(a5asd6e87c4字首隨便打打應該比較少人能搜到)HPC學習(二)
OMP學習
motivation:剛接觸高效能運算,學習方向有點亂,偶然在網上找到一篇部落格: ASC18華農隊長超算競賽完整備戰指南.,決定按照這個思路進行整理學習。本篇部落格主要用於本人學習記錄,如有錯誤,歡迎各位大佬指出。(大佬勿噴…)
這篇繼續按照指南順序,學習openmp程式設計。
學omp推薦b站網課:新竹清華大學並行計算與並行程式設計課程,挑選着看,感覺不需要太多基礎都可以看懂。
introduction
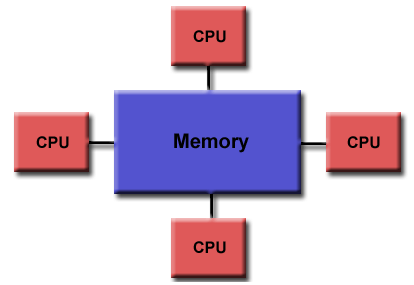
OpenMP = open specification for multi-processing
OpenMP是由一組計算機硬體和軟體供應商聯合定義的應用程式介面(API);
OpenMP爲基於共用記憶體的並行程式的開發人員提供了一種便攜式和可延伸的程式設計模型,其API支援各種架構上的C/C++和Fortran;
 omp的並行模型稱爲fork-join模型
omp的並行模型稱爲fork-join模型
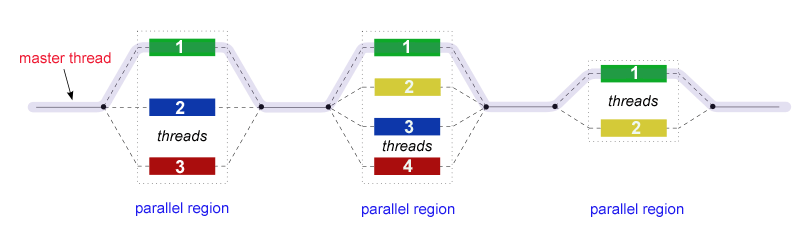 由主執行緒創造出多個執行緒(fork過程),
由主執行緒創造出多個執行緒(fork過程),
並行程式碼執行完後,只剩下一個主執行緒(join過程)
環境設定
- 在Windows下很簡單,vs本身就支援omp,只需要在專案屬性頁上左側選擇「設定屬性」——「C/C++」——「語言」,然後在右側「OpenMP支援」後填入"Yes",然後在檔案中include進<omp.h>即可。
- 在linux下,一般gcc跟icc都.支援openmp,只要在編譯的時候加上參數即可
gcc -fopenmp source.c -o source
OpenMP API
關於OpenMp的API介紹,有一位博主已經寫得很全面了,想要深入學習的話去看看。以下內容參考了下方部落格並根據我自己的需要簡化,會相對簡略。(部落格鏈接:OpenMP學習筆記)
OpenMP API總覽
編譯器指令(44個)
執行時庫函數(35個)
環境變數(13條個)
編譯器指令
編譯器指令在你的原始碼中可能被顯示爲註釋,並且被編譯器所忽略,除非你明顯地告訴編譯器
OpenMP的編譯器指令的目標主要有:
- 產生一個並行區域
- 劃分執行緒中的程式碼塊
- 線上程之間分配回圈迭代
- 序列化程式碼段
- 同步執行緒間的工作
| 指令 | 作用 |
|---|---|
| parallel | 用在一個結構塊之前,表示這段程式碼將被多個執行緒並行執行 |
| for | 用於for回圈語句之前,表示將回圈計算任務分配到多個執行緒中並行執行,以實現任務分擔。注意要保證每次回圈之間無數據相關性。 |
| parallel for | parallel和for指令的結合,也是用在for回圈語句之前,表示for回圈體的程式碼將被多個執行緒並行執行,它同時具有並行域的產生和任務分擔兩個功能 |
| sections | 用在可被並行執行的程式碼段之前,用於實現多個結構塊語句的任務分擔,可並行執行的程式碼段各自用section指令標出(注意區分sections和section) |
| parallel sections | parallel和sections兩個語句的結合,類似於parallel for |
| single | 用在並行域內,表示一段只被單個執行緒執行的程式碼 |
| private | 子句可以將變數宣告爲執行緒私有,每個執行緒都有一個該變數的副本,不會互相影響。原變數在並行部分不起任何作用,也不會受到並行部分內部操作的影響。 |
| firstprivate | 在private的基礎上,用原變數的值初始化執行緒中的副本 |
| lastprivate | 在並行部分結束時,將程式語法上最後一次迭代的值賦回給變數 |
| threadprivate | 只針對全域性變數,使得每個執行緒都有一個私有的全域性物件 |
| shared | shared可以將一個變數宣告爲共用變數,在多個執行緒中共用,但要注意使用安全。 |
| reduction | reduction子句可以對一個或者多個參數指定一個操作符,然後每一個執行緒都會建立這個參數的私有拷貝,在並行區域結束後,迭代執行指定的運算子,並更新原參數的值。eg:reduction(+: sum) |
| copyin | copyin子句可以將主執行緒中變數的值拷貝到各個執行緒的私有變數中,讓各個執行緒可以存取主執行緒中的變數。copyin的參數必須要被宣告稱threadprivate. |
| schedule(method=static, size=1) | 執行緒分配方式,method參數有static(平均分配,執行緒間迭代數最多相差size),dynamic(根據程式執行動態分配),size表示每次分配的迭代樹最少是多少。 |
庫函數
接下來介紹部分常用的庫函數
| 庫函數 | 作用 |
