走進 C/C++後臺開發的第二步:Linux系統程式設計
Linux系統程式設計
一. 檔案操作程式設計
Linux 檔案操作程式設計是使用 UNIX/LINUX 提供的ANSI標準函數介面爲基準對檔案進行操作。
1.1 基於檔案指針的檔案操作
1.1.1 Linux的檔案
檔案型別:

基於檔案指針的檔案操作函數是ANSI標準函數庫的一部分。
1.1.2 檔案的建立,開啓與關閉
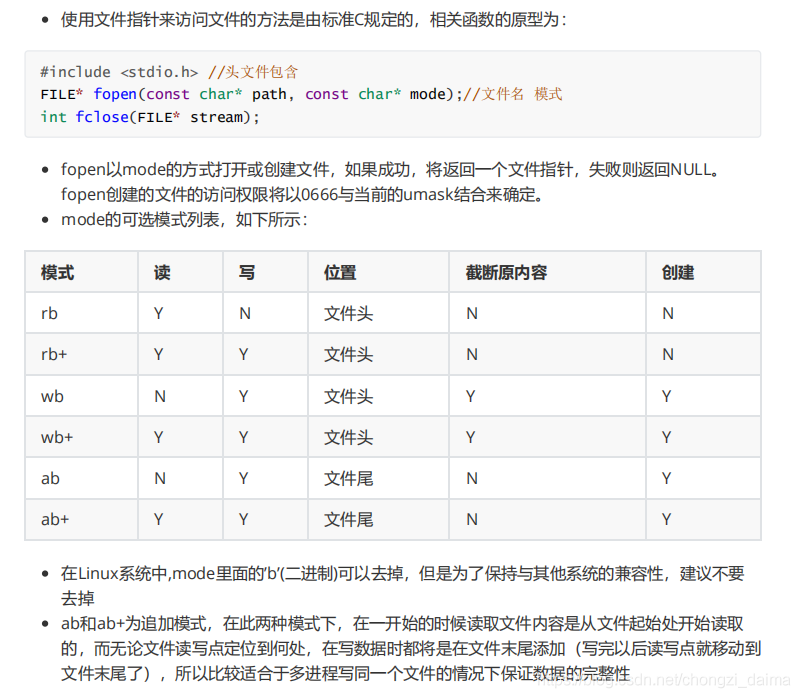
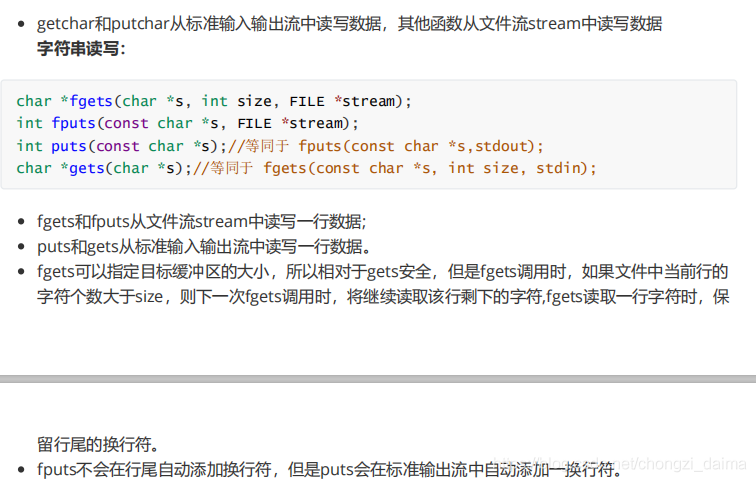
1.1.3 讀寫檔案
