大數據元件圖譜---比較齊全
大數據元件圖譜
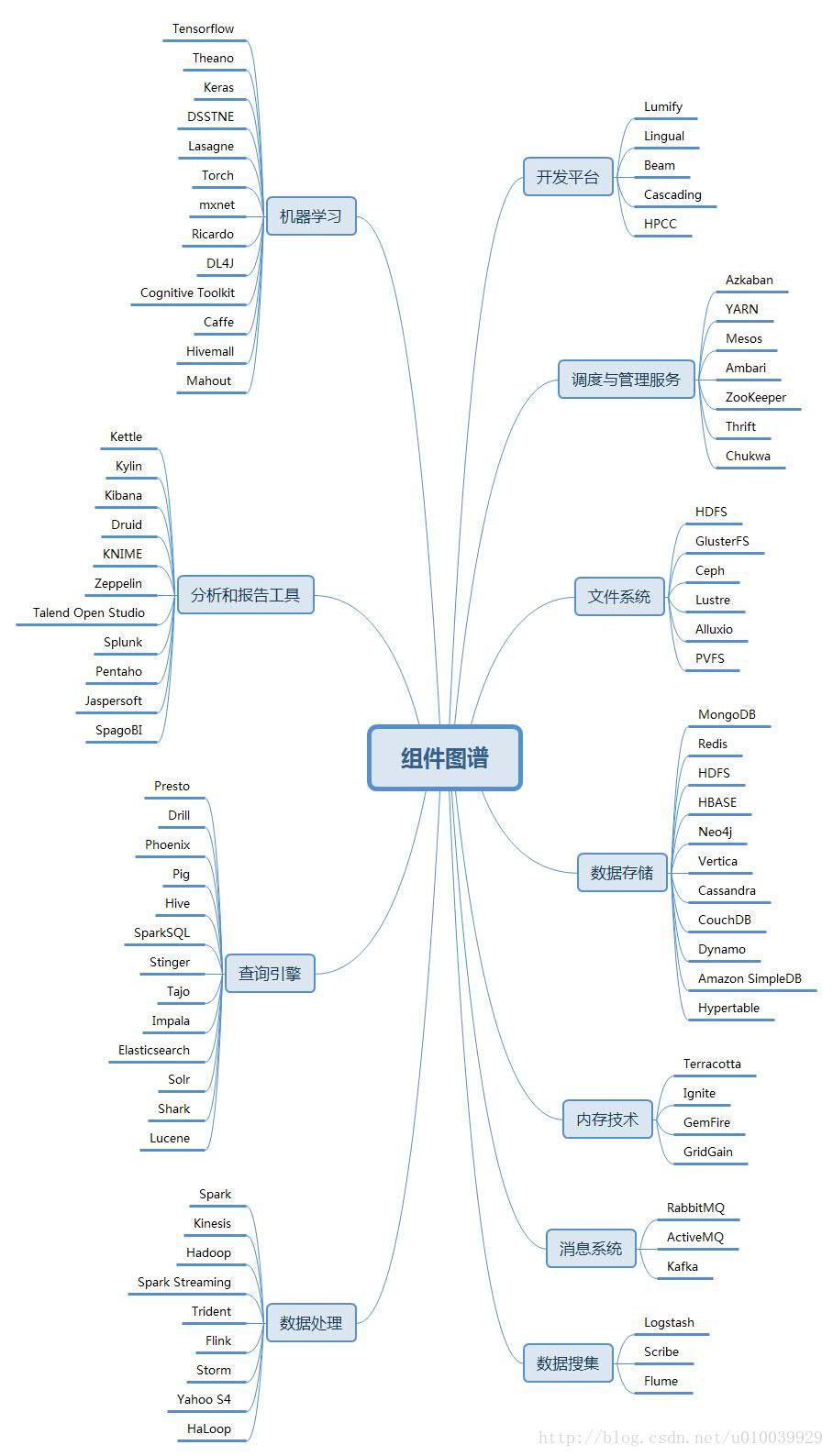
檔案系統
HDFS Hadoop Distributed File System,簡稱HDFS,是一個分佈式檔案系統。HDFS是一個高度容錯性的系統,適合部署在廉價的機器上。HDFS能提供高吞吐量的數據存取,非常適合大規模數據集上的應用。
GlusterFS 是一個叢集的檔案系統,支援PB級的數據量。GlusterFS 通過RDMA和TCP/IP方式將分佈到不同伺服器上的儲存空間彙整合一個大的網路化並行檔案系統。
Ceph 是新一代開源分佈式檔案系統,主要目標是設計成基於POSIX的沒有單點故障的分佈式檔案系統,提高數據的容錯性並實現無縫的複製。
Lustre 是一個大規模的、安全可靠的、具備高可用性的叢集檔案系統,它是由SUN公司開發和維護的。該專案主要的目的就是開發下一代的叢集檔案系統,目前可以支援超過10000個節點,數以PB的數據儲存量。
Alluxio 前身是Tachyon,是以記憶體爲中心的分佈式檔案系統,擁有高效能和容錯能力,能夠爲叢集框架(如Spark、MapReduce)提供可靠的記憶體級速度的檔案共用服務。
PVFS 是一個高效能、開源的並行檔案系統,主要用於並行計算環境中的應用。PVFS特別爲超大數量的用戶端和伺服器端所設計,它的模組化設計結構可輕鬆的新增新的硬體和演算法支援。
數據儲存
MongoDB 是一個基於分佈式檔案儲存的數據庫。由C++語言編寫。旨在爲web應用提供可延伸的高效能數據儲存解決方案。介於關係數據庫和非關係數據庫之間的開源產品,是非關係數據庫當中功能最豐富、最像關係數據庫的產品。
Redis 是一個高效能的key-value儲存系統,和Memcached類似,它支援儲存的value型別相對更多,包括string(字串)、list(鏈表)、set(集合)和zset(有序集合)。Redis的出現,很大程度補償了memcached這類key/value儲存的不足,在部分場合可以對關係數據庫起到很好的補充作用。
HDFS Hadoop分佈式檔案系統(HDFS)被設計成適合執行在通用硬體(commodity hardware)上的分佈式檔案系統。它和現有的分佈式檔案系統有很多共同點。HDFS是一個高度容錯性的系統,適合部署在廉價的機器上。HDFS能提供高吞吐量的數據存取,非常適合大規模數據集上的應用。
HBASE 是Hadoop的數據庫,一個分佈式、可延伸、大數據的儲存。是爲有數十億行和數百萬列的超大表設計的,是一種分佈式數據庫,可以對大數據進行隨機性的實時讀取/寫入存取。提供類似谷歌Bigtable的儲存能力,基於Hadoop和Hadoop分佈式檔案系統(HDFS)而建。
Neo4j 是一個高效能的,NOSQL圖形數據庫,它將結構化數據儲存在網路上而不是表中。自稱「世界上第一個和最好的圖形數據庫」,「速度最快、擴充套件性最佳的原生圖形數據庫」,「最大和最有活力的社羣」。使用者包括Telenor、Wazoku、ebay、必能寶(Pitney Bowes)、MigRaven、思樂(Schleich)和Glowbl等。
Vertica 基於列儲存高效能和高可用性設計的數據庫方案,由於對大規模並行處理(MPP)技術的支援,提供細粒度、可伸縮性和可用性的優勢。每個節點完全獨立運作,完全無共用架構,降低了共用資源的系統競爭。
