WEB請求處理一:瀏覽器請求發起處理
最近,終於要把《WEB請求處理系列》提上日程了,一直答應小夥伴們給分享一套完整的WEB請求處理流程:從瀏覽器、Nginx、Servlet容器,最終到應用程式WEB請求的一個處理流程,前段時間由於其他工作事情的安排,一直未進行整理。不過還好該系列終於啓動了,給大家分享的同時,也順便整理下自己的思路,以便溫故而知新吧。希望大家都能在此過程中得到新的收穫吧。
本系 本係列主要分五部分:
1.《WEB請求處理一:瀏覽器請求發起處理》:分析使用者在瀏覽器中輸入URL地址,瀏覽器如何找到伺服器地址的過程,併發起請求;
2.《WEB請求處理二:Nginx請求反向代理》:分析請求在達反向代理伺服器內部處理過程;
3.《WEB請求處理三:Servlet容器請求處理》:分析請求在Servlet容器內部處理過程,並找到目標應用程式;
4.《WEB請求處理四:WEB MVC框架請求處理》:分析請求在應用程式內部,開源MVC框架的處理過程;
5.《WEB請求處理五:瀏覽器請求響應處理》:分析請求在伺服器端處理完成後,瀏覽器渲染響應頁面過程;
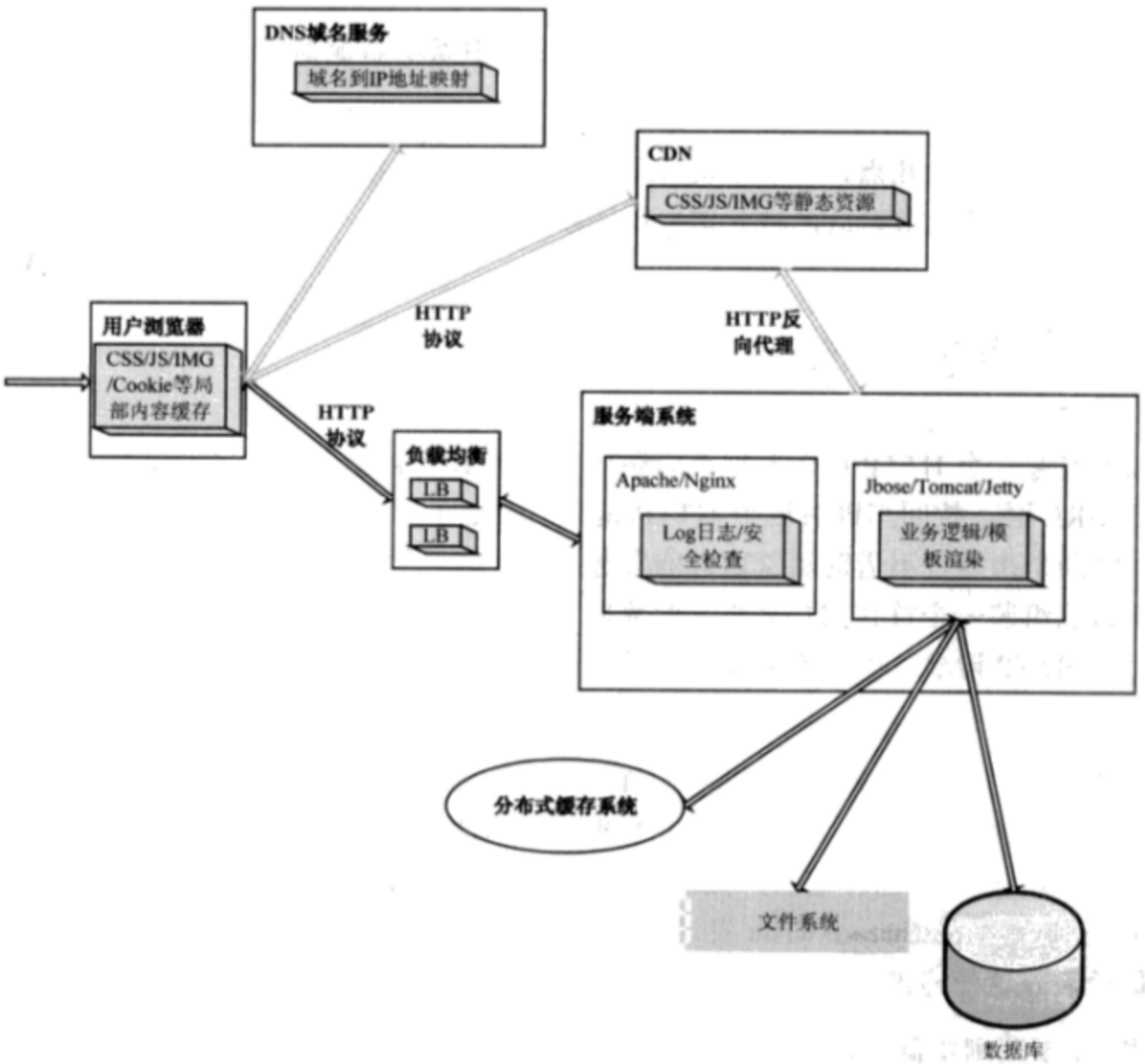
爲直觀明瞭,先上一張圖,紅色部分爲本章所述模組:

1 B/S網路架構概述#
我們先瞭解下B/S網路架構是什麼?B/S網路架構從前端到後端都得到了簡化,都基於統一的應用層協定HTTP來互動數據,HTTP協定採用無狀態的短鏈接的通訊方式,通常情況下,一次請求就完成了一次數據互動,通常也對應一個業務邏輯,然後這次通訊連線就斷開了。採用這種方式是爲了能夠同時服務更多的使用者,因爲當前網際網路應用每天都會處理上億的使用者請求,不可能每個使用者存取一次後就一直保持住這個連線。
當一個使用者在瀏覽器裡輸入www.google.com這個URL時,將會發生如下操作:
首先,瀏覽器會請求DNS把這個域名解析成對應的IP地址;
然後,根據這個IP地址在網際網路上找到對應的伺服器,建立Socket連線,向這個伺服器發起一個HTTP Get請求,由這個伺服器決定返回預設的數據資源給存取的使用者;
在伺服器端實際上還有複雜的業務邏輯:伺服器可能有多臺,到底指定哪臺伺服器處理請求,這需要一個負載均衡裝置來平均分配所有使用者的請求;
還有請求的數據是儲存在分佈式快取裡還是一個靜態檔案中,或是在數據庫裡;
當數據返回瀏覽器時,瀏覽器解析數據發現還有一些靜態資源(如:css,js或者圖片)時又會發起另外的HTTP請求,而這些請求可能會在CDN上,那麼CDN伺服器又會處理這個使用者的請求;
