Lua:05---string字串型別:lua字串的使用、字串標準庫、Unicode標準庫
2020-08-11 23:24:24
一、Lua字串介紹
- Lua語言中的字串是一串位元組組成的序列。在Lua語言中,字元使用8個位元位來儲存
- Lua語言中的字串可以儲存包括空字元在內的所有數值程式碼,這意味着我們可以在字串中儲存任意的二進制數據
- 我們也可以使用任意一種編碼方式(UTF-8、UTF-16等)來儲存Unicode字串(在文章下面 下麪會詳細介紹)
二、字串常數
- 我們可以使用一對雙引號或者單引號來宣告字串常數。例如:
a = "a line"
a
b = 'another line'
b
- 雙引號和單引號宣告字串是等價的,區別在於:
- 使用雙引號宣告的字串中出現單引號時,單引號可以不用跳脫
- 使用單引號宣告的字串中出現單引號時,雙引號可以不用跳脫
a = "I am 'C++'"
a
b = 'I am "Lua"'
b

- 雙引號與單引號如何選擇使用呢?
- 在同一個程式中,一般規定統一使用哪種形式的字串
- 另外,根據實際的需求使用哪一種。例如,在XML文字中會有雙引號,因此一個操作XML的庫可能就會使用單引號來宣告XML片段
三、跳脫字元
- Lua支援C語言風格的跳脫字元

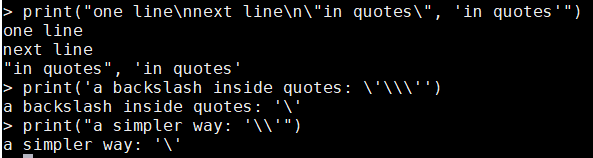
- 下面 下麪是一些使用案例
print("one line\nnext line\n\"in quotes\", 'in quotes'")
print('a backslash inside quotes: \'\\\'')
print("a simpler way: '\\'")
其他跳脫模式
- 在字串中,你還可以通過下面 下麪的方式來宣告字元
- \ddd:其中ddd是由最多3個十進制數位組成的序列(其中d可以爲1~3個)
- \xhh:hh是由兩個且必須是兩個十六進制數位組成的序列(此處的h必須爲2個)
- 演示案例:在一個使用ASCII編碼的系統中,下面 下麪兩個字串是等價於的
- 0x41(十進制的65)在ASCII編碼中對應的字元爲A(此處就使用到了上面的\xhh模式)
- \10對應的就是換行符\n
- \049對應數位1(此處就用到了上面的\ddd模式)
"ALO\n123\"" '\x41LO\10\04923"'
- 例如,我們還可以把上述字串全部改爲十六進制,來表示字串中的每一個字元
'\x41\x4c\x4f\x0a\x31\x32\x33\x22'


跳脫序列
- 從Lua 5.3開始,可以使用跳脫序列\u{h...h}來宣告UTF-8字元,花括號中可以支援任意有效的十六進制
- 例如:
"\u{3b1} \u{3b2} \u{3b3}"
四、字串的長度
- 可以使用長度操作符(#)獲取字串的長度
- 備註:該操作符返回字串佔用的位元組數,在某些編碼中,這個值可能與字串中字元的個數不同
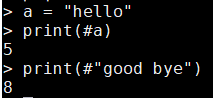
- 例如:
a = "hello"
print(#a)
print(#"good bye")
五、字串的拼接
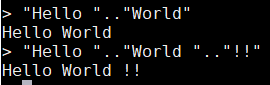
- 可以使用連線操作符..來進行字串連線。例如
"Hello ".."World"
"Hello ".."World ".."!!"
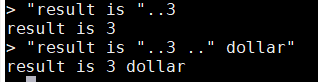
- 如果運算元中有數值,那麼會把數值轉換爲字串。例如:
- 注意:數位後面使用連線符時,必須要用一個空格隔開,否則Lua會把數位後面的第一個.當成小數點
"result is "..3
-- 3與後面的..必須要有空格
"result is "..3 .." dollar"
- 注意,在Lua中,字串是不可變變數。字串連線總是建立一個新字串,而不會改變原來運算元的字串。例如
a = "Hello"
a.." World"
a

六、長字串/多行字串
- 像常長註釋/多行註釋一樣,可以使用一對雙方括號來宣告長字串/多行字串常數
- 例如:
-- </html>之後會兩次換行, 一次爲page的末尾有換行, 另一次爲print()的換行
page = [[
<html>
<head>
<title> An HTML Page</tile>
</head>
<body>
<a href="http://www.lua.org">Lua</a>
</body>
</html>
]]
print(page)