Cassandra 是一個混合型的非關係的數據庫,類似於Google的BigTable,其主要功能比Dynamo (分佈式的Key-Value儲存系統)更豐富。這種NoSQL數據庫最初由Facebook開發,現已被1500多家企業組織使用,包括蘋果、歐洲原子核研究組織(CERN)、康卡斯特、電子港灣、GitHub、GoDaddy、Hulu、Instagram、Intuit、Netfilx、Reddit及其他機構。
CouchDB 號稱是「一款完全擁抱網際網路的數據庫」,它將數據儲存在JSON文件中,這種文件可以通過Web瀏覽器來查詢,並且用JavaScript來處理。它易於使用,在分佈式上網路上具有高可用性和高擴充套件性。
Dynamo 是一個經典的分佈式Key-Value 儲存系統,具備去中心化、高可用性、高擴充套件性的特點。Dynamo在Amazon中得到了成功的應用,能夠跨數據中心部署於上萬個結點上提供服務,它的設計思想也被後續的許多分佈式系統借鑑。
Amazon SimpleDB 是一個用Erlang編寫的高可用的NoSQL數據儲存,能夠減輕數據庫管理工作,開發人員只需通過Web服務請求執行數據項的儲存和查詢,Amazon SimpleDB 將負責餘下的工作。作爲一項Web 服務,像Amazon的EC2和S3一樣,是Amazon網路服務的一部分。
Hypertable 是一個開源、高效能、可伸縮的數據庫,它採用與Google的Bigtable相似的模型。它與Hadoop相容,效能超高,其使用者包括電子港灣、百度、高朋、Yelp及另外許多網際網路公司。
記憶體技術
Terracotta 聲稱其BigMemory技術是「世界上首屈一指的記憶體中數據管理平臺」,支援簡單、可延伸、實時訊息,聲稱在190個國家擁有210萬開發人員,全球1000家企業部署了其軟體。
Ignite 是一種高效能、整合式、分佈式的記憶體中平臺,可用於對大規模數據集執行實時計算和處理,速度比傳統的基於磁碟的技術或快閃記憶體技術高出好幾個數量級。該平臺包括數據網格、計算網格、服務網格、串流媒體、Hadoop加速、高階叢集、檔案系統、訊息傳遞、事件和數據結構等功能。
GemFire Pivotal宣佈它將開放其大數據套件關鍵元件的原始碼,其中包括GemFire記憶體中NoSQL數據庫。它已向Apache軟體基金會遞交了一項提案,以便在「Geode」的名下管理GemFire數據庫的核心引擎。
GridGain 由Apache Ignite驅動的GridGrain提供記憶體中數據結構,用於迅速處理大數據,還提供基於同一技術的Hadoop加速器。
數據蒐集 搜集
Logstash 是一個應用程式日誌、事件的傳輸、處理、管理和搜尋的平臺。可以用它來統一對應用程式日誌進行收集管理,提供了Web介面用於查詢和統計。
Scribe Scribe是Facebook開源的日誌收集系統,它能夠從各種日誌源上收集日誌,儲存到一箇中央儲存系統(可以是NFS,分佈式檔案系統等)上,以便於進行集中統計分析處理。
Flume 是Cloudera提供的一個高可用的、高可靠的、分佈式的海量日誌採集、聚合和傳輸的系統。Flume支援在日誌系統中定製各類數據發送方,用於收集數據。同時,Flume支援對數據進行簡單處理,並寫入各種數據接受方(可定製)。
訊息系統