以上具體流程,如圖所示:
不管網路架構如何變化,但是始終有一些固定不變的原則需要遵守:
網際網路上所有資源都要用一個URL來表示。URL就是統一資源定位符;
必須基於HTTP協定與伺服器端互動;
數據展示必須在瀏覽器中進行;
2 HTTP協定解析#
B/S網路架構的核心是HTTP協定,最重要的就是要熟悉HTTP協定中的HTTP Header,HTTP Header控制着網際網路上成千上萬的使用者的數據傳輸。最關鍵的是,它控制着使用者瀏覽器的渲染行爲和伺服器的執行邏輯。
常見的HTTP請求頭:

常見的HTTP響應頭:

常見的HTTP狀態碼:

2.1 瀏覽器快取機制 機製##
當我們使用Ctrl+F5組合鍵重新整理一個頁面時,首先是在瀏覽器端,會直接向目標URL發送請求,而不會使用瀏覽器快取的數據;其次即使請求發送到伺服器端,也有可能存取到的是快取的數據。所以在HTTP的請求頭中會增加一些請求頭,它告訴伺服器端我們要獲取最新的數據而非快取。最重要的是在請求Head中增加了兩個請求項Pragma:no-cache和Cache-Control:no-cache。
- Cache-Control/Pragma
這個HTTP Head欄位用於指定所有快取機制 機製在整個請求/響應鏈中必須服從的指令,如果知道該頁面是否爲快取,不僅可以控制瀏覽器,還可以控制和HTTP協定相關的快取或代理伺服器。
Cache-Control/Pragma欄位的可選值:

Cache-Control請求欄位被各個瀏覽器支援的較好,而且它的優先順序也比較高,它和其他一些請求欄位(如Expires)同時出現時,Cache-Control會覆蓋其他欄位。
Pragma欄位的作用和Cache-Control有點類似,它也是在HTTP頭中包含一個特殊的指令,使相關的伺服器來遵守,最常用的就是Pragma:no-cache,它和Cache-Control:no-cache的作用是一樣的。
- Expires 快取過期時間
Expires通常的使用格式是Expires:Sat,25 Feb 2012 12:22:17 GMT,後面跟着一個日期和時間,超過這個值後,快取的內容將失效,也就是瀏覽器在發出請求之前檢查這個頁面的這個欄位,看該頁面是否已經過期了,過期了將重新向伺服器發起請求。
- Last-Modified/Etag 最後修改時間
Last-Modified欄位一般用於表示一個伺服器上的欄位的最後修改時間,資源可以是靜態(靜態內容自動加上Last-Modified)或者動態的內容(如Servlet提供了一個getLastModified方法用於檢查某個動態內容是否已經更新),通過這個最後修改時間可以判斷當前請求的資源是否是最新的。
