理解 Paimon changelog producer
介紹
目的
Chaneglog producer 的主要目的是為了在 Paimon 表上產生流讀的 changelog, 所以如果只是批讀的表是可以不用設定 Chaneglog producer 的.
一般對於資料庫如 MySQL 來說, 當執行的語句涉及資料的修改例如插入、更新、刪除時,MySQL 會將這些資料變動記錄在 binlog 中。相當於額外記錄一份操作紀錄檔, 類似於 Paimon 中的 input changelog producer 的模式
儲存形式
Chaneglog 一般是以單獨的 changelog 檔案的形式儲存的, 也是在 snapshot commit 期間提交的. 在每次 Snapshot 的後設資料中就會記錄 changelogManifestList. 因此在 Snapshot 過期時, 也會一起過期.
Changelog producer 有四種模式, 分別是 None, input, lookup, full comapction. 一般來說, 是要以儘可能低的代價生成 Changelog. 這四種的生成代價是由低到高的.
四種模式
None
不查詢舊值, 不額外寫Chaneglog
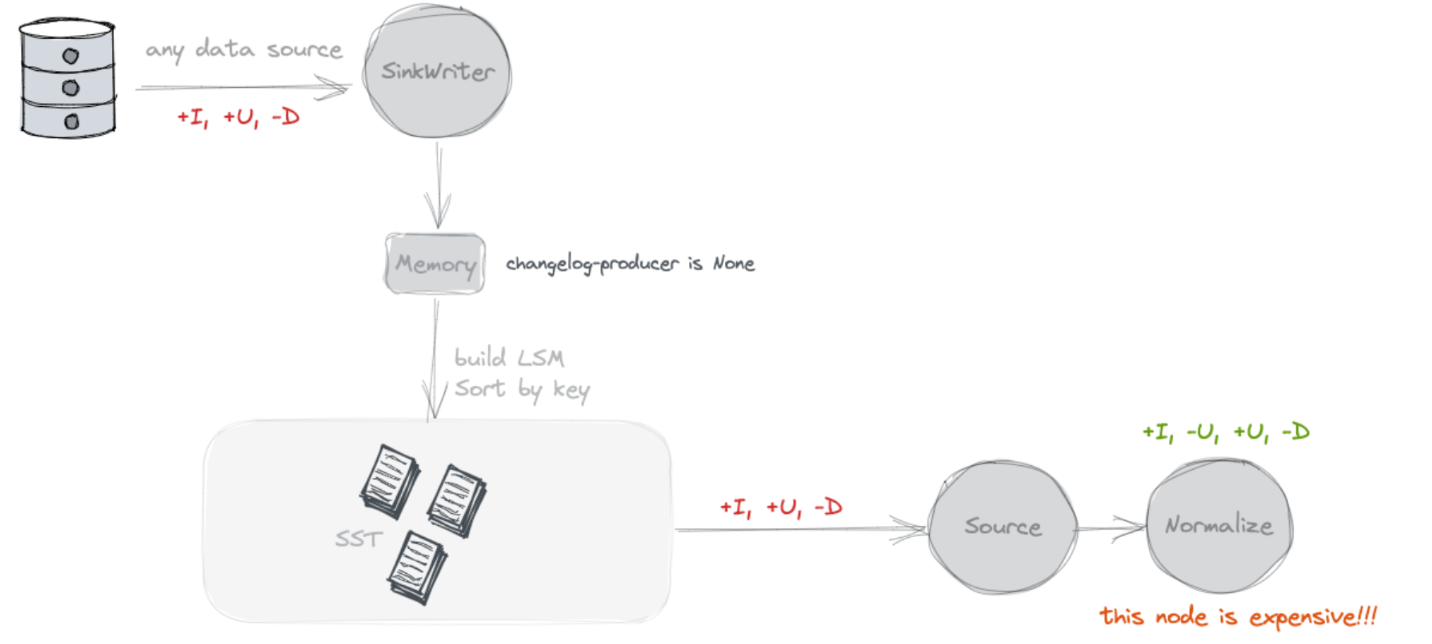
預設就是 none, 這種模式下在 Paimon 側不會額外儲存資料. Source 讀取的時候, 就是將 snapshot 的 delta list 檔案讀取出來, 就是本次 Snapshot 的增量 Changelog 了.