兩個注意事項
- 在這種字串中,跳脫序列不會被跳脫
page = [[ Hello \n World ]] print(page)
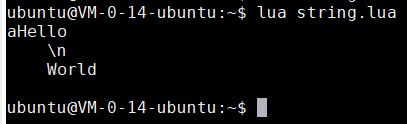
- 如果多行字串中的第一個字元是換行符,那麼這個換行符會被忽略
-- 字串開始換了兩次行, 但是第一次換行被忽略了 page = [[ Hello \n World ]] print(page)
-- 第一個字元不是換行, 因此不會換行 page = [[aHello \n World ]] print(page)


特殊字串宣告
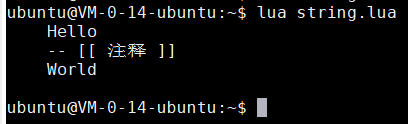
- 有時候長字串可能會包含"a=b[c[i]]"這樣的內容,或者字串中可能有被註釋掉的程式碼"--[[]]",所以其會與長字串的宣告產生衝突。例如下面 下麪的程式碼在執行時產生了錯誤
string = [[ Hello -- [[ 註釋 ]] World ]] print(string)
- 爲了應對這種情況,可以在左方括號之間加上任意數量的等號,例如[===[,這樣當長字串遇到]===]時纔會結束
- 這種方式的原理是,Lua語言的語法掃描器會忽略中間所含等號數量不相同的方括號
- 對於註釋而言,這種機制 機製也同樣使用,例如可以使用--[=[]=]來表示長註釋
string = [===[ Hello -- [[ 註釋 ]] World ]===] print(string)

\z跳脫字元
- 當代嗎中需要使用常數文字時,使用長字串是一種理想的選擇。但是,對於非文字的常數我們不應該濫用長字串。雖然Lua語言中的字串常數可以包含任意位元組,但是濫用這個特性並不明智(例如,可能導致某些文字編輯器出現異常)。同時,像"\r\n"一樣的EOF序列在被讀取的時候可能會被歸一化爲"\n"
- 作爲替代方案,最好就是把這些可能引起歧義的二進制數據用十進制數值或者十六進制的數值跳脫序列進行表示,例如"\x13\x01\xA1\xBB"。不過,由於這種跳脫表示形成的字串往往很長,所以對於長字串來說仍可能是個問題
- 針對這種問題,Lua 5.2開始引入了跳脫序列\z,該跳脫符會跳過其後的所有空白字元,直到遇到第一個非空白字元
- 演示案例:
data1 = "\x00\x01\x02\x0A\x0B" -- [[ 這種宣告方式是錯誤的 data1 = "\x00\x01\x02 \x0A\x0B" ]] -- \z會忽略\x02後面的所有換行符和空白符 data2 = "\x00\x01\x02\z \x0A\x0B"
七、強制型別轉換
自動強制型別轉換
- Lua語言在執行時提供了數值與字串之間的自動轉換
- 字串轉數位:
- 針對字串的所有算術操作都會嘗試將字串轉換爲數值,然後再進行計算
- 不僅僅在算術操作時進行這種強制型別轉轉,還會在任何需要數值的情況下進行,例如函數math.sin()的參數
'2' - '1' -- 不可以進行強制型別轉換, 因爲H不是數位 'H' - '1' -- 會將參數轉換爲90 math.sin('90')
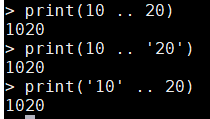
- 數位轉字串:在需要字串的地方出現了數值時,它就會把數值轉換爲字串(這種使用在上面已經介紹過了)
print(10 .. 20) print(10 .. '20') print('10' .. 20)
- 備註:與算術操作不同,比較操作符不會對運算元進行強制型別轉換。爲了避免出現不一致的結果,當比較操作符中混用了字串和數值時,Lua語言會拋出異常。例如
2 < 15 -- 第一個字元2比第一個字元1大, 因此直接返回false "2" < "15" -- 拋出異常, 一個爲數值, 另一個爲字串 2 < "15"


顯式轉換:字串轉數值(tonumber()函數)
- 可以呼叫該函數顯式地將字串轉換爲數值。例如:
tonumber(" -3") tonumber("10e4") tonumber("0x1.3p-4")
- 當字串的內容不能表示爲有效數位時將會返回nil。例如:
tonumber("10e") tonumber("a")
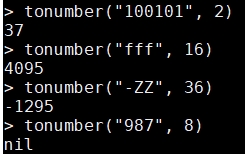
- tonumber()預設情況下使用的是十進制,但是也可以指明二進制到三十六進制之間的任意進位制。例如:
tonumber("100101", 2) tonumber("fff", 16) tonumber("-ZZ", 36) -- 錯誤的, 因爲9超出了八進制的範圍 tonumber("987", 8)


