MySQL數據庫超精華點總結(筆記配合操作更快上手)

數據庫概念性知識總結
0:序
秋招之際,對於應屆大學生而言,如果簡歷上能夠增加上關於數據庫的一些相關知識,無疑是錦上添花,而不論是網上的一些課程還是書籍看起來都過於繁瑣,這篇知識總結也是我自己學習數據可路程上所進行的總結和積累,希望幫助到更多的同伴,秋招加油!(可以收藏起來分幾天時間看)
1. 初試數據庫
守護行程:
在我們檢視mysql埠的時候會發現,會存在一個mysql_safe的存在,這也就是我們所說到的的守護行程,守護行程在判斷mysql伺服器是否執行正常,如果mysql使用過程當中,伺服器端掛掉了,守護行程就會重新拉起來mysql伺服器端,保證muysql的正常工作。
mysql伺服器端:
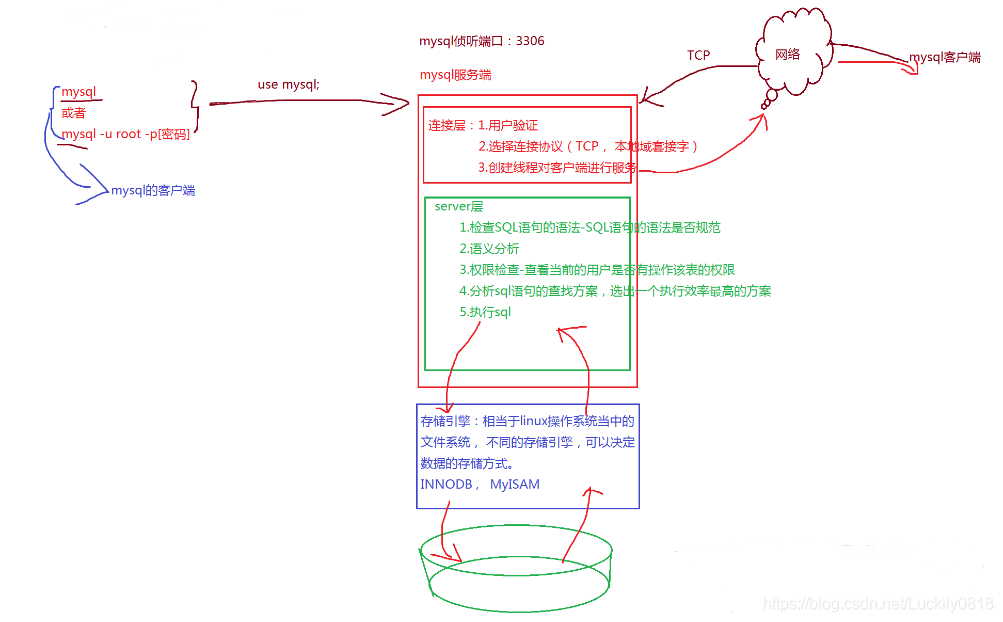
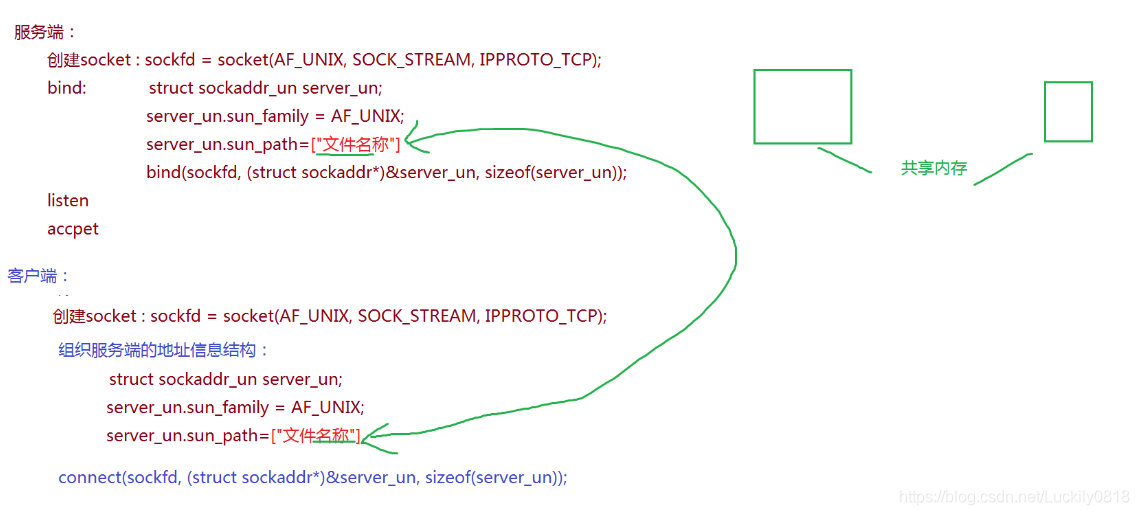
對於域通訊端的話,其本質上就是本地機器當中建立一個檔案,用戶端和伺服器端通過檔案來進行通訊,本質上就是進程間通訊,這個進程間通訊會走網路協定棧。(程式碼如下)
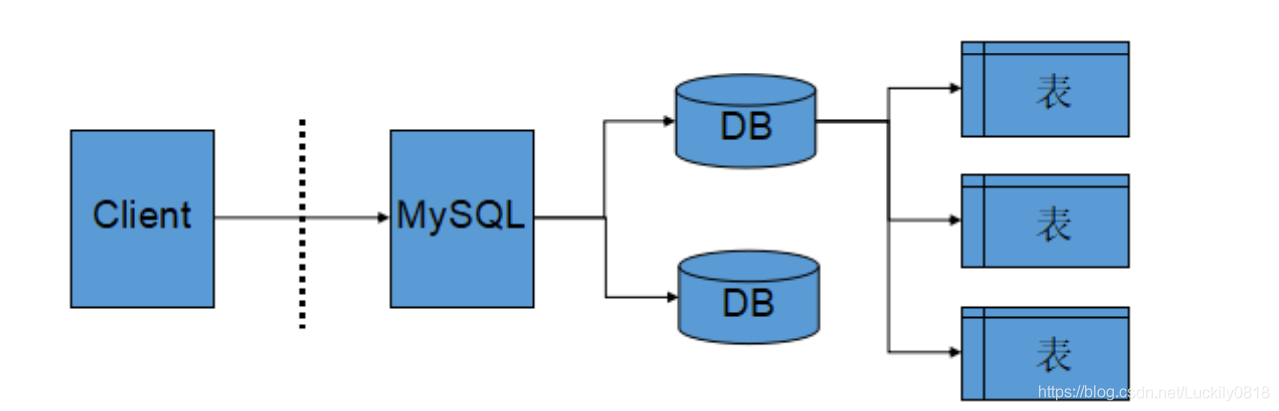