那麼在這種模式下, 對於一個主鍵寫入兩條 INSERT 資料, 批式查詢讀出來是一個合併後的值, 流式查詢應該讀出來是兩個 INSERT 資料, 實際上這個 changelog 是不對的, 應該讀取第二條的時間應該是 -U +U 才對.
驗證
CREATE TABLE T (
a INT
,b INT
,c STRING
,PRIMARY KEY (a) NOT ENFORCED
)
WITH (
'merge-engine' = 'deduplicate'
,'changelog-producer' = 'none'
,'continuous.discovery-interval' = '1s' -- 調低discovery-interval
);
BlockingIterator<Row, Row> iterator = streamSqlBlockIter("SELECT * FROM T");
sql("INSERT INTO T VALUES(1, 1, '1')");
// 兩次插入之間間隔2s, 這樣source可以讀取到兩次snapshot的資料
Thread.sleep(2000);
sql("INSERT INTO T VALUES(1, 1, '2')");
assertThat(iterator.collect(3))
.containsExactlyInAnyOrder(
Row.ofKind(RowKind.INSERT, 1, 1, "1"),
Row.ofKind(RowKind.INSERT, 2, 2, "2"));
測試流轉
// 第一次commit
Successfully commit snapshot #1 (path /warehouse/default.db/T/snapshot/snapshot-1) by user 6434ee5c-ad2e-4564-a32c-568104392533 with identifier 9223372036854775807 and kind APPEND.
// 掃描到第一個snapshot
start snapshotId: 1
// 第二次commit
Successfully commit snapshot #2 (path /warehouse/default.db/T/snapshot/snapshot-2) by user ce0b10c0-e63f-4db0-ab90-1c542e832791 with identifier 9223372036854775807 and kind APPEND.
// 掃描到delta檔案
scan with delta 2
// 輸出資料
[+I[1, 1, 1]]
[+I[1, 1, 1], -U[1, 1, 1]]
[+I[1, 1, 1], -U[1, 1, 1], +U[1, 1, 2]]
ChangelogNormalize
可以看到流讀的輸出產生了正確的 changelog, 但是實際上 none 模式讀取的時候是沒有這個 -U. 具體可以通過 debug ValueContentRowDataRecordIterator 來檢視真實讀取的資料. 那這個 changelog 訊息從哪裡來呢 ? 實際上這個流讀任務會產生 ChangelogNormalize 運算元.

if (
isUpsertSource(resolvedSchema, table.tableSource) ||
isSourceChangeEventsDuplicate(resolvedSchema, table.tableSource, config)
) {
// generate changelog normalize node
// primary key has been validated in CatalogSourceTable
val primaryKey = resolvedSchema.getPrimaryKey.get()
val keyFields = primaryKey.getColumns
val inputFieldNames = newScan.getRowType.getFieldNames
val primaryKeyIndices = ScanUtil.getPrimaryKeyIndices(inputFieldNames, keyFields)
val requiredDistribution = FlinkRelDistribution.hash(primaryKeyIndices, requireStrict = true)
// 給source新增pk shuffle
val requiredTraitSet = rel.getCluster.getPlanner
.emptyTraitSet()
.replace(requiredDistribution)
.replace(FlinkConventions.STREAM_PHYSICAL)
val newInput: RelNode = RelOptRule.convert(newScan, requiredTraitSet)
// 本質上就是按照 PK進行last row計算, 用於生成PK的changelog
new StreamPhysicalChangelogNormalize(
scan.getCluster,
traitSet,
newInput,
primaryKeyIndices,
table.contextResolvedTable
)
}
// 表示source是upsert的source
public static boolean isUpsertSource(
ResolvedSchema resolvedSchema, DynamicTableSource tableSource) {
if (!(tableSource instanceof ScanTableSource)) {
return false;
}
ChangelogMode mode = ((ScanTableSource) tableSource).getChangelogMode();
boolean isUpsertMode =
mode.contains(RowKind.UPDATE_AFTER) && !mode.contains(RowKind.UPDATE_BEFORE);
boolean hasPrimaryKey = resolvedSchema.getPrimaryKey().isPresent();
// 只傳送update_after, 不傳送update_before, 並且設定了pk
return isUpsertMode && hasPrimaryKey;
}
可以看到在這種模式下, 預設下游流讀的時候是會生成 ChangelogNormalize 運算元的, 類似於一個 Last Row 的運算元, 實際上就是每條 input 流入的時候, 因為外掛告訴 Planner, 我這個 source 只能產生 Upsert 訊息(Insert, Update_after, Delete) , 所以下游通過 Normalize 節點自己來生成 Changelog.
