吳恩達課後程式設計作業折積神經網路 - 第四課第一週作業
本文參考何寬大神的文章,https://blog.csdn.net/u013733326/article/details/80086090
基於以上的文章加以自己的理解發表這篇部落格,希望對大家的學習有所幫助
何寬大神的程式碼使用的是tf1.x,我所用的是tf2.x,一些程式碼有所改動,希望大家注意
1. 神經網路的底層搭建

1.1 - 匯入庫
我們先要引入一些庫:
import numpy as np
import h5py
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (5.0,4.0)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
np.random.seed(1)#指定隨機種子
1.2 - 大綱
我們將實現一個折積神經網路的一些模組,下面 下麪我們將列舉我們要實現的模組的函數功能:
-
折積模組,包含了以下函數:
- 使用0擴充邊界
- 折積視窗
- 前向折積
- 反向折積(可選)
-
池化模組,包含了以下函數:
- 前向池化
- 建立掩碼
- 值分配
- 反向池化(可選)
我們將在這裏從底層搭建一個完整的模組,之後我們會用TensorFlow實現。模型結構如下:

1.3- 折積神經網路
儘管程式設計框架使折積容易使用,但它們仍然是深度學習中最難理解的概念之一。折積層將輸入轉換成不同維度的輸出,如下所示。

我們將一步步構建折積層,我們將首先實現兩個輔助函數:一個用於零填充,另一個用於計算折積。
1.3.1 - 邊界填充
邊界填充將會在影象邊界周圍新增值爲0的畫素點,如下圖所示:
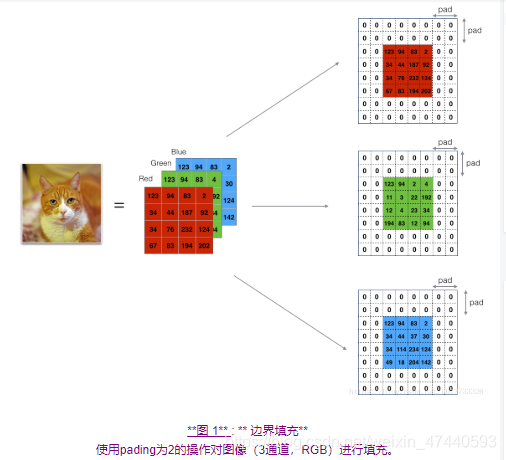
使用0填充邊界有以下好處:
-
折積了上一層之後的CONV層,沒有縮小高度和寬度。 這對於建立更深的網路非常重要,否則在更深層時,高度/寬度會縮小。 一個重要的例子是「same」折積,其中高度/寬度在折積完一層之後會被完全保留。
-
它可以幫助我們在影象邊界保留更多資訊。在沒有填充的情況下,折積過程中影象邊緣的極少數值會受到過濾器的影響從而導致資訊丟失。
-
def zero_pad(X,pad): """ 把數據集X的影象邊界全部使用0來擴充pad個寬度和高度。 參數: X - 影象數據集,維度爲(樣本數,影象高度,影象寬度,影象通道數) pad - 整數,每個影象在垂直和水平維度上的填充量 返回: X_paded - 擴充後的影象數據集,維度爲(樣本數,影象高度 + 2*pad,影象寬度 + 2*pad,影象通道數) """ X_paded = np.pad(X,( (0,0), #樣本數,不填充 (pad,pad), #影象高度,你可以視爲上面填充x個,下面 下麪填充y個(x,y) (pad,pad), #影象寬度,你可以視爲左邊填充x個,右邊填充y個(x,y) (0,0)), #通道數,不填充 'constant', constant_values=0) #連續一樣的值填充 return X_paded測試一下:
-
np.random.seed(1) x = np.random.randn(4,3,3,2) x_paded = zero_pad(x,2) #檢視資訊 print ("x.shape =", x.shape) print ("x_paded.shape =", x_paded.shape) print ("x[1, 1] =", x[1, 1]) print ("x_paded[1, 1] =", x_paded[1, 1]) #繪製圖 fig , axarr = plt.subplots(1,2) #一行兩列 axarr[0].set_title('x') axarr[0].imshow(x[0,:,:,0]) axarr[1].set_title('x_paded') axarr[1].imshow(x_paded[0,:,:,0])程式碼執行結果如下:
-
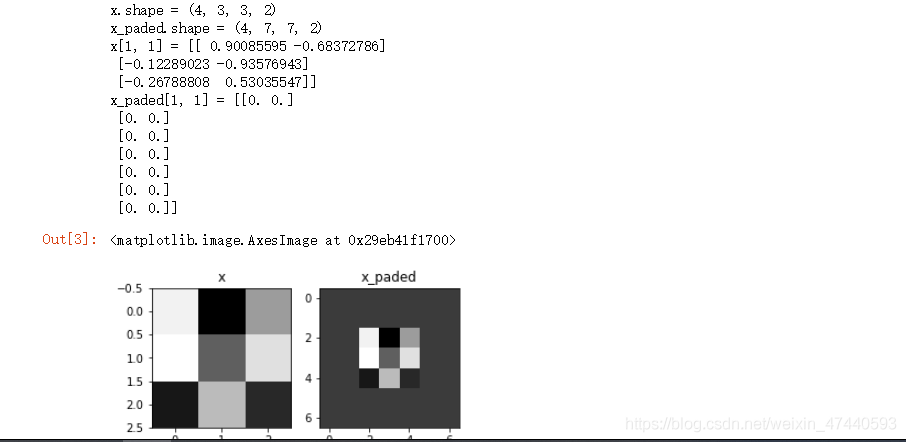
這裏博主有點迷多維陣列,特意輸出了一下x,可以看出:
x [[[[ 1.62434536 -0.61175641]
[-0.52817175 -1.07296862]
[ 0.86540763 -2.3015387 ]]
[[ 1.74481176 -0.7612069 ]
[ 0.3190391 -0.24937038]
[ 1.46210794 -2.06014071]]
