python sklearn中的分類演算法:定義及簡單應用
本階段的學習目的,主要是瞭解各種演算法,並從中選擇準確率最高的一種。用到的庫是scikit-learn,即sklearn。
文章目錄
樸素貝葉斯
定義
在機器學習中,樸素貝葉斯分類器是一系列以假設特徵之間強(樸素)獨立下運用貝葉斯定理爲基礎的簡單概率分類器。
通常,事件A在事件B(發生)的條件下的概率,與事件B在事件A(發生)的條件下的概率是不一樣的,其中:
- B事件發生之前,A事件的概率(A的先驗概率),以P(A)表示。
- A事件發生之前,B事件的概率(B的先驗概率),以P(B)表示。
- 已知B發生後A的條件概率(A的後驗概率),以P(A|B)表示。
- 已知A發生後B的條件概率(B的後驗概率),以P(B|A)表示。
如果我們已經知道A、B的先驗概率和B的後驗概率,希望求得A的後驗概率,可以用以下公式:
其中,P(B|A)/P(B)被稱爲"可能性函數"(Likelyhood),這是一個調整因子,使得預估概率更接近真實概率。
所以,條件概率可以理解成下面 下麪的式子:
貝葉斯推斷的含義。我們先預估一個"先驗概率",然後加入實驗結果,看這個實驗到底是增強還是削弱了"先驗概率",由此得到更接近事實的"後驗概率"。
在這裏,如果"可能性函數",意味着"先驗概率"被增強,事件A的發生的可能性變大;如果"可能性函數"=1,意味着B事件無助於判斷事件A的可能性;如果"可能性函數"<1,意味着"先驗概率"被削弱,事件A的可能性變小1。
【例子】水果糖問題
假設有兩個一模一樣的碗,一號碗有30顆水果糖和10顆巧克力糖,二號碗有水果糖和巧克力糖各20顆。現在隨機選擇一個碗,從中摸出一顆糖,發現是水果糖。請問這顆水果糖來自一號碗的概率有多大?
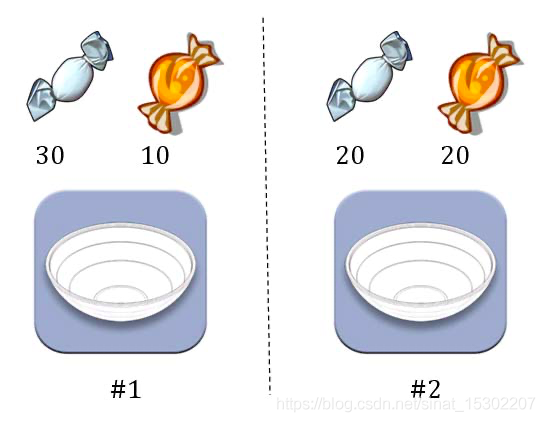
以表示一號碗,表示二號碗。由於這兩個碗是一樣的,所以P()=P(),兩個碗被選中的概率相同。因此,P()=0.5,即選中一號碗的概率是0.5。
再假定,E表示水果糖,題目問題就變成了在已知E的情況下,來自一號碗的概率有多大,即求P(|E)。
將數位代入原方程,得到:
「可能性函數」,表明取出水果糖之後(E),事件的可能性得到了增強1。
樸素貝葉斯類庫的GaussianNB
如果要處理的是連續數據,一種通常的假設是這些連續數值的分佈曲線將會呈兩頭低,中間高,左右對稱的正態分佈(normal distribution),即高斯分佈(Gaussian distribution),所以用到的是高斯樸素貝葉斯(GaussianNB)分類演算法。
class sklearn.naive_bayes.GaussianNB(*, priors=None, var_smoothing=1e-09)
其中priors爲該類的先驗概率,var_smoothing爲所有特徵的最大方差部分預設爲1e-9。
In [1]:
import numpy as np
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Y = np.array([1, 1, 1, 2, 2, 2])
In [2]:
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(X, Y) # 根據X,y擬合高斯樸素貝葉斯
In [3]:
print(clf.predict([[-0.8, -1]])) # 對向量X進行分類
Out[3]: [1]
In [4]: print(clf.score([[-0.8, -1]], [1])) # 返回給定X和y的平均準確度。
Out[4]: 1.0
支援向量機
定義
