python-------字串
一、 建立
建立寫法不一:
s1 = 'lenovo'
s2 = "QF"
s3 = """hello lenovo"""
s4 = '''hello 你好 '''
s5 = """hello
shark
"""
s6 = '''hello
world'''
二、簡單使用
1. \ 跳脫符
[1]testimony = ‘This shirt doesn\'t fit me’
[2] > this shirt doesn`t fit me
[3] w = ‘hello \nkevin’ (\n 換行符)
[4]> hello
kevin
2. + 拼接
In [13]: file_name= 「成功之母」
In [14]: suffix = ‘失敗’
In [15]: file_name = file_name + suffix
In [16]: file_name
Out[16]: ‘成功之母失敗’
拼接只能是 字串和字串進行操作,不可以用 字串和 一個非字串型別的物件相加
In [5]: ‘西瓜’ + 5 ## 這會報錯的
3. * 複製
In [6]: 「-」 * 10
Out[6]: ‘----------’
In [7]: print(’’ * 10)
**************(10個)
一可以直接進行演算法的運算
In [17]: 1*2
Out[17]: 2
In [18]: 2*4*3*3
Out[18]: 72
2**3(兩個*就是次方2的3次方)
三、取值和切片
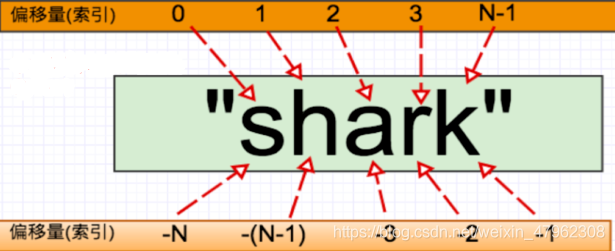
1. 字串 是 Python 中的一個 序列型別 的數據結構
- 存放的數據,在其內是有序的。
s1 = "shark"
序列型別的特點
-
序列裡的每個數據被稱爲序列的一個元素
-
元素在序列裡都是有個自己的位置的,這個位置被稱爲索引或者叫偏移量,也有叫下標的, 從
0開始,從左到右依次遞增 -
序列中的每一個元素可以通過這個元素的索引來獲取到
-
獲取到序列型別數據中的多個元素需要用切片的操作來獲取
2. 通過索引取值,獲取單個元素
In [10]: s1 = 「shark」
In [11]: s1[0]
Out[11]: 's'
In [12]: s1[-1]
Out[12]: 'k'
In [13]: s1[3]
Out[13]: 'r
3. 切片,獲取多個元素

3.1 一般操作
使用切片獲取多個元素
In [15]: s1[0:3]
Out[15]: 'sha'
起始和結尾的索引號可以省略
In [16]: s1[:3]
Out[16]: 'sha'
In [17]: s1[1:]
Out[17]: 'hark'
索引可以使用 負數
In [18]: s1[2:-1]
Out[18]: 'ar'
In [19]:
記住順序是 從左到右
逆順序不行
例如:
>>> s1[-1:-3]
''
>>>
3.2 使用步長
- 步長就是每數幾個取一個的意思
- 步長是正數時,是從左向右開始操作
- 步長是負數時,是從右向左操作
注意是雙冒號
In [19]: s2 = 'abcdefg'
In [20]: s2[::2]
Out[20]: 'aceg'
In [21]: s2[::-1]
Out[21]: 'gfedcba'
In [22]: s2[::-2]
Out[22]: 'geca'
四、字串方法
1. 統計序列數據的長度
就是獲取一個序列數據的元素個數,這個適用於所有的序列型別的數據,比如 字串、列表、元組。
獲取字串的長度,包含空格和換行符
In [25]: s3 = "a \n\t" 'a' a' '後面的空格 '\n' 是換行符 '\t'tab鍵空格
In [26]: len(s3)
Out[26]: 4
\n 是一個換行符
\t 是一個 Tab 鍵
3. strip() 去除字串兩端的空白字元(空格、\t、 \n)

4. split() 分割
預設使用空白字元作爲分隔符(空格、\t、 \n)
和 shell 中的 awk 一樣道理


可以指定分隔符

5. strip() 移除字串兩端的空白字元**
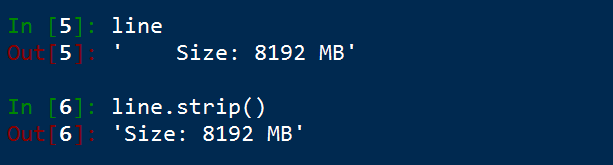
strip() 返回的是字串,所以可以連續操作