[[-0.3224172 -0.38405435]
[ 1.13376944 -1.09989127]
[-0.17242821 -0.87785842]]]
[[[ 0.04221375 0.58281521]
[-1.10061918 1.14472371]
[ 0.90159072 0.50249434]]
[[ 0.90085595 -0.68372786]
[-0.12289023 -0.93576943]
[-0.26788808 0.53035547]]
[[-0.69166075 -0.39675353]
[-0.6871727 -0.84520564]
[-0.67124613 -0.0126646 ]]]
[[[-1.11731035 0.2344157 ]
[ 1.65980218 0.74204416]
[-0.19183555 -0.88762896]]
[[-0.74715829 1.6924546 ]
[ 0.05080775 -0.63699565]
[ 0.19091548 2.10025514]]
[[ 0.12015895 0.61720311]
[ 0.30017032 -0.35224985]
[-1.1425182 -0.34934272]]]
[[[-0.20889423 0.58662319]
[ 0.83898341 0.93110208]
[ 0.28558733 0.88514116]]
[[-0.75439794 1.25286816]
[ 0.51292982 -0.29809284]
[ 0.48851815 -0.07557171]]
[[ 1.13162939 1.51981682]
[ 2.18557541 -1.39649634]
[-1.44411381 -0.50446586]]]]
1.3.2 - 單步折積
在這裏,我們要實現第一步折積,我們要使用一個過濾器來折積輸入的數據。先來看看下面 下麪的這個gif:
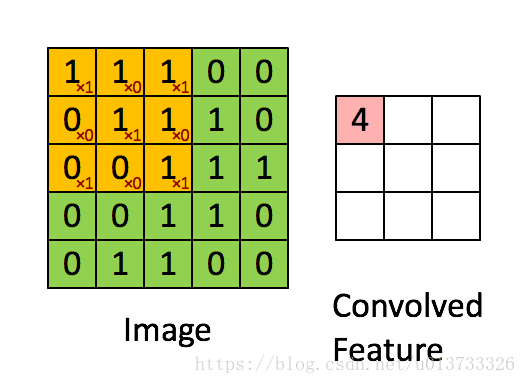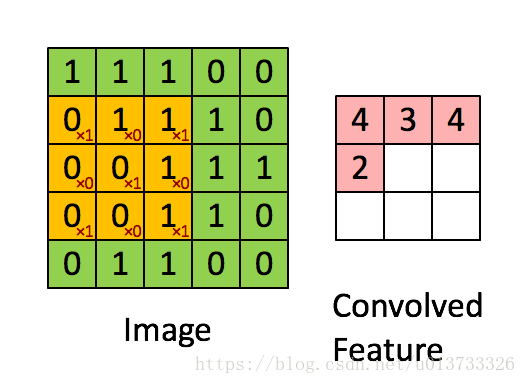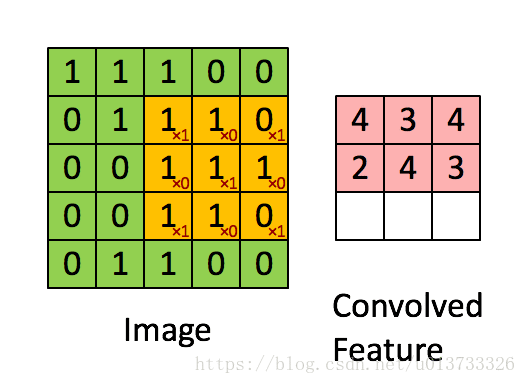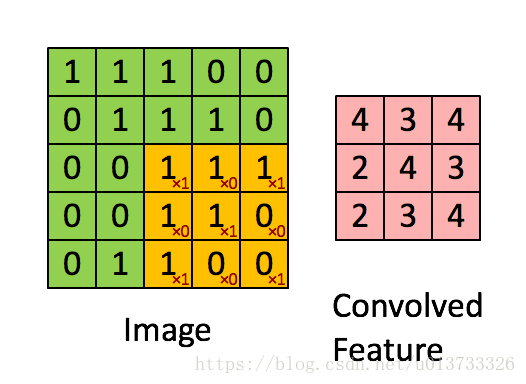
在計算機視覺應用中,左側矩陣中的每個值都對應一個畫素值,我們通過將其值與原始矩陣元素相乘,然後對它們進行求和來將3x3濾波器與影象進行折積。我們需要實現一個函數,可以將一個3x3濾波器與單獨的切片塊進行折積並輸出一個實數。現在我們開始實現conv_single_step()
def conv_single_step(a_slice_prev,W,b):
"""
在前一層的啓用輸出的一個片段上應用一個由參數W定義的過濾器。
這裏切片大小和過濾器大小相同
參數:
a_slice_prev - 輸入數據的一個片段,維度爲(過濾器大小,過濾器大小,上一通道數)
W - 權重參數,包含在了一個矩陣中,維度爲(過濾器大小,過濾器大小,上一通道數)
b - 偏置參數,包含在了一個矩陣中,維度爲(1,1,1)
返回:
Z - 在輸入數據的片X上折積滑動視窗(w,b)的結果。
"""
s = np.multiply(a_slice_prev,W) + b
Z = np.sum(s)
return Z
測試一下:
np.random.seed(1)
#這裏切片大小和過濾器大小相同
a_slice_prev = np.random.randn(4,4,3)
W = np.random.randn(4,4,3)
b = np.random.randn(1,1,1)
Z = conv_single_step(a_slice_prev,W,b)
print("Z = " + str(Z))
Z = -23.16021220252078
1.3.3 - 折積神經網路 - 前向傳播
在前向傳播的過程中,我們將使用多種過濾器對輸入的數據進行折積操作,每個過濾器會產生一個2D的矩陣,我們可以把它們堆疊起來,於是這些2D的折積矩陣就變成了高維的矩陣。我們可以看一下下的圖:
我們需要實現一個函數以實現對啓用值進行折積。我們需要在啓用值矩陣[Math Processing Error]A_prevAprev上使用過濾器[Math Processing Error]WW進行折積。該函數的輸入是前一層的啓用輸出[Math Processing Error]A_prevAprev,[Math Processing Error]FF個過濾器,其權重矩陣爲[Math Processing Error]WW、偏置矩陣爲[Math Processing Error]bb,每個過濾器只有一個偏置,最後,我們需要一個包含了步長[Math Processing Error]ss和填充[Math Processing Error]pp的字典型別的超參數。
小提示:
- 如果我要在矩陣A_prev(shape = (5,5,3))的左上角選擇一個2x2的矩陣進行切片操作,那麼可以這樣做:
<span style="color:#000000"><code class="language-python">a_slice_prev <span style="color:#669900">=</span> a_prev<span style="color:#999999">[</span><span style="color:#98c379">0</span><span style="color:#999999">:</span><span style="color:#98c379">2</span><span style="color:#999999">,</span><span style="color:#98c379">0</span><span style="color:#999999">:</span><span style="color:#98c379">2</span><span style="color:#999999">,</span><span style="color:#999999">:</span><span style="color:#999999">]</span> </code></span>- 1
- 如果我想要自定義切片,我們可以這麼做:先定義要切片的位置,
vert_start、vert_end、horiz_start、horiz_end,它們的位置我們看一下下面 下麪的圖就明白了。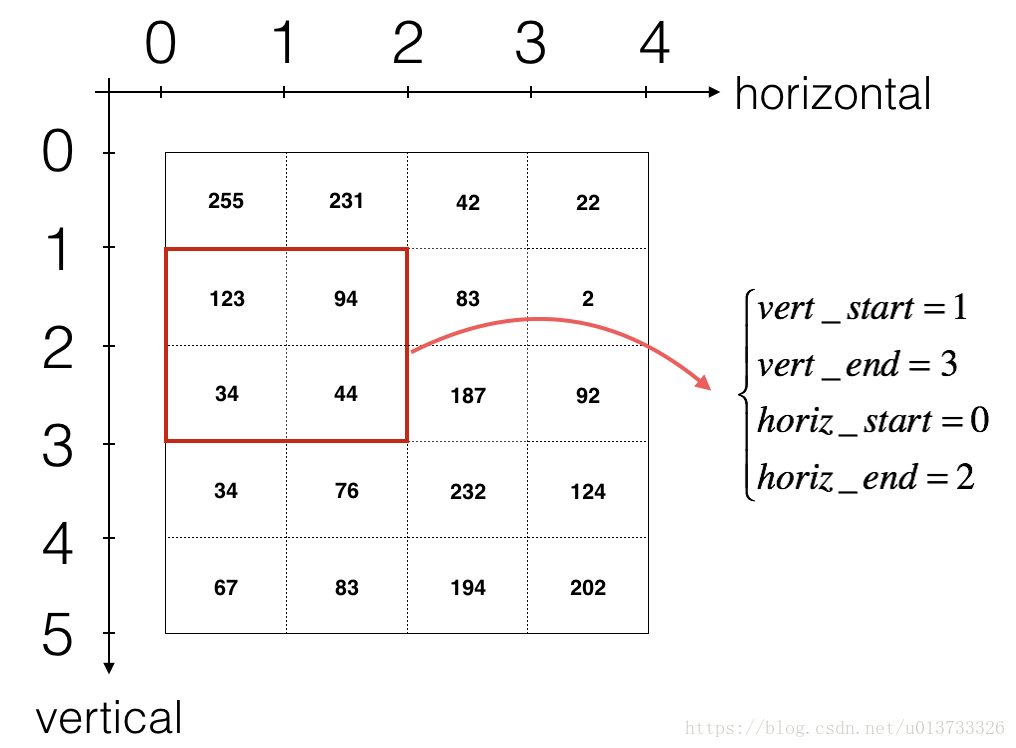
**圖 3** : **定義切片的開始、結束位置 (使用 2x2 的過濾器)**
只適用於單通道
def conv_forward(A_prev, W, b, hparameters):
"""
實現折積函數的前向傳播
參數:
A_prev - 上一層的啓用輸出矩陣,維度爲(m, n_H_prev, n_W_prev, n_C_prev),(樣本數量,上一層影象的高度,上一層影象的寬度,上一層過濾器數量)
W - 權重矩陣,維度爲(f, f, n_C_prev, n_C),(過濾器大小,過濾器大小,上一層的過濾器數量,這一層的過濾器數量)
b - 偏置矩陣,維度爲(1, 1, 1, n_C),(1,1,1,這一層的過濾器數量)
hparameters - 包含了"stride"與 "pad"的超參數字典。
返回:
Z - 折積輸出,維度爲(m, n_H, n_W, n_C),(樣本數,影象的高度,影象的寬度,過濾器數量)
cache - 快取了一些反向傳播函數conv_backward()需要的一些數據
"""
#獲取來自上一層數據的基本資訊
(m , n_H_prev , n_W_prev , n_C_prev) = A_prev.shape
#獲取權重矩陣的基本資訊
( f , f ,n_C_prev , n_C ) = W.shape
#獲取超參數hparameters的值
stride = hparameters["stride"]
pad = hparameters["pad"]
#計算折積後的影象的寬度高度,參考上面的公式,使用int()來進行板除
n_H = int(( n_H_prev - f + 2 * pad )/ stride) + 1
n_W = int(( n_W_prev - f + 2 * pad )/ stride) + 1
#使用0來初始化折積輸出Z
Z = np.zeros((m,n_H,n_W,n_C))
#通過A_prev建立填充過了的A_prev_pad
A_prev_pad = zero_pad(A_prev,pad)
for i in range(m): #遍歷樣本
a_prev_pad = A_prev_pad[i] #選擇第i個樣本的擴充後的啓用矩陣
for h in range(n_H): #在輸出的垂直軸上回圈
for w in range(n_W): #在輸出的水平軸上回圈
for c in range(n_C): #回圈遍歷輸出的通道