RabbitMQ 是一個受歡迎的訊息代理系統,通常用於應用程式之間或者程式的不同組件之間通過訊息來進行整合。RabbitMQ提供可靠的應用訊息發送、易於使用、支援所有主流操作系統、支援大量開發者平臺。
ActiveMQ 是Apache出品,號稱「最流行的,最強大」的開源訊息整合模式伺服器。ActiveMQ特點是速度快,支援多種跨語言的用戶端和協定,其企業整合模式和許多先進的功能易於使用,是一個完全支援JMS1.1和J2EE 1.4規範的JMS Provider實現。
Kafka 是一種高吞吐量的分佈式發佈訂閱訊息系統,它可以處理消費者規模網站中的所有動作流數據,目前已成爲大數據系統在非同步和分佈式訊息之間的最佳選擇。
數據處理
Spark 是一個高速、通用大數據計算處理引擎。擁有Hadoop MapReduce所具有的優點,但不同的是Job的中間輸出結果可以儲存在記憶體中,從而不再需要讀寫HDFS,因此Spark能更好地適用於數據挖掘與機器學習等需要迭代的MapReduce的演算法。它可以與Hadoop和Apache Mesos一起使用,也可以獨立使用
Kinesis 可以構建用於處理或分析流數據的自定義應用程式,來滿足特定需求。Amazon Kinesis Streams 每小時可從數十萬種來源中連續捕獲和儲存數TB數據,如網站點選流、財務交易、社交媒體源、IT日誌和定位追蹤事件。
Hadoop 是一個開源框架,適合執行在通用硬體,支援用簡單程式模型分佈式處理跨叢集大數據集,支援從單一伺服器到上千伺服器的水平scale up。Apache的Hadoop專案已幾乎與大數據劃上了等號,它不斷壯大起來,已成爲一個完整的生態系統,擁有衆多開源工具面向高度擴充套件的分佈式計算。高效、可靠、可伸縮,能夠爲你的數據儲存專案提供所需的YARN、HDFS和基礎架構,並且執行主要的大數據服務和應用程式。
Spark Streaming 實現微批次處理,目標是很方便的建立可延伸、容錯的流應用,支援Java、Scala和Python,和Spark無縫整合。Spark Streaming可以讀取數據HDFS,Flume,Kafka,Twitter和ZeroMQ,也可以讀取自定義數據。
Trident 是對Storm的更高一層的抽象,除了提供一套簡單易用的流數據處理API之外,它以batch(一組tuples)爲單位進行處理,這樣一來,可以使得一些處理更簡單和高效。
Flink 於今年躋身Apache頂級開源專案,與HDFS完全相容。Flink提供了基於Java和Scala的API,是一個高效、分佈式的通用大數據分析引擎。更主要的是,Flink支援增量迭代計算,使得系統可以快速地處理數據密集型、迭代的任務。
Samza 出自於LinkedIn,構建在Kafka之上的分佈式流計算框架,是Apache頂級開源專案。可直接利用Kafka和Hadoop YARN提供容錯、進程隔離以及安全、資源管理。
Storm Storm是Twitter開源的一個類似於Hadoop的實時數據處理框架。程式設計模型簡單,顯著地降低了實時處理的難度,也是當下最人氣的流計算框架之一。與其他計算框架相比,Storm最大的優點是毫秒級低延時。
Yahoo S4 (Simple Scalable Streaming System)是一個分佈式流計算平臺,具備通用、分佈式、可延伸的、容錯、可插拔等特點,程式設計師可以很容易地開發處理連續無邊界數據流(continuous unbounded streams of data)的應用。它的目標是填補複雜專有系統和麪向批次處理開源產品之間的空白,並提供高效能運算平臺來解決併發處理系統的複雜度。