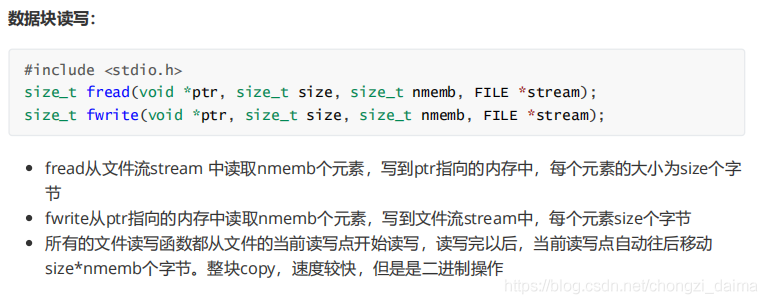
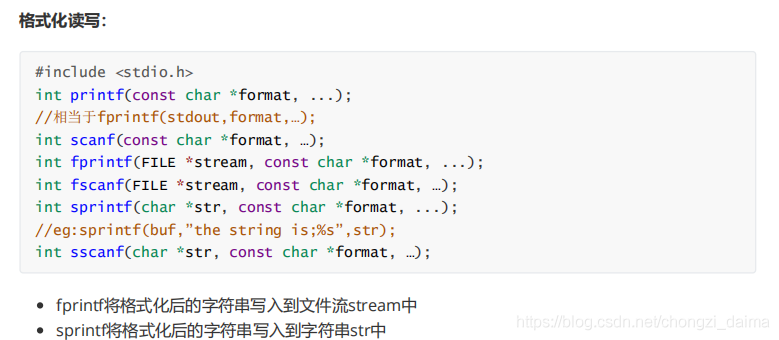
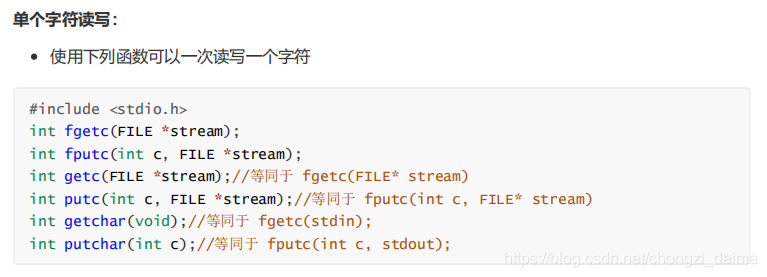
基於檔案指針的數據讀寫函數較多,可分爲如下幾組:
1.1.4 修改檔案的許可權

1.2 目錄操作
1.2.1:獲取改變當前工作目錄



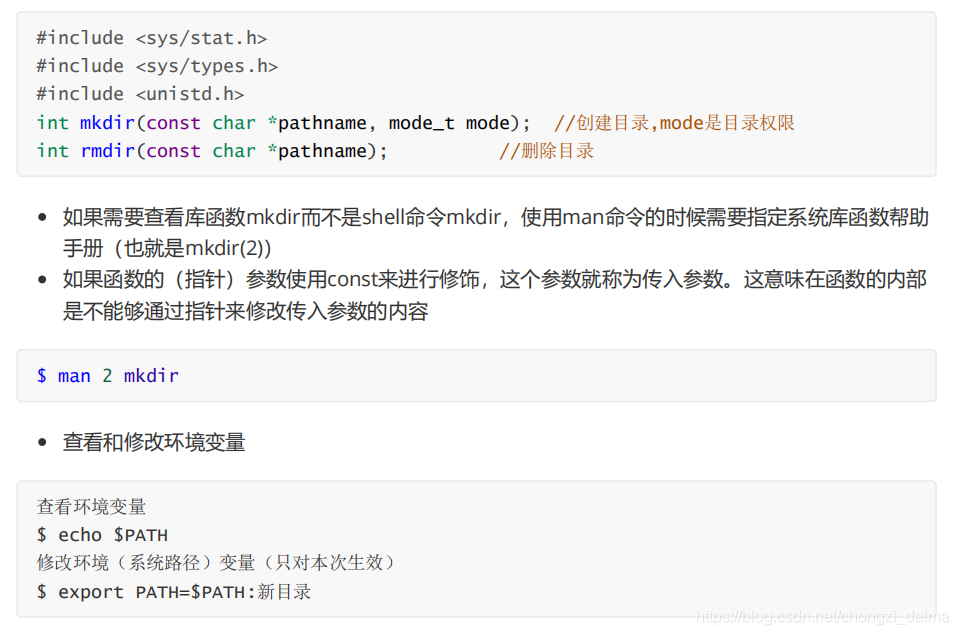
1.2.2 建立刪除目錄
1.2.3 目錄的儲存原理

1.2.4 目錄相關操作


1.3 基於檔案描述符的檔案操作 (重點)
1.3.1 檔案描述符簡介