#定位當前的切片位置
vert_start = h * stride #豎向,開始的位置
vert_end = vert_start + f #豎向,結束的位置
horiz_start = w * stride #橫向,開始的位置
horiz_end = horiz_start + f #橫向,結束的位置
#切片位置定位好了我們就把它取出來,需要注意的是我們是「穿透」取出來的,
#自行腦補一下吸管插入一層層的橡皮泥就明白了
a_slice_prev = a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]
#執行單步折積
Z[i,h,w,c] = conv_single_step(a_slice_prev,W[: ,: ,: ,c],b[0,0,0,c])
#數據處理完畢,驗證數據格式是否正確
assert(Z.shape == (m , n_H , n_W , n_C ))
#儲存一些快取值,以便於反向傳播使用
cache = (A_prev,W,b,hparameters)
return (Z , cache)
測試一下:
np.random.seed(1)
A_prev = np.random.randn(10,4,4,3)
W = np.random.randn(2,2,3,8)
b = np.random.randn(1,1,1,8)
hparameters = {"pad" : 2, "stride": 1}
Z , cache_conv = conv_forward(A_prev,W,b,hparameters)
print("np.mean(Z) = ", np.mean(Z))
print("cache_conv[0][1][2][3] =", cache_conv[0][1][2][3])
輸出:
np.mean(Z) = 0.15585932488906465 cache_conv[0][1][2][3] = [-0.20075807 0.18656139 0.41005165]
1.4 - 池化層
池化層會減少輸入的寬度和高度,這樣它會較少計算量的同時也使特徵檢測器對其在輸入中的位置更加穩定。下面 下麪介紹兩種型別的池化層:
-
最大值池化層:在輸入矩陣中滑動一個大小爲fxf的視窗,選取視窗裏的值中的最大值,然後作爲輸出的一部分。
-
均值池化層:在輸入矩陣中滑動一個大小爲fxf的視窗,計算視窗裏的值中的平均值,然後這個均值作爲輸出的一部分。
-
-
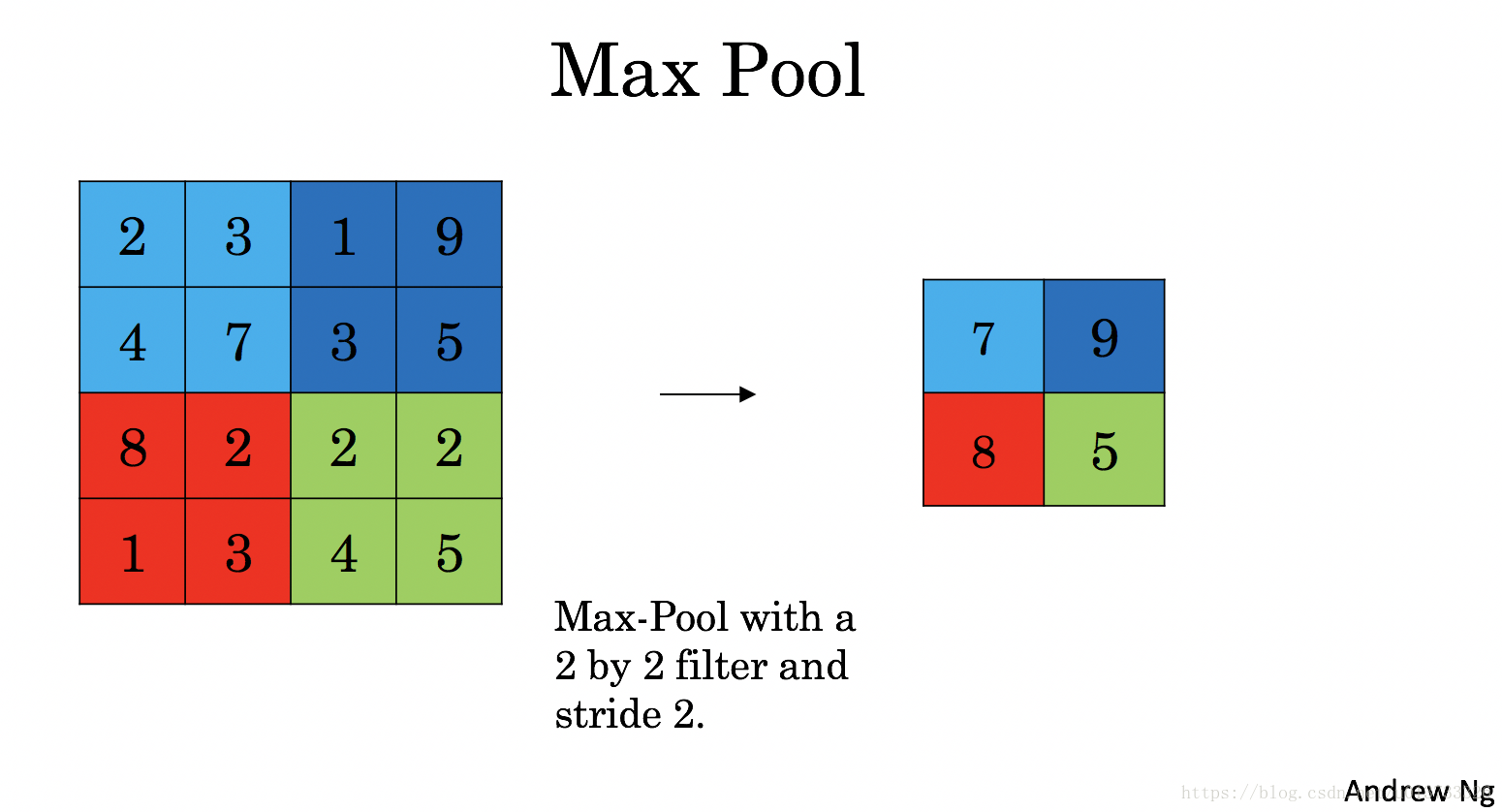
<td> <img src="https://img-blog.csdn.net/20180425215257202?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTM3MzMzMjY=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70" style="width:500px;height:300px;"> <td>- 1
- 2
- 3
池化層沒有用於進行反向傳播的參數,但是它們有像視窗的大小爲[Math Processing Error]ff的超參數,它指定fxf視窗的高度和寬度,我們可以計算出最大值或平均值。
1.4.1 - 池化層的前向傳播
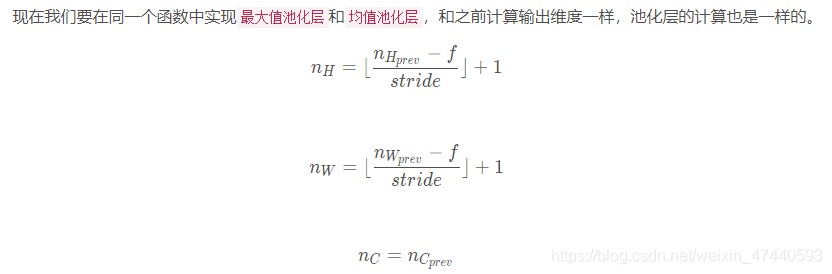
def pool_forward(A_prev,hparameters,mode="max"):
"""
實現池化層的前向傳播
參數:
A_prev - 輸入數據,維度爲(m, n_H_prev, n_W_prev, n_C_prev)
hparameters - 包含了 "f" 和 "stride"的超參數字典
mode - 模式選擇【"max" | "average"】
返回:
A - 池化層的輸出,維度爲 (m, n_H, n_W, n_C)
cache - 儲存了一些反向傳播需要用到的值,包含了輸入和超參數的字典。
"""
#獲取輸入數據的基本資訊
(m , n_H_prev , n_W_prev , n_C_prev) = A_prev.shape
#獲取超參數的資訊
f = hparameters["f"]
stride = hparameters["stride"]
#計算輸出維度
n_H = int((n_H_prev - f) / stride ) + 1
n_W = int((n_W_prev - f) / stride ) + 1