HaLoop 是一個Hadoop MapReduce框架的修改版本,其目標是爲了高效支援 迭代,遞回數據 分析任務,如PageRank,HITs,K-means,sssp等。
查詢引擎
Presto 是一個開源的分佈式SQL查詢引擎,適用於互動式分析查詢,可對250PB以上的數據進行快速地互動式分析。Presto的設計和編寫是爲了解決像Facebook這樣規模的商業數據倉庫的互動式分析和處理速度的問題。Facebook稱Presto的效能比諸如Hive和MapReduce要好上10倍有多。
Drill 於2012年8月份由Apache推出,讓使用者可以使用基於SQL的查詢,查詢Hadoop、NoSQL數據庫和雲端儲存服務。它能夠執行在上千個節點的伺服器叢集上,且能在幾秒內處理PB級或者萬億條的數據記錄。它可用於數據挖掘和即席查詢,支援一系列廣泛的數據庫,包括HBase、MongoDB、MapR-DB、HDFS、MapR-FS、亞馬遜S3、Azure Blob Storage、谷歌雲端儲存和Swift。
Phoenix 是一個Java中間層,可以讓開發者在Apache HBase上執行SQL查詢。Phoenix完全使用Java編寫,並且提供了一個用戶端可嵌入的JDBC驅動。Phoenix查詢引擎會將SQL查詢轉換爲一個或多個HBase scan,並編排執行以生成標準的JDBC結果集。
Pig 是一種程式語言,它簡化了Hadoop常見的工作任務。Pig可載入數據、轉換數據以及儲存最終結果。Pig最大的作用就是爲MapReduce框架實現了一套shell指令碼 ,類似我們通常熟悉的SQL語句。
Hive 是基於Hadoop的一個數據倉庫工具,可以將結構化的數據檔案對映爲一張數據庫表,並提供簡單的sql查詢功能,可以將sql語句轉換爲MapReduce任務進行執行。 其優點是學習成本低,可以通過類SQL語句快速實現簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合數據倉庫的統計分析。
SparkSQL 的前身是Shark,SparkSQL拋棄原有Shark的程式碼並汲取了一些優點,如記憶體列儲存(In-Memory Columnar Storage)、Hive相容性等。由於擺脫了對Hive的依賴性,SparkSQL無論在數據相容、效能優化、元件擴充套件方面都得到了極大的方便。
Stinger 原來叫Tez,是下一代Hive,由Hortonworks主導開發,執行在YARN上的DAG計算框架。某些測試下,Stinger能提升10倍左右的效能,同時會讓Hive支援更多的SQL。
Tajo 目的是在HDFS之上構建一個可靠的、支援關係型數據的分佈式數據倉庫系統,它的重點是提供低延遲、可延伸的ad-hoc查詢和線上數據聚集,以及爲更傳統的ETL提供工具。
Impala Cloudera聲稱,基於SQL的Impala數據庫是「面向Apache Hadoop的領先的開源分析數據庫」。它可以作爲一款獨立產品來下載,又是Cloudera的商業大數據產品的一部分。Cloudera Impala 可以直接爲儲存在HDFS或HBase中的Hadoop數據提供快速、互動式的SQL查詢。