一般伺服器端在響應頭中返回一個Last-Modified欄位,告訴瀏覽器這個頁面的最後修改時間,如:Sat,25 Feb 2012 12:55:04 GMT,瀏覽器再次請求時在請求頭中增加一個If-Modified-Since:Sat,25 Feb 2012 12:55:04 GMT欄位,詢問當前快取的頁面是否是最新的,如果是最新的就會返回304狀態碼,告訴瀏覽器是最新的,伺服器也不會傳輸新的數據。
與Last-Modified欄位有類似功能的還有一個Etag欄位,這個欄位的作用是讓伺服器端給每個頁面分配一個唯一編號,然後通過這個編號來區分當前這個頁面是否是最新的。這種方式比使用Last-Modified更加靈活,但是在後端的Web伺服器有多臺時比較難處理,因爲每個Web伺服器都要記住網站的所有資源編號,否則瀏覽器返回這個編號就沒有意義了。
3 WEB工作流程#
對於正常的上網過程,系統其實是這樣做的:
瀏覽器本身是一個用戶端,當你輸入URL的時候,
首先瀏覽器會去請求DNS伺服器,通過DNS獲取相應的域名對應的IP,然後通過IP地址找到IP對應的伺服器後,要求建立TCP連線,等瀏覽器發送完HTTP Request(請求)包後,伺服器接收到請求包之後纔開始處理請求包,伺服器呼叫自身服務,返回HTTP Response(響應)包;用戶端收到來自伺服器的響應後開始渲染這個Response包裡的主體(body),等收到全部的內容隨後斷開與該伺服器之間的TCP連線。
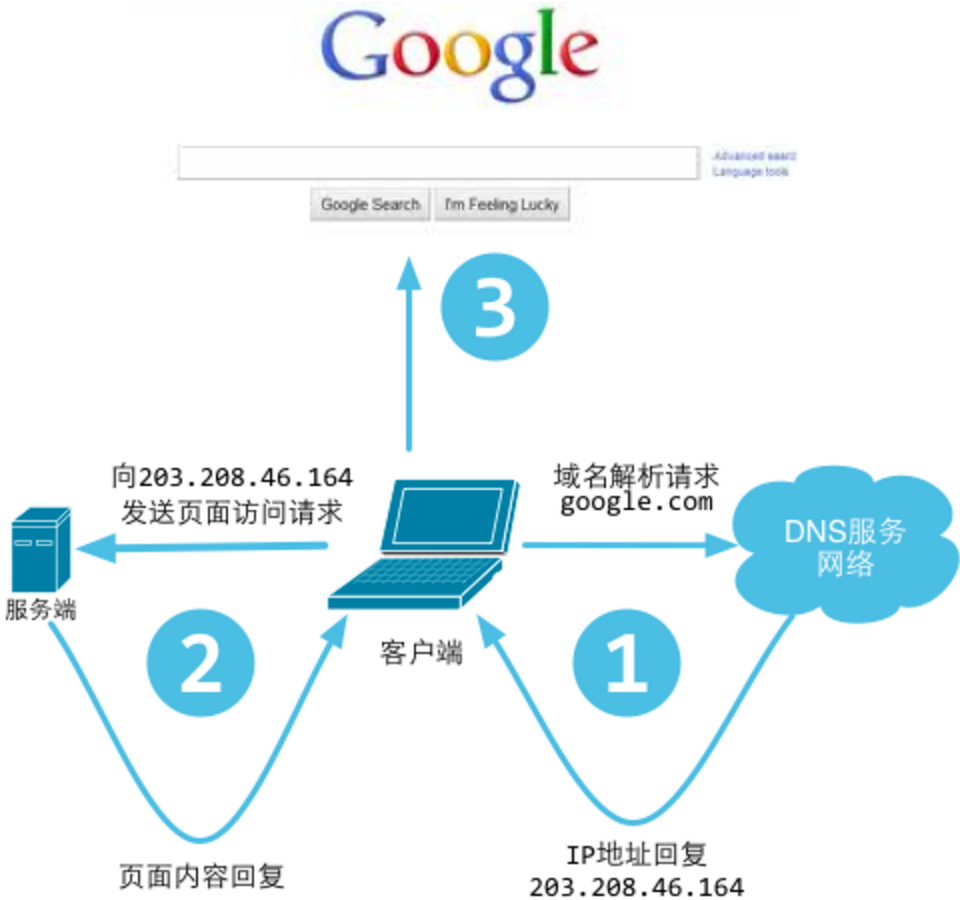
Web請求的工作原理可以簡單地歸納爲:
瀏覽器通過DNS域名解析到伺服器IP;
客戶機通過TCP/IP協定建立到伺服器的TCP連線;
用戶端向伺服器發送HTTP協定請求包,請求伺服器裡的資源文件;
伺服器向客戶機發送HTTP協定應答包,如果請求的資源包含有動態語言的內容,那麼伺服器會呼叫動態語言的解釋引擎負責處理「動態內容」,並將處理得到的數據返回給用戶端;
客戶機與伺服器斷開。由用戶端解釋HTML文件,在用戶端螢幕上渲染圖形結果;
一個簡單的HTTP事務就是這樣實現的,看起來很複雜,原理其實是挺簡單的。需要注意的是客戶機與伺服器之間的通訊是非持久連線的,也就是當伺服器發送了應答後就與客戶機斷開連線,等待下一次請求。
4 DNS域名解析#
4.1 DNS域名解析過程##
