ES定時清理索引
ES 定時清理索引
ES會將索引存放在記憶體中,以加速查詢效能,但如果長期將使用不頻繁的數據放入記憶體,將會浪費我們的一些資源,下面 下麪先舉例子一個由於無用數據過多導致的問題
自動清理指令碼
#!/bin/bash
###################################
#刪除早於十天的ES叢集的索引
###################################
function delete_indices() {
comp_date=`date -d "10 day ago" +"%Y-%m-%d"`
date1="$1 00:00:00"
date2="$comp_date 00:00:00"
t1=`date -d "$date1" +%s`
t2=`date -d "$date2" +%s`
if [ $t1 -le $t2 ]; then
echo "$1時間早於$comp_date,進行索引刪除"
#轉換一下格式,將類似2017-10-01格式轉化爲2017.10.01
format_date=`echo $1| sed 's/-/\./g'`
curl -XDELETE http://127.0.0.1:9200/*$format_date
fi
}
curl -XGET http://127.0.0.1:9200/_cat/indices | awk -F" " '{print $3}' | awk -F"-" '{print $NF}' | egrep "[0-9]*\.[0-9]*\.[0-9]*" | sort | uniq | sed 's/\./-/g' | while read LINE
do
#呼叫索引刪除函數
echo "delete indexes..."
delete_indices $LINE
echo "deleted success"
done
不清理的危害
我有一個自己的伺服器,部署了一些常見的中介軟體docker容器,通過 fluentd 將他們的日誌輸出到 ES中,在 kibana 中進行展示。
有天手機收到郵件告警,說ES佔用CPU異常(自己整的docker監控,對自己部署的容器進行了監控與告警)。
於是到 Grafana 中檢視,發現ES的CPU佔用開始尖刺形而後長期過高,猜測是GC導致的。
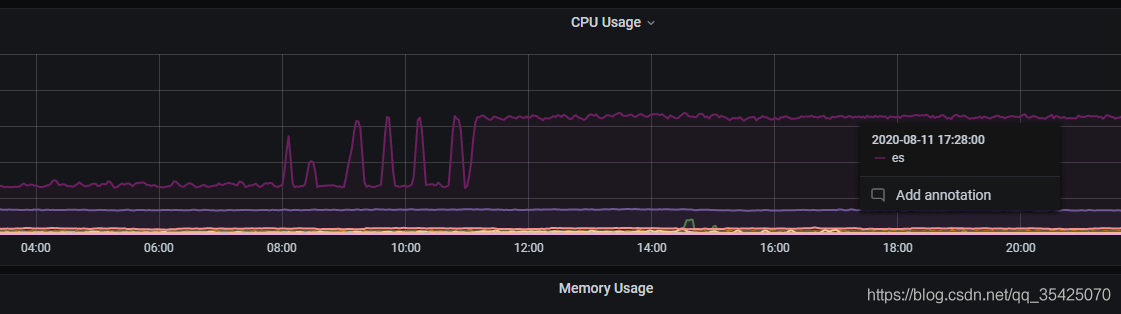
登錄伺服器檢視ES的GC日誌,如下:頻繁觸發GC,可回收垃圾較少,且佔用時間過高(5s)。
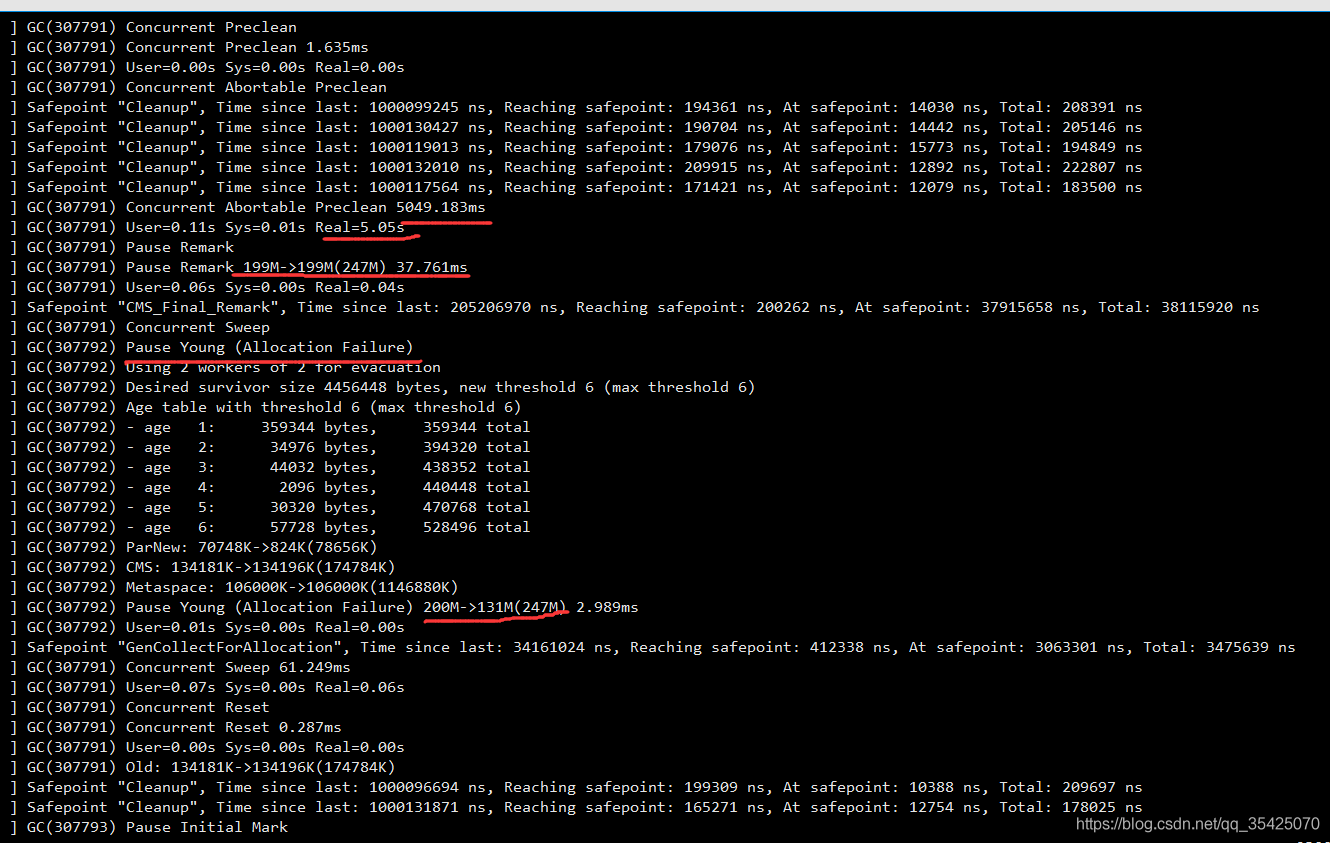
而正常應該是這種,偶爾一次young GC,年輕代每次回收約90%的垃圾