返回的結果是字串,所有可以對返回的結果,進一步處理。
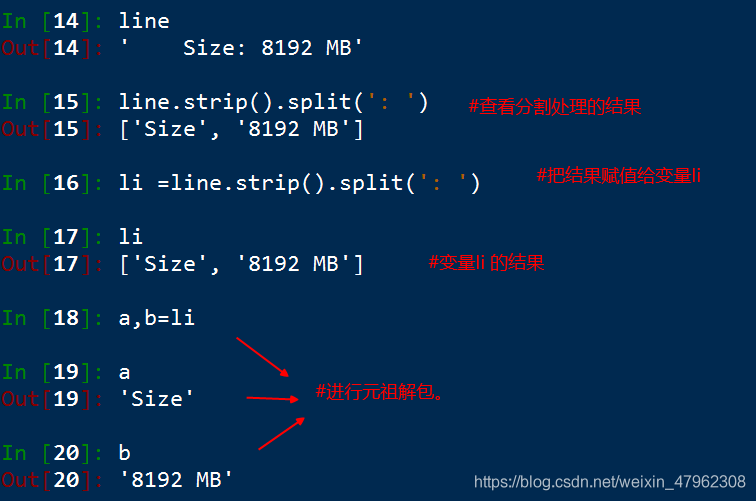
進行多元賦值
(字串、列表、元組都支援這種操作,也要元組解包)
假設 a,b = 1,2
那麼 a= 1
b =2

字串也可以進行元祖解包,和賦值。 我們建line的結果就可以進行如下操作。
6. replace() 替換

最後通過索引 [1:-6] 取結果

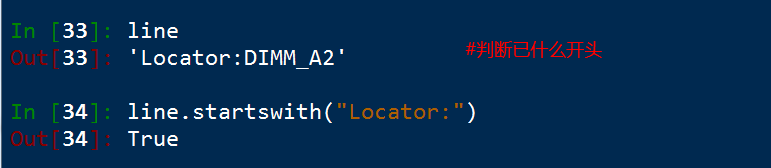
7. startswith() 判斷字串以什麼爲開頭
主要用在指令碼判斷語句中返回True 表示確實line是已Locator開頭
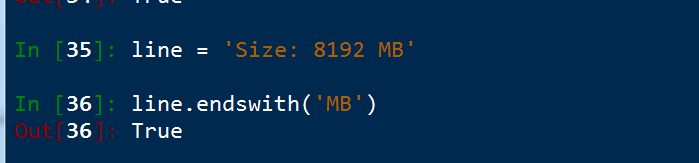
8. endswith() 判斷字串以什麼爲結尾
和 startswith先同性質
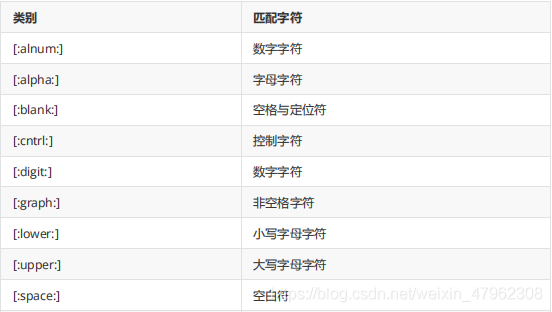
五、 字串的判斷(擴充套件自修)
digit 純數位
alnum 數位和字母
alpha 純字母
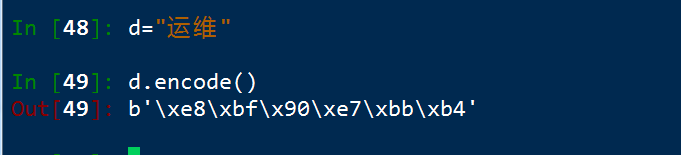
encode 二進制數據型別
根據下表的內容
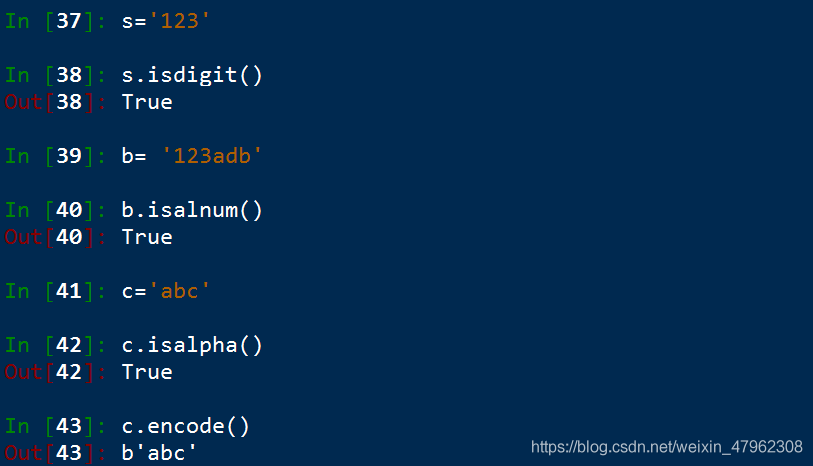
將運維轉化爲二進制顯示