數據庫就像是一個資料夾一般,管理着諸多的檔案,也就是我們的數據表。
- 檢視mysql當中有多少個數據庫:
show databases; - 檢視當前數據庫當中的數據表:
show tables; - 切記sql語句的結尾必須加上分號
;
2. 數據庫基礎操作
字元集:

校對規則:
- 影響了使用者對數據查詢的一個排序
- 後綴爲_cs:大小寫敏感的校對規則,後綴爲_ci:大小寫不敏感的校對規則,後綴爲_bin:二進制校對規則,大小寫敏感
- 校對規則的特徵:不同的字元集有着不同的校對規則,每一個字元集也都有着自己一個預設的校對規則,如utf8的校對規則是 utf_general_ci
- 建立數據庫
create database helloworld charset=utf8 collate utf8_general_ci;
建立一個使用utf字元集,並帶校對規則的 db3 數據庫。
-
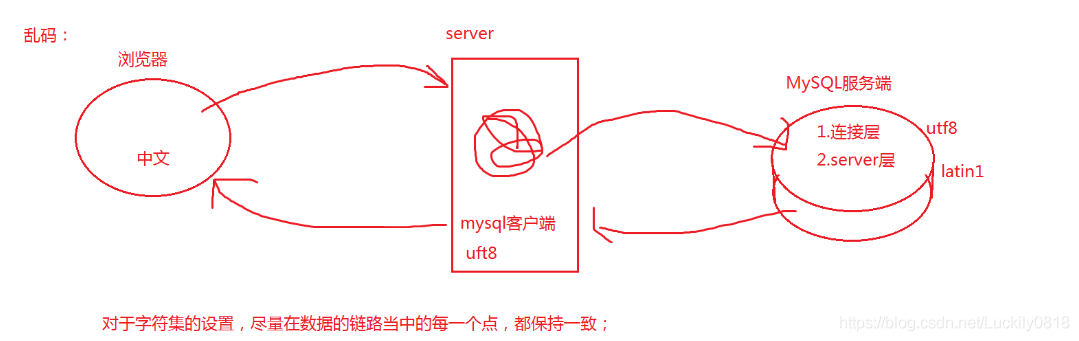
爲何要使用指定字元集呢?
這也是爲了避免亂碼的出現,亂碼的來源就是由於前後端字元集不匹配的原因造成的,因此在我們建立數據庫的時候儘可能地指定字元集,儘量數據的字元集設定成utf8!!