所以 none 模式其實本身傳送的 changlog 確實是不全的, 但是通過下游 changelog normalize 補足了這個 Changelog. 所以類似於 MySQL 中 binlog 生成的行為, 他其實也是存在查詢前映象的過程的, 只不過將查詢的過程放到了下游的流任務中.
當下遊不依賴完整的 Chaneglog, 比如下游也是個同步, 那麼下游任務是可以通過引數 scan.remove-normalize 來移除 Normalize 的, 通過偽造 ChangelogMode 為 all 來繞過.
但是這裡其實還有一個問題, 下游的 ChaneglogNormalize 節點是有 ttl 的, 假如我某個 key 更新是在 ttl 之後到來, 那麼可能導致第二條 Insert/update_after 到來的時候又被當做一條 insert 訊息下發, 其實會有資料不準確的問題存在的.
DeltaFollowUpScanner
流式讀取的時候會分為兩個部分, 歷史 + 增量. 有一些模式是不需要讀歷史資料的, 但是增量部分一般都是要讀的. 歷史部分是讀取的某個時刻的快照. 而增量的資料是讀取的 CommitKind 為 Append 的 snapshot 所對應的 delta list. 所以其實這種流讀模式下, delta scanner 只會讀取 L0 的檔案.
input
不查詢舊值, 額外寫Chaneglog
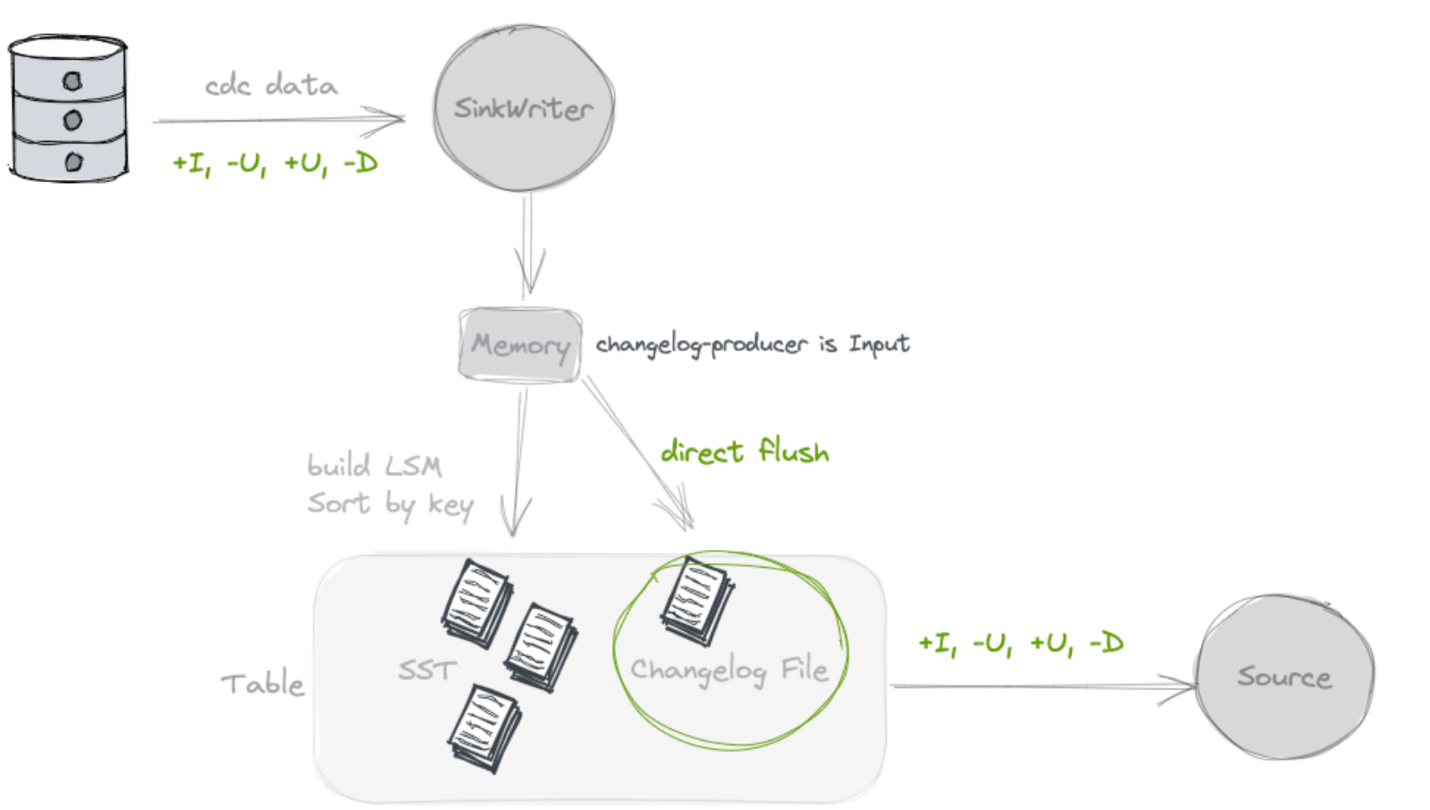
寫資料過程中雙寫一份檔案, 作為 Changelog.
