Python----數據分析-使用scikit-learn構建模型實訓(wine數據集、wine_quality數據)
Python----數據分析-使用scikit-learn構建模型實訓(wine數據集、wine_quality數據)
目錄:
實訓1 使用 sklearn處理wine和wine_quality數據集
實訓2 構建基於wine數據集的k- Means聚類模型
實訓3 構建基於wine數據集的SVM分類模型
實訓4 構建基於wine_quality數據集的迴歸模型
wine數據集包含來自3種不同起源的葡萄酒的共178條記錄。13個屬性是葡萄酒的13種化學成分。通過化學分析可以來推斷葡萄酒的起源。值得一提的是所有屬性變數都是連續變數。
實訓1 使用 sklearn處理wine和wine_quality數據集
1.訓練要點
- 掌握 sklearn轉換器的用法。
- 掌握訓練集、測試集劃分的方法。
- 掌握使用sklearn進行PCA降維的方法。
2.需求說明
- wine數據集和 winequality數據集是兩份和酒有關的數據集。wine數據集包含3種 同起源的葡萄酒的記錄,共178條。其中,每個特徵對應葡萄酒的每種化學成分,並且都 屬於連續型數據。通過化學分析可以推斷葡萄酒的起源。
- winequality數據集共有4898個觀察值,11個輸入特徵和一個標籤。其中,不同類的
觀察值數量不等,所有特徵爲連續型數據。通過酒的各類化學成分,預測該葡萄酒的評分3.實現思路及步驟
- 使用pandas庫分別讀取wine數據集和 winquality數據集
- 將wine數據集和winequality數據集的數據和標籤拆分開(提取)。
- 將winequality數據集劃分爲訓練集和測試集。
- 標準化wine數據集和 wine quality數據集
- 對wine數據集和 winequality數據集進行PCA降維。
import pandas as pd
// 讀取數據
wine_quality = pd.read_csv('data/winequality.csv',sep=';')
wine = pd.read_csv('data/wine.csv')
print(type(wine),type(wine_quality))
//<class 'pandas.core.frame.DataFrame'> <class 'pandas.core.frame.DataFrame'>
// 提取 wine_quality 數據
wine_quality_data = wine_quality.iloc[:,:-1]
wine_quality_target = wine_quality['quality']
// 提取 wine 數據
wine_data = wine.iloc[:,:-1]
wine_target = wine['Class']
wine數據集和winequality數據集的表現形式不一樣,這裏的wine數據集可以直接讀入,而winequality數據集在檔案中是以」;」爲間隔的,所以要採用間隔讀入的方式獲取其數據。讀取後數據都以DataFrame的型別保留,使用iloc等切片操作提取所需數據。
// 將 wine_quality 數據劃分爲訓練集和測試集
from sklearn.model_selection import train_test_split
wine_quality_data_train,wine_quality_data_test,\
wine_quality_target_train,wine_quality_target_test=\
train_test_split(wine_quality_data,wine_quality_target,test_size=0.2,random_state=321)
wine_data_train,wine_data_test,\
wine_target_train,wine_target_test=\
train_test_split(wine_data,wine_target,test_size=0.2,random_state=321)
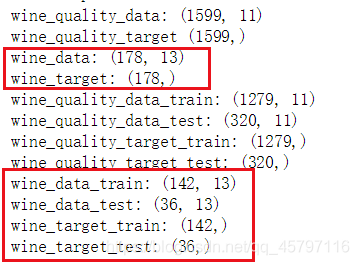
train_test_split()函數將數據集劃分爲訓練集和測試集兩部分,參數test_size=0.2代表着測試集在總數中的佔比,通過計算wine_data總共178條記錄,wine_data_test有36條,佔0.20224171(20%),參數random_state=321,表示隨機種子編號,方便測試時得到相同隨機結果。
// 標準化數據集
from sklearn.preprocessing import StandardScaler
stdScaler = StandardScaler().fit(wine_data_train) // 生成標準化規則