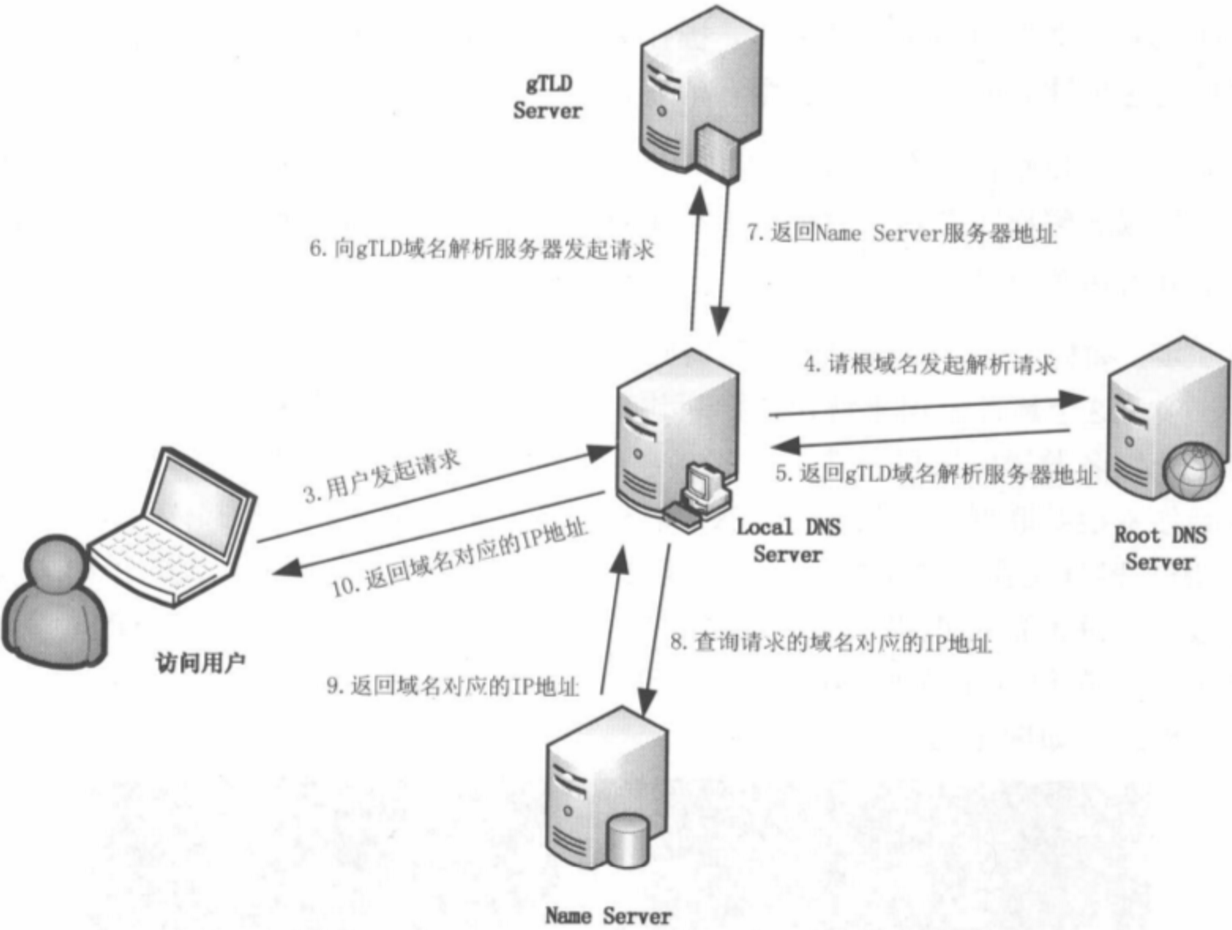
當使用者在瀏覽器中輸入域名,如:www.google.com,並按下回車後,DNS解析過程大體如下:
- 瀏覽器快取檢查(本機)
瀏覽器會首先搜尋瀏覽器自身的DNS快取(快取時間比較短,大概只有1分鐘,且只能容納1000條快取),看自身的快取中是否有www.google.com對應的條目,而且沒有過期,如果有且沒有過期則解析到此結束。
瀏覽器快取域名也是有限制的,不僅瀏覽器快取大小有限制,而且快取的時間也有限制,通常情況下爲幾分鐘到幾小時不等,域名被快取的時間限制可以通過TTL屬性來設定。這個快取時間太長和太短都不好,如果快取時間太長,一旦域名被解析到的IP有變化,會導致被用戶端快取的域名無法解析到變化後的IP地址,以致該域名不能正常解析,這段時間內有可能會有一部分使用者無法存取網站。如果時間設定太短,會導致使用者每次存取網站都要重新解析一次域名。
注:我們怎麼檢視Chrome自身的快取?可以使用 chrome://net-internals/#dns 來進行檢視

- 操作系統快取檢查(本機)+hosts解析(本機)
如果瀏覽器自身的快取裏面沒有找到對應的條目,其實操作系統也會有一個域名解析的過程,那麼Chrome會首先搜尋操作系統自身的DNS快取中是否有這個域名對應的DNS解析結果,如果找到且沒有過期則停止搜尋解析到此結束。
其次在Linux中可以通過/etc/hosts檔案來設定,你可以將任何域名解析到任何能夠存取的IP地址。如果你在這裏指定了一個域名對應的IP地址,那麼瀏覽器會首先使用這個IP地址。當解析到這個組態檔中的某個域名時,操作系統會在快取中快取這個解析結果,快取的時間同樣是受這個域名的失效時間和快取的空間大小控制的。
- 本地區域名伺服器解析(LDNS)
如果在hosts檔案中也沒有找到對應的條目,瀏覽器就會發起一個DNS的系統呼叫,就會向本地設定的首選DNS伺服器(LDNS一般是電信運營商提供的,也可以使用像Google提供的DNS伺服器)發起域名解析請求(通過的是UDP協定向DNS的53埠發起請求,這個請求是遞回的請求,也就是運營商的DNS伺服器必須得提供給我們該域名的IP地址)。
