Redis-NoSql結構化數據庫
文章目錄
Redis
阿裡雲的這羣瘋子
- 分庫分表+水平拆分+Mysql叢集
Nosql
NoSQL,指的是非關係型的數據庫。NoSQL有時也稱作Not Only SQL的縮寫,是對不同於傳統的關係型數據庫的數據庫管理系統的統稱。
NoSQL用於超大規模數據的儲存。(例如谷歌或Facebook每天爲他們的使用者收集萬億位元的數據)。這些型別的數據儲存不需要固定的模式,無需多餘操作就可以橫向擴充套件。
- 方便擴充套件(數據庫之間沒有關係,很好擴充套件)
- 大數據量高效能(Redis 一秒可以寫8萬次,讀取11萬次)
- 數據型別是多樣型的(不需要實現設計數據庫,隨取隨用)
- 傳統的RDBMS
- 結構化組織
- SQL
- 數據和關係都存在單獨的表中
- 操作簡單,數據定義語言
- 嚴格的一致性
- 基礎的事務…
- Nosql
- 沒有固定的查詢語言
- 鍵值對儲存、列儲存、文件儲存、圖形數據庫(社交關係)
- 最終一致性
- CAP定理二和BASE理論(異地多活)
- 高效能,高可用,高可延伸…
NoSql的四大分類
- KV鍵值對
- 新浪:Redis、
- 美團:Redis+Tair
- 阿裡、百度:Redis+memecache
- 文件型的數據庫(bson格式)
- MongDB:基於分佈式檔案儲存的數據庫
- C++編寫的,主要用來處理大量的文件
- 介於關係型和非關係型數據庫的中間產品
- 非關係數據庫中功能最豐富,最像關係型數據庫的
- 列儲存數據庫
- HBase
- 分佈式檔案系統
- 影象關係數據庫
- 存的是關係
- Neo4j,infoGrid
Redis基礎
- Remote Dictionary Server :遠端字典服務
- 是一個開源的ANSI,C語言編寫的、支援網路,可基於記憶體亦可持久化的日誌型
- Key-Value數據庫,並提供多種語言的API
- 記憶體儲存、持久化(rdb、aof)
- 效率高,可以用於快取記憶體
- 發佈訂閱系統,地圖資訊分析、計時器、計數器
- 多樣的數據型別、持久化、叢集、事務
- 預設埠6379
Linux下安裝Redis
Redis效能測試(redis-benchmark)
- 參數列表
| 序號 | 選項 | 描述 | 預設值 |
|---|---|---|---|
| 1 | -h | 指定伺服器主機名 | 127.0.0.1 |
| 2 | -p | 指定伺服器埠 | 6379 |
| 3 | -s | 指定伺服器 socket | |
| 4 | -c | 指定併發連線數 | 50 |
| 5 | -n | 指定請求數 | 10000 |
| 6 | -d | 以位元組的形式指定 SET/GET 值的數據大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用隨機 key, SADD 使用隨機值 | |
| 9 | -P | 通過管道傳輸 請求 | 1 |
| 10 | -q | 強制退出 redis。僅顯示 query/sec 值 | |
| 11 | –csv | 以 CSV 格式輸出 | |
| 12 | -l | 生成回圈,永久執行測試 | |
| 13 | -t | 僅執行以逗號分隔的測試命令列表。 | |
| 14 | -I | Idle 模式。僅開啓 N 個 idle 連線並等待。 |
- 例如:redis-benchmark -h localhost -p 6379 -c 100 -n 10000
Redis基本知識
- redis預設有16個數據庫:組態檔中:databases 16
- 預設使用第0個數據庫
- 切換數據庫:select 數位
- 檢視數據庫大小:desize
- 清空當前數據庫:flushdb
- 清空所有數據庫:flushall
- 埠號:6379
- Redis是單執行緒的
- Redis是基於記憶體操作的
- Redis的效能瓶頸是根據記憶體,網路頻寬,可以使用單執行緒實現,所以就使用單執行緒了
- 多執行緒(CPU上下文切換效率慢),對於記憶體系統來說,沒有CPU上下文切換效率就是最高的
- 多次讀寫都在一塊CPU上