Elasticsearch 是一個基於Lucene的搜尋伺服器。它提供了一個分佈式、支援多使用者的全文搜尋引擎,基於RESTful web介面。Elasticsearch是用Java開發的,並作爲Apache許可條款下的開放原始碼發佈,是當前流行的企業級搜尋引擎。設計用於雲端計算中,能夠達到實時搜尋、穩定、可靠、快速、安裝使用方便。
Solr 基於Apache Lucene,是一種高度可靠、高度擴充套件的企業搜尋平臺。知名使用者包括eHarmony、西爾斯、StubHub、Zappos、百思買、AT&T、Instagram、Netflix、彭博社和Travelocity。
Shark 即Hive on Spark,本質上是通過Hive的HQL解析,把HQL翻譯成Spark上的RDD操作,然後通過Hive的metadata獲取數據庫裡的表資訊,實際HDFS上的數據和檔案,會由Shark獲取並放到Spark上運算。Shark的特點就是快,完全相容Hive,且可以在shell模式下使用rdd2sql()這樣的API,把HQL得到的結果集,繼續在scala環境下運算,支援自己編寫簡單的機器學習或簡單分析處理常式,對HQL結果進一步分析計算。
Lucene 基於Java的Lucene可以非常迅速地執行全文搜尋。據官方網站聲稱,它在現代硬體上每小時能夠檢索超過150GB的數據,它擁有強大而高效的搜尋演算法。
分析和報告工具
Kettle 這是一個ETL工具集,它允許你管理來自不同數據庫的數據,通過提供一個圖形化的使用者環境來描述你想做什麼,而不是你想怎麼做。作爲Pentaho的一個重要組成部分,現在在國內專案應用上逐漸增多。
Kylin 是一個開源的分佈式分析引擎,提供了基於Hadoop的超大型數據集(TB/PB級別)的SQL介面以及多維度的OLAP分佈式聯機分析。最初由eBay開發並貢獻至開源社羣。它能在亞秒內查詢巨大的Hive表。
Kibana 是一個使用Apache 開源協定的Elasticsearch 分析和搜尋儀表 儀錶板,可作爲Logstash和ElasticSearch日誌分析的 Web 介面,對日誌進行高效的搜尋、視覺化、分析等各種操作。
Druid 是一個用於大數據實時查詢和分析的高容錯、高效能、分佈式的開源系統,旨在快速處理大規模的數據,並能夠實現快速查詢和分析。
KNIME 的全稱是「康斯坦茨資訊挖掘工具」(Konstanz Information Miner),是一個開源分析和報表平臺。宣稱「是任何數據科學家完美的工具箱,超過1000個模組,可執行數百個範例,全面的整合工具,以及先進的演算法」。
Zeppelin 是一個提供互動數據分析且基於Web的筆電。方便你做出可數據驅動的、可互動且可共同作業的精美文件,並且支援多種語言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等。
Talend Open Studio 是第一家針對的數據整合工具市場的ETL(數據的提取Extract、傳輸Transform、載入Load)開源軟體供應商。Talend的下載量已超過200萬人次,其開源軟體提供了數據整合功能。其使用者包括美國國際集團(AIG)、康卡斯特、電子港灣、通用電氣、三星、Ticketmaster和韋裡遜等企業組織。
Splunk 是機器數據的引擎。使用 Splunk 可收集、索引和利用所有應用程式、伺服器和裝置(物理、虛擬和雲中)生成的快速移動型計算機數據,從一個位置搜尋並分析所有實時和歷史數據。