-
檢視已經建立好的數據庫的建立語句
show create database helloworld;
- 使用數據庫
use helloworld; - 刪除數據庫
刪除連帶數據庫當中的表也刪除掉drop database; - 建立表
建立表的時候,設定列的名稱以及列的屬性:create table [表名稱](列的名稱 列的型別 comment ' 註釋', ...)
插入數據的時候,插入一行數據,包含了多個列的屬性,而註釋則是方便後來者檢視數據時知道此數據表示什麼。 - 檢視和修改表欄位
檢視錶欄位:desc [表欄位]

修改表欄位
- 新增:
alter table [表名稱] add [欄位的名稱][ 欄位的型別]aftre[欄位的名稱]; - 刪除:
alter table [表的名稱]drop [欄位的名稱];如果刪除某一個列,則該列的數據也隨之刪除 - 修改:
alter table [表名稱] modify [欄位的名稱][修改後的欄位型別] - 表的重新命名:
alter table [待命名的表名稱]rename to [重新命名後的名字]; - 列名稱的重新命名:
alter table[ 表名稱] change [欄位名][修改後的名稱][欄位屬性]; - 刪除表:
drop table 表名稱;
- 表的基本操作
- 增加數據
全列增加:insert into 表名稱 values (表欄位對應的值,....)
指定列插入:insert into 表名稱 (表中的列名稱)values(指定表欄位對應的值,....)
一次插入多行數據:insert into 表名稱 values (表欄位對應的,...) ,(表欄位對應的值,....)
一次插入一列的多行數據:insert into 表名稱 (表中的列名稱)values(指定表欄位對應的值,...),(指定表欄位對應的值,...)
更新數據:update 表名稱 set 欄位=‘ 內容’; - 簡單查詢
全列查詢:select * from [表名稱];
指定列查詢:select 列名稱1,列名稱2 ,列名稱3 from 表名稱;
表達式當中不包含列欄位:select 列名稱1,列名稱2,表達式 from 表名稱
表達式中包含多個欄位:select 列名稱1+列名稱2+列名稱3+...from 表名稱
爲查詢結果定義別名:select 列名稱1+列名稱2+列名稱3 別名...from 表名稱
- 備份和恢復(此操作在數據庫外操作)
數據庫備份:mysqldump -p 埠 -u 使用者 -p 密碼 -B 數據庫的名稱 > 檔案
數據表備份:mysqldump -p 埠 -u 使用者 -p 密碼 -B 數據庫的名稱 表名稱1 表名稱2 > 檔案

3. 數據型別
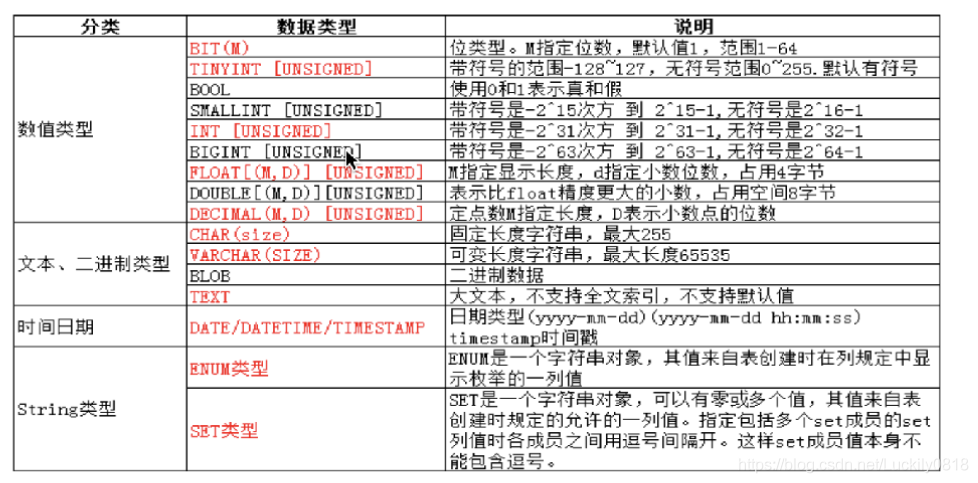
- tinyint型別 :佔用1哥位元組,表示範圍(-128~127)
- 在my.cnf當中mysqld標籤下增加「sql_mode=STRICT_ALL_TABLES」,增強數據庫對插入數據的型別範圍的校驗
- 如果在設計數據庫表欄位的時候,涉及到整數數據,儘量不要用tinyint(根據實際情況),而是用表示範圍大的整型型別
- 對於整形數據,在設計的時候,儘量少用unsigned,因爲一個小的數位,減去一個大的數位,可能會導致結果出錯。
- BIT型別
- 如果設定BIT型別,它的值時按照ASCII碼來表示的
- 如果只想儲存0和1,則BIT型別的位元位數設定成1
- 小數 float和decimal兩種
float(4,2) 表示的範圍是-99.99~99.99MySQL在儲存值是會自動進行四捨五入,如果是無符號的話,float(4,2)unsigned則只能夠表示0~99.99,float精度大約爲7位- decimal的精度更加準確,因此如果我們希望某個數據表示高精度,則選擇decimal,它的整數位65,小數位30.
