自然語言處理——TF-IDF文字表示
引言
在文字的表示中,我們已經介紹了基於計數(Count-based Representation)的文字表示方法,爲什麼還要介紹TF-IDF文字表示法呢。
在一句話裏面有很多停止詞,通常這些停止詞出現的次數很多。
只要是個英文網站都會用到a或者是the。 在中文網站裏面其實也存在大量的停止詞。比如,我們前面這句話,「在」、「裏面」、「也」、「的」、「它」、「爲」這些詞都是停止詞。——百度百科
如果採用基於計數的文字表示方法,會給停止詞很大的頻次,從而可能會影響我們計算文字相似度的結果。tf-idf就能解決這個問題。
tf-idf
我們先來看下tf-idf(Term Frequency-Inverse Document Frequency, 詞頻-逆文件頻率)的公式。
tf-idf是由兩部分組成的:
tf-idf(w) = tf(d,w) * idf(w)
tf是文件d中w的詞頻,也就是單詞出現的次數,但是文件有長短之分,爲了比較不同的文件,需要做"詞頻"標準化,即 (w在文件d中出現的次數 / 文件d的總單詞數)。
idf是逆文件頻次,說的是如果包含單詞w的文件越少,則idf越大,說明單詞w具有很好的類別區分能力,越重要。
- 其中是語料庫中的文件總數
- 是包含單詞的文件數
之前的停用詞,很多出現在大多數的文件(句子)中,因此很大,也就是分母很大,idf就較小。加了是防止idf過大。
下面 下麪我們通過一個例子來計算一下td-idf。
首先定義我們的詞典:
word_dic = ['今天','上','NLP','的','課程','有','意思','數據','也']
假設我們有這樣三個分好詞的句子:
:「今天/上/NLP/課程」
:「今天/的/課程/有/意思」
:「數據/課程/也/有/意思」
那麼如何計算句子的tf呢?
先看中第一個單詞「今天」,也是詞典中的第一個單詞:
的單詞數爲,「今天」出現的次數爲,tf爲;
文件總數爲,包含「今天」的文件數爲,idf爲。
然後再看詞典中的第二個單詞「上」:
「上」出現的次數爲,tf爲;
包含「上」的文件數爲,idf爲。
接着看詞典中的第三個單詞「NLP」:
「NLP」出現的次數爲,tf爲;
包含「NLP」的文件數爲,idf爲。
再看詞典中的第四個單詞「的」:
「的」沒有在中出現,因此tf-idf爲0。
再看詞典中的第五個單詞「課程」:
「課程」出現的次數爲,tf爲;
包含「課程」的文件數爲,idf爲。
接下來詞典中的其他單詞沒有在中出現,因此tf-idf都爲0。
這樣我們得到了第一個句子的tf-idf表示:
tf-idf向量的維度也是和詞典大小一致的。
下面 下麪直接給出句子的tf-idf向量:
出句子的tf-idf向量:
這樣我們就得到這三個句子的tf-idf向量。
下面 下麪通過程式碼實現一下。
TF-IDF程式碼實現
word_dic = ['今天','上','NLP','的','課程','有','意思','數據','也']
s1 = '今天上NLP課程'
s2 = '今天的課程有意思'
s3 = '數據課程也有意思'
首先是我們的詞典和三個句子。
def cut_words(segment,word_dic,max_len=3):
seg_list = []
i = len(s1)
while i > 0:
for pos in reversed(range(max_len)):
if i >= pos + 1:
if segment[i-pos-1:i] in word_dic:
seg_list.append(segment[i-pos-1:i])
i = i - pos
break
i = i -1
return list(reversed(seg_list))
然後基於這個詞典實現一個分詞演算法。
# 先進行分詞
s1_words = cut_words(s1,word_dic)
s2_words = cut_words(s2,word_dic)
s3_words = cut_words(s3,word_dic)
print("/".join(s1_words))