wine_trainScaler = stdScaler.transform(wine_data_train) // 對訓練集標準化
wine_testScaler = stdScaler.transform(wine_data_test) // 用訓練集建立的模型對測試集標準化
Scaler = StandardScaler().fit(wine_quality_data_train) // 生成標準化規則
winequality_trainScaler = Scaler.transform(wine_quality_data_train) // 對訓練集標準化
winequality_testScaler = Scaler.transform(wine_quality_data_test) // 用訓練集建立的模型對測試集標準化
這裏有個順序:生成標準化規則;對訓練集標準化;用訓練集建立的模型對測試集標準化
主要是因爲在數據分析的時候,各類特徵處理相關的操作都需要對訓練集和測試集分開進行,同時需要將訓練集的操作規則、權重係數等應用到測試集中。這也就是爲什麼生成規則時fit傳入訓練集。transform函數緊接着將定義好的規則應用對傳入的特徵進行對應轉換。
// PCA降維
from sklearn.decomposition import PCA
pca_model = PCA(n_components=5).fit(wine_trainScaler) // 生成PCA規則
wine_trainpca = pca_model.transform(wine_trainScaler) // 將規則應用到訓練集
wine_testpca = pca_model.transform(wine_testScaler) // 將規則應用到測試集
pca_model = PCA(n_components=5).fit(winequality_trainScaler) // 生成PCA規則
winequality_trainpca = pca_model.transform(winequality_trainScaler) // 將規則應用到訓練集
winequality_testpca = pca_model.transform(winequality_testScaler) #// 將規則應用到測試集
PCA(n_components=5)的參數n_components表示將原始數據降低到n個維度。
實訓2 構建基於wine數據集的k- Means聚類模型
1.訓練要點
- 瞭解sklearn估計器的用法。
- 掌握聚類模型的構建方法。
- 掌握聚類模型的評價方法。
2.需求說明
- wine數據集的葡萄酒總共分爲3種,通過將wine數據集的數據進行聚類,聚集爲3 個簇,能夠實現葡萄酒的類別劃分。
3.實現思路及步驟
- 根據實訓1的wine數據集處理的結果,構建聚類數目爲3的- -Means模型。
- 對比真實標籤和聚類標籤求取FMI。
- 在聚類數目爲2~10類時,確定最優聚類數目。
- 求取模型的輪廓係數,繪製輪廓係數折線圖,確定最優聚類數目。
- 求取 Calinski-Harabasz-指數,確定最優聚類數目。
// 構建 K-Means 模型
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3,random_state=32).fit(wine_trainScaler) //構建訓練模型
print('wine_trainScaler構建的模型爲:\n',kmeans)
//wine_trainScaler構建的模型爲:
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=3, n_init=10, n_jobs=None, precompute_distances='auto',
random_state=32, tol=0.0001, verbose=0)
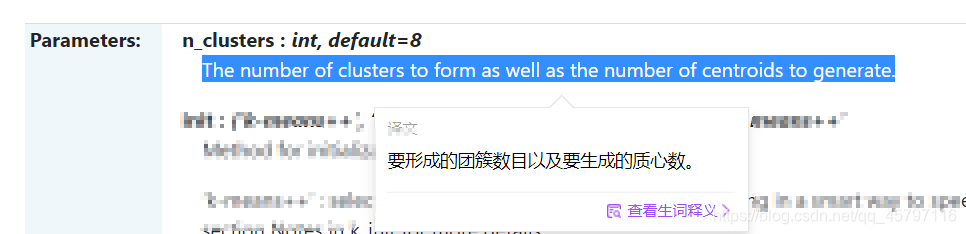
構建K-Means聚類模型,參數n_clusters=3表示要形成的團簇數目,也就是分爲幾類,這裏是分爲3類。
// 對比真實標籤和聚類標籤求取FMI
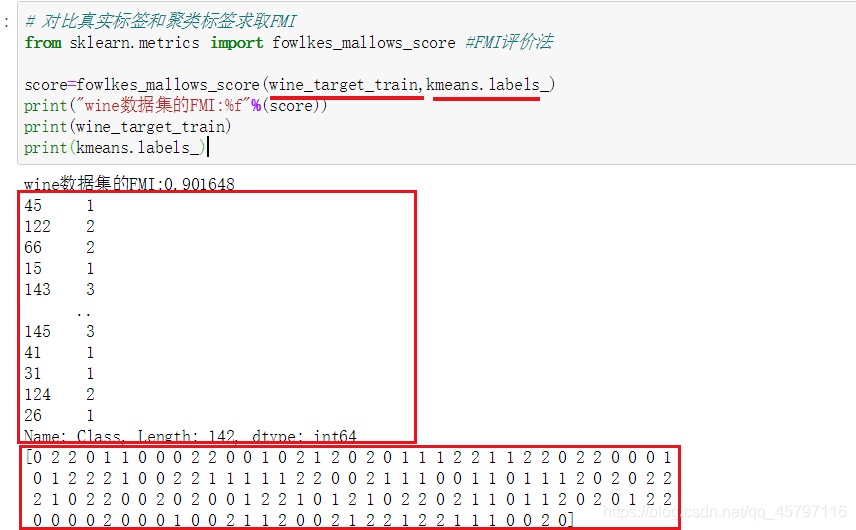
from sklearn.metrics import fowlkes_mallows_score //FMI評價法
score=fowlkes_mallows_score(wine_target_train,kmeans.labels_)
print("wine數據集的FMI:%f"%(score))
//wine數據集的FMI:0.901648
//在聚類數目爲2~10類時,確定最優聚類數目
from sklearn.metrics import fowlkes_mallows_score