假設某些給定的數據點各自屬於兩個類之一,我們需要確定新數據點將在哪個類中。如果這些點在一個二維的平面上,支援向量機(support vector machines, SVM)就是劃分這兩類數據的一條直線。
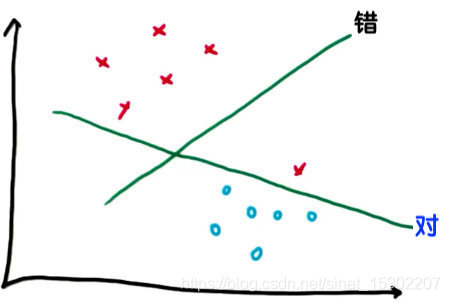
如上圖所示,儘管另一條線能使其他點與線的間隔最大化,但支援向量機首先考慮分類的正確。
不過,SVM在無法區隔時也會忽略異常值,採用折中的方案,SVM的參數決定它如何應對新的異常值。

核(Kernel)
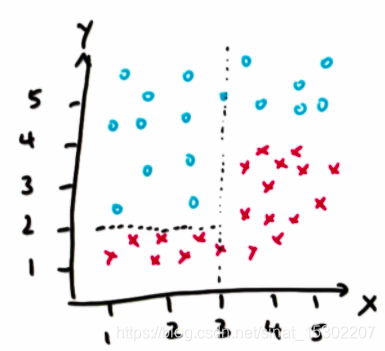
有時,折中的方案的直線也不能很好的分類,如下圖:
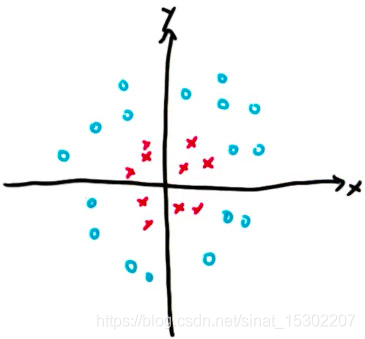
如果我們想用SVM把上圖紅藍點區分開來,需要新建一個變數,然後再將z與y區分開來:
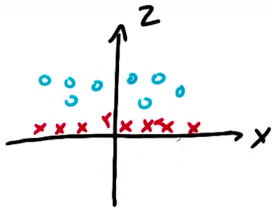
這就是SVM的核,它將低維度的特徵值(x,y),對映到高維度空間,獲得解後再返回原始空間,得到一個非線性的分隔線。
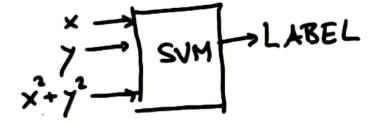
-
sklearn.svm庫中預設的核函數是’RBF’(radial basis function, 徑向基函數核, 又稱爲高斯核函數)。
-
實際工作中一般用線性核(Linear)和RBF核:
-
Linear核():主要用於線性可分的情形。參數少,速度快,對於一般數據,分類效果已經很理想了。
-
RBF核():可以處理非線性的情況,linear kernel可以是RBF kernel的特殊情況;sigmoid kernel又在某些參數下和RBF很像。
-
sigmoid核(S函數, ):採用sigmoid核函數,支援向量機實現的就是一種多層神經網路。
-
poly核(polynomial, 多項式核函數, ):
參數比RBF多,而參數越多模型越複雜。
-
precomputed:表示自己提前計算好核函數矩陣,這時候演算法內部就不再用核函數去計算核矩陣,而是直接用你給的核矩陣
-
-
因此,在選用核函數的時候,如果我們對我們的數據有一定的先驗知識,就利用先驗來選擇符合數據分佈的核函數;如果不知道的話,通常使用交叉驗證的方法,來試用不同的核函數,誤差最下的即爲效果最小的核函數,或者也可以將多個核函數結合起來,形成混合核函數。
-
吳恩達也曾總結過選擇核函數的方法:
-
如果特徵的數量大到和樣本數量差不多,則選用線性迴歸(Linear Regression)或者Linear核的SVM;
-
如果特徵的數量小,樣本的數量正常,則選用SVM+RBF核函數;
-
如果特徵的數量小,而樣本的數量很大,則需要手工新增一些特徵從而變成第一種情況2。
注:特徵指的是從原始數據提取的單個屬性,一般是一個數。原始數據必須轉化成一個特徵向量纔可以進一步分析。它們類似於統計中的自變數。特徵向量所屬的向量空間稱爲特徵空間。
-
參數(parameters)——C與gamma
- SVM模型有兩個非常重要的參數C與gamma()。
- 其中,C是懲罰係數(regularization parameter),即對誤差的寬容度。C越高,說明越不能容忍出現誤差,容易過擬合(準確率太高);C越小,容易欠擬合(準確率太低)。C過大或過小,泛化能力變差。
- 而gamma是 ‘RBF’、'poly’和’sigmoid’的自帶參數,它能隱含地決定數據對映到新的特徵空間後的分佈情況。gamma越大,支援向量越少;gamma值越小,支援向量越多。支援向量的個數將進一步影響訓練與預測的速度3。
- BYR_jiandong(2015)根據gamma的物理意義認爲:如果gamma設得太大,可能會使分類效果只作用於支援向量樣本附近,導致模型對訓練集分類準確率高,但對測試集分類準確率不高的情況出現;而如果gamma值設得過小,則會造成平滑效應太大,無法在訓練集上得到特別高的分類準確率,也會影響測試集的分類準確率3。