在我們的網路設定中都會有「DNS伺服器地址」這一項,這個地址就用於解決前面所說的如果兩個過程無法解析時要怎麼辦,操作系統會把這個域名發送給這裏設定的LDNS,也就是本地區的域名伺服器。這個DNS通常都提供給你本地網際網路接入的一個DNS解析服務,例如你是在學校接入網際網路,那麼你的DNS伺服器肯定在你的學校,如果你是在一個小區接入網際網路的,那這個DNS就是提供給你接入網際網路的應用提供商,即電信或者聯通,也就是通常所說的SPA,那麼這個DNS通常也會在你所在城市的某個角落,通常不會很遠。這個專門的域名解析伺服器效能都會很好,它們一般都會快取域名解析結果,當然快取時間是受域名的失效時間控制的,一般快取空間不是影響域名失效的主要因素。大約80%的域名解析都到這裏就已經完成了,所以LDNS主要承擔了域名的解析工作。
運營商的DNS伺服器首先查詢自身的快取,找到對應的條目,且沒有過期,則解析成功。

- 根域名伺服器解析(Root Server)
如果LDNS沒有找到對應的條目,則由運營商的DNS代我們的瀏覽器發起迭代DNS解析請求。它首先是會找根域的DNS的IP地址(這個DNS伺服器都內建13台根域的DNS的IP地址),找到根域的DNS地址,就會向其發起請求(請問www.google.com這個域名的IP地址是多少啊?)。
- 根域名伺服器返回給本地域名伺服器一個所查詢域的主域名伺服器(gTLD Server)地址,gTLD是國際頂級域名伺服器,如.com、.cn、.org等,全球只有13台左右。
根域發現這是一個頂級域com域的一個域名,於是就告訴運營商的DNS我不知道這個域名的IP地址,但是我知道com域的IP地址,你去找它去。
- 本地域名伺服器(Local DNS Server)再向上一步返回的gTLD伺服器發送請求。
於是運營商的DNS就得到了com域的IP地址,又向com域的IP地址發起了請求(請問www.google.com這個域名的IP地址是多少?),com域這台伺服器告訴運營商的DNS我不知道www.google.com這個域名的IP地址,但是我知道google.com這個域的DNS地址,你去找它去。
- 接受請求的gTLD伺服器查詢並返回此域名對應的Name Server域名伺服器的地址,這個Name Server通常就是你註冊的域名伺服器,例如你在某個域名服務提供商申請的域名,那麼這個域名解析任務就由這個域名提供商的伺服器來完成。
於是運營商的DNS又向google.com這個域名的DNS地址(這個一般就是由域名註冊商提供的,像萬網,新網等)發起請求(請問www.google.com這個域名的IP地址是多少?),這個時候google.com域的DNS伺服器一查,果真在我這裏,於是就把找到的結果發送給運營商的DNS伺服器,這個時候運營商的DNS伺服器就拿到了www.google.com這個域名對應的IP地址。
-