from sklearn.cluster import KMeans
for i in range(2,11):
kmeans = KMeans(n_clusters=i,random_state=32).fit(wine_trainScaler)
score = fowlkes_mallows_score(wine_target_train,kmeans.labels_)
print('wine聚%d類FMI評價分爲:%f'%(i,score))
wine聚2類FMI評價分爲:0.693972
wine聚3類FMI評價分爲:0.901648
wine聚4類FMI評價分爲:0.801280
wine聚5類FMI評價分爲:0.775956
wine聚6類FMI評價分爲:0.782225
wine聚7類FMI評價分爲:0.607152
wine聚8類FMI評價分爲:0.570184
wine聚9類FMI評價分爲:0.567783
wine聚10類FMI評價分爲:0.559720
// 求取模型的輪廓係數,繪製輪廓係數折線圖,確定最優聚類數目
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
silhouettteScore = []
for i in range(2,11):
// 構建並訓練模型
kmeans = KMeans(n_clusters = i,random_state=1).fit(wine)
score = silhouette_score(wine,kmeans.labels_)
silhouettteScore.append(score)
plt.figure(figsize=(10,6))
plt.plot(range(2,11),silhouettteScore,linewidth=1.5, linestyle="-")
plt.show()
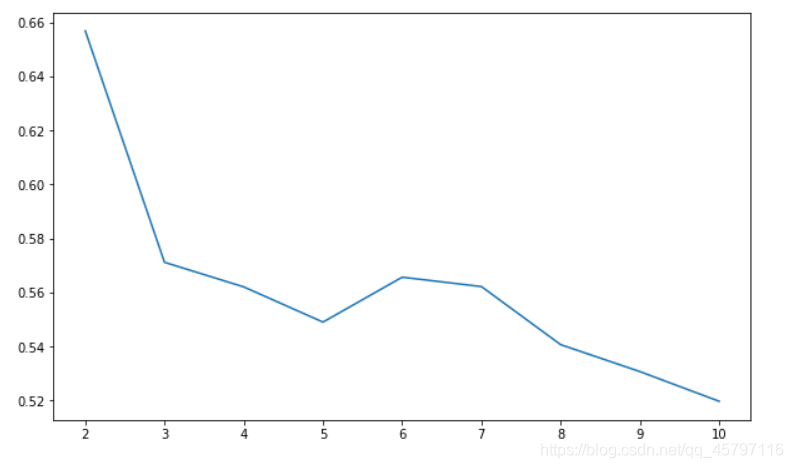
求取模型的輪廓係數:

//求取 Calinski-Harabasz指數,確定最優聚類數
from sklearn.metrics import calinski_harabasz_score
for i in range(2,11):
// 構建並訓練模型
kmeans = KMeans(n_clusters = i,random_state=1).fit(wine_trainScaler)
score = calinski_harabaz_score(wine_trainScaler,kmeans.labels_)
print('seeds數據聚%d類calinski_harabaz指數爲:%f'%(i,score))
seeds數據聚2類calinski_harabaz指數爲:67.189882
seeds數據聚3類calinski_harabaz指數爲:62.785275
seeds數據聚4類calinski_harabaz指數爲:49.058796
seeds數據聚5類calinski_harabaz指數爲:41.101132
seeds數據聚6類calinski_harabaz指數爲:36.321948
seeds數據聚7類calinski_harabaz指數爲:34.295581
seeds數據聚8類calinski_harabaz指數爲:31.101151
seeds數據聚9類calinski_harabaz指數爲:28.693663
seeds數據聚10類calinski_harabaz指數爲:28.563627
分析FMI評價分值,可以看出wine數據分3類的時候其FMI值最高,故聚類爲3類的時候wine數據集K-means聚類效果最好
分析輪廓係數折線圖,可以看出在wine數據集爲3的時候,其平均畸變程度最大,故亦可知聚類爲3類的時候效果最佳
實訓3 構建基於wine數據集的SVM分類模型
1.訓練要點
- 掌握sklearn估計器的用法。
- 掌握分類模型的構建方法。
- 掌握分類模型的評價方法。
2.需求說明
- wine數據集中的葡萄酒類別爲3種,將wie數據集劃分爲訓練集和測試集,使用訓練 集訓練SVM分類模型,並使用訓練完成的模型預測測試集的葡萄酒類別歸屬。
3.實現思路及步驟
- 讀取wine數據集,區分標籤和數據。
- 將wine數據集劃分爲訓練集和測試集
- 使用離差標準化方法標準化wine數據集。
- 構建SVM模型,並預測測試集結果。
- 列印出分類報告,評價分類模型效能。
import pandas as pd
// 讀取數據
wine_quality = pd.read_csv('data/winequality.csv',sep=';')
wine = pd.read_csv('data/wine.csv')
// 提取 wine_quality 數據
wine_quality_data = wine_quality.iloc[:,:-1]