n_C = n_C_prev
#初始化輸出矩陣
A = np.zeros((m , n_H , n_W , n_C))
for i in range(m): #遍歷樣本
for h in range(n_H): #在輸出的垂直軸上回圈
for w in range(n_W): #在輸出的水平軸上回圈
for c in range(n_C): #回圈遍歷輸出的通道
#定位當前的切片位置
vert_start = h * stride #豎向,開始的位置
vert_end = vert_start + f #豎向,結束的位置
horiz_start = w * stride #橫向,開始的位置
horiz_end = horiz_start + f #橫向,結束的位置
#定位完畢,開始切割
a_slice_prev = A_prev[i,vert_start:vert_end,horiz_start:horiz_end,c]
#對切片進行池化操作
if mode == "max":
A[ i , h , w , c ] = np.max(a_slice_prev)
elif mode == "average":
A[ i , h , w , c ] = np.mean(a_slice_prev)
#池化完畢,校驗數據格式
assert(A.shape == (m , n_H , n_W , n_C))
#校驗完畢,開始儲存用於反向傳播的值
cache = (A_prev,hparameters)
return A,cache
測試一下:
np.random.seed(1)
A_prev = np.random.randn(2,4,4,3)
hparameters = {"f":4 , "stride":1}
A , cache = pool_forward(A_prev,hparameters,mode="max")
A, cache = pool_forward(A_prev, hparameters)
print("mode = max")
print("A =", A)
print("----------------------------")
A, cache = pool_forward(A_prev, hparameters, mode = "average")
print("mode = average")
print("A =", A)
輸出
mode = max
A = [[[[1.74481176 1.6924546 2.10025514]]]
[[[1.19891788 1.51981682 2.18557541]]]]
----------------------------
mode = average
A = [[[[-0.09498456 0.11180064 -0.14263511]]]
[[[-0.09525108 0.28325018 0.33035185]]]]
反向傳播我偷懶了就沒做
2. 神經網路的應用
我們已經使用了原生程式碼實現了折積神經網路,現在我們要使用TensorFlow來實現,然後應用到手勢識別中,在這裏我們要實現4個函數,一起來看看吧~
2.1.0 TensorFlow模型
我們先來匯入庫:
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import tensorflow as tf
from tensorflow.python.framework import ops
import cnn_utils
%matplotlib inline
np.random.seed(1)
構建網路
#構建網路
X_train_orig , Y_train_orig , X_test_orig , Y_test_orig , classes = cnn_utils.load_dataset()#載入數據集
再看一下裏面的圖片:
index = 19
plt.imshow(X_train_orig[index])
print ("y = " + str(np.squeeze(Y_train_orig[:, index])))
輸出:

在課程2中,我們已經建立過一個神經網路,我想對這個數據集應該不陌生吧~我們再來看一下數據的維度,如果你忘記了獨熱編碼的實現,請看https://blog.csdn.net/weixin_47440593/article/details/107721334
X_train = X_train_orig/255.