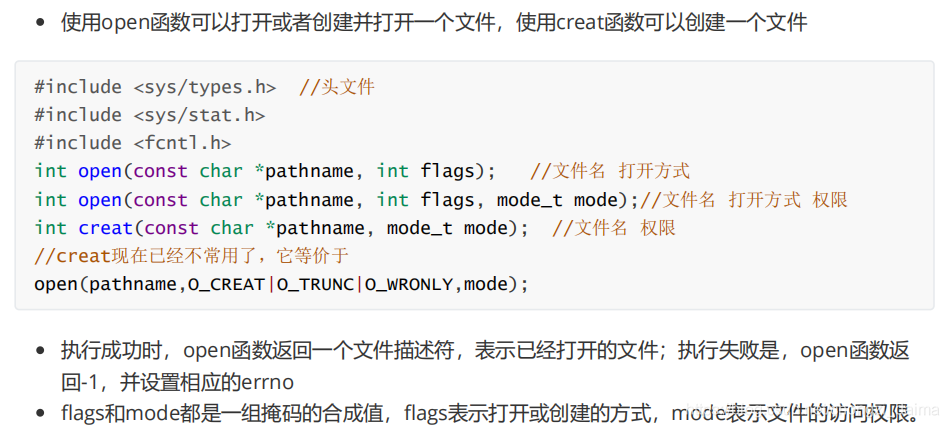
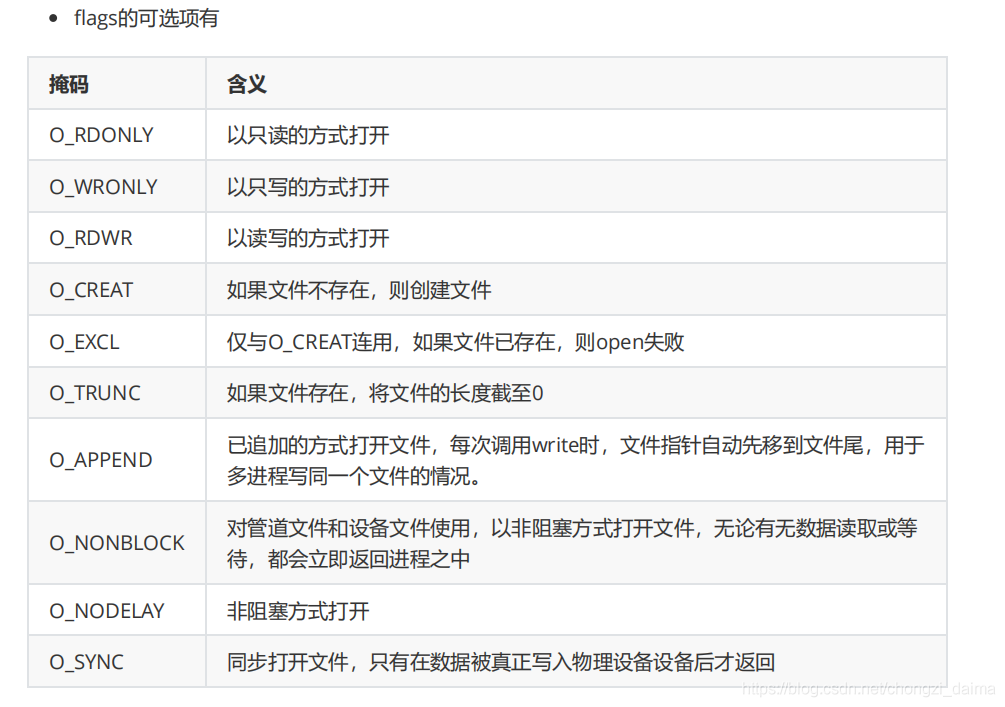
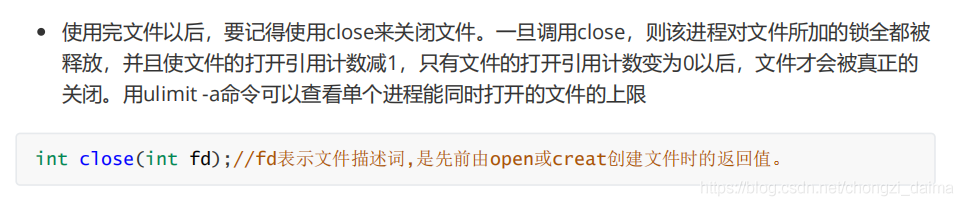
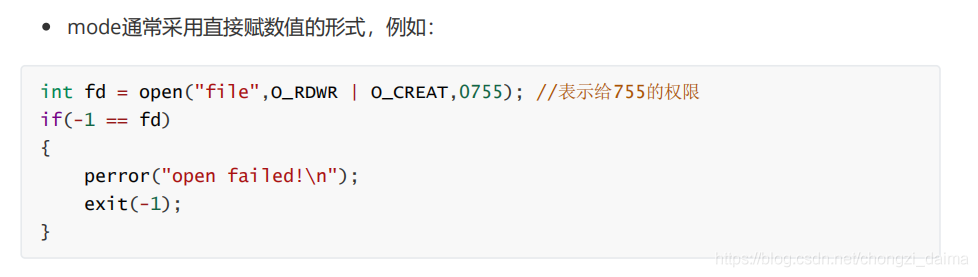
1.3.2 開啓、建立和關閉檔案
1.3.3 讀寫檔案
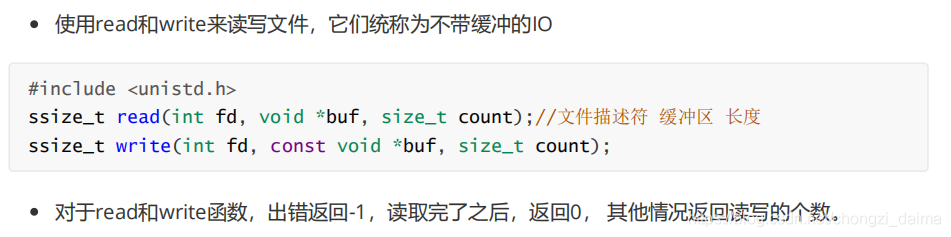

1.3.4 改變檔案大小
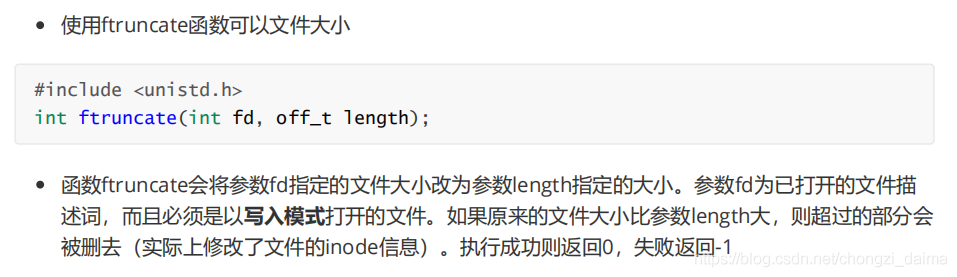