Redis五大數據型別
- Redis支援五種數據型別:string(字串),hash(雜湊),list(列表),set(集合)及zset(sorted set:有序集合)。
Redis-Key
- 檢視所有的key:keys *
- 判斷是否存在:exit key
- 設定過期時間:exit key time
- 檢視當前key的剩餘時間:ttl name
- 移除數據:move key
- 檢視key數據型別:type key
- 不會的命令去官網查詢:命令查詢頁
String(字串)
- 設定值:set key value
- 獲得值:get key
- 追加字串:append key value,如果不存在,新建一個字串
- 值加一:incr key
- 值減一:decr key
- 值加多:incrby key value
- 值減多:decrby key value
- 擷取字串:getrange key 0 -1
- 替換指定位置的字串:setrange key 2 value
- 設定過期時間:setex key seconds value
- 不存在在設定:setnx key value,(不存在就建立,存在就建立失敗)
- 批次設定:mset k1 v1 k2 v2 k3 v3
- 批次獲取:mget k1 k2
- msetnx:msetnx k1 v1,原子性操作,要麼一起成功,要麼一起失敗
- 先獲取再設定:getset key value,返回原值,設定新值
List(列表/可重複)
- 實際上是一個鏈表
- 在兩邊插入或者改動值,效率最高,中間元素相對較低
- 所有的List命令都是以L開頭的
- 將值放在列表頭部:lpush list v1 v2 v3
- 將值放在列表尾部:rpush list v1 v2 v3
- 檢視位置值:lrange list 0 -1
- 左邊移除一個值:lpop list
- 右邊移除一個值:rpop list
- 通過下表獲取列表中的值:Lindex list 3
- 返回列表長度:Llen list
- 移除指定個數的值:Lrem list 1 value
- 通過下表修剪擷取列表:Ltrim list 1 2
- 移除列表的最後一個元素,將她移動到新的列表中:rpopLpush list1 list2
- 將列表中指定下標的值替換爲另外一個值:lset list index value,如果不存在列表或下表會報錯
- 在指定值的前面或後面插入值:Linsert list before|after 指定值 插入值
Set(集合/不能重複)
- 無序不重複集合
- 新增集合元素:sadd myset value
- 返回集合所有值:smembers myset
- 判斷元素是否在集閤中:sismember myset value
- 獲取set集閤中內容個數:scard myset
- 移除指定元素:srem myet value
- 隨機抽選一個元素:srandmember myset number,number表示抽出幾個
- 隨機刪除一些set元素:spop myset
- 將一個指定的值,移動到另外一個set中:smove myset myset2 value
- 差集:sdiff myset myset2
- 交集:sinter myset myset2
- 並集:sunion myset myset2
Hash(雜湊)
- key-map:這個值是一個map集合
- 新增一個值:hset myhash key value
- 查詢一個值:hget myhash key
- 新增多個值:hmset myhash k1 v1 k2 v2
- 得到多個值:hmget myhash k1 k2
- 獲取所有的值:hgetall myhash
- 刪除指定值:hdel myhash key
- 獲取hash表的長度:hlen myhash
- 判斷指定欄位是否存在:hexists myhash key
- 獲取所有欄位:hkeys myhash
- 獲取所有值:hvals myhash
- 指定增量:Hincrby myhash key number