理論上來說這種模式應該是很輕量的一種了, 因為首先額外的一份儲存是都省不了的, 在 None 模式中,雖然在 Paimon 側沒有佔用額外的儲存, 但是在下游的流任務的狀態中, 其實是有一份全量表的額外儲存的開銷的. 所以如果 input 模式不考慮儲存開銷, 計算開銷已經是最低了, 因為這種模式不查詢舊值.
也因此, 這種模式解決不了的一個問題是, 如果我的輸入源就是沒有完整 Changelog 的, 比如我從一份有重複資料的離線表匯入 Paimon, 那麼即使雙寫一份資料作為 Changelog, 這份 Changelog 也是不對的, 裡面可能存在同一個主鍵的重複資料.
這種模式對於 CDC 的資料來源是適用的. 那 None 模式對於 cdc 的資料來源是否適用呢 ? 其實是不適用的, 上面我們提到 None 模式的流讀其實就是讀取 L0的檔案, 那麼我們只要看 L0的檔案是否包含 Key 的變更記錄. 因為 write buffer 會有合併的邏輯, 所以, 對於 CDC 的資料, L0中可能會是已經在記憶體合併後的資料. 比如同一個 key 的-U 和+U 訊息, 同時寫入, 那麼在 writer buffer 寫入的時候就已經只保留+U 訊息了, 所以 None 模式中 L0檔案中的資料, 可能已經是合併後的資料, 對於 CDC 的資料也不適用.
那麼是不是可以在記憶體中不進行合併, L0寫入之後在後續 compact 的時候才進行合併, 這樣 None 模式就可以替換 input 的功能, 這樣不引入額外雙寫的代價, 也不用額外查詢, 就可以保留上游 cdc 資料的完整 Change log.
lookup
查詢舊值, 額外儲存Chaneglog
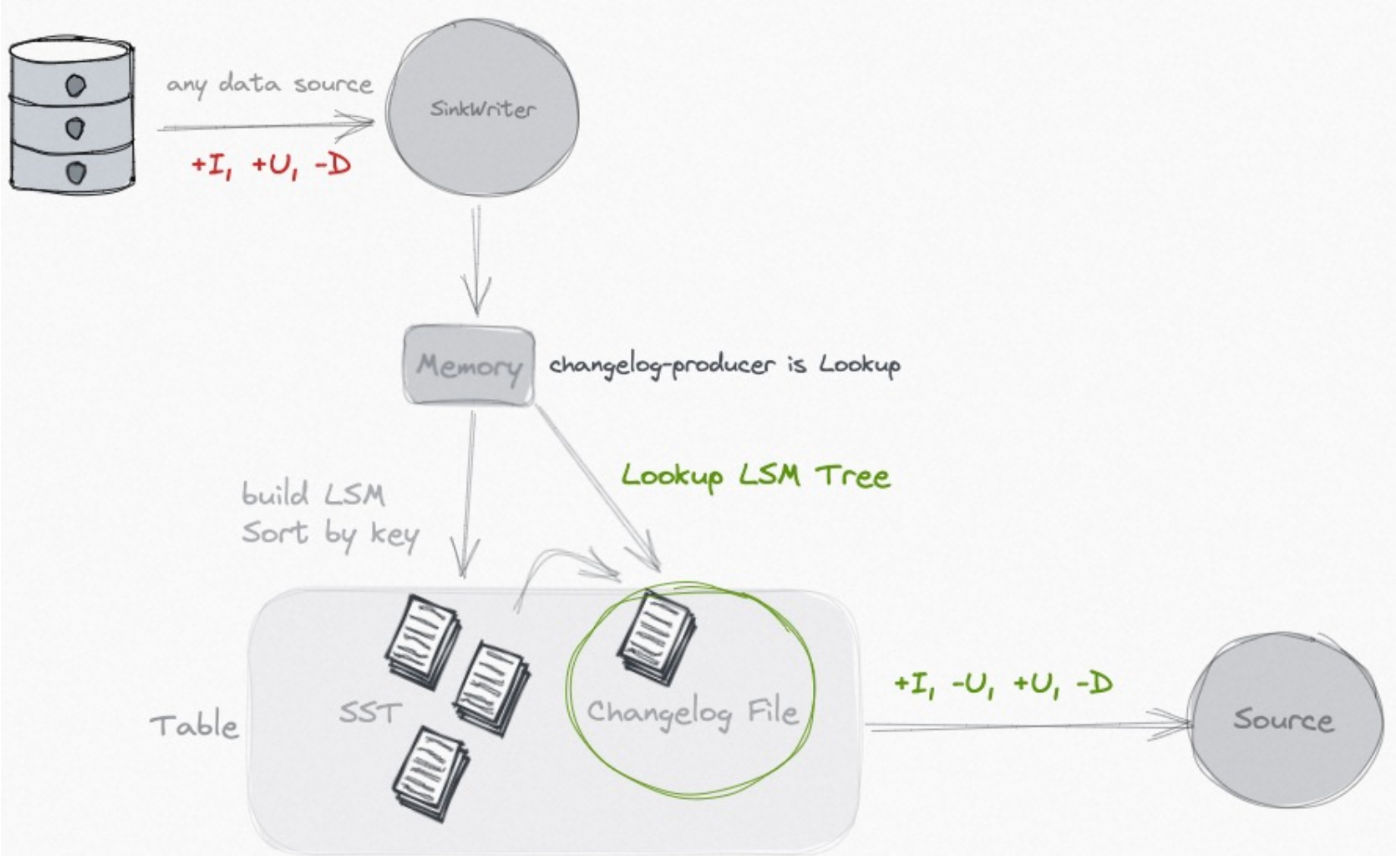
如果不是 CDC 的資料來源, 或者此 Paimon 表本身在寫入的過程中還有計算邏輯(如 partial-update/aggregation), 那麼以上兩種模式都不能生成正確的 Changelog.