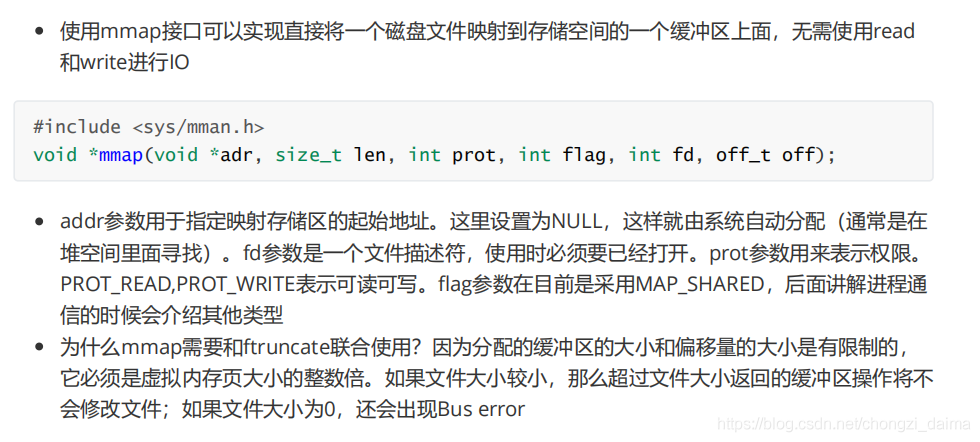
1.3.5 檔案對映
DMA裝置:
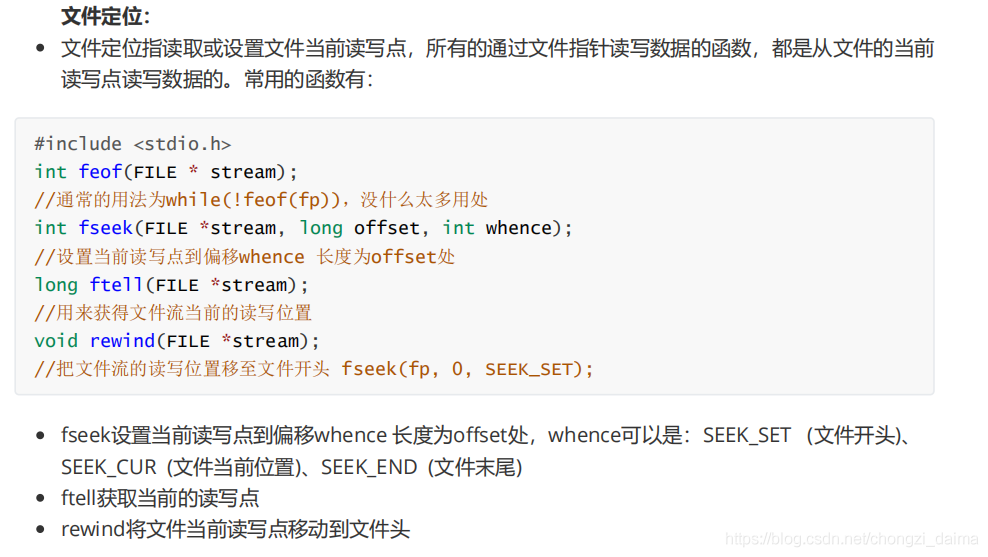
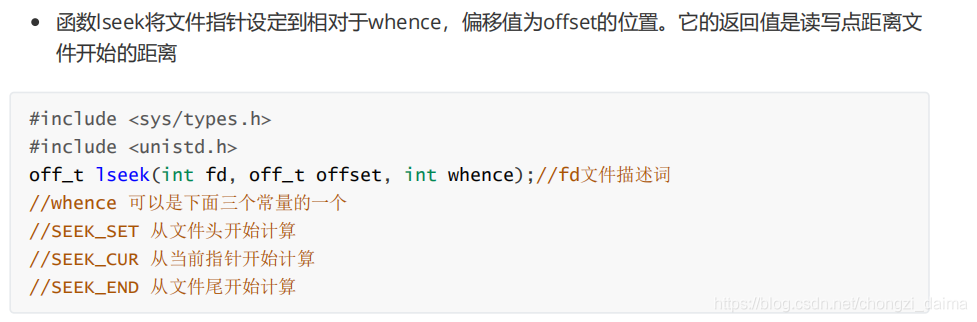
1.3.6 檔案定位
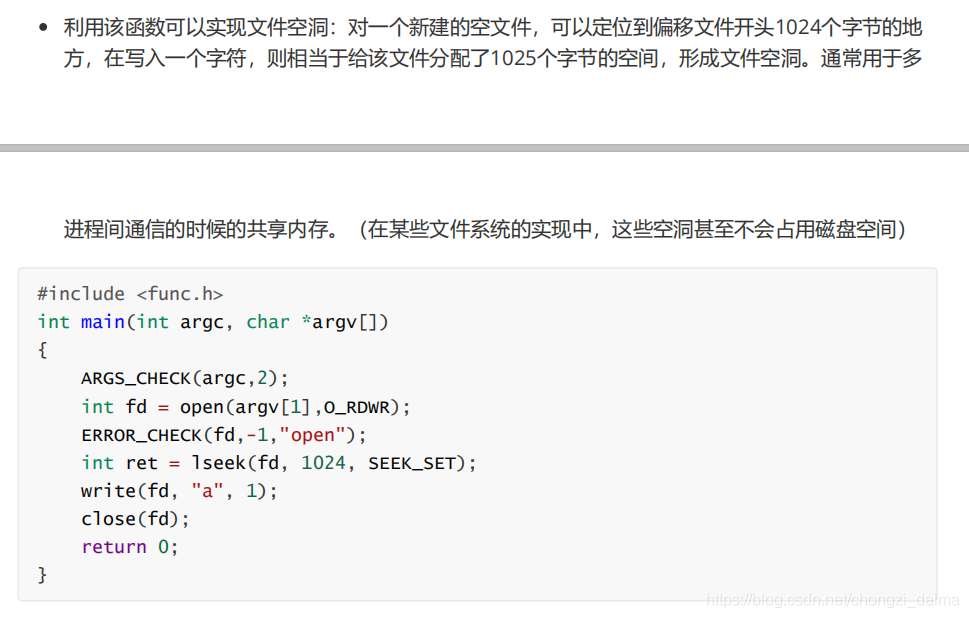
1.3.7 獲取檔案資訊
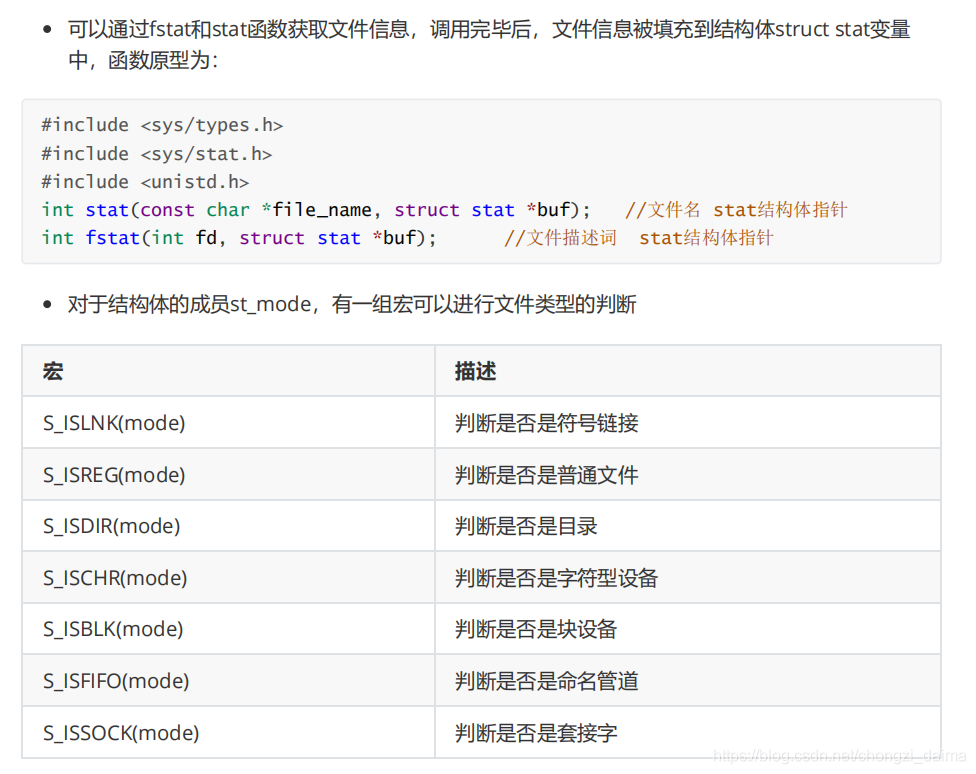
1.3.8 檔案描述符的複製


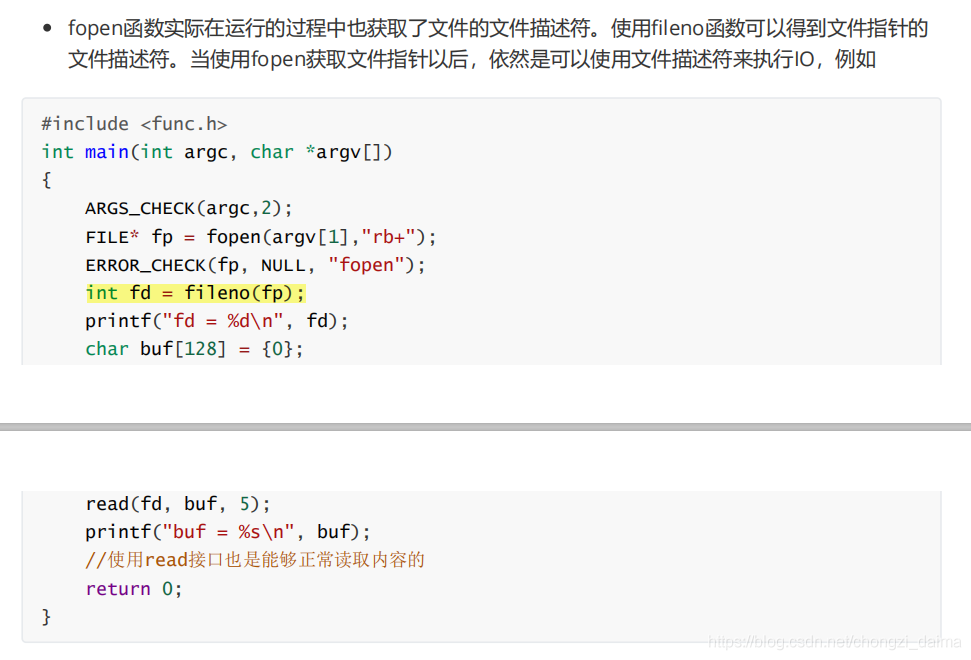