|---|---|
| int omp_get_num_procs(void) | 返回撥用函數時可用的處理器數目 |
| int omp_get_num_threads(void) | 返回當前並行區域中的活動執行緒個數 |
| int omp_get_thread_num(void) | 返回當前執行緒號 |
| int omp_set_num_threads(void) | 設定進入並行區域時,將要建立的執行緒個數 |
| int omp_get_max_threads() | 返回最大執行緒數量,可用上一個函數修改 |
| int omp_in_parallel() | 可以判斷當前是否處於並行狀態,返回0或1 |
| void omp_set_dynamic(int) | 該函數可以設定是否允許在執行時動態調整並行區域的執行緒數。0表示禁用,其他數位表示可用。 |
| int omp_get_dynamic() | 返回當前程式是否允許在執行時動態調整並行區域的執行緒數。 |
互斥鎖
與互斥鎖相關的函數我獨立開一個表格來介紹
| 庫函數 | 作用 |
|---|---|
| void omp_init_lock(omp_lock) | 初始化互斥鎖 |
| void omp_destroy_lock(omp_lock) | 銷燬互斥鎖 |
| void omp_set_lock(omp_lock) | 獲得互斥鎖 |
| void omp_unset_lock(omp_lock) | 釋放互斥鎖 |
| bool omp_test_lock(omp_lock) | 該函數可以看作是omp_set_lock的非阻塞版本。 |
補充一下omp_lock變數。
定義:
omp_lock_t lock;
使用:
omp_init_lock(&lock)
也就是說,omp_lock是一個omp_lock_t型別變數的指針
數據依賴與衝突
關於這方面的內容國內網站上好像比較少也比較散亂,我就按自己的理解說一下(水平有限,不敢保證正確性…)
什麼叫數據依賴(carries dependency)?舉個栗子就能理解:
c = a + b;
e = c + d;
c 數據依賴於 e,因爲它需要 c 的值。
(應該沒理解錯吧…)
數據衝突
在多執行緒程式設計中,當各個執行緒對某一個變數同時進行讀取修改的時候,執行緒讀取的順序就會對結果造成影響,這時候就會發生數據衝突。(個人淺見)
原子操作與鎖
原子操作理解
首先要理解什麼是原子操作。下面 下麪的解釋是從原子操作這篇部落格中擷取的。
原子操作(atomic operation)指的是由多步操作組成的一個操作。如果該操作不能原子地執行,則要麼執行完所有步驟,要麼一步也不執行,不可能只執行所有步驟的一個子集。
現代操作系統中,一般都提供了原子操作來實現一些同步操作,所謂原子操作,也就是一個獨立而不可分割的操作。在單核環境中,一般的意義下原子操作中執行緒不會被切換,執行緒切換要麼在原子操作之前,要麼在原子操作完成之後。更廣泛的意義下原子操作是指一系列必須整體完成的操作步驟,如果任何一步操作沒有完成,那麼所有完成的步驟都必須回滾,這樣就可以保證要麼所有操作步驟都未完成,要麼所有操作步驟都被完成。
例如在單核系統裡,單個的機器指令可以看成是原子操作(如果有編譯器優化、亂序執行等情況除外);在多核系統中,單個的機器指令就不是原子操作,因爲多核系統裡是多指令流並行執行的,一個核在執行一個指令時,其他核同時執行的指令有可能操作同一塊記憶體區域,從而出現數據競爭現象。多核系統中的原子操作通常使用記憶體柵障(memory barrier)來實現,即一個CPU核在執行原子操作時,其他CPU核必須停止對記憶體操作或者不對指定的記憶體進行操作,這樣才能 纔能避免數據競爭問題。
說實話,在閱讀完上述解釋後,我還是有些雲裡霧裏的,我再找了一個簡單的程式,也許能幫助理解。
#include<iostream>
#include<omp.h>
using namespace std;
int main(int argc, char** argv)
{
omp_set_num_threads(6);
int counter = 0, i;
#pragma omp parallel
{
for (i = 0; i < 10; i++)
{
#pragma omp atomic
counter++;
}
}
cout << "counter =" << counter;
return 0;
}
輸出是counter = 60。
事實上,通過原子操作使得併發有了先後順序,也就導致這段程式碼失去了並行的效果。
原子操作與鎖的區別
- 互斥鎖是一種數據結構,用來讓一個執行緒執行程式的關鍵部分,完成互斥的多個操作。
- 原子操作是針對某個值的單個互斥操作。
- 可以把互斥鎖理解爲悲觀鎖,共用資源每次只給一個執行緒使用,其它執行緒阻塞,用完後再把資源轉讓給其它執行緒。
通常來說,原子操作的效率比鎖要高出一些。
OpenMP實操(矩陣乘法)
待補