lookup 的做法, 如其名字, 就是在 compaction 的過程中, 會去向高層查詢本次新增 key 的舊值, 如果沒有查詢到, 那麼本次的就是新增 key, 如果有查詢到, 那麼就生成完整的 UB 和 UA 訊息.
LookupCompaction
如何保證本次寫入的資料一定能夠產生的 Chaneglog. 首先按照 Universal Compaction策略挑選檔案參與本次 compaction. 如果沒有挑選到, 那麼會通過 LookupCompaction 策略來挑選, 這裡其實隱含了, 如果 Universal Compaction 產生了 Compaction Unit, 一定包含所有的 L0檔案.
通過 LookupCompaction 策略會將 L0 檔案進行 Compaction.
LookupMergeFunction
在 Compaction rewrite 的過程中, 會將相同 key 的資料餵給 LookupMergeFunction
public KeyValue getResult() {
// 1. Find the latest high level record
Iterator<KeyValue> descending = candidates.descendingIterator();
while (descending.hasNext()) {
KeyValue kv = descending.next();
if (kv.level() > 0) {
if (highLevel != null) {
descending.remove();
} else {
highLevel = kv;
}
} else {
containLevel0 = true;
}
}
// 2. Do the merge for inputs
mergeFunction.reset();
candidates.forEach(mergeFunction::add);
return mergeFunction.getResult();
}
- candidates 儲存的相同 key 的多個 SortedRun 的資料
- 插入順序是 sequence number 的增序.