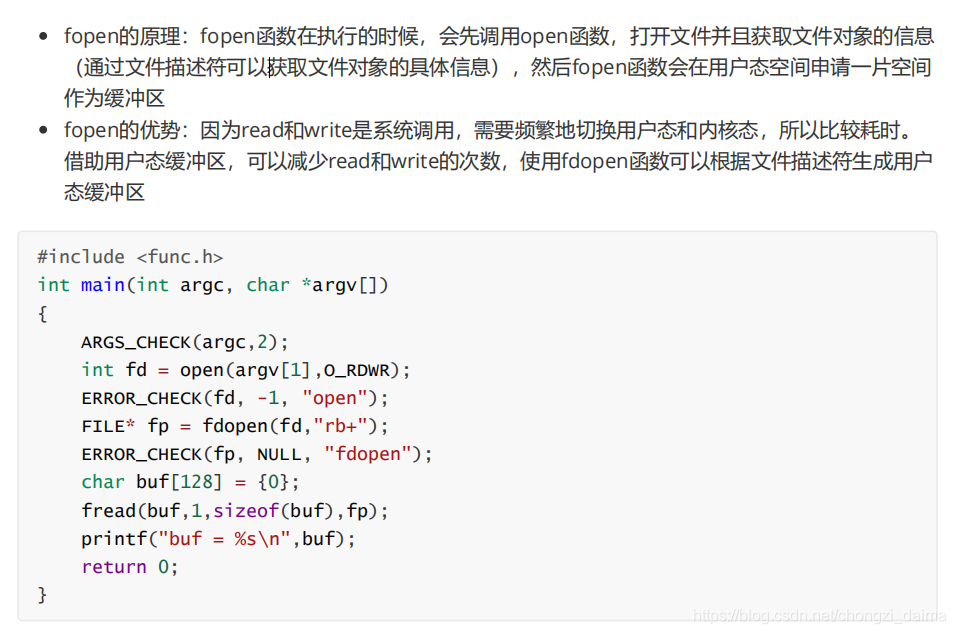
1.3.9 檔案描述符和檔案指針

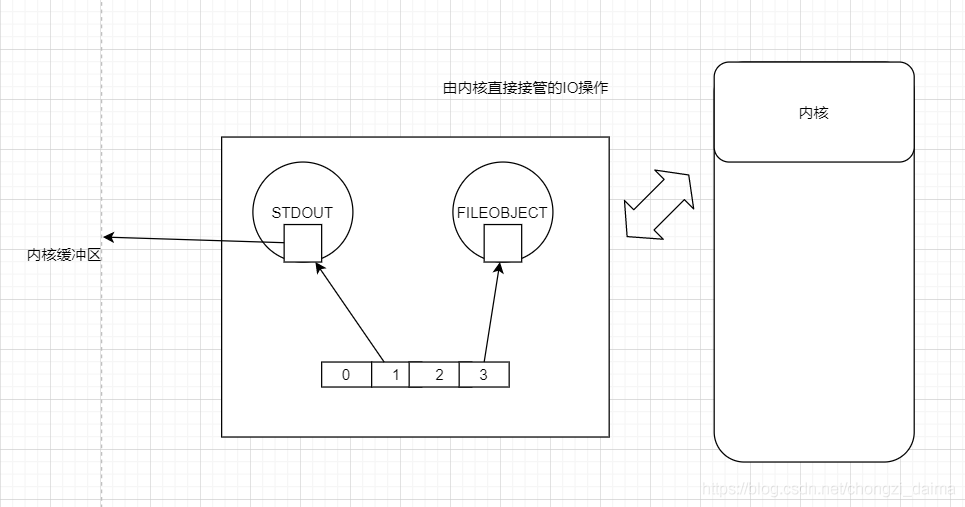
1.3.10 標準輸入輸出檔案描述符

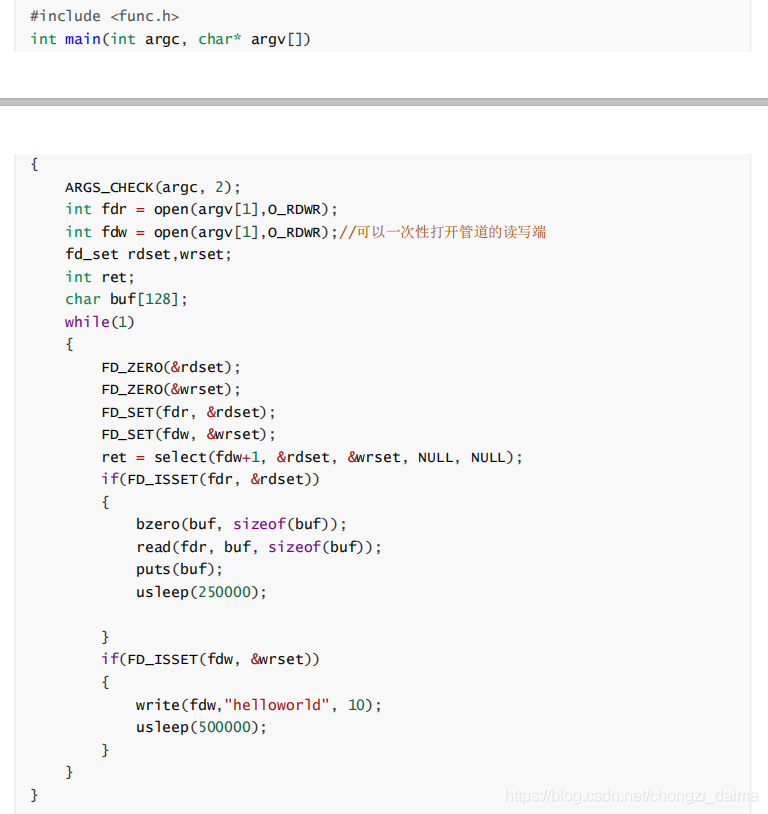
1.3.10 管道
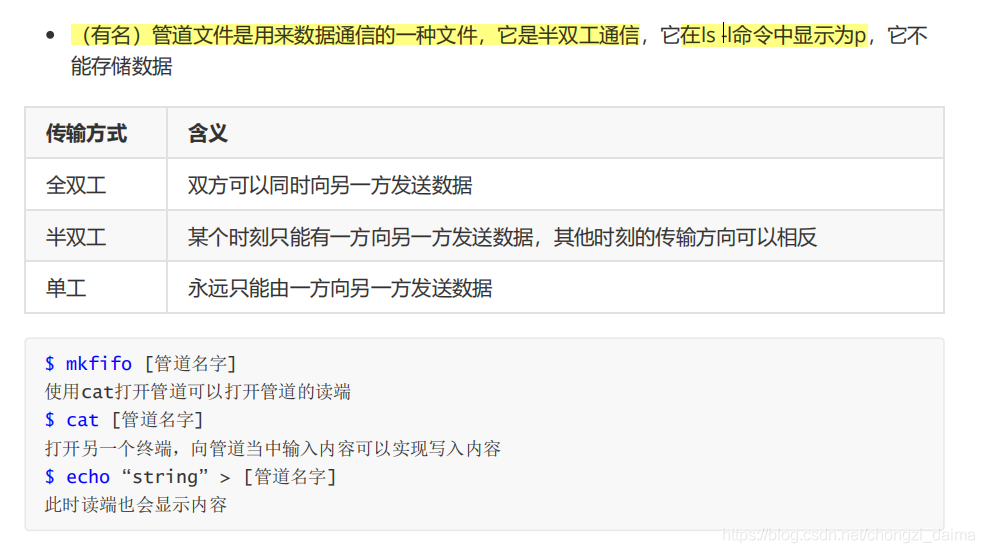
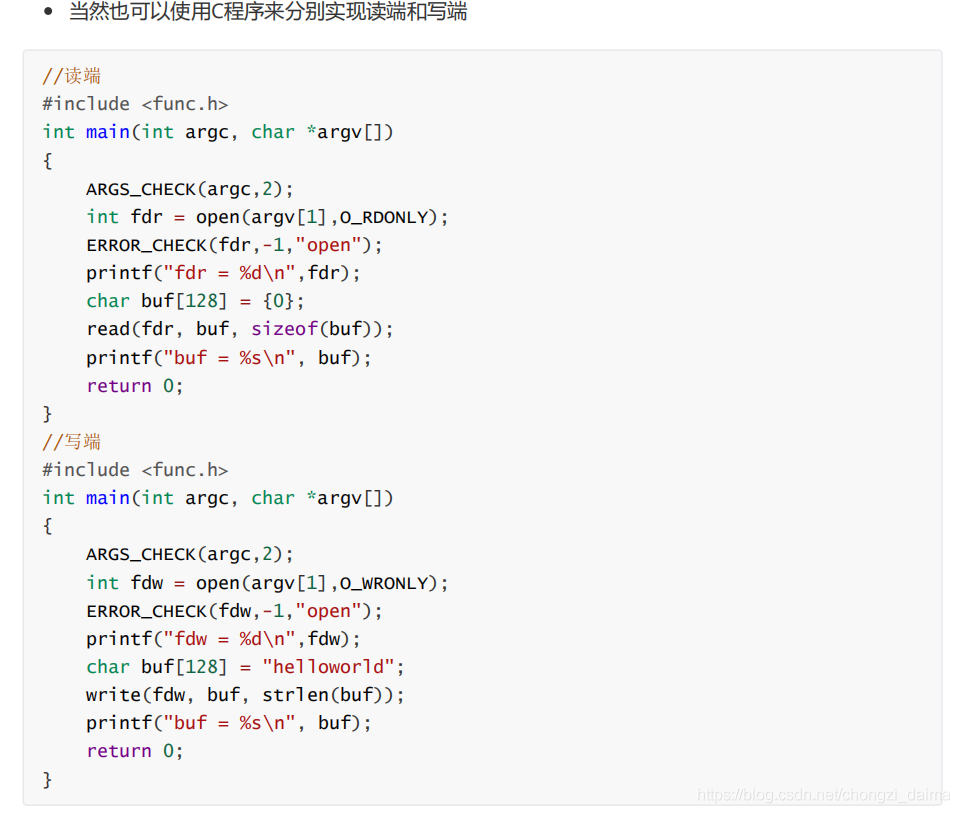
1.4 I/O多路轉接模型
1.4.1 讀取操作的阻塞
1.4.2 IO 多路複用模型和 Select