- 如果不存在設定,存在則不設定:hsetnx myhash key value
Zset(有序集合)
- 在set的基礎上新增一個值用來排序
- 新增一個值:zadd myset 1 value
- 檢視所有值:zrange myset 0 -1
- 從小到大排序:zrangebyscore myset -inf +inf
- 從大到小排序:zrevrange myset 0 -1
- 獲取集閤中的個數:zcard myset
- 統計區間個數:zcount myset 1 4,統計1到4之間的個數
Redis三種特殊數據型別
geospatial(地理位置)
- 主要用於儲存地理位置資訊,並對儲存的資訊進行操作
- geoadd:新增地理位置的座標。geoadd key 緯度 經度 名稱
- geopos:獲取地理位置的座標。geopos key 名稱
- geodist:計算兩個位置之間的距離。geodist key 名稱 名稱 單位單位:m,km,英裡mi,英尺ft
- georadius:根據使用者給定的經緯度座標來獲取指定範圍內的地理位置集合。georadius key 緯度 經度 半徑大小
- 參數 whithdish:顯示到中間距離的位置
- 參數 withcoord:顯示他人的定位資訊
- 參數 count 1:顯示指定數量的結果
- georadiusbymember:根據儲存在位置集合裏面的某個地點獲取指定範圍內的地理位置集合。georadiusbymember key 名稱 半徑大小
- geohash:返回一個或多個位置物件的 geohash 值。
- 底層是zset集合,使用zset命令
hyperloglog(統計數據結構)
- 基數統計演算法
- 佔用記憶體是固定的,12KB,有0.81%錯誤率
- 建立一組元素:PFadd mykey v1 v2 v3
- 統計基數數量:PFcount mykey
- 合併兩組:PFmerge 新mykey 原mykey 原mykey
bitmaps(點陣圖數據結構)
- 操作二進制位來記錄,只有01
- 記錄數據:setbit sign 0 0
- 檢視數據:getbit sign 0
- 統計爲1個數:bitcount sign
Redis基本事務操作
- Redis單條指令保證原子性,但是事務不保證原子性
- 本質:一組命令的集合,一個事務中的所有命令都會被序列化,在事務執行過程中,按照順序執行
- 沒有隔離級別的概念
- 所有命令在事務中,並沒有直接被執行,只有發起執行命令才執行
- 執行過程:
- 開啓事務(multi)
- 命令入隊
- 執行事務(exec)
- 取消事務(discard)
- 執行完事務就結束
樂觀鎖
- watch可以當作redis的樂觀鎖操作:watch key,unwatch key
Jedis
- 官方推薦的java連線開發工具
- 匯入依賴
<!--jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
<!--fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
- 遠端連線測試:連線遠端redis
SpringBoot整合Redis(lettuce)
-
Springboot操作數據:Spring-data jpa jdbc mongodb redis
-
在springBoot2.x原jedis被替換爲lettuce
- jedis:採用直連,多個執行緒操作不安全,要避免不安全的,使用jedis pool連線池。更像BIO模式
- lettuce採用netty,範例可以在多個執行緒中進行共用,不存線上程不安全的情況,減少執行緒數據,更像NIO模式
-
SpringBoot所有的設定類都有一個自動設定類:RedisAutoConfiguration
- 帶入依賴
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 組態檔
spring.redis.host=119.3.226.219
spring.redis.password=123456
spring.redis.port=6379
- 測試連線