- 字串型別
- char(L) 固定長度的字串,L不是佔用位元組的大小,而是字串的長度,字元佔用位元組的數量和數據庫的編碼格式息息相關,LATIN1:1個字元佔用一個位元組;utf8L一個字元佔用3個位元組 ==》 char(4): 4*3=12位元組
- varchar(L):可變長度的字串,L表示字元長度,到底可以儲存多少個位元組,和數據庫的編碼格式息息相關,理論上可以儲存65535個位元組,如果編碼格式表示字元不用1個位元組表示,而用n個字元來表示,則字串長度位(65535-(1~3))/n; 如:utf8 則是(65535-3)/3;
- 對於char而言定義後就自動開闢號空間,而varchar的話,在定義的範圍內,儲存多少字串,就開闢多大的空間,但是並不刻意超過固定的字串長度,且它需要1~3個位元組來儲存字串長度。
- 日期和時間型別
- datatime:時間日期型別:YYYY-MM-DD HH:mm:SS 需要自己插入時間
- date :只表示年月日
- timestamp:時間戳型別,可以自己計算年月日時分秒
- enum和set
- enum列舉,也就是單選,如果插入的不是枚舉出來的值,則就會報錯
- set集合,多選,可以選擇其中任意多個值機型組合儲存,但是如果不在列舉出來的值,就會報錯。
- 查詢語句:
select * from 表名稱 where 表欄位= ‘內容’在這個表中查詢此內容的資訊。
4. 表的約束
定義欄位的時候,需要有一個型別,這樣的一個型別,有時候並不能滿足我們對列數據的一個約束;例如表欄位是否可以爲NULL,有沒有預設值,表欄位的解釋能不能加上,對於數位型別的欄位可以不可以指定預設表示的位數,可不可以將這個欄位設定成唯一標識該行數據的呢?因此也就產生了表的約束!
對於欄位的約束:
- 空屬性
NULL:表示當前欄位可以爲NULL
NOT NULL:表示當前欄位不可以爲NULL,列的欄位指定該屬性之後,在插入數據的時候如果不插入該列數據,會報錯。 - 預設值
default:可以再建立表欄位的時候,制定一個預設值,當我們插入數據的時候,沒有插入該欄位的時候,就採用預設屬性。 - 列描述 comment ‘ 註釋’
相當於列的註釋,告訴檢視該表的使用者,該欄位是什麼含義,對於儲存數據而言,並沒有實質的約束。 - zerofill
約束了數位的寬度,如果寬度不夠則用0來填充 ,會預設加上unsigned無符號的屬性,在數據庫當中儲存的還是原本的數值,只不過列印的時候會按照寬度進行輸出(如:1 寬度爲3 則表示爲001 ) - 主鍵:不是重新開闢一個新的列,而是表當中的一列被設定屬性,這種屬性被稱之爲主鍵。
- 主鍵的屬性保證了該列數據不能爲空,不能重複
- 一個表當中只能夠有一個主鍵,不能由多個主鍵
- 主鍵在設定的時候,都是整型型別,主鍵的這一列數據可以唯一標識一行數據
- 主鍵列的值可以唯一標識該行的數據,因爲逐漸不能爲空,不能重複的原因
如何設定主鍵: - 在建立表的時候,直接在欄位的後面加上「primary key」
createtable t(id int primary key, name varchar(20)); - 在建立表的時候,在所有欄位全部指定完畢之後,在所有欄位後面加上設定的逐漸關鍵詞,並加上指定欄位的名稱
createtable t(id int, name varchar(20),primary key(id)); - 在建立表可以不指定,完成後通過alter關鍵字來增加主鍵
alter table t add primary key(id);
如何刪除主鍵:
使用alter關鍵字加上drop可以刪除 ,alter table t drop primary key;
- 自增長 auto_increment
當我們設定一個欄位爲自增長的時候,如果插入數據的時候,不給該列數據,則系統會自動填寫一個比上一行數值加1的數值填寫進去,通常自增長是搭配主鍵來進行使用的,主鍵不可重複每次自增長都會給新的數據分配比上一行+1的數值;
自增長的條件:
- 首先欄位必須是一個整數,欄位型別需要整數型別
- 一張表當中最多隻能夠有一個自增長的列