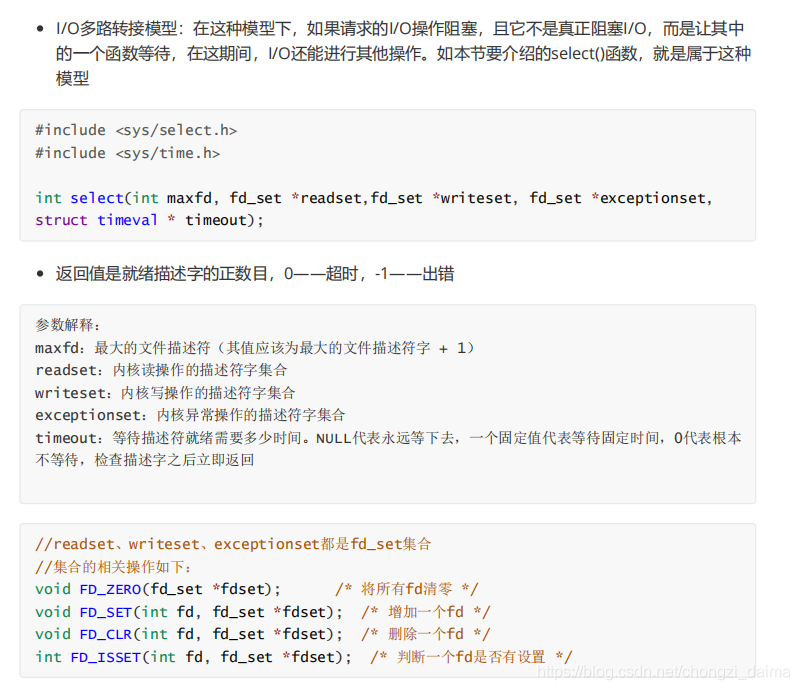


1.4.3 select的退出機制 機製
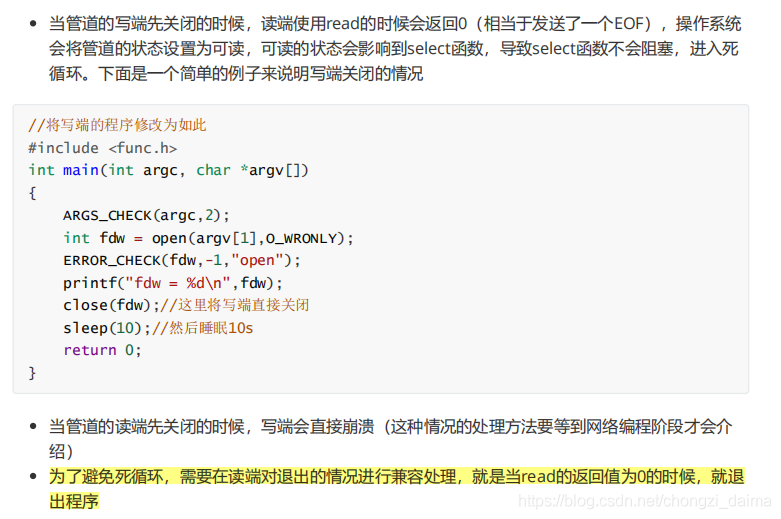
1.4.4 select函數的超時處理

1.4.5 寫集合的原理

二. Linux 進程控制
1.1 Linux 進程概述
在早期的多機處理系統中, 併發執行程式的話(由於併發程式的速度不同與資源競爭導致了程式執行的間斷性),存在數據計算結果的不可再現性,這樣的程式失去了其意義。
後來呢爲了使得程式能併發執行且有效地對併發程式進行控制與描述,引入了進程的概念。
進程是如何產生的?