Name Server域名伺服器會查詢儲存的域名和IP的對映關係表,正常情況下都根據域名得到目標IP記錄,連同一個TTL值返回給DNS Server域名伺服器。
-
返回該域名對應的IP和TTL值,Local DNS Server會快取這個域名和IP的對應關係,快取的時間由TTL值控制。
-
把解析的結果返回給使用者,使用者根據TTL值快取在本地系統快取中,域名解析過程結束。
通過上面的步驟,我們最後獲取的是IP地址,也就是瀏覽器最後發起請求的時候是基於IP來和伺服器做資訊互動的。在實際的DNS解析過程中,可能還不止這10個步驟,如Name Server也可能有多級,或者有一個GTM來負載均衡控制,這都有可能會影響域名解析的過程。根據以上解析流程,DNS解析整個過程,分爲:遞回查詢過程和迭代查詢過程。如圖所示:

所謂 遞回查詢過程 就是 「查詢的遞交者」 更替, 而 迭代查詢過程 則是 「查詢的遞交者」不變。
舉個例子來說,你想知道某個一起上法律課的女孩的電話,並且你偷偷拍了她的照片,回到寢室告訴一個很仗義的哥們兒,這個哥們兒二話沒說,拍着胸脯告訴你,甭急,我替你查(
此處完成了一次遞回查詢,即,問詢者的角色更替)。然後他拿着照片問了學院大四學長,學長告訴他,這姑娘是xx系的;然後這哥們兒馬不停蹄又問了xx系的辦公室主任助理同學,助理同學說是xx系yy班的,然後很仗義的哥們兒去xx系yy班的班長那裏取到了該女孩兒電話。(此處完成若幹次迭代查詢,即,問詢者角色不變,但反覆 反復更替問詢物件)最後,他把號碼交到了你手裏。完成整個查詢過程。
4.2 跟蹤域名解析過程##
在Linux系統中還可以使用dig命名來查詢DNS的解析過程,如下所示:dig +cmd +trace www.google.com

上面清楚地顯示了整個域名是如何發起和解析的,從根域名(.)到gTLD Server(.com.)再到Name Server (google.com.)的整個過程都顯示出來了。還可以看出DNS的伺服器有多個備份,可以從任何一臺查詢到解析結果。
4.3 清除快取的域名##
我們知道DNS域名解析後會快取解析結果,其中主要在兩個地方快取結果,一個是Local DNS Server,另外一個是使用者的本地機器。這兩個快取都是TTL值和本機快取大小控制的,但是最大快取時間是TTL值,基本上Local DNS Server的快取時間就是TTL控制的,很難人工介入,但是我們的本機快取可以通過如下方式清除。
在Linux下可以通過/etc/init.d/nscd restart來清除DNS快取。如下:

JVM快取DNS解析結果:
在Java應用中JVM也會快取DNS的解析結果,這個快取是在InetAddress類中完成的,而且這個快取時間還比較特殊,它有兩種快取策略:一種是正確解析結果快取,另一種是失敗的解析結果快取。這兩個快取時間由兩個設定項控制,設定項是在%JAVA_ HOME%\lib\security\java.security檔案中設定的。兩個設定項分別是networkaddress.cache.ttl 和networkaddress.cache.negative.ttl,它們的預設值分別是-1(永不失效)和10(快取10秒)。
要修改這兩個值同樣有幾種方式,分別是:直接修改java.security檔案中的預設值、在Java的啓動參數中增加-Dsun.net.inetaddr.ttl=xxx來修改預設值、通過InetAddress類動態修改。
在這裏還要特別強調一下,如果我們需要用InetAddress類解析域名時,一定要是單例模式,不然會有嚴重的效能問題,如果每次都建立InetAddress範例,每次都要進行一次完整的域名解析,非常耗時,這點要特別注意。
4.4 幾種域名解析方式##
- A記錄,A代表的是Address,用來指定域名對應的IP地址
如將item.taobao.com指定到115.238.23.241,將switch.taobao.com指定到121.14.24.241。A記錄可以將多個域名解析到一個IP地址,但是不能將一個域名解析到多個IP地址。
- MX記錄,表示的是Mail Exchange,就是可以將某個域名下的郵件伺服器指向自己的Mail Server
如taobao.com域名的A記錄IP地址是115.238.25.245,如果MX記錄設定爲115.238.25.246,是[email protected]的郵件路由,DNS會將郵件發送到115.238.25.246所在的伺服器,而正常通過Web請求的話仍然解析到A記錄的IP地址。
- CNAME記錄,全稱是Canonical Name(別名解析),所謂的別名解析就是可以爲一個域名設定一個或者多個別名
如將taobao.com解析到xulingbo.net,將srcfan.com也解析到xulingbo.net,其中xulingbo.net分別是taobao.com和srcfan.com的別名。前面的跟蹤域名解析中的「www.taobao.com. 1542 IN CNAME www.gslb.taobao.com」就是CNAME解析。
- NS記錄,爲某個域名指定DNS解析伺服器,也就是這個域名有指定的IP地址的DNS伺服器去解析