- 搭配主鍵使用
mysql> create table tt21(
-> id int unsigned primary key auto_increment,
-> name varchar(10) not null default ''
-> );
獲取上次插入的自增長的值
mysql > select last_insert_id();
- 唯一鍵 unique 給某個欄位設定一個屬性,該屬性約束欄位的內容不能重複但可以爲空NULL
主鍵比唯一鍵多了一個約束欄位內容不能NULL,但是一張表當中可以多個欄位被定義爲unique
mysql> create table student (
-> id char(10) unique comment '學號,不能重複,但可以爲空',
-> name varchar(10)
-> );
- 外來鍵用於定義主表和從表的一個約束關係
主表:存放基礎屬性的表,當前表中的數據用來描述基礎屬性
班級表即是主表,而學生表則是從表,存放具體的使用者產生的資訊
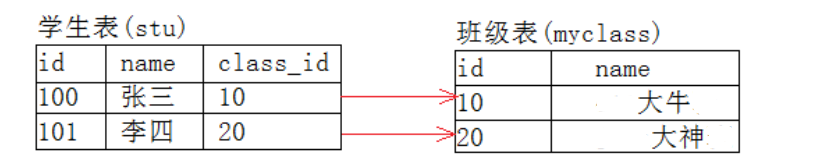
- 定義主表當中可能成爲其他表外來鍵的欄位,一定需要將該欄位設定成爲主鍵或者唯一鍵,因爲主鍵不能夠重複,不能夠爲空,可以唯一標識一行數據
- 定義從表的時候,設定外來鍵其實就是設定一個關係,當前從表的欄位和住表當中欄位的關係,在從表當中插入數據的時候,會對插入數據進行校驗,校驗的標準插入的數據是否存在主表列欄位當中。
建立主表
create table myclass (
id int primary key,
name varchar(30) not null comment'班級名'
);
建立從表
create table stu (
id int primary key,
name varchar(30) not null comment '學生名',
class_id int,
foreign key (class_id) references myclass(id)
);
5. 表的增刪改查
- 替換 replace into
如果要替換的數據不存在主鍵或者唯一鍵衝突,表的數據沒有衝突,則插入一行數據,表當中有衝突的話,則刪除之後在插入。
replace into 表名稱 欄位名稱 values (欄位對應的值,欄位對應的值,...);
對於一些在插入數據時時是整形插入的,但是後期有可能需要進行計算的數據,在定義欄位的型別時定義爲浮點數。 - 查詢
- 全列查詢
select * from*代表當前表的所有列 - 指定列查詢
select 欄位名稱 欄位名稱 from 表名稱 - 查詢時候,表達式中包含一個欄位:
select 欄位名稱,欄位名稱,表達式(欄位名稱) from 表名稱 - 去重:關鍵字distinct
select distinct 欄位名稱,欄位名稱 from 表名稱
- where條件 對查詢結果進行約束
- 運算子
-
任意一個結果成立:or => ’ || ’
-
多個結果一起成立:and => ‘&&’
-
in(option…) 如果是選擇之中任意一個,則成立
SELECT name, shuxue FROM exam_result WHERE shuxue IN (58, 59, 98, 99); -
範圍匹配: between a0 and a1 則表示[a0,a1];
SELECT name, yuwen FROM exam_result WHERE yuwen BETWEEN 80 AND 90; -
模糊匹配:like ‘%’表示任意多個字元;‘_’表示一個字元
SELECT name FROM exam_result WHERE name LIKE '孫%';
SELECT name FROM exam_result WHERE name LIKE '孫_';

- NULL查詢
IS NOT:不是xxx
是否爲空:IS NULL 是空 ; IS NOT NULL 不是空
= 和<=>都表示等於運算子,但是區別在於:
=在數據庫查詢的時候並不是安全的,空和空使用「=」進行比較的時候,結果還是爲NULL