在程式執行前, 操作系統會爲之分配一個PCB(過程控制塊:系統通過PCB對進程控制與描述), PCB與程式段和程式相關的數據一起構成了進程實體。
進程的實質就是進程實體的一次執行過程。
進程和程式本身的區別
程式是靜態的,是儲存在磁碟上的指令的有序集合,進程是一個動態的概念
它是一個執行着的程式,包括了進程的動態建立,排程和消亡的過程,是Linux的基本排程單位。
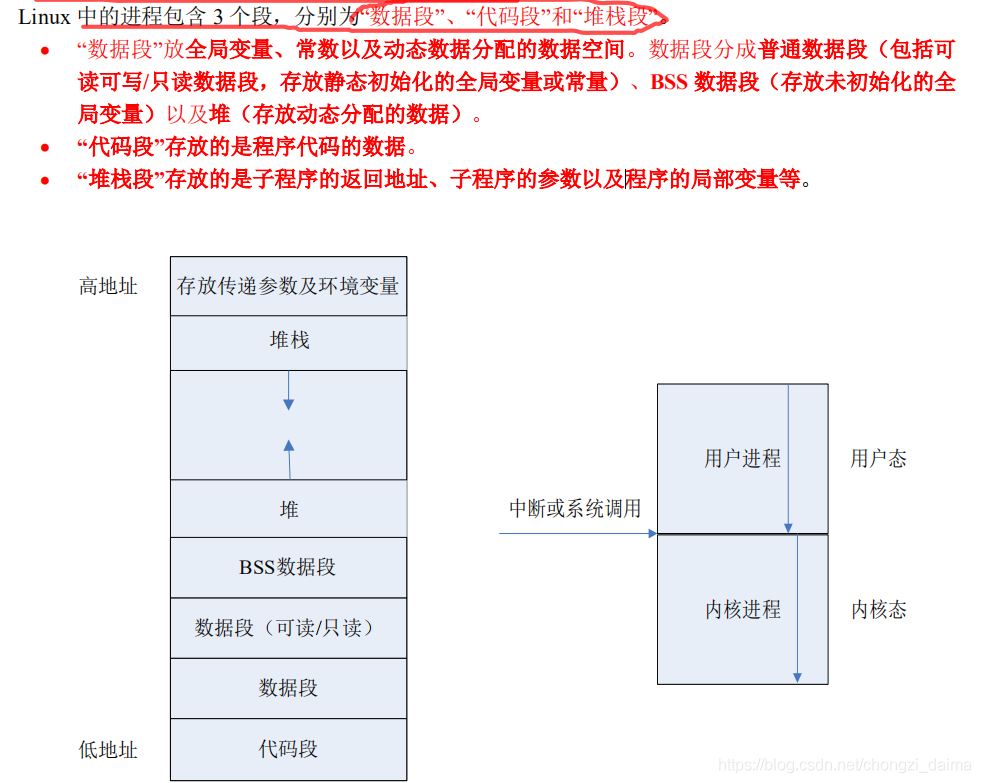
進程 process:是 os 的最小單元 ,os 會爲每個進程分配大小爲 4g 的虛擬記憶體空間,其中 1g 給內核空間, 3g 給使用者空間{程式碼區 數據區 堆疊區}
操作系統和進程間的聯繫
- 系統通過過程控制塊來描述進程的動態變化,過程控制塊有進程的基本資訊,控制資訊和資源資訊。
- 操作系統內核通過進程來控制對 CPU 和其他系統資源的存取,並決定進程的CPU 使用和運作時間。
Linux 內核通過一個被稱爲 進程描述符的 task_struct 結構體來管理進程,這個結構體包含一個進程所需的所有資訊。
它定義在 \kernel\msm-4.4\include\linux\sched.h 檔案中,
struct task_struct {
進程描述資訊
進程識別符號
進程的使用者識別符號
進程控制資訊
1.進程狀態 2. 優先順序
檔案和檔案系統
記憶體管理
信號處理
}
1.1.1 進程的識別符號
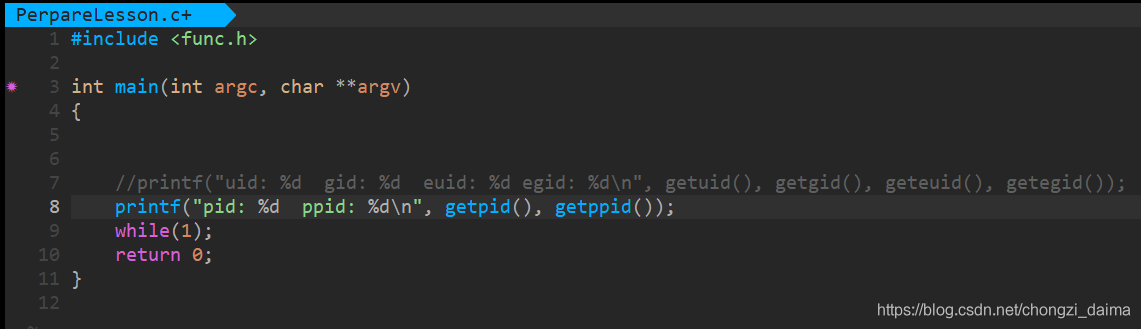
- OS 會爲每個進程分配一個唯一的整數 ID, 作爲其標識號(pid)。
- 進程描述符結構體也存放了其父進程的 ID(ppid)
- 其次,所有的進程的祖先進程是同一個進程,叫做 Init 進程,ID 號爲 1,Init 是內核自舉後啓動的一個進程,負責引導系統,啓動守護行程並且允許必要的程式。
通過 標準 c 的函數可以獲取當前進程的 pid 和 ppid
1.1.2 進程的使用者 ID 和 組ID (進程的執行身份)
進程的使用者ID 和 組ID
- 進程的使用者標識了其進程的許可權控制, 預設情況下,誰啓動了進程,該進程的身份就有該使用者的身份
- 使用 getuid() 和 getgid() 能得到進程的真實使用者 ID 和真實組 ID。
進程的有效使用者ID 和 有效使用者組ID
-
內核對進程使用者執行的ID 進行檢查時,檢查的是其有效使用者ID 和 有效使用者組ID,預設情況下與真實使用者ID 和 真實組ID 其是相等的
-
使用 geteuid 和 getegid 能得到進程的有效使用者ID 和 有效使用者組ID
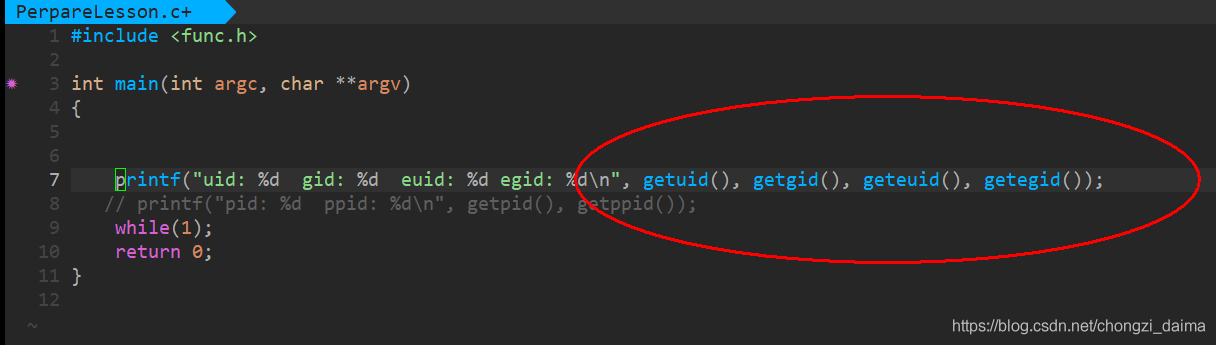
- 改變有效使用者ID 使得每個使用者對檔案的有效ID
chmod u+s 檔名
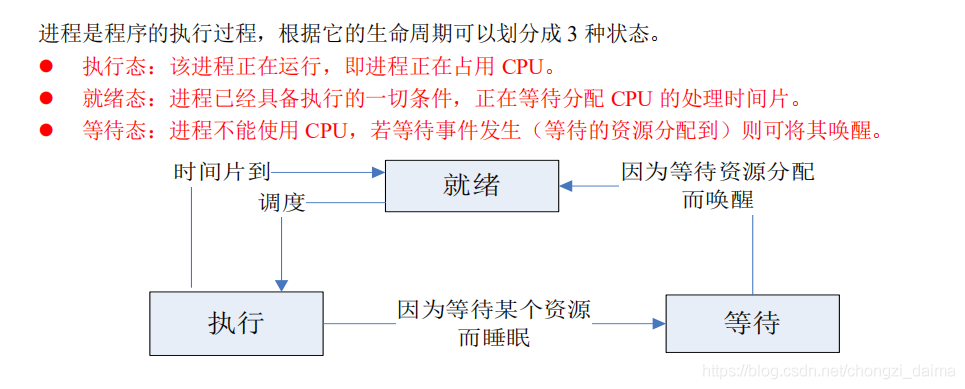
1.1.3 進程的狀態
1.1.3 Linux 下的進程結構
Linux 是多進程的系統,
-
進程間有並行性和互不幹 不乾擾性,進程間是各自分離的任務,每個進程擁有各自的權力和責任。
-
每個進程都執行在各自獨立的虛擬地址空間,因此,即使一個進程發生了異常,它也不會影響到系統的其他進程。
1.1.4 進程相關命令