@SpringBootTest
class DemoApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
/**
* opsForValue(); 操作字串
* opsForList(); 操作list
* opsForHash(); 操作hash
* opsForSet(); 操作set
* opsForZSet(); 操作zset
* opsForGeo(); 操作地圖
* opsForHyperLogLog();
*/
redisTemplate.opsForValue().set("huang","hhhhh");
Object huang = redisTemplate.opsForValue().get("huang");
System.out.println(huang);
//常用的方法可以通過redisTemplate點出來
//獲取連線的數據庫物件
RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
connection.flushDb();
}
}
Redis.conf詳解
-
組態檔對大小寫不敏感
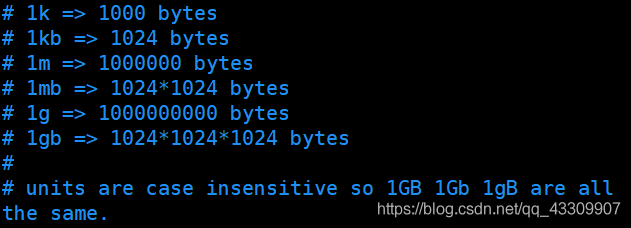
-
可以包含多個組態檔
-
網路設定
- 系結IP,指定哪些ip可以存取 bing 127.0.0.1
- 是否受保護:protected-mode no
- 埠設定:port 6379
-
通用設定
- 是否以守護行程開啓,後臺執行:daemonize yes
- 組態檔:pidfile /var/run/redis_6379.pid,如果以後台方式進程,就要指定一個pid檔案
- 日誌級別:loglevel notice
- 生成的日誌檔名:logfile 「」
- 預設的數據庫數量:databases 16
- 是否顯示logo:always-show-logo yes
-
快照:SNAPSHOTTING
- 持久化,在規定的時間內執行了多少次操作則會持久化到檔案 .rdb .aof檔案
- 沒有持久化,斷電即失去
- 900秒內至少有一個key修改,就進行持久化 save 900 1
- 持久化如果出錯,是否繼續工作:stop-writes-on-bgsave-error yes
- 是否壓縮rdb檔案:rdbcompression yes,需要消耗cpu資源
- 儲存rdb檔案的時候進行校驗檢查:rdbchecksum yes
- rdb儲存檔名和目錄:dbfilename dump.rdb dir ./
-
複製:REPLICATION
- 主機地址埠號:replicaof < masterip > < masterport >
- 主機密碼:masterauth < master-password >
-
安全:SECURITY
- 設定命令:requirepass 123456
-
用戶端:CLIENTS
- 設定最大的用戶端連線數:maxclients 10000
- 設定最大的記憶體容量:maxmemory < bytes >
- 記憶體到達上限的處理策略:maxmemory-policy noeviction
- maxmemory-policy 六種方式
- volatile-lru:只對設定了過期時間的key進行LRU(預設值)
- allkeys-lru : 刪除lru演算法的key
- volatile-random:隨機刪除即將過期key
- allkeys-random:隨機刪除
- volatile-ttl : 刪除即將過期的
- noeviction : 永不過期,返回錯誤
- maxmemory-policy 六種方式
-
aof設定:APPEND ONLY MODE
- 預設不開啓:appendonly no,大部分情況rdb夠用
- 持久化檔案名字:appendfilename 「appendonly.aof」
- 同步時間:appendfsync everysec,
- everysec:每秒同步一次
- always:每次修改都會同步
- no:不執行sync,操作系統自己同步,最快