<=>在數據庫查詢的時候是安全的,空和空使用「<=>」進行比較,結果爲1 - 對查詢結果進行排序 order by 欄位名稱
規則:按照order by 後面的欄位內容進行排序後輸出 預設是升序(ASC)降序的話是(DESC)
SELECT name, shuxue FROM exam_result ORDER BY shuxue; - 篩選分頁結果
- 方式1:limit n :從0開始,篩選n條
- 方式2:limit s,n 從s開始,篩選n條
- 方式3:limit n offset s:從s開始,篩選n條
SELECT id, name, shuxue, yingyu, yuwen FROM exam_result ORDER BY id LIMIT 3 OFFSET 0;
- 更新表數據 update
更改一行數據時候,一定要加上約束條件,否則叫全表更新了update 表名稱 set 欄位名稱=更改後的值 where 約束條件
UPDATE exam_result SET shuxue = 80 WHERE name = '孫悟空'; - 刪除表當中數據
如果不加上約束條件,表示刪除整張表當中的數據;如果又自增長的屬性不會進行情況,不會對錶結構造成影響。DELETE FROM exam_result WHERE name = '孫悟空'; - 截斷表
truncate table 表名稱
不能針對某一行數據進行操作,而是針對整個表的數據進行操作的。 - 聚合函數
- count函數 :查詢表當中數據的個數
SELECT COUNT(*) FROM students; - sum函數:查詢數據的綜合
SELECT SUM(shuxue) FROM exam_result; - avg函數:計算數據平均值
SELECT AVG(yuwen + shuxue + yingyu) 平均總分 FROM exam_result; - max函數:計算最大值
SELECT MAX(yingyu) FROM exam_result; - min函數:計算最小值
SELECT MIN(shuxue) FROM exam_result WHERE shuxue > 70;
- 分組查詢
group by 子句
是將我們所需要查詢的結果先進行分組,之後再進行計算
查詢每個部門的平均工資和最高工資:select deptno, avg(asl),max(sal) from emp group by deptno
查詢每個部門的不同崗位的平均工資和最低工資:select deptno , job,avg(sal),min(sal) from emp group by deptno ,job先按照部門進行分,之後再按照崗位來進行劃分
顯示平均工資低於2000的部門和它的平均工資:select deptno ,avg(sal), from emp group by debtno having agv(sal)<2000;
一般情況下group by和having 配套使用,進行過濾使用。
6. 內建函數
- 日期函數
- 獲取當前日期:
select current_date(); - 獲取當前時間:
select current_time(); - 獲取當前時間戳:
select current_timestamp(); - 返回datetime當中的日期部分
date(datetime) - 對日期進行減操作,單位可以爲year,month,day
select date_sub('2017-10-1', interval 2 day); - 對日期進行加操作,單位可以爲year,month,day
select date_add('2017-10-28', interval 10 day); - 計算兩個時間的差值,單位是天:
select datediff('2017-10-10', '2016-9-1');計算方式是date1-date2 - 返回當前的日期時間:
now()
- 字串函數
- 獲取str字元集
select charset(ename) from EMP; - 將字串連線起來