1. ps -elf 檢視系統中的進程。ps 命令是一個採樣的資訊。
2. ps -aux 可以檢視進程的CPU和記憶體的佔用率。
3. echo $$列印當前bash的進程ID。
4. top命令 動態的顯示進程的資訊,
展示的是系統中CPU佔用率最高的20個進程。
5. kill命令,給進程發信號,
使用方式:kill -信號的編號 進程ID。通過kill -l可以檢視所有信號。
6. nice命令按照指定的優先順序執行進程,
renice命令可以修改進程的nice值,nice值的範圍:-20-19。
1. nice -n 可執行程式
2. renice -n 指定的nice值 -p 進程ID
1.1.5進程的排程策略
-
先來先服務排程演算法FCFS:佇列實現,非搶佔,先請求CPU的進程先分配到CPU,可以作爲作業排程演算法也可以作爲進程排程演算法;按作業或者進程到達的先後順序依次排程,對於長作業比較有利;
-
優先順序排程演算法(可以是搶佔的,也可以是非搶佔的):優先順序越高越先分配到CPU,相同優先順序先到先服務,存在的主要問題是:低優先順序進程無窮等待CPU,會導致無窮阻塞或飢餓;
-
時間片輪轉排程演算法(可搶佔的):按到達的先後 先後對進程放入佇列中,然後給隊首進程分配CPU時間片,時間片用完之後計時器發出中斷,暫停當前進程並將其放到佇列尾部,回圈 ;佇列中沒有進程被分配超過一個時間片的CPU時間,除非它是唯一可執行的進程。如果進程的CPU區間超過了一個時間片,那麼該進程就被搶佔並放回就緒佇列。
-
最短作業優先排程演算法SJF:作業排程演算法,演算法從就緒佇列中選擇估計時間最短的作業進行處理,直到得出結果或者無法繼續執行,平均等待時間最短,但難以知道下一個CPU區間長度;缺點:不利於長作業;未考慮作業的重要性;執行時間是預估的,並不靠譜 ;
-
高相應比演算法HRN:響應比=(等待時間+要求服務時間)/要求服務時間;
-
多級佇列排程演算法:將就緒佇列分成多個獨立的佇列,每個佇列都有自己的排程演算法,佇列之間採用固定優先順序搶佔排程。其中,一個進程根據自身屬性被永久地分配到一個佇列中。
-
多級反饋佇列排程演算法:目前公認較好的排程演算法;設定多個就緒佇列併爲每個佇列設定不同的優先順序,第一個佇列優先順序最高,其餘依次遞減。優先順序越高的佇列分配的時間片越短,進程到達之後按FCFS放入第一個佇列,如果排程執行後沒有完成,那麼放到第二個佇列尾部等待排程,如果第二次排程仍然沒有完成,放入第三佇列尾部…。只有當前一個佇列爲空的時候纔會去排程下一個佇列的進程。與多級佇列排程演算法相比,其允許進程在佇列之間移動:若進程使用過多CPU時間,那麼它會被轉移到更低的優先順序佇列;在較低優先順序佇列等待時間過長的進程會被轉移到更高優先順序佇列,以防止飢餓發生。
1.1.6 對談,行程羣組,前臺進程和後臺進程
1. 對談,控制終端,對談中的首進程是bash進程,一個對談下面 下麪可以有多個行程羣組。包括一個前臺行程羣組和若幹個後臺行程羣組。
2. 前臺行程羣組,可以接受控制終端上傳輸的數據。
3. 後臺執行一個進程,在執行程式時後面加一個&符號,變成了後臺進程。
4. 通過jobs命令可以看到當前對談下面 下麪的後臺作業,每個作業都有一個編號。可以通過fg+作業編號把後臺執行的作業拉回到前臺。拉回到前臺之後,就可以通過控制終端跟前臺進程互動。