Pentaho 是世界上最流行的開源商務智慧軟體,以工作流爲核心的、強調面向解決方案而非工具元件的、基於java平臺的商業智慧(Business Intelligence)套件。包括一個web server平臺和幾個工具軟體:報表、分析、圖表、數據整合、數據挖掘等,可以說包括了商務智慧的方方面面。
Jaspersoft 提供了靈活、可嵌入的商業智慧工具,使用者包括衆多企業組織:高朋、冠羣科技、美國農業部、愛立信、時代華納有線電視、奧林匹克鋼鐵、內斯拉斯加大學和通用動力公司。
SpagoBI Spago被市場分析師們稱爲「開源領袖」,它提供商業智慧、中介軟體和品質保證軟體,另外還提供相應的Java EE應用程式開發框架。
排程與管理服務
Azkaban 是一款基於Java編寫的任務排程系統任務排程,來自LinkedIn公司,用於管理他們的Hadoop批次處理工作流。Azkaban根據工作的依賴性進行排序,提供友好的Web用戶介面來維護和跟蹤使用者的工作流程。
YARN 是一種新的Hadoop資源管理器,它是一個通用資源管理系統,可爲上層應用提供統一的資源管理和排程,解決了舊MapReduce框架的效能瓶頸。它的基本思想是把資源管理和作業排程/監控的功能分割到單獨的守護行程。
Mesos 是由加州大學伯克利分校的AMPLab首先開發的一款開源羣集管理軟體,支援Hadoop、ElasticSearch、Spark、Storm 和Kafka等架構。對數據中心而言它就像一個單一的資源池,從物理或虛擬機器器中抽離了CPU,記憶體,儲存以及其它計算資源, 很容易建立和有效執行具備容錯性和彈性的分佈式系統。
Ambari 作爲Hadoop生態系統的一部分,提供了基於Web的直觀介面,可用於設定、管理和監控Hadoop叢集。目前已支援大多數Hadoop元件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog等。
ZooKeeper 是一個分佈式的應用程式協調服務,是Hadoop和Hbase的重要元件。它是一個爲分佈式應用提供一致性服務的工具,讓Hadoop叢集裏面的節點可以彼此協調。ZooKeeper現在已經成爲了 Apache的頂級專案,爲分佈式系統提供了高效可靠且易於使用的協同服務。
Thrift 在2007年facebook提交Apache基金會將Thrift作爲一個開源專案,對於當時的facebook來說創造thrift是爲了解決facebook系統中各系統間大數據量的傳輸通訊以及系統之間語言環境不同需要跨平臺的特性。
Chukwa 是監測大型分佈式系統的一個開源數據採集系統,建立在HDFS/MapReduce框架之上並繼承了Hadoop的可伸縮性和可靠性,可以收集來自大型分佈式系統的數據,用於監控。它還包括靈活而強大的顯示工具用於監控、分析結果。
機器學習
Tensorflow是Google開源的一款深度學習工具,使用C++語言開發,上層提供Python API。在開源之後,在工業界和學術界引起了極大的震動,因爲TensorFlow曾經是著名的Google Brain計劃中的一部分,Google Brain專案的成功曾經吸引了衆多科學家和研究人員往深度學習這個「坑」裏面跳,這也是當今深度學習如此繁榮的重要原因。