select concat(name, '的語文是',chinese,'分,數學是',math,'分') as '分數' from student; - 返回substing在string當中的位置,沒有則返回0
instr(string ,substring) - 將str轉換成大寫
ucase(str) - 將str轉換成小寫
lcase(str) - 從str當中的左邊開始取len個字元
left(str,len) - 計算str的長度,並非是位元組數量
select length(name), name from student; - 替換
select replace(ename, 'S', '上海') ,ename from EMP; - 比較字串
strcmp(str1,str2); - 從str的pos位置開始取len個字元
select substring(ename, 2, 2), ename from EMP;
- 數學函數
- 絕對值函數
select abs(-100.2); - 向上取整
select ceiling(23.04); - 向下取整
select floor(23.7); - 獲取亂數
select rand(); - 精確,超過的部分會自動四捨五入
select format(12.3456, 2);
- 其他函數
- 獲取當前使用者
select user(); - 獲取當前正在使用的數據庫
select database(); - 計算MD5(一般在工作時候檢驗是否相同的話是比較md5)
select md5('admin') - 查詢使用者密碼
select password('root');
7. 複合查詢與內外連線
- 多表查詢:往往數據來自不同的表,所以需要多表查詢


- 顯示部門號爲10的部門名, 員工名和工資
select ename, sal,dname from EMP, DEPT where EMP.deptno=DEPT.deptno and DEPT.deptno = 10; - 顯示各個員工的姓名,工資及工資級別
select ename, sal, grade from EMP, SALGRADE where EMP.sal between losal and hisal;
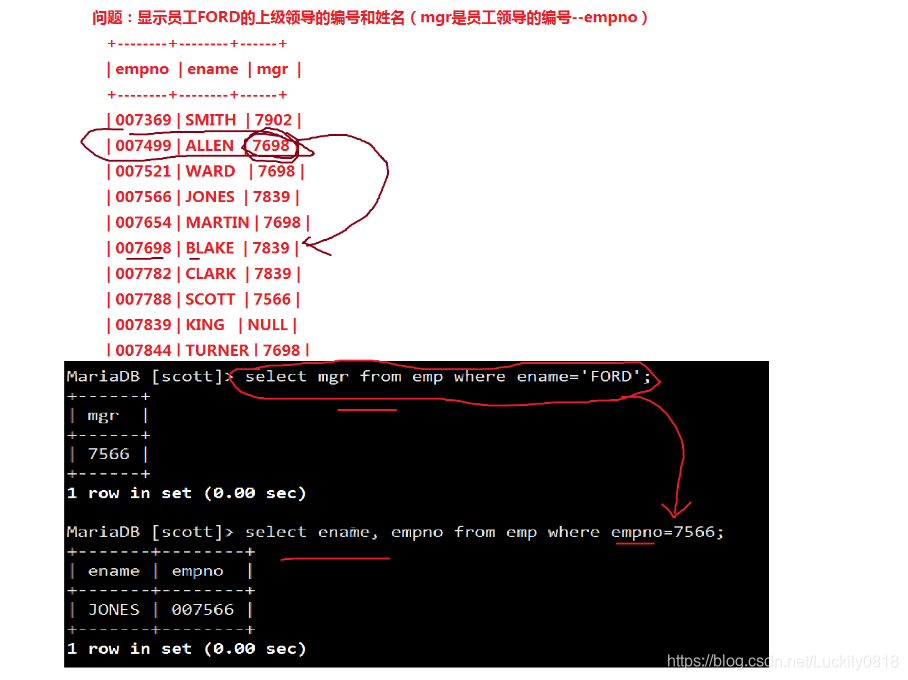
- 自連線:指的是在同一張表當中查詢
- 子查詢:第二個select語句寫到where的子句當中,也就是巢狀查詢
- 單行子查詢:子查詢當中返回了單列,單行的數據
- 多行子查詢:子查詢當中返回了單列,多行數據,兩個表的結果如果不在where後面加約束條件,會形成笛卡爾積
- 多列子查詢:子查詢當中但會多列數據 只需要在where語句後面使用「(a,b)=(子查詢語句)」將多個列的名稱括起來
例子:查詢和SMITH的部門和崗位完全相同的所有僱員,不含SMITH本人
mysql> select ename from EMP where (deptno, job)=(select deptno, job from EMP where ename='SMITH') and ename <> 'SMITH';

- 在from語句當中使用子查詢,是將其中一個表當作一個臨時表
查詢每個部門工資最高的人的姓名,工資,部門,最高工資select EMP.ename, EMP.sal, EMP.deptno, ms from EMP,(select max(sal) ms, deptno from EMP group by deptno) tmp where EMP.deptno=tmp.deptno and EMP.sal=tmp.ms; - 合併查詢
- union:作用是將兩個查詢結果集合進行合併,會自動去除結果當中重複的行
- union all:作用是將兩個查詢的結果進行合併,不會自動去除結果當中重複的行,相當於將結果1和結果2直接拼接

- 外連線:連線是指要在多個表當中去查詢
只需要關心sql語句當中select查詢的位置來決定左右的