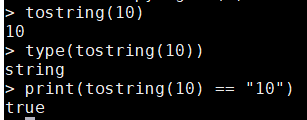
顯式轉換:數值轉字串(tostring()函數)
- 可以呼叫該函數顯式地將數值轉換爲字串。例如:
tostring(10) type(tostring(10)) print(tostring(10) == "10")
- 這種轉換並不能控制輸出字串的格式(例如,結果中十進制數位的個數),在文章下面 下麪我們會介紹通過函數string.format()來全面的控制字串的格式
八、字串標準庫
- Lua的字串標準庫提供了很多功能同來處理字串
- 字串標準庫預設處理的是1位元組8bit的字元(數值爲0~255之間)。這對於某些編碼方式(例如ASCII或ISO-8859-1)適用,但對所有的Unicode編碼來說都不適用。不過儘管如此,我們在文章下面 下麪可以看到字串標準庫的某些功能對UTF-8編碼來說還是非常有用的
- 下面 下麪是一些常用的函數:
- string.len(s):返回字串s的長度
- string.rep(s, n):將字串s重複n此的結果。例如,可以通過呼叫string.rep("a", 2^20)來建立一個1MB大小的字串(例如用於測試)
- string.reverse(s):返回一份s的副本(s本身不變),其中將s進行反轉
- string.lower(s):返回一份s的副本(s本身不變),其中所有的大寫字母都變爲小寫字母
- string.upper(s):返回一份s的副本(s本身不變),其中所有的小寫字母都變爲大寫字母
string.len("Hello World")
string.rep("abc", 3)
string.reverse("A Long Line!")
string.lower("A Long Line!")
string.upper("A Long Line!")

- 其中lower()和upper()函數可以用來在忽略大小寫的差異的原則下比較兩個字串
a = "Hello"
b = "World"
string.lower(a) < string.lower(b)
stirng.sub()
- string.sub(s, i, j):從字串s中提取第i個到第j個字元(包括i和j),字串的索引從1開始。例如:
s ="HelloWorld" string.sub(s, 1, 1) string.sub(s, 1, 3)
- 該函數還支援負數索引:
- 負數索引從字串的結尾開始計數(從-1開始)
- -1代表最後一個字元,-2代表倒數第二個字元,以此類推.....
s = "HelloWorld" -- 得到字串s從開頭開始長度爲5的字首 string.sub(s, 1, 5) -- 得到字串s從第6個字元開始的後綴 string.sub(s, 6, -1) -- 去掉字串s的第一個字元和最後一個字元 string.sub(s, 2, -2)
- 該函數不會改變參數所指的字串


string.char()、string.byte()
- string.char():接收0個或多個整數作爲參數,然後將每個整數轉換爲對應的字元,最後返回這些字元連線而成的字串
string.char(65) string.char(66) string.char(67) string.char(65, 66, 67)
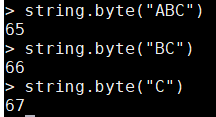
- string.byte(s, i):返回字串s中第i個字元的數值表示
string.byte("ABC", 1) string.byte("ABC", 2) string.byte("ABC", 3)
- 同理,string.byte()也支援負數索引。例如:
string.byte("ABC", -1) string.byte("ABC", -2) string.byte("ABC", -3)
- string.byte(s):如果忽略第二個參數,那麼預設返回字串s中第一個字元的數值表示
string.byte("ABC") string.byte("BC") string.byte("C")
- string.byte(s, i ,j):返回索引i到j之間(包括i和j)的所有字元的數值表示
-- 返回AB的數值表示 string.byte("ABCDEF", 1, 2) -- 返回所有字元的數值表示 string.byte("ABCDEF", 1, -1)
- string.byte(s, i ,j)的使用技巧:
- 一種常見的寫法是利用{string.byte(s , 1, -1)}建立一個由字串s中的字元組成的表
- 由於Lua語言限制了棧大小,所以也限制了一個函數的返回值的最大個數,預設最大爲一百萬個。因此,這個技巧不能用於大小超過1MB的字串
{string.byte("ABCDEF", 1, 2)}




