ETL處理過程
ETL代表提取,轉換和載入。ETL是一個用於提取資料,轉換資料和將資料載入到最終源的過程。ETL遵循將資料從源系統載入到資料倉庫的過程。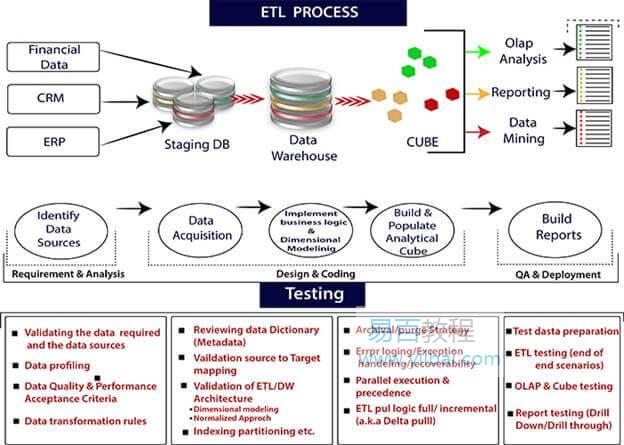
執行ETL過程的步驟如下:
提取
提取是第一個過程,其中收集來自不同來源的資料,如文字檔案,XML檔案,Excel檔案或各種其他來源。
轉換
轉換是ETL過程的第二步,其中所有收集的資料都已轉換為相同的格式。根據要求,格式可以是任何格式。在該步驟中,將一組函式規則應用於提取的資料以將其轉換為單個標準格式。它可能涉及以下任務:
- 過濾:僅將特定屬性載入到資料倉庫中。
- 清除:使用特定的預設值填充空值。
- 加入:將多個屬性加入到一個屬性中。
- 拆分:將單個屬性拆分為多個屬性。
- 排序:根據屬性對元組進行排序。
載入
載入是ETL過程的最後一步。從各種來源收集大量資料,轉換它們,最後載入到資料倉庫。
ETL是從不同源系統提取資料,轉換資料並將資料載入到資料倉庫的過程。ETL流程需要各種利益相關方的積極參與,包括開發人員,分析師,測試人員,高階管理人員。
ETL(提取,轉換和載入)是一種自動化過程,用於從原始資料中提取分析所需的資訊,並將其轉換為可滿足業務需求並將其載入到資料倉庫中的格式。ETL通常匯總資料以減小其大小並提高特定型別分析的效能。
ETL過程使用流水線概念。在這個概念中,一旦提取資料,就可以對其進行變換,並且在變換期間,可以獲得新資料。當將修改後的資料載入到資料倉庫中時,可以轉換已提取的資料。

當構建ETL基礎架構時,必須整合資料源,仔細計劃和測試,以確保正確地轉換源資料。
在這裡,我們將解釋構建ETL基礎結構的三種方法,以及在不使用ETL的情況下構建資料管道的另一種方法。
方法1:使用批次處理構建ETL管道
這裡是構建傳統ETL過程的過程,其中我們將資料從源資料庫批次傳輸和處理到資料倉庫。開發企業ETL管道具有挑戰性; 通常會依賴諸如Stitch和Blendo之類的ETL工具來簡化和自動化流程。
使用批次處理構建ETL,這是ETL的最佳實踐。
1)參考資料:在這裡,我們將建立一組資料來定義允許值的集合,並且可以包含資料。
範例:在國家/地區資料欄位中,我們可以定義允許的國家/地區程式碼。
2)從資料參照中提取:ETL步驟的成功是正確提取資料。大多數ETL系統組合來自多個源系統的資料,每個系統都有其資料組織和格式,包括關聯式資料庫,非關聯式資料庫,XML,JSON,CSV檔案,成功提取後,資料被轉換為單一格式,用於標準化格式。
3)資料驗證:自動化流程確認從源中提取的資料是否具有預期值。例如,A資料欄位應包含過去12年內過去12年的金融交易資料庫中的有效日期。如果驗證規則未通過,驗證引擎將拒絕該資料。我們定期分析被拒絕的記錄,以確定出現了什麼問題。在這裡,我們更正源資料或修改提取的資料以解決下一批中的問題。
4)轉換資料:刪除無關或錯誤的資料,應用業務規則,檢查資料完整性(確保資料未在源中被破壞或被ETL破壞,並且在前幾個階段沒有丟棄資料),並根據需要建立聚合。如果我們分析收入,我們可以將發票的美元金額彙總為每日或每月總計。我們需要編寫和測試一系列規則或函式,這些規則或函式可以實現所需的轉換並在提取的資料上執行它們。
5)階段:我們通常不會將轉換後的資料直接載入到目標資料倉庫中。應首先將資料輸入到臨時資料庫中,以便在出現問題時更容易回滾。此時,我們還可以生成審計報告,以符合法規要求或診斷和修復資料問題。
6)發布到資料倉庫:將資料載入到目標表。有些資料倉庫每次都會覆蓋現有資訊,ETL管道每天,每月或每週載入一個新批次。換句話說,ETL可以新增新資料而不會覆蓋,時間戳表明它是唯一的。我們必須小心謹慎,以防止資料倉庫由於磁碟空間和效能限制而「爆裂」。
方法2:使用流處理構建ETL管道
現代資料流程通常包括實時資料。例如,來自大型電子商務網站的網站分析資料。在這些用例中,我們無法大批次提取和轉換資料,並且需要對資料流執行ETL,這意味著當用戶端應用程式將資料寫入資料源時,應該將資料處理,轉換並立即儲存到目標 資料儲存。目前有許多流處理工具可用,包括apache Samza,Apache商店和Apache Kafka。

基於Kafka構建流式ETL涉及以下幾點:
1)將資料提取到Kafka:JDBC連線器拉取源表的每一行。當用戶端應用程式向表中新增行時,Kafka會自動將它們作為新訊息寫入Kafka主題,從而啟用實時資料流。
2)從Kafka中提取資料:ETL應用程式從Kafka主題中提取訊息,如Avro Records,它建立Avro模式檔案並對其進行反序列化,並從訊息中建立KStream物件。
3)在KStream物件中轉換資料:使用Kafka Streams API,流處理器一次接收一條記錄,對其進行處理,並可以從下游處理器生成一條或多條輸出記錄。這些可以一次轉換一條訊息,根據條件過濾它們,或者對多條訊息執行資料操作。
4)將資料載入到其他系統:ETL應用程式仍然儲存資料,現在需要將其流式傳輸到目標系統,例如資料倉庫或資料湖。它們的目的是使用S3接收器連線器將資料流式傳輸到Amazon S3。我們可以實現與其他系統的整合。例如:使用Amazon Kinesis將資料流式傳輸到Redshift資料倉庫。