- 對於非 L0 的 kv, sequence 越大, level 越小. 因此 candidates 中的 level 是遞減的, 最後的一部分是 L0的. 可以參見一部分
LookupChangelogMergeFunctionWrapperTest
- 對於非 L0 的 kv, sequence 越大, level 越小. 因此 candidates 中的 level 是遞減的, 最後的一部分是 L0的. 可以參見一部分
- 按照
candidates倒序查詢就是, 找到最近的 highlevel 的 value
LookupChangelogMergeFunctionWrapper
public ChangelogResult getResult() {
reusedResult.reset();
KeyValue result = mergeFunction.getResult();
if (result == null) {
return reusedResult;
}
KeyValue highLevel = mergeFunction.highLevel;
boolean containLevel0 = mergeFunction.containLevel0;
// 1. No level 0, just return
// 1. No level 0, just return
// 沒有level 0的資料, 意味著沒有新資料產生
// 那麼沒有changelog檔案產生, 只是高層檔案的合併
if (!containLevel0) {
return reusedResult.setResult(result);
}
// 2. With level 0, with the latest high level, return changelog
// 出現了highlevel的value, 很幸運, 這樣直接就可以得出change log了.
if (highLevel != null) {
// For first row, we should just return old value. And produce no changelog.
setChangelog(highLevel, result);
return reusedResult.setResult(result);
}
// 3. Lookup to find the latest high level record
// 向更高level中查詢這個key先前的資料, 為了產生變更流代價還是挺高的
// org.apache.paimon.mergetree.LookupLevels#lookup
highLevel = lookup.apply(result.key());
if (highLevel != null) {
// 找到了更高level的資料, 那麼別浪費這個結果, 可以再次進行合併, 得到一個更新的值, 並生成UB和UA訊息
mergeFunction2.reset();
mergeFunction2.add(highLevel);
mergeFunction2.add(result);
result = mergeFunction2.getResult();
setChangelog(highLevel, result);
} else {
// 沒有找到更高level的資料, 那麼Changelog就是一條insert
setChangelog(null, result);
}
return reusedResult.setResult(result);
}
根據 LookupMergeFunction#getResult 得到的 containLevel0 和 highLevel 的資訊, 以及高層 Lookup 完成 Change log 的生成. 在 Lookup 的過程中需要進行檔案的二分查詢, 以及 Lookup file 的索引檔案構建, 整體代價還是比較高的.
full compaction
查詢舊值, 額外儲存 Chaneglog
這種模式下一般通過設定 full-compaction.delta-commits 定期進行 full compact, 因為 full compact 其實代價是比較高的. 所以這種模式整體的開銷也是比較大的. 但是在 full compact 的過程中, 其實資料都會被寫到最高層, 所以所有 value 的變化都是可以推演出來的.
FullChangelogMergeFunctionWrapper
public ChangelogResult getResult() {
reusedResult.reset();
if (isInitialized) {
KeyValue merged = mergeFunction.getResult();
// 沒有topLevel
if (topLevelKv == null) {
// merged結果為ADD訊息, 那麼產生insert的訊息. 如果merge完是一條DELETE訊息, 相當於這條訊息的Changelog還沒有下發就已經刪除了, 所以這個Changelog就不下發了.
if (merged != null && isAdd(merged)) {
reusedResult.addChangelog(replace(reusedAfter, RowKind.INSERT, merged));
}
} else {
// 有topLevel的資料, merged結果為空或者為DELETE訊息, 那麼產生UB和UA訊息
if (merged == null || !isAdd(merged)) {
reusedResult.addChangelog(replace(reusedBefore, RowKind.DELETE, topLevelKv));
} else if (!changelogRowDeduplicate
|| !valueEqualiser.equals(topLevelKv.value(), merged.value())) {
reusedResult
.addChangelog(replace(reusedBefore, RowKind.UPDATE_BEFORE, topLevelKv))
.addChangelog(replace(reusedAfter, RowKind.UPDATE_AFTER, merged));
}
}
return reusedResult.setResultIfNotRetract(merged);
} else {
// 只有一個value, 並且這個value不在topLevel, 那麼就是本次新的Changelog, 置為 insert 資料.
if (topLevelKv == null && isAdd(initialKv)) {
reusedResult.addChangelog(replace(reusedAfter, RowKind.INSERT, initialKv));
}
// either topLevelKv is not null, but there is only one kv,
// so topLevelKv must be the only kv, which means there is no change
//
// or initialKv is not an ADD kv, so no new key is added
return reusedResult.setResultIfNotRetract(initialKv);
}
}
參考
https://paimon.apache.org/docs/master/concepts/primary-key-table/
本文來自部落格園,作者:血染河山,轉載請註明原文連結:https://www.cnblogs.com/Aitozi/p/17909012.html