X_test = X_test_orig/255.
Y_train = cnn_utils.convert_to_one_hot(Y_train_orig, 6).T
Y_test = cnn_utils.convert_to_one_hot(Y_test_orig, 6).T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
conv_layers = {}
輸出結果:
number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6)
2.1.1 建立placeholders
TensorFlow要求您爲執行對談時將輸入到模型中的輸入數據建立佔位符。現在我們要實現建立佔位符的函數,因爲我們使用的是小批次數據塊,輸 入的樣本數量可能不固定,所以我們在數量那裏我們要使用None作爲可變數量。輸入X的維度爲**[None,n_H0,n_W0,n_C0],對應的Y是[None,n_y]**。
tf.compat.v1.disable_eager_execution()#防止出現Error: tf.placeholder() is not compatible with eager execution.
def create_placeholders(n_H0, n_W0, n_C0, n_y):
"""
爲session建立佔位符
參數:
n_H0 - 實數,輸入影象的高度
n_W0 - 實數,輸入影象的寬度
n_C0 - 實數,輸入的通道數
n_y - 實數,分類數
輸出:
X - 輸入數據的佔位符,維度爲[None, n_H0, n_W0, n_C0],型別爲"float"
Y - 輸入數據的標籤的佔位符,維度爲[None, n_y],維度爲"float"
"""
X = tf.compat.v1.placeholder(tf.float32,[None, n_H0, n_W0, n_C0])#這裏注意下tf版本,和原部落格不一致
Y = tf.compat.v1.placeholder(tf.float32,[None, n_y])
return X,Y
測試一下
X , Y = create_placeholders(64,64,3,6)
print ("X = " + str(X))
print ("Y = " + str(Y))
輸出結果:
X = Tensor("Placeholder:0", shape=(?, 64, 64, 3), dtype=float32)
Y = Tensor("Placeholder_1:0", shape=(?, 6), dtype=float32)
2.1.2 初始化參數
現在我們將使用tf.contrib.layers.xavier_initializer(seed = 0) 來初始化權值/過濾器W1W1W1、W2W2W2。在這裏,我們不需要考慮偏置,因爲TensorFlow會考慮到的。需要注意的是我們只需要初始化爲2D折積函數,全連線層TensorFlow會自動初始化的。
注意:由於TF2.x刪除了contrib,我使用了initializer = tf.initializers.GlorotUniform(seed=1))來代替initializer=tf.contrib.layers.xavier_initializer(seed=1))
#初始化參數
def initialize_parameters():
"""
初始化權值矩陣,這裏我們把權值矩陣寫死:
W1 : [4, 4, 3, 8]
W2 : [2, 2, 8, 16]
返回:
包含了tensor型別的W1、W2的字典
"""
tf.compat.v1.set_random_seed(1)
W1 = tf.compat.v1.get_variable("W1",[4,4,3,8],initializer = tf.initializers.GlorotUniform(seed=0))
W2 = tf.compat.v1.get_variable("W2",[2,2,8,16],initializer = tf.initializers.GlorotUniform(seed=0))
parameters = {"W1": W1,
"W2": W2}
return parameters
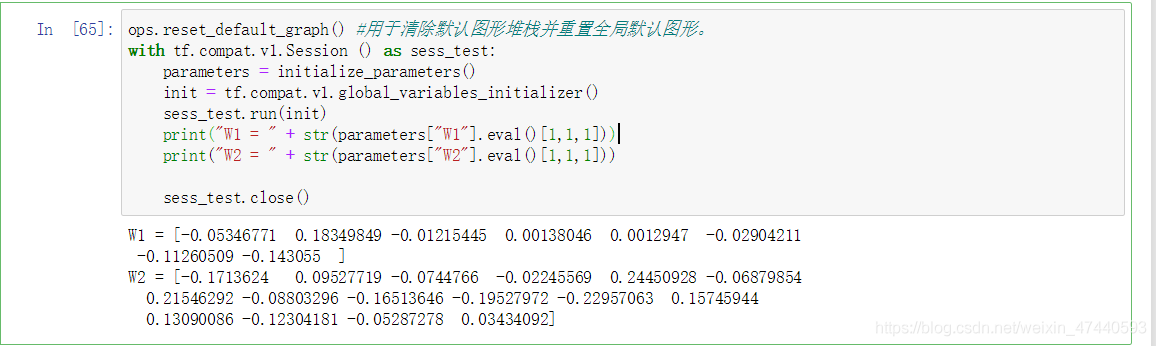
測試一下:
ops.reset_default_graph() #用於清除預設圖形堆疊並重置全域性預設圖形。
with tf.compat.v1.Session () as sess_test:
parameters = initialize_parameters()
init = tf.compat.v1.global_variables_initializer()
sess_test.run(init)
print("W1 = " + str(parameters["W1"].eval()[1,1,1]))
print("W2 = " + str(parameters["W2"].eval()[1,1,1]))
sess_test.close()
輸出:
2.1.2 - 前向傳播
def forward_propagation(X,parameters):
"""
實現前向傳播
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
參數:
X - 輸入數據的placeholder,維度爲(輸入節點數量,樣本數量)
parameters - 包含了「W1」和「W2」的python字典。
返回:
Z3 - 最後一個LINEAR節點的輸出
"""
W1 = parameters['W1']
W2 = parameters['W2']
#Conv2d : 步伐:1,填充方式:「SAME」
Z1 = tf.nn.conv2d(X,W1,strides=[1,1,1,1],padding="SAME")
#ReLU :
A1 = tf.nn.relu(Z1)
#Max pool : 視窗大小:8x8,步伐:8x8,填充方式:「SAME」
P1 = tf.nn.max_pool(A1,ksize=[1,8,8,1],strides=[1,8,8,1],padding="SAME")