持久化
RDB
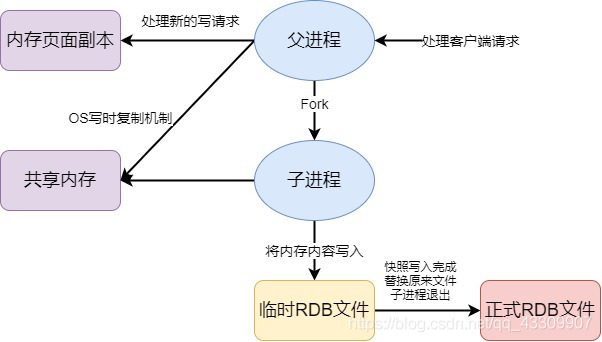
- 在指定時間間隔內將記憶體中的數據集快照寫入磁碟,Snapshot快照,恢復時直接將問價讀到記憶體中
Redis會單獨建立一個子進程來持久化,將數據寫到一個臨時檔案中,持久化結束,替換之前持久化的檔案,整個過程主進程不進行IO操作,確保了效能,如果需要大規模進行數據恢復,且對數據恢復的完整性不是非常敏感,那麼RDB比AOF更加有效,RDB的缺點就是最後一次持久化後數據可能丟失,我們預設的就是RDB,一般情況下不需要修改這個設定
-
rdb儲存的檔案預設是:dunp.rdb,在
-
觸發機制 機製:
- save規則滿足
- 執行flushall
- 推出redis
-
恢復RDB檔案:將RDB檔案放在redis啓動目錄下就可以了,啓動時會自動檢測檔案恢復數據
AOF(Append Only File)
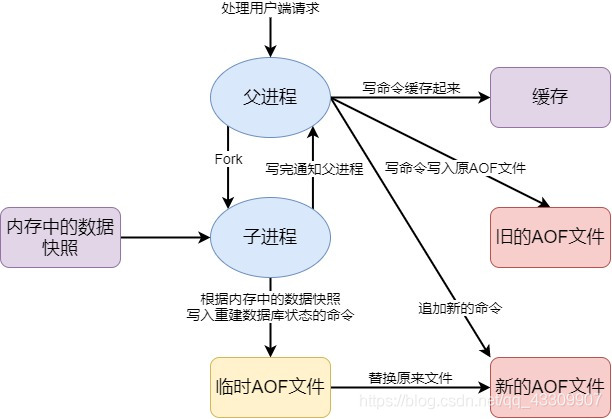
- 將我們所有的命令都記錄下來,恢復的時候把檔案全部執行一遍
- 以日誌的形式來記錄每個寫操作,將Redis執行過的所有指令記錄下來(寫操作),只許追加檔案,不可以改寫檔案,redis啓動之初會讀取檔案重新構建數據
- Aof儲存的是appendonly.aof
- 將組態檔中的appendonly 改爲yes,重新啓動既可以生效
- 如果aof組態檔有錯誤,redis啓動不了,用 redis-check-aof --fix appendonly.aof,修復即可
Redis叢集
- 主從複製,讀寫分離,
環境設定
- 設定:只設定從庫,不用設定主庫
- 檢視當前庫資訊:info replication
# Replication
role:master # 角色
connected_slaves:0 # 從機個數
-
從機設定修改內容:(本機測試)
- 日誌輸出命名:logfile 「」
- 備份名稱:dbfilename name.rdb
- 埠號
- pid名稱
-
預設是主庫,只用設定從機就好了
- 從機中命令設定設定:slaveof host port
- 從機中檔案設定:
- 主機地址埠號:replicaof < masterip > < masterport >,(重新啓動變回主機)
- 主機密碼:masterauth < master-password >
複製原理
-
主機負責寫,從機負責讀取
-
只要是從機就會馬上負責
-
從機啓動連線到master後會發送一個sync同步命令
-
Master接到命令,啓動後臺的存檔進程,同時蒐集 搜集所有接受到的用於修改數據集命令,將整個檔案傳到從機,完成一次同步。
- 全量複製:從機接收到數據庫檔案數據後,將其存檔並載入到記憶體中
- 增量複製:Master繼續將新的所有收集到的修改命令依次傳給從機完成同步
-
斷開從新連線就會觸發全量複製
-
如果主機斷開可以手動使用命令是自己成爲主機:slaveof no one
哨兵模式
-
主從切換技術的方法是:當主伺服器宕機後,需要手動把一臺從伺服器切換爲主伺服器,這就需要人工幹預,費事費力,還會造成一段時間內服務不可用。這不是一種推薦的方式,更多時候,我們優先考慮哨兵模式。
-
哨兵模式是一種特殊的模式,首先Redis提供了哨兵的命令,哨兵是一個獨立的進程,作爲進程,它會獨立執行。其原理是哨兵通過發送命令,等待Redis伺服器響應,從而監控執行的多個Redis範例。
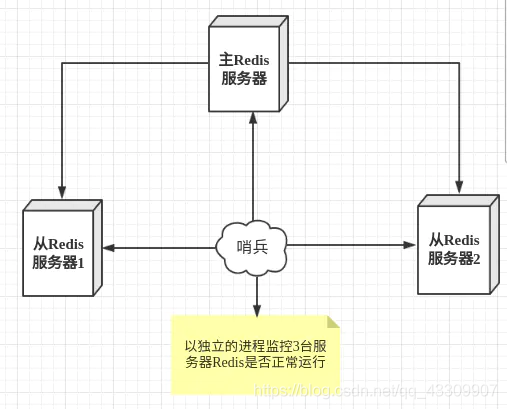
-
作用:
- 通過發送命令,讓Redis伺服器返回監控其執行狀態,包括主伺服器和從伺服器。
- 當哨兵監測到master宕機,會自動將slave切換成master,然後通過發佈訂閱模式通知其他的從伺服器,修改組態檔,讓它們切換主機。
-
一個哨兵進程對Redis伺服器進行監控,可能會出現問題,爲此,我們可以使用多個哨兵進行監控。各個哨兵之間還會進行監控,這樣就形成了多哨兵模式。