wine_quality_target = wine_quality['quality']
// 提取 wine 數據
wine_data = wine.iloc[:,:-1]
wine_target = wine['Class']
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.preprocessing import MinMaxScaler
// 劃分訓練集、測試集
wine_data_train,wine_data_test,wine_target_train,wine_target_test=\
train_test_split(wine_data,wine_target,test_size=0.2,random_state=123)
// 數據標準化規則
Scaler = MinMaxScaler().fit(wine_data_train)
// 應用規則
wine_trainScaler = Scaler.transform(wine_data_train) // 對訓練集進行標準化
wine_testScaler = Scaler.transform(wine_data_test) // 用訓練集訓練的模型對測試集標準化
// 構建SVM分類模型
svm = SVC().fit(wine_trainScaler,wine_target_train)
print("建立的SVM模型爲:\n",svm)
//建立的SVM模型爲:
SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
// 預測訓練結果
wine_target_pred = svm.predict(wine_testScaler)
print('預測前20個結果爲:',wine_target_pred[:20])
//預測前20個結果爲: [3 2 3 2 2 3 1 3 3 2 3 3 3 1 1 3 2 2 1 2]
// 列印模型評價報告
from sklearn.metrics import classification_report
print('使用SVM預測數據的分析報告爲:\n',classification_report(wine_target_test,wine_target_pred))
//使用SVM預測數據的分析報告爲:
precision recall f1-score support
1 1.00 1.00 1.00 8
2 1.00 1.00 1.00 11
3 1.00 1.00 1.00 17
accuracy 1.00 36
macro avg 1.00 1.00 1.00 36
weighted avg 1.00 1.00 1.00 36
實訓4 構建基於wine_quality數據集的迴歸模型
1.訓練要點
(1)熟練sklearn估計器的用法。
(2)掌握迴歸模型的構建方法。
(3)掌握迴歸模型的評價方法。2.需求說明
- winequality數據集的葡萄酒評分在1~10之間,建線性迴歸模型與梯度提升迴歸模 型,訓練 winequality數據集的訓練集數據,訓練完成後預測測試集的葡萄酒評分。結合 真實評分,評價構建的兩個迴歸模型的好壞。
3.實現思路及步驟
- 根據winequality數據集處理的結果,構建線性迴歸模型。
- 根據wine quality數據集處理的結果,構建梯度提升迴歸模型。
- 結合真實評分和預測評分,計算均方誤差中值絕對誤差、可解釋方差值。
- 根據得分,判定模型的效能優劣。
// 構建線性迴歸模型
from sklearn.linear_model import LinearRegression
clf = LinearRegression().fit(winequality_trainpca,wine_quality_target_train)
y_pred = clf.predict(winequality_testpca)
print('線性迴歸模型預測前10個結果爲:','\n',y_pred[:10])
線性迴歸模型預測前10個結果爲:
[5.27204611 5.16410891 6.93394979 6.52520955 5.56143289 5.02815869
5.17867439 5.95768188 5.68991275 5.33085457]
// 根據wine_quality數據集處理的結果,構建梯度提升迴歸模型。
from sklearn.ensemble import GradientBoostingRegressor
gbr_wine = GradientBoostingRegressor().fit(winequality_trainpca,wine_quality_target_train)
wine_target_pred = gbr_wine.predict(winequality_testpca)