Theano是老牌、穩定的庫之一。它是深度學習開源工具的鼻祖,由蒙特利爾理工學院時間開發於2008年並將其開源,框架使用Python語言開發。它是深度學習庫的發軔,許多在學術界和工業界有影響力的深度學習框架都構建在Theano之上,並逐步形成了自身的生態系統,這其中就包含了著名的Keras、Lasagne和Blocks。Theano是底層庫,遵循Tensorflow風格。因此不適合深度學習,而更合適數值計算優化。它支援自動函數梯度計算,它有 Python介面 ,整合了Numpy,使得這個庫從一開始就成爲通用深度學習最常用的庫之一。
Keras是一個非常高層的庫,工作在Theano或Tensorflow(可設定)之上。此外,Keras強調極簡主義,你可以用寥寥可數的幾行程式碼來構建神經網路。在 這裏 ,您可以看到一個Keras程式碼範例,與在Tensorflow中實現相同功能所需的程式碼相比較。
DSSTNE(Deep Scalable Sparse Tensor Network Engine,DSSTNE)是Amazon開源的一個非常酷的框架,由C++語言實現。但它經常被忽視。爲什麼?因爲,撇開其他因素不談,它並不是爲一般用途設計的。DSSTNE只做一件事,但它做得很好:推薦系統。正如它的官網所言,它不是作爲研究用途,也不是用於測試想法,而是爲了用於生產的框架。
Lasagne是一個工作在Theano之上的庫。它的任務是將深度學習演算法的複雜計算予以簡單地抽象化,並提供一個更友好的 Python 介面。這是一個老牌的庫,長久以來,它是一個具備高擴充套件性的工具。在Ricardo看來,它的發展速度跟不上Keras。它們適用的領域相同,但是,Keras有更好的、更完善的文件。
Torch是Facebook和Twitter主推的一個特別知名的深度學習框架,Facebook Reseach和DeepMind所使用的框架,正是Torch(DeepMind被Google收購之後才轉向TensorFlow)。出於效能的考慮, 它使用了一種比較小衆的程式語言Lua ,目前在音訊、影象及視訊處理方面有着大量的應用。在目前深度學習大部分以Python爲程式語言的大環境之下,一個以Lua爲程式語言的框架只有更多的劣勢,而不是優勢。Ricardo沒有Lua的使用經驗,他表示,如果他要用Torch的話,就必須先學習Lua語言才能 纔能使用Torch。就他個人來說,更傾向於熟悉的Python、Matlab或者C++來實現。
mxnet是支援大多數程式語言的庫之一,它支援Python、R、C++、Julia等程式語言。Ricardo覺得使用R語言的人們會特別喜歡mxnet,因爲直到現在,在深度學習的程式語言領域中,Python是衛冕之王。
Ricardo以前並沒有過多關注mxnet,直到Amazon AWS宣佈將mxnet作爲其 深度學習AMI 中的 參考庫 時,提到了它巨大的水平擴充套件能力,他纔開始關注。
Ricardo表示他對多GPU的擴充套件能力有點懷疑,但仍然很願意去瞭解實驗更多的細節。但目前還是對mxnet的能力抱有懷疑的態度。
DL4J,全名是Deep Learning for Java。正如其名,它支援Java。Ricardo說,他之所以能接觸到這個庫,是因爲它的文件。當時,他在尋找 限制波爾茲曼機(Restricted Boltzman Machines) 、 自編碼器(Autoencoders) ,在DL4J找到這兩個文件,文件寫得很清楚,有理論,也有程式碼範例。Ricardo表示D4LJ的文件真的是一個藝術品,其他庫的文件應該向它學習。