用文字描述一下故障切換(failover)的過程。假設主伺服器宕機,哨兵1先檢測到這個結果,系統並不會馬上進行failover過程,僅僅是哨兵1主觀的認爲主伺服器不可用,這個現象成爲主觀下線。當後面的哨兵也檢測到主伺服器不可用,並且數量達到一定值時,那麼哨兵之間就會進行一次投票,投票的結果由一個哨兵發起,進行failover操作。切換成功後,就會通過發佈訂閱模式,讓各個哨兵把自己監控的從伺服器實現切換主機,這個過程稱爲客觀下線。這樣對於用戶端而言,一切都是透明的。
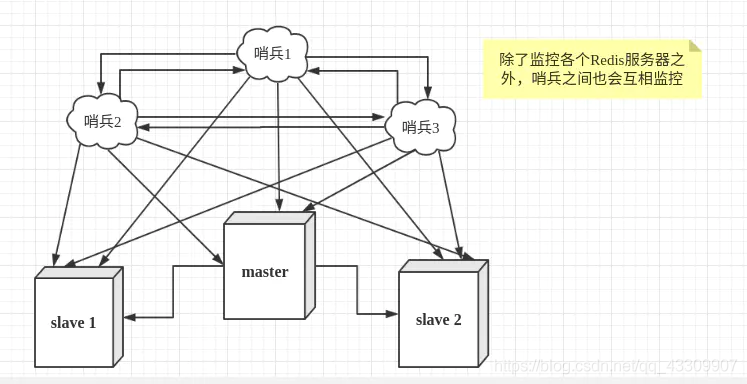
設定哨兵
- 在Redis安裝目錄下有一個sentinel.conf檔案
sentinel monitor myredis ip 埠號 1
# 1 代表主機掛了,從機投票讓誰接替,票數最多成爲主機
- 啓動哨兵:redis-sentinel myconfig/sentinel.conf
- 如果主節點斷開了,這個時候會從從機中按照演算法選擇一個作爲主機
- 如果主機斷開後回來,只能歸併到新主機下當作從機
| 設定項 | 參數型別 | 作用 |
|---|---|---|
| port | 整數 | 啓動哨兵進程埠 |
| dir | 資料夾目錄 | 哨兵進程服務臨時資料夾,預設爲/tmp,要保證有可寫入的許可權 |
| sentinel down-after-milliseconds | <服務名稱><毫秒數(整數)> | 指定哨兵在監控Redis服務時,當Redis服務在一個預設毫秒數內都無法回答時,單個哨兵認爲的主觀下線時間,預設爲30000(30秒) |
| sentinel parallel-syncs | <服務名稱><伺服器數(整數)> | 指定可以有多少個Redis服務同步新的主機,一般而言,這個數位越小同步時間越長,而越大,則對網路資源要求越高 |
| sentinel failover-timeout | <服務名稱><毫秒數(整數)> | 指定故障切換允許的毫秒數,超過這個時間,就認爲故障切換失敗,預設爲3分鐘 |
| sentinel notification-script | <服務名稱><指令碼路徑> | 指定sentinel檢測到該監控的redis範例指向的範例異常時,呼叫的報警指令碼。該設定項可選,比較常用 |
高併發問題
快取穿透
使用者想要查詢一個數據,Redis中沒有,會向持久層數據庫中查詢,發現也沒有,查詢失敗
當有很多使用者時,快取如果都沒有命中,就都去請求持久層數據庫,會給持久層數據庫帶來很大壓力,這個時候相當於快取穿透
- 解決方案:
- 布隆過濾器
- 一種數據結構,對所有可能查詢的參數以hash形式儲存,在控制層先進行校驗,不符合則丟棄,避免對底層儲存系統的查詢壓力
- 快取空物件
- 當儲存層不命中後,即使返回的空物件也將其快取起來,同時設定一個過期時間,之後再存取這個數據將會從快取中獲取,保護後端資源
- 布隆過濾器
快取擊穿
- 是指一個key非常熱點,在不停的扛着高併發,當這個key在失效的瞬間,這個key在失效的瞬間,持續的大併發就會擊破快取,直接請求數據庫,就像在一個屏障上鑿開了一個洞,或者是也該key在過期的瞬間,有大量的請求併發存取,會同時存取數據庫來查詢最新數據,並且回寫快取,會導致數據庫瞬間壓力過大
- 解決方案:
- 設定熱點數據永不過期
- 從快取層面來看,沒有設定過期時間,所以不會出現熱點key過期後產生的問題
- 加互斥鎖
- 分佈式鎖:使用分佈式鎖,保證對於每個key同時只有一個執行緒去查詢後端業務,其他執行緒沒有獲得分佈式鎖的許可權,因此只需要等待即可,這種方式將高併發的壓力轉移到了分佈式鎖,因此對分佈式鎖的考驗很大
- 設定熱點數據永不過期
雪崩
-
快取雪崩:某一個時間段,快取集中過期失效,Redis宕機
-
解決方案:
- redis高可用
- 增加Redis,搭建叢集(異地多活)
- 限流降級
- 快取失效後,通過加鎖或佇列來控制讀數據庫寫快取的執行緒數量,比如對某個key只允許一個執行緒查詢數據和寫快取,其他執行緒等待
- 數據預熱
- 數據加熱的含義就是在正式部署之前,把可能的數據預先存取一遍,這樣部分可能大量存取的數據就會載入到快取中,在即將發生大併發存取前手動觸發載入快取不同的key,設定不同過期時間,讓快取失效的時間點儘量均勻
- redis高可用