print('梯度提升迴歸模型預測前10個結果爲:','\n',wine_target_pred[:10])
print('真實標籤前10個預測結果爲:','\n',list(wine_quality_target_test[:10]))
梯度提升迴歸模型預測前10個結果爲:
[5.4569842 5.1020336 6.39325331 6.55163291 5.62504565 5.16770619
5.22503393 5.6942301 5.43575267 5.22052962]
真實標籤前10個預測結果爲:
[6, 5, 6, 7, 6, 6, 5, 6, 6, 5]
from sklearn.metrics import mean_absolute_error,mean_squared_error,median_absolute_error,explained_variance_score,r2_score
print('線性迴歸模型評價結果:')
print('winequality數據線性迴歸模型的平均絕對誤差爲:',
mean_absolute_error(wine_quality_target_test,y_pred))
print('winequality數據線性迴歸模型的均方誤差爲:',
mean_squared_error(wine_quality_target_test,y_pred))
print('winequality數據線性迴歸模型的中值絕對誤差爲:',
median_absolute_error(wine_quality_target_test,y_pred))
print('winequality數據線性迴歸模型的可解釋方差值爲:',
explained_variance_score(wine_quality_target_test,y_pred))
print('winequality數據線性迴歸模型的R方值爲:',
r2_score(wine_quality_target_test,y_pred))
線性迴歸模型評價結果:
winequality數據線性迴歸模型的平均絕對誤差爲: 0.500442590483755
winequality數據線性迴歸模型的均方誤差爲: 0.4116335179704622
winequality數據線性迴歸模型的中值絕對誤差爲: 0.42681355355182804
winequality數據線性迴歸模型的可解釋方差值爲: 0.3304259967770349
winequality數據線性迴歸模型的R方值爲: 0.32853409414296564
print('梯度提升迴歸模型評價結果:')
print('winequality數據梯度提升迴歸樹模型的平均絕對誤差爲:',
mean_absolute_error(wine_quality_target_test,wine_target_pred))
print('winequality數據梯度提升迴歸樹模型的均方誤差爲:',
mean_squared_error(wine_quality_target_test,wine_target_pred))
print('winequality數據梯度提升迴歸樹模型的中值絕對誤差爲:',
median_absolute_error(wine_quality_target_test,wine_target_pred))
print('winequality數據梯度提升迴歸樹模型的可解釋方差值爲:',
explained_variance_score(wine_quality_target_test,wine_target_pred))
print('winequality數據梯度提升迴歸樹模型的R方值爲:',
r2_score(wine_quality_target_test,wine_target_pred))
梯度提升迴歸模型評價結果:
winequality數據梯度提升迴歸樹模型的平均絕對誤差爲: 0.49135412186249
winequality數據梯度提升迴歸樹模型的均方誤差爲: 0.3929327053069297
winequality數據梯度提升迴歸樹模型的中值絕對誤差爲: 0.4130905910176561
winequality數據梯度提升迴歸樹模型的可解釋方差值爲: 0.3620462459660544
winequality數據梯度提升迴歸樹模型的R方值爲: 0.3590392827808905
對於一個迴歸模型來說,平均絕對誤差、均方誤差、中值絕對誤差越接近0越好,可解釋方差和R2值越接近1越好。通過對比兩者的迴歸評價指標不難發現,線性迴歸模型的平均絕對誤差、均方誤差、中值絕對誤差都要大於梯度迴歸模型,但是可解釋方差和R2值都要小於梯度迴歸模型。因此,梯度迴歸模型在五個指標上都要優於線性迴歸模型,故在本實訓中,梯度迴歸模型效能更優!