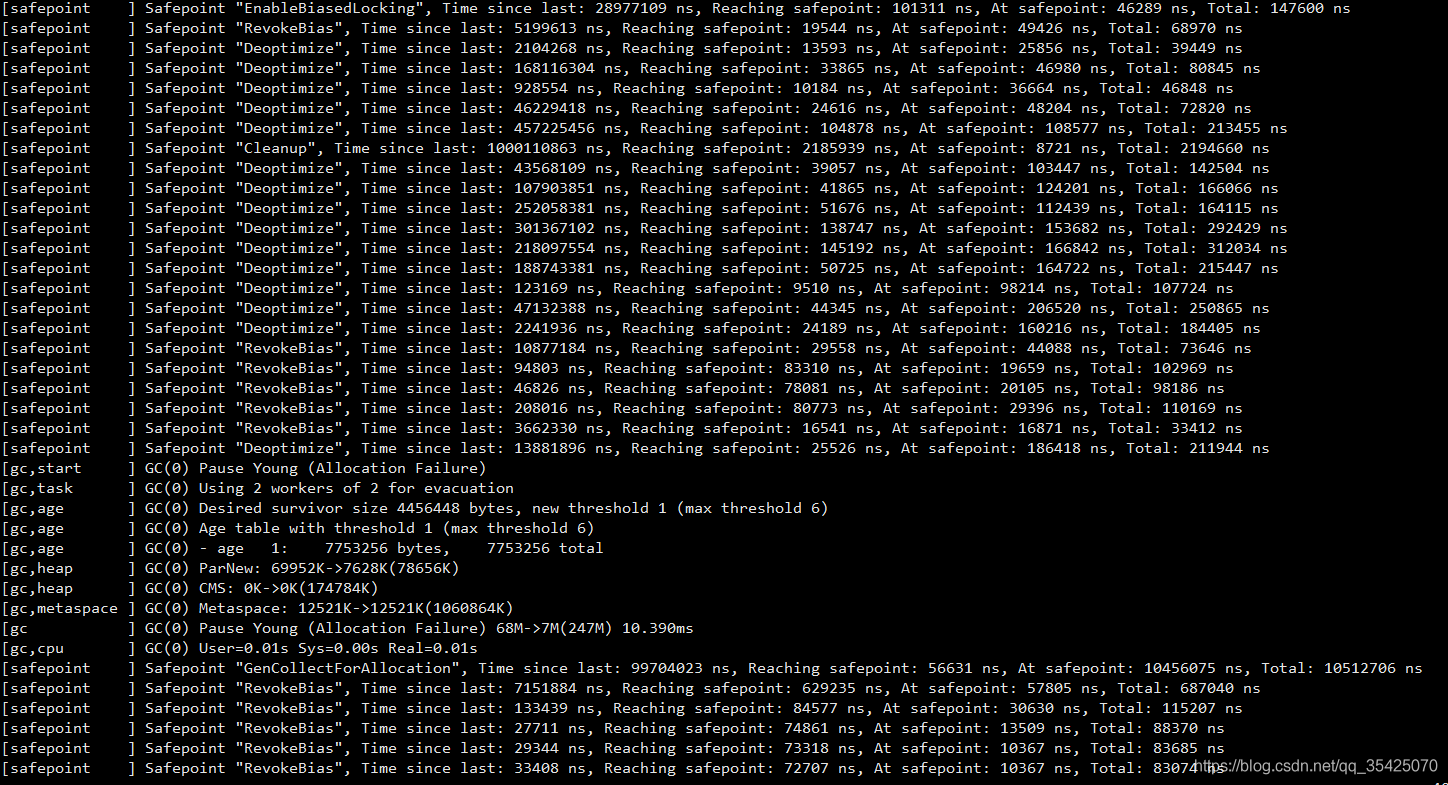
因爲我伺服器設定較低,只能給ES很少的資源,限制了其記憶體,當因爲索引過多,記憶體達到上限後不斷觸發GC(可以看到基本每兩個安全點都要觸發一次GC),由於JVM認爲他們是不能回收的,故每次基本不會回收東西,導致頻繁觸發,我這裏使用的是ES預設CMS 垃圾回收器,CMS垃圾回收器在識別垃圾時,會掃描JVM堆空間中的物件,這部分會佔用較多CPU。
既然找到了根本原因(頻繁觸發GC),那就要對症下藥,把無用垃圾的幹掉,將CPU佔用降下去。
進入ESHD,發現索引數量確實有點多,記憶體佔用達到限定值。
進入 kibana,將無用的索引先手動清理如
DELETE /fluentd.*.202007*
刪掉過舊的日誌索引,清理後再到grafana檢視。

爲了更好的避免該問題,需要定時清理ES中無用的索引。這裏爲了省事,寫了一個指令碼,在文章首部。
總結
因爲沒有特別重要的服務,故沒及時清理與優化,舊的日誌太多,2個月前都有,導致ES中無用索引較多,導致頻繁GC,導致CPU佔用過高。
這裏還有其他幾個點可以探索,爲什麼是早上8點開始有"着火"的趨勢?
- 每新過一天,fluentd 都會爲每個採集的容器生成新的日誌索引,可以看到其實每天的早上8點都有上升的趨勢。
- 差8小時?時區原因(+8時區)