#Conv2d : 步伐:1,填充方式:「SAME」
Z2 = tf.nn.conv2d(P1,W2,strides=[1,1,1,1],padding="SAME")
#ReLU :
A2 = tf.nn.relu(Z2)
#Max pool : 過濾器大小:4x4,步伐:4x4,填充方式:「SAME」
P2 = tf.nn.max_pool(A2,ksize=[1,4,4,1],strides=[1,4,4,1],padding="SAME")
#一維化上一層的輸出
P = tf.compat.v1.layers.flatten(P2)
#全連線層(FC):使用沒有非線性啓用函數的全連線層
Z3 = tf.compat.v1.layers.dense(P,6)
return Z3
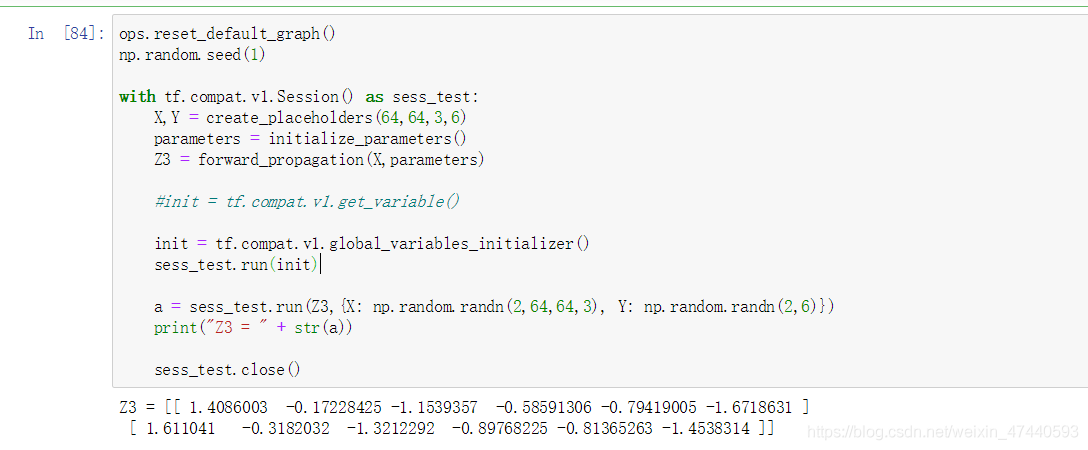
測試一下:
ops.reset_default_graph()
np.random.seed(1)
with tf.compat.v1.Session() as sess_test:
X,Y = create_placeholders(64,64,3,6)
parameters = initialize_parameters()
Z3 = forward_propagation(X,parameters)
#init = tf.compat.v1.get_variable()
init = tf.compat.v1.global_variables_initializer()
sess_test.run(init)
a = sess_test.run(Z3,{X: np.random.randn(2,64,64,3), Y: np.random.randn(2,6)})
print("Z3 = " + str(a))
sess_test.close()
輸出:
2.1.3 計算成本
我們要在這裏實現計算成本的函數,下面 下麪的兩個函數是我們要用到的:
-
tf.nn.softmax_cross_entropy_with_logits(logits = Z3 , lables = Y):計算softmax的損失函數。這個函數既計算softmax的啓用,也計算其損失,你可以閱讀手冊 -
tf.reduce_mean:計算的是平均值,使用它來計算所有樣本的損失來得到總成本。你可以閱讀手冊
現在,我們就來實現計算成本的函數。
def compute_cost(Z3,Y):
"""
計算成本
參數:
Z3 - 正向傳播最後一個LINEAR節點的輸出,維度爲(6,樣本數)。
Y - 標籤向量的placeholder,和Z3的維度相同
返回:
cost - 計算後的成本
"""
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3,labels=Y))
return cost
測試一下:
tf.compat.v1.reset_default_graph()
with tf.compat.v1.Session() as sess_test:
np.random.seed(1)
X,Y = create_placeholders(64,64,3,6)
parameters = initialize_parameters()
Z3 = forward_propagation(X,parameters)
cost = compute_cost(Z3,Y)
init = tf.compat.v1.global_variables_initializer()
sess_test.run(init)
a = sess_test.run(cost,{X: np.random.randn(4,64,64,3), Y: np.random.randn(4,6)})
print("cost = " + str(a))
sess_test.close()
輸出結果:

2.1.4 構建模型
最後,我們已經實現了我們所有的函數,我們現在就可以實現我們的模型了。
我們之前在課程2就實現過random_mini_batches()這個函數,它返回的是一個mini-batches的列表。
在實現這個模型的時候我們要經歷以下步驟:
- 建立佔位符
- 初始化參數
- 前向傳播
- 計算成本
- 反向傳播
- 建立優化器
最後,我們將建立一個session來執行模型。
def model(X_train, Y_train, X_test, Y_test, learning_rate=0.009,
num_epochs=100,minibatch_size=64,print_cost=True,isPlot=True):
"""
使用TensorFlow實現三層的折積神經網路
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
參數:
X_train - 訓練數據,維度爲(None, 64, 64, 3)
Y_train - 訓練數據對應的標籤,維度爲(None, n_y = 6)
X_test - 測試數據,維度爲(None, 64, 64, 3)
Y_test - 訓練數據對應的標籤,維度爲(None, n_y = 6)
learning_rate - 學習率
num_epochs - 遍歷整個數據集的次數
minibatch_size - 每個小批次數據塊的大小
print_cost - 是否列印成本值,每遍歷100次整個數據集列印一次
isPlot - 是否繪製圖譜
返回:
train_accuracy - 實數,訓練集的準確度
test_accuracy - 實數,測試集的準確度
parameters - 學習後的參數
"""
ops.reset_default_graph() #能夠重新執行模型而不覆蓋tf變數
tf.random.set_seed(1) #確保你的數據和我一樣
seed = 3 #指定numpy的隨機種子
(m , n_H0, n_W0, n_C0) = X_train.shape
n_y = Y_train.shape[1]
costs = []
#爲當前維度建立佔位符
X , Y = create_placeholders(n_H0, n_W0, n_C0, n_y)