sklearn.svm庫
class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale')
儘管SVM與樸素貝葉斯的原理有較大差異,但在sklearn中,svm庫的使用方法與GaussianNB差不多,只需要將上面GaussianNB的"In [2]"稍加修改就可以直接輸出結果:
In [2]:
from sklearn.svm import SVC
clf = SVC(gamma='auto')
clf.fit(X, Y) # 根據X,y擬合svm
使用RBF核時可以明顯感覺到運算時間長於GaussianNB和SVM的Linear核。
決策樹
定義:分支做判斷,葉子下結論
決策樹演算法,人如其名,結構就像一棵樹,有分叉的枝丫和樹葉。枝丫的分叉處是關於目標某一個特徵的判斷,枝丫本體則是關於該特徵的判斷結果,而葉子則是判斷過後產生的決策結果。如下圖所示,這是一個最爲簡單的分類樹決策,根據降雨、霧霾、氣溫、活動範圍是室內活動還是室外活動等等特徵,將行爲分類爲出門和不出門。簡單來說,決策樹可以被看做由一大堆if-then的判斷,每一條枝丫都是一條規則4。
更多的情況,我們需要在特徵向量所屬的特徵空間中分類。例如我們需要將下圖的數據分類:
則決策樹可寫爲:
參數(Parameters)
最少樣本分割(min sample split)
定義
決策樹的最少樣本分割值(min_sample_split)預設爲2,也就是說當節點樣本爲1時,就無法再分割了。
效果
設定最少樣本分割值可以幫助我們獲得更簡單的決策邊界
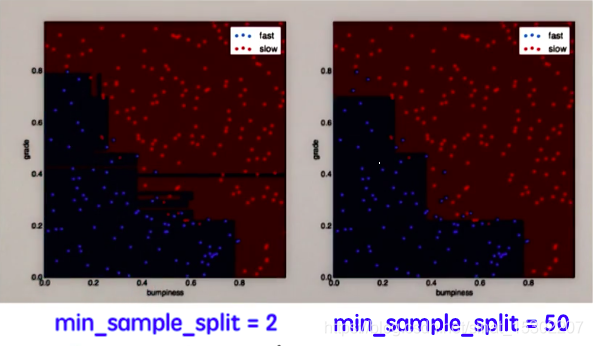
sklearn程式碼
更簡單的決策邊界有助於獲得更高的準確率,獲取準確率的程式碼與前面的方法類似:
In [1]: features_train, labels_train, features_test, labels_test = makeTerrainData()
from sklearn import tree
clf2 = tree.DecisionTreeClassifier(min_samples_split=2)
clf2.fit(features_train, labels_train)
acc_min_samples_split_2=clf2.score(features_test, labels_test)
clf50 = tree.DecisionTreeClassifier(min_samples_split=50)
clf50.fit(features_train, labels_train)
acc_min_samples_split_50=clf50.score(features_test, labels_test)
In [2]: def submitAccuracies():
return {"acc_min_samples_split_2":round(acc_min_samples_split_2,3),
"acc_min_samples_split_50":round(acc_min_samples_split_50,3)}
Out[2]:
{"message": "{'acc_min_samples_split_50': 0.912, 'acc_min_samples_split_2': 0.908}"}
可以看出,min_samples_split_50的準確率爲0.912,高於min_samples_split_2的準確率0.908。
不過,更簡單的決策邊界與準確率的增加不是必然聯繫的,在實踐中需要調整參數,形式每個參數對結果影響的直觀印象,瞭解參數對決策邊界形狀的影響,以優化演算法效能。