DL4J背後的公司Skymind意識到,雖然在深度學習世界中,Python是王,但大部分程式設計師都是Java起步的,因此,DL4J相容JVM,也適用於Java、Clojure和Scala。 隨着Scala的潮起潮落,它也被很多 有前途的初創公司 使用。
Cognitive Toolkit,就是之前被大家所熟知的縮略名CNTK,但最近剛更改爲現在這個名字,可能利用Microsoft認知服務(Microsoft Cognitive services)的影響力。在發佈的基準測試中,它似乎是非常強大的工具,支援垂直和水平推移。
到目前爲止,認知工具包似乎不太流行。關於這個庫,還沒有看到有很多相關的部落格、網路範例,或者在Kaggle裡的相關評論。Ricardo表示這看起來有點奇怪,因爲這是一個背靠微軟研究的框架,特別強調自己的推移能力。而且這個研究團隊在語音識別上打破了世界紀錄並逼近了人類水平。
你可以在他們的專案Wiki中的範例,瞭解到認知工具包在Python的語法和Keras非常相似。
Caffe是最老的框架之一,比老牌還要老牌。 Caffe 是加州大學伯克利分校視覺與學習中心(Berkeley Vision and Learning Center ,BVLC)貢獻出來的一套深度學習工具,使用C/C++開發,上層提供Python API。Caffe同樣也在走分佈式路線,例如著名的Caffe On Spark專案。
Hivemall 結合了面向Hive的多種機器學習演算法,它包括了很多擴充套件性很好的演算法,可用於數據分類、遞回、推薦、k最近鄰、異常檢測和特徵雜湊等方面的分析應用。
RapidMiner 具有豐富數據挖掘分析和演算法功能,常用於解決各種的商業關鍵問題,解決方案覆蓋了各個領域,包括汽車、銀行、保險、生命科學、製造業、石油和天然氣、零售業及快消行業、通訊業、以及公用事業等各個行業。
Mahout 目的是「爲快速建立可延伸、高效能的機器學習應用程式而打造一個環境」,主要特點是爲可伸縮的演算法提供可延伸環境、面向Scala/Spark/H2O/Flink的新穎演算法、Samsara(類似R的向量數學環境),它還包括了用於在MapReduce上進行數據挖掘的衆多演算法。
開發平臺
Lumify 歸Altamira科技公司(以國家安全技術而聞名)所有,這是一種開源大數據整合、分析和視覺化平臺。
Lingual 是Cascading的高階擴充套件,爲Hadoop提供了一個ANSI SQL介面極大地簡化了應用程式的開發和整合。Lingual實現了連線現有的商業智慧(BI)工具,優化了計算成本,加快了基於Hadoop的應用開發速度。
Beam 基於Java提供了統一的數據進程管道開發,並且能夠很好地支援Spark和Flink。提供很多線上框架,開發者無需學太多框架。
Cascading 是一個基於Hadoop建立的API,用來建立複雜和容錯數據處理工作流。它抽象了叢集拓撲結構和設定,使得不用考慮背後的MapReduce,就能快速開發複雜的分佈式應用。
HPCC 作爲Hadoop之外的一種選擇,是一個利用叢集伺服器進行大數據分析的系統,HPCC在LexisNexis內部使用多年,是一個成熟可靠的系統,包含一系列的工具、一個稱爲ECL的高階程式語言、以及相關的數據倉庫,擴充套件性超強。