#初始化參數
parameters = initialize_parameters()
#前向傳播
Z3 = forward_propagation(X,parameters)
#計算成本
cost = compute_cost(Z3,Y)
#反向傳播,由於框架已經實現了反向傳播,我們只需要選擇一個優化器就行了
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
#全域性初始化所有變數
init = tf.compat.v1.global_variables_initializer()
#開始執行
with tf.compat.v1.Session() as sess:
#初始化參數
sess.run(init)
#開始遍歷數據集
for epoch in range(num_epochs):
minibatch_cost = 0
num_minibatches = int(m / minibatch_size) #獲取數據塊的數量
seed = seed + 1
minibatches = cnn_utils.random_mini_batches(X_train,Y_train,minibatch_size,seed)
#對每個數據塊進行處理
for minibatch in minibatches:
#選擇一個數據塊
(minibatch_X,minibatch_Y) = minibatch
#最小化這個數據塊的成本
_ , temp_cost = sess.run([optimizer,cost],feed_dict={X:minibatch_X, Y:minibatch_Y})
#累加數據塊的成本值
minibatch_cost += temp_cost / num_minibatches
#是否列印成本
if print_cost:
#每5代列印一次
if epoch % 5 == 0:
print("當前是第 " + str(epoch) + " 代,成本值爲:" + str(minibatch_cost))
#記錄成本
if epoch % 1 == 0:
costs.append(minibatch_cost)
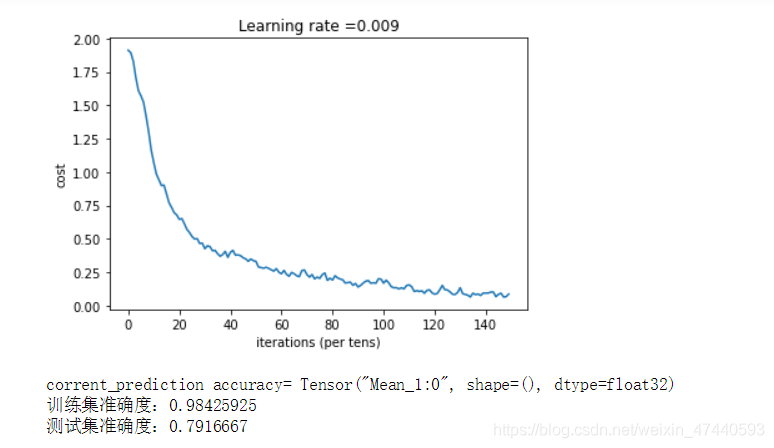
#數據處理完畢,繪製成本曲線
if isPlot:
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
#開始預測數據
## 計算當前的預測情況
predict_op = tf.argmax(Z3,1)
corrent_prediction = tf.equal(predict_op , tf.argmax(Y,1))
##計算準確度
accuracy = tf.reduce_mean(tf.cast(corrent_prediction,"float"))
print("corrent_prediction accuracy= " + str(accuracy))
train_accuracy = accuracy.eval({X: X_train, Y: Y_train})
test_accuary = accuracy.eval({X: X_test, Y: Y_test})
print("訓練集準確度:" + str(train_accuracy))
print("測試集準確度:" + str(test_accuary))
return (train_accuracy,test_accuary,parameters)
然後我們啓動模型:
_, _, parameters = model(X_train, Y_train, X_test, Y_test,num_epochs=150)
執行結果如下:
當前是第 0 代,成本值爲:1.912230797111988
當前是第 5 代,成本值爲:1.569796048104763
當前是第 10 代,成本值爲:1.0709842927753925
當前是第 15 代,成本值爲:0.8364478275179863
當前是第 20 代,成本值爲:0.6450640186667442
當前是第 25 代,成本值爲:0.5164481848478317
當前是第 30 代,成本值爲:0.4250429607927799
當前是第 35 代,成本值爲:0.3875112319365144
當前是第 40 代,成本值爲:0.39796690735965967
當前是第 45 代,成本值爲:0.35784107632935047
當前是第 50 代,成本值爲:0.33078993018716574
當前是第 55 代,成本值爲:0.2784481458365917
當前是第 60 代,成本值爲:0.23763000266626477
當前是第 65 代,成本值爲:0.23787363898009062
當前是第 70 代,成本值爲:0.2309840233065188
當前是第 75 代,成本值爲:0.20303455460816622
當前是第 80 代,成本值爲:0.19067543931305408
當前是第 85 代,成本值爲:0.16841116221621633
當前是第 90 代,成本值爲:0.13843759335577488
當前是第 95 代,成本值爲:0.16666325414553285
當前是第 100 代,成本值爲:0.16687324037775397
當前是第 105 代,成本值爲:0.13381452416069806
當前是第 110 代,成本值爲:0.1545729306526482
當前是第 115 代,成本值爲:0.10977528267540038
當前是第 120 代,成本值爲:0.08463473827578127
當前是第 125 代,成本值爲:0.11592008848674595
當前是第 130 代,成本值爲:0.13320672535337508
當前是第 135 代,成本值爲:0.09206865262240171
當前是第 140 代,成本值爲:0.09328121761791408
當前是第 145 代,成本值爲:0.08370728208683431
2.7 - 測試你自己的圖片(選做)