標準(Criterion)——熵(Entropy)
定義
Criterion這個參數是用來決定不純度的計算方法的。sklearn提供了兩種選擇: 1)輸入」entropy「,使用資訊熵 ;2)輸入」gini「,使用基尼係數(Gini Impurity)。
其中熵在資訊理論中代表隨機變數不確定的度量,熵越大代表隨機變數的不確定性就越大。
在決策樹中,熵會控制決策樹分割數據的位置,因爲較低的熵指向更有條理的數據。
熵的公式爲:
該公式表示:
- 假如一組數據有k類資訊,那麼每一個資訊所佔的比例就是。
- 因爲只可能是小於1的,所以始終是負數。所以需要在公式最前面加負號,讓整個熵的值大於0。
例子
假設有一臺根據路況數據中的坡度、是否顛簸、是否限速來調整行車速度的自動駕駛汽車,數據如下:
| 坡度 | 是否顛簸 | 是否限速 | 行駛速度 |
|---|---|---|---|
| 陡峭 | 顛簸 | 是 | 慢 |
| 陡峭 | 平緩 | 是 | 慢 |
| 平地 | 顛簸 | 否 | 快 |
| 陡峭 | 平緩 | 否 | 快 |
自動駕駛汽車的速度分爲快和慢,那每種速度所佔的比例就是,那麼和也均爲。
代入資訊熵的公式可得:
熵值爲1,說明該樣本的各個樣本平均地分配在每個類中,是樣本數據單一性最差的狀態。
再來看一個極端的例子,,將其代入資訊熵公式後得到的值是0。因爲整個數據中就一種型別的數據,所以不確定性達到了最低,既資訊熵的最小值爲05。
資訊增益(information gain)
定義
父節點的熵減去子節點的熵的加權平均:
資訊增益與決策樹
決策樹演算法會最大化資訊增益,以此來劃分特徵。如果特徵可以取多個不同的值,該方法將從中提煉出劃分特徵的位置。
例子
- 在上面自動駕駛汽車的例子中,已經計算出父節點的熵爲1。接下來,我們嘗試利用資訊增益對「坡度」這一變數進行計算。
-
如圖所示,平地地形節點只有一個類別,;
陡峭地形的 ,,。 -
子節點的熵的加權平均爲:
-
資訊增益:
-
同理,對於‘是否顛簸’的資訊增益:
,我們不能在這個變數中獲得任何資訊。
-
是否限速的資訊增益:
,得到最大的資訊增益。
總結:決策樹的優缺點
優點
- 可解釋性好
- 只需要很少的數據預處理工作。並且能夠處理各種型別的特徵
- 原生支援多分類
缺點
-
決策樹容易過擬合
-
決策樹不穩定,也就是說可能數據集的一個很小的變動就會導致樹發生很大的改變。
-
構建一個最佳的決策樹是一個NP-hard問題6,現有的啓發式演算法不能夠保證最優(也沒有一個理論的上下界)。
- 簡單的決策樹模型比較簡單,很難表示數據集中的複雜關係。
其他分類演算法
k nearest neighbors: K-近鄰演算法
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier()
AdaBoost (Adaptive Boosting): 自適應增強
from sklearn.ensemble import AdaBoostClassifier
clf = AdaBoostClassifier()
random forest: 隨機森林
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
研究與理解演算法的步驟
-
在Google查一下演算法的概念,可以的話向別人講解一下
-
在sklearn網站上檢視
-
實際操作sklearn程式碼
-
對比accuracy
P問題:有多項式時間演算法,算得很快的問題。NP問題:算起來不確定快不快的問題,但是我們可以快速驗證這個問題的解。NP-complete問題:屬於NP問題,且屬於NP-hard問題。NP-hard問題:比NP問題都要難的問題。 ↩︎