string.format()
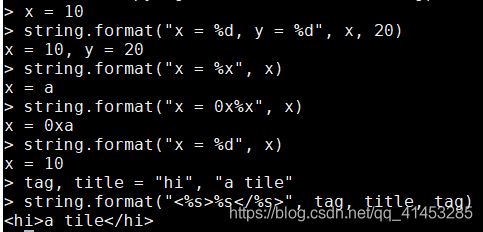
- 該函數類似於C語言的print()函數,用來進行格式化的輸出。例如:
x = 10 string.format("x = %d, y = %d", x, 20) -- 將x使用十六進制列印 string.format("x = %x", x) -- 在前面加上修飾符 string.format("x = 0x%x", x) -- 將x以浮點數的格式列印 string.format("x = %d", x) -- 列印字串 tag, title = "hi", "a tile" string.format("<%s>%s</%s>", tag, title, tag)
- 還可以控制浮點數中小數點的位數。例如:
-- 保留4位元小數點 string.format("pi = %.4f", math.pi)
- 還可以對數位進行補齊。例如:
d = 5; m =11; y = 1990 -- 每個數位必須佔用2個位置, 不足的時候用0補齊 string.format("%02d/%02d/%04d", d, m, y) -- 每個數位必須佔用2個位置, 不足的時候用空白補齊 string.format("%2d/%2d/%4d", d, m, y)
- 更多細節請參閱C語言的printf()函數,與printf()的函數是一樣的

- 字串標準庫還提供了幾個基於模式匹配的函數,例如find()和gsub()
stirng.find()
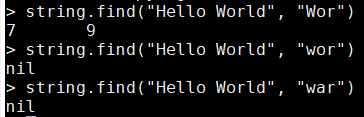
- string.find():
- 用於在指定的字串中進行模式搜尋
- 返回值:如果找到了返回模式的開始和結束位置,否則返回nil
string.find("Hello World", "Wor") string.find("Hello World", "wor") string.find("Hello World", "war")
string.gsub()
- string.gsub():
- 把所有匹配的模式用另一個字串替換
- 返回值:返回替換之後的字串,並且返回替換的字元個數
string.gsub("Hello World", "l", ".") string.gsub("Hello World", "ll", "..") string.gsub("Hello World", "a", ".")

冒號操作符的使用
- 可以使用冒號操作符像呼叫字串的一個方法那樣呼叫字串標準庫的所有函數
- 例如:
s = "HelloWorld" string.len(s) -- 使用冒號操作符呼叫 s:len() string.sub(s, 1, 2) -- 使用冒號操作符呼叫 s:sub(1,2)

