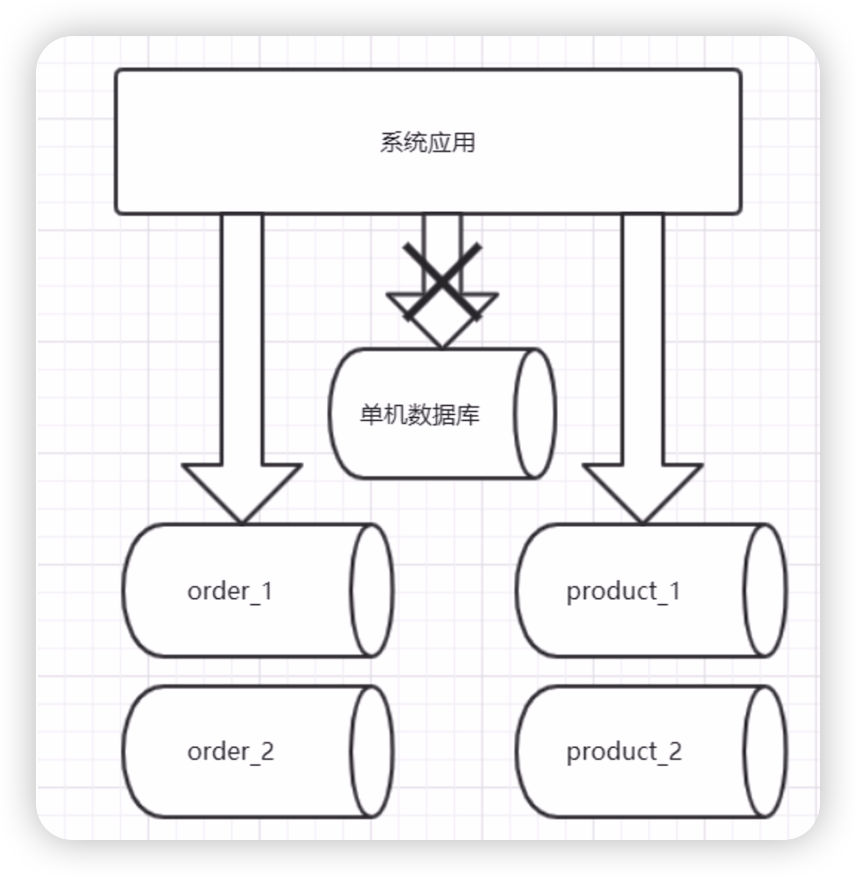
水平拆分資料,要先訂單拆分的規則,找到你要按哪個維度去拆分,還是前面訂單的例子,我們按照訂單尾號的奇偶去拆分,那麼這樣拆分會有什麼影響呢?假如我是一個使用者,我下了兩個訂單,一個訂單尾號為奇數,一個訂單尾號為偶數,這時,我去個人中心,訂單列表頁去檢視我的訂單。那麼這個訂單列表頁要去怎麼查,要根據我的使用者d分別取訂單1庫和訂單2庫去查詢出訂單,然後再合併成一個列表,是不是很麻煩。所以,咱們在拆分資料時,一定要結合業務,選擇出適合當前業務場景的拆分規則。那麼按照使用者id去拆分資料就合理嗎?也不一定,比如:咱們的身份變了,不是買家了,而是賣家,我這個賣家有很多的訂單,賣家的後臺系統也有訂單列表頁,那這個訂單列表頁要怎麼樣去查?是不是也要在所有的訂單庫中查一遍,然後再聚合成一個訂單列表呀。那這樣看,是不是按照使用者id去拆分訂單又不合理了。所以在做資料水平拆分時,是對架構師的真正考驗。
我們看看幾種水平拆分的典型的分片規則:
- 使用者id求模,我們前面已經提到過;
- 按照日期去拆分資料;
- 按照其他欄位求模,去拆分資料;
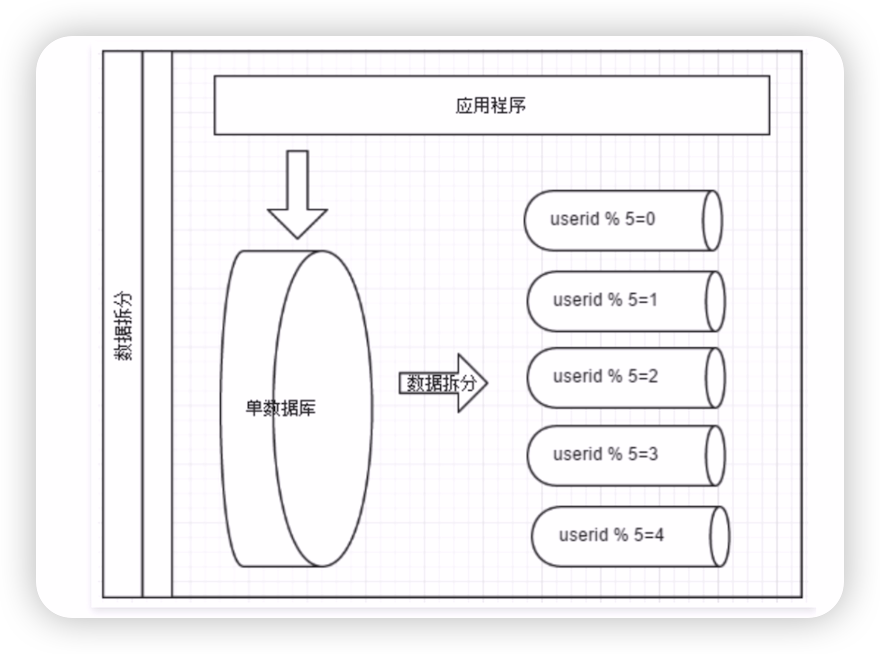
上面是按照使用者id去求模拆分的一個示意圖。咱們再來看看水平拆分的優缺點:
優點:
- 解決了單庫巨量資料、高並行的效能瓶頸;
- 拆分規則封裝好,對應用端幾乎透明,開發人員無需關心拆分細節;
- 提高了系統的穩定性和負載能力;
缺點:
- 拆分規則很難抽象;
- 分片事務一致性難以解決;
二次擴充套件時,資料遷移、維護難度大。比如:開始我們按照使用者id對2求模,但是隨著業務的增長,2臺資料庫難以支撐,還是繼續拆分成4個資料庫,那麼這時就需要做資料遷移了。
總結
世界上的萬物沒有完美的,有利就有弊,就像資料切分一樣。無論是垂直切分,還是水平切分,它們解決了海量資料的儲存和存取效能問題,但也隨之而來的帶來了很多新問題,它們的共同缺點有:
分散式的事務問題;
跨庫join問題;
多資料來源的管理問題
針對多資料來源的管理問題,主要有兩種思路:
- 使用者端模式,在每個應用模組內,設定自己需要的資料來源, 直接存取資料庫,在各模組內完成資料的整合;
- 中間代理模式,中間代理統一管理所有的資料來源,資料庫層對開發人員完全透明,開發人員無需關注拆分的細節。
基於這兩種模式,目前都有成熟的第三方軟體,代表作分別如下:
- 中間代理模式: MyCat
- 使用者端模式: sharding-jdbc