python-----正則--re模組
一 發送訊息和正則表達式
1 . 正則介紹
Python 中的正則,本質上是嵌入在Python中的一種微小的、高度專業化的程式語言,可通過 re 這個內建模組獲得。
正則表達式模式幾乎和 shell 中的一樣,更接近 grep -P 的效果,因爲 Python 中的 re 模組提供的是類似 Perl 語言中的正則表達式。
正則表達式模式會被編譯成一系列位元組碼,然後由用 C 編寫的匹配引擎執行。
2. 陷阱
友情提示:
正則表達式語言相對較小且受限制,因此並非所有可能的字串處理任務都可以使用正則表達式完成。
還有一些任務 可以 用正則表達式完成,但表達式變得非常複雜。 在這些情況下,你最好編寫 Python 程式碼來進行處理;雖然 Python 程式碼比精心設計的正則表達式慢,但它也可能更容易理解。
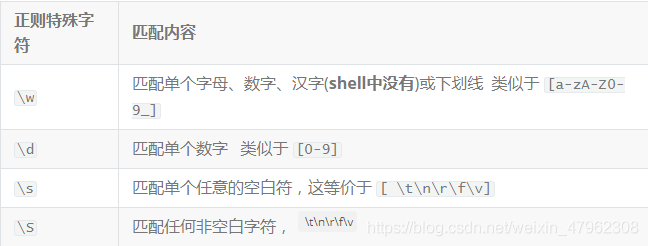
3. 特殊的字元
在 Python 中有一些特殊的字元,在正則表達式模式中的作用和 shell 和 grep -P 時候有一些細微的差別
二、 re 模組的方法
其實,前面在 shell 中我們已經學習正則,這裏我們主要學習的是 Python 中如何使用正則的,就是 re 模組中都有哪些方法。
接下來我們就學習幾個常間的方法
1 常用方法
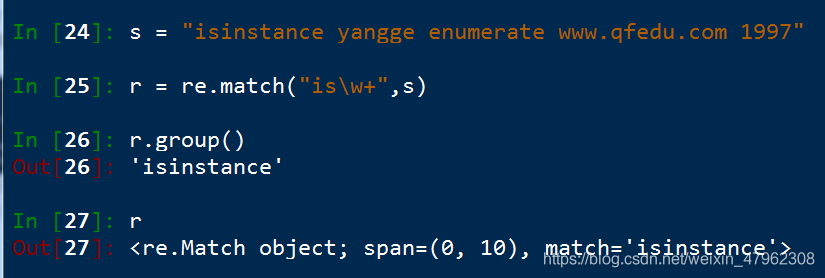
match() 就看開頭有沒有
只在整個字串的起始位置進行匹配.匹配的成功的結果是一段普通的資訊,所以在python中需要用group() 來獲取這段資訊
範例字串
r.group() 獲取檢視匹配成功的結果
search() 只查到第一個匹配的
從整個字串的開頭找到最後,當第一個匹配成功後,就不再繼續匹配。
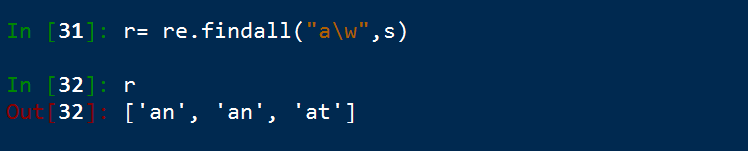
已a開始匹配,一旦滿足「a\w+"的條件就停止。

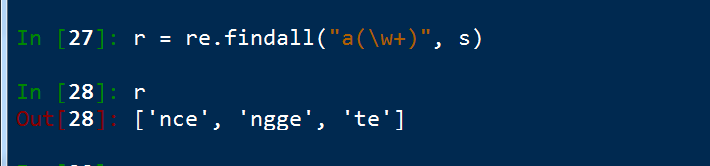
findall() 查到所有**
搜尋整個字串,找到所有匹配成功的字串,比把這些字串放在一個列表中返回。注意是列表返回,所以不需要藉助group()來展示結果
sub() 替換
把匹配成功的字串,進行替換。
基本語法
匹配規則,替換成的新內容, 被搜尋的物件, 有相同的話替換的次數
建」a\w" 替換成100
"a\w\ 表示後面的一個 an
s 搜尋的物件
2 字串內有相同的,替換的次數,從第一個開始算
語法內都已「,」 隔開
這裏用 r 來承接結果
模式不匹配時,返回原 來 s 的值

split() 分割
和 awk -F '[d]' 一樣效果,以匹配到的字元進行分割,返回分割後的列表
列對下面 下麪的s進行分割
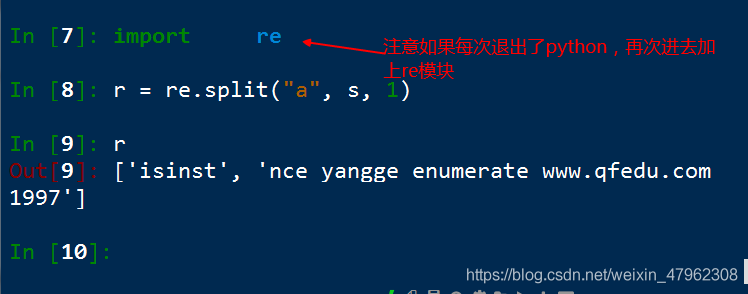
s = 'isinstance yangge enumerate www.qfedu.com 1997'
a作爲分割符
1 分割一次
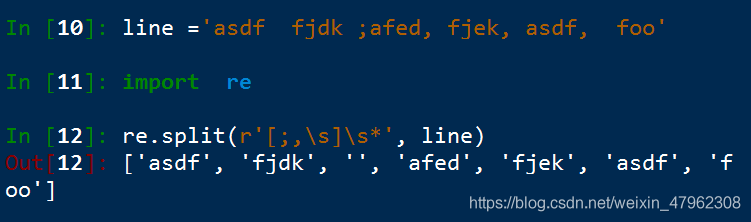
使用多個界定符分割字串
r 來定義分割符
[;,\s]\s*
已【冒號 逗號 空白符】 中的一個和多個空白符 作爲分割符
2. 正則分組
比如match
group() 匹配的內容
groups() 匹配的內容中的組

比如search
(?P<name>y\w+e)
這裏意思是 搜尋已 y 後面多個字元到e結束
()並給其分組
?P 命名 固定寫法
<>裏面的 內容隨意
groupdict() 顯示字典的格式

比如findall
整行的匹配 ,本身就是字串的顯示,所以只能顯示字串,不能匹配分組