- 在後面的「模式匹配」文章中還將繼續學習上面的所有函數和關於模式匹配的所有知識
九、Unicode標準庫
- 從Lua 5.3開始,Lua語言引入了一個用於操作UTF-8編碼的Unicode字串的標準庫。當然,在引入這個標準之前,Lua語言也提供了對UTF-8字串的合理支援
- UTF-8是Web環境中用於Unicode的主要編碼之一。由於與AUTF-8編碼SCII編碼部分相容,所以UTF-8對於Lua語言來說也是一種理想的編碼方式。這種相容性保證了用於ASCII字串的一些字串操作技巧也無須修改就可以用於UTF-8字串
- UTF-8使用變長的多位元組來編碼一個Unicode字元。例如,UTF-8編碼使用一個位元組的65來代表A,使用兩個位元組的215-144代表希伯來語字元Aleph(其在Unicode中的編碼是1488)。UTF-8編碼使用一個位元組表示所有ASCII範圍內的字元(小於128)。對於其他字元,則使用位元組序列表示,其中第一個位元組的範圍是[194, 244],而後續的位元組範圍是[128, 191]。更準確的說,對於兩位元組組成的序列來說,第一個位元組的範圍是[194, 223];對於三個位元組組成的序列來說,第一個位元組的範圍是[224, 239];對於四個位元組組成的序列來說,第一個位元組的範圍是[240, 244],這些範圍相互之間均不重疊。這種特點保證了任意字元對應的位元組序列不會在其他字元對應的位元組序列中出現。特別地,一個小於128的位元組永遠不會出現在多位元組序列中,它只會代表閾值對應的ASCII字元
- Lua語言中的一些機制 機製對UTF-8字串來說同樣「有效」。由於Lua使用8個位元組來編碼字元,所以可以像操作其他字串一樣讀寫和儲存UTF-8字串。字串常數也可以包含UTF-8數據(當然,讀者可能需要使用支援UTF-8編碼的編輯器來處理UTF-8編碼的原始檔)。字串連線對UTF-8字串同樣適用。對字串的比較(小於、小於等於,等等)會按照Unicode編碼中的字元程式碼順序進行(即程式碼點,下面 下麪會介紹)
- Lua語言的操作系統庫和輸入輸出庫是與對應系統之間的主要介面,所以它們是否支援UTF-8取決於對應的操作系統。例如,在Linux操作系統下檔名使用UTF-8編碼,而在Windows操作系統下檔名使用UTF-8編碼。因此,如果要在Windows操作系統中處理Unicode檔名,那麼要麼使用額外的庫,要麼就要修改Lua語言的標準庫
字串標準庫的函數處理UTF-8字串
- 上面介紹的字串標準庫中有些函數可以處理UTF-8字串,而有的不行
- 使用語法有:
- 函數string.reverse()、string.upper()、string.lower()、string.byte()、string.char()不適用於UTF-8字串,因爲它們針對的都是1位元組的字元
- 函數string.format()、string.rep()適用於UTF-8字串(格式選項'%c'除外,該格式選項針對1位元組的字元)
- 函數string.len()、string.sub()可以用於UTF-8字串,其中的索引以位元組爲單位而不是以字元爲單位
- 通常,這些函數已經夠用了
- 下面 下麪介紹新的utf8標準庫
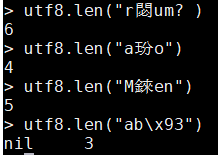
- utf8.len()函數:
- 該函數返回字串中UTF-8字元(程式碼點)的個數
- 備註:一個諸如Unicode等的超大字元集中的字元可能需要用兩個或兩個以上的位元組表示,一個完整的Unicode字元就叫做程式碼點,不能直接使用位元組位置或位元組長度來對Unicode字元進行操作
- 如果該函數發現字串中包含無效的位元組序列,則返回nil外加第一個無效位元組的位置
-- 在控制檯列印亂碼了
utf8.len("résumé")
utf8.len("ação")
utf8.len("Månen")
utf8.len("ab\x93")
- utf8.char():等價於string.char(),接收0個或多個整數作爲參數,然後將每個整數轉換爲對應的Unicode字元,最後返回這些字元連線而成的字串
-- 對應的爲résumé, 在控制檯列印亂碼了
utf8.char(114, 233, 155, 117, 109, 233)
![]()
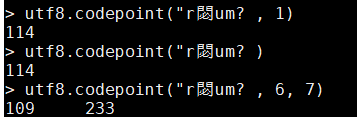
- utf8.codepoint():
- 等價於string.byte(),不過其是以位元組爲索引的
- utf8.codepoint(s, i):返回字串s中第i個字元的數值表示
- utf8.codepoint(s):如果忽略第二個參數,那麼預設返回字串s中第一個字元的數值表示
- utf8.codepoint(s, i ,j):返回索引i到j之間(包括i和j)的所有字元的數值表示(以位元組爲索引的)
-- 在控制檯列印亂碼了
utf8.codepoint("résumé", 1)
utf8.codepoint("résumé")
utf8.codepoint("résumé", 6, 7)
- utf8.offset():
- 預設情況下,utf8.xx()系列函數都是以位元組爲索引的
- 如果想要以字元位置爲索引,則可以使用該函數把字元位置轉換爲位元組位置
- utf.offset()的索引也可以是負值,表示從字串末尾開始計數
s = "Nähdän"
-- utf8.offset獲取字串中第5個字元的位元組索引, 然後作爲參數呼叫codepoint()函數
-- 列印288
utf8.codepoint(s, utf8.offset(s, 5))
-- ä
utf8.char(288)
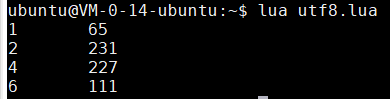
- utf8.codes():該函數用於遍歷UTF-8字串中的每一個字元
for i, c in utf8.codes("Ação") do
print(i, c)
end
- 除了上面的內容,Lua語言沒有再提供其他幾隻。Unicode具有如此多稀奇古怪的特性,以至於想從特定的語言中抽象出其中的任意一個概念基本上都是不太可能的。由於Unicode編碼的字元和字素之間沒有一對一的關係,所以甚至連字元的概念都是模糊的。例如,常見的字素é既可以使用單個程式碼點"\u{E9}"表示,也可以使用兩個程式碼點表示("e\u{301}",即e後面跟一個區分標記)。其他諸如字母之類的基本概念在不同的語系中也有差異。由於這些複雜性的存在,如果想支援完整的Unicode就需要巨大的表,而這又與Lua語言精簡的大小相矛盾。因此,對於這些特殊需求來說,最好的選擇就使用外部庫