print("/".join(s2_words))
print("/".join(s3_words))
# 構建數據集
data_set = [s1_words,s2_words,s3_words]
data_set
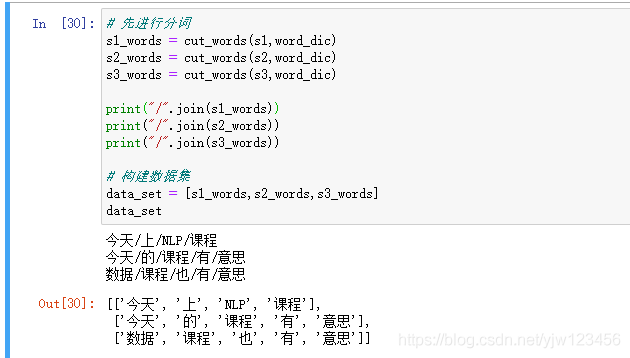
用我們實現的分詞演算法來進行分詞,剛好可以得到上一節例子中的結果。
接下裡就開始實現TF-IDF演算法了。
from collections import defaultdict
from collections import Counter
from math import log
def compute_tfidf(data_set,word_dic):
'''根據傳入的data_set和word_dic,計算data_set中每個句子的tfidf向量'''
N = len(data_set) #文件的總數
N_w = defaultdict(int) #包含單詞w的文件數,通過字典來快取計算結果
for w in word_dic:
for segment in data_set:
if w in segment:
N_w[w] += 1
tfidfs = []#返回的結果
for segment in data_set:
# 每個句子
c = Counter(segment)
N_S = len(segment) #文件的單詞總數
result = []
for w in word_dic:
if w not in c:
result.append(0)
print('0 ',end='')
else:
tf = c[w] / N_S
idf = log(N / N_w[w])
result.append(tf * idf)
print('%i/%i*log(%i/%i) ' %(c[w],N_S,N,N_w[w]),end ='')
print()
tfidfs.append(result)
return tfidfs
這裏是針對上節介紹的原理一個簡單實現,沒有考慮N_w爲零的情況,效率也有一定的問題,不過作爲理解原理足夠了。

在計算的過程中增加了一個偵錯資訊,可以看到和上節我們手寫的結果是一樣的。
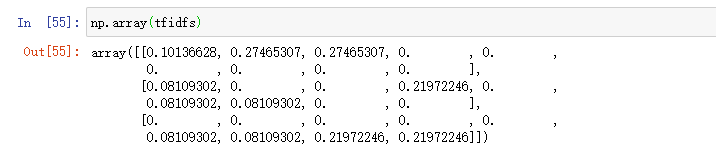
計算的結果如上所示。
然後我們實現一下歐幾裡得距離和餘弦相似度計算公式。
import numpy as np
def euclid_dis(v1,v2):
v1 = np.array(v1)
v2 = np.array(v2)
return np.sqrt(np.sum( (v1 - v2)**2))
def cosine_similarity(v1,v2):
v1 = np.array(v1)
v2 = np.array(v2)
return (v1.dot(v2)) / (np.linalg.norm(v1) * np.linalg.norm(v2))
基於numpy是很簡單的。
print('s1 and s2 euclid_dis:%.2f , cosine_similarity:%.2f' % (euclid_dis(tfidfs[0],tfidfs[1]),cosine_similarity(tfidfs[0],tfidfs[1])))
print('s1 and s3 euclid_dis:%.2f , cosine_similarity:%.2f' % (euclid_dis(tfidfs[0],tfidfs[2]),cosine_similarity(tfidfs[0],tfidfs[2])))
print('s2 and s3 euclid_dis:%.2f , cosine_similarity:%.2f' % (euclid_dis(tfidfs[1],tfidfs[2]),cosine_similarity(tfidfs[1],tfidfs[2])))

最後從列印結果可知,句子「今天的課程有意思」和「數據課程也有意思」是最相似的,這也符合我們的直覺。
參考
- 貪心學院課程