- 左外連線:左側的表完全顯示
from 表1 left join 表2 on 約束條件完全顯示錶1 - 右外連線:右側的表完全顯示
from 表1 right join 表2 on 約束條件完全顯示錶2
8. 索引特性
- 常見的索引:
- 主鍵索引:在一個表當中設定了主鍵,就會建立一個主鍵索引
主鍵索引遵循主鍵的特性,不重複,不能爲NULL,按照主鍵的值構建一顆二元樹,準確的說是b+樹 - 唯一索引:在一個表當中設定了唯一鍵,就會建立一個唯一索引
- 普通索引
- 全文索引:前替是儲存引擎需要MyISAM ,INNODE儲存引擎支援事務,而MyISAM不支援
- 建立了一個二元樹的結構,將設定成爲索引的欄位的內短通過二元樹維護起來
也就是說如果一張表當中建立了索引,也就是建立了一個二元樹結構
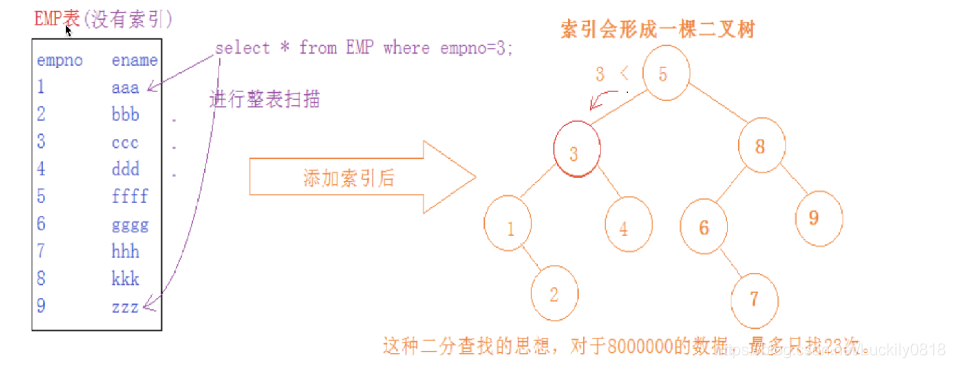
- 增刪改查的效率是否有影響
- 增:有影響,因序更新二元樹
- 刪:有影響,因序更新二元樹
- 改:有影響,因序更新二元樹
- 查:查詢時如果使用索引欄位值,效率會大大增加
- 索引檢視和刪除
檢視索引:show keys from 表名稱
刪除索引:alter table 表名稱 drop primary key;或者alter table 表名稱 drp index 索引名稱
9. 事務管理
相當於多執行緒當中的執行緒互斥問題
- 保證多個用戶端存取數據庫的同一張表的時候不會產生數據二義性的問題;
- 事務的基本操作:
- 開始事務:
start transaction; - 建立一個儲存點:
savepoint 儲存點名稱 - 回滾:
rollback to 儲存點名稱 - 提交事故:
commit

當提交事務完成後,不能再回到之前的儲存點了。
INNODE儲存引擎支援事務,而MyISAM不支援
- 事務的隔離級別
無隔離級別:
- 髒讀:讀到數據並不是有效的數據
- 不可重複讀:前後兩次讀到的結果是不一致的
- 幻讀:前後讀到的數據條目都是不一致的
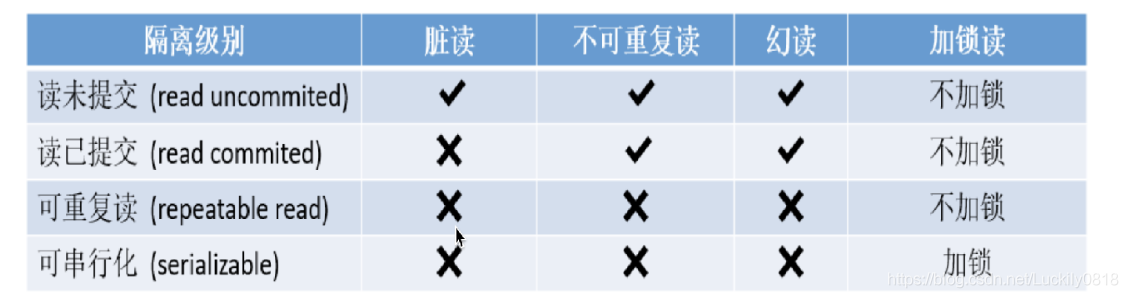
設定隔離級別:set session transaction islation level 事務的隔離級別
10. 檢視特性
- 檢視就是一個虛擬的表,虛擬表當中的數據來源於真實的表;
- 檢視也可以當作是一個表來進行操作;
- 修改檢視當中的內容也會同步修改真實表中的數據,當然修改真實表也會更新檢視當中的內容。
- 建立一個檢視:
create view 檢視名稱 as select 語句檢視數目是沒有限制的 - 刪除一個檢視:
drop view 檢視名稱
11. 使用者管理
MySQL的使用者管理相當於linux操作系統的多使用者管理 因爲不想給數據庫操作人員,所有數據庫的許可權,所以需要分使用者,可以設定使用者只能夠看到某一個具體的數據庫!

- 建立使用者 :
create user '使用者名稱'@‘允許從哪裏鏈接上來’ identidied by 密碼; - 刪除使用者:
drop user '使用者名稱'@'允許從哪裏連線上來'; - 修改使用者密碼
- root使用者可以修改其他使用者:
set password for '使用者名稱'@'允許從哪裏連線上來=password(’新密碼‘); - 其他使用者可以修改自己的密碼:
set password=password('新密碼');
- 如何給使用者建立許可權
- 剛剛建立出來的使用者是沒有任何許可權的
- 語法:
grant 許可權列表 on 庫.物件名 to '使用者名稱'@'登陸位置' [identified by '密碼'] - 許可權列表:多個許可權用
,隔開 *.*代表本系 本係統中所有數據庫的所有物件庫.*表示某個數據庫中的所有數據物件
- 如果刪除一個使用者的許可權
revoke 許可權列表 on 庫.物件名 from '使用者名稱'@'登陸位置';
對於這些基本的操作和相關概念,我們能夠做到瞭解甚至熟練的話,那麼對於我們秋招來說無疑是一次很大的提升,也可以讓我們的簡歷更加的豐富,一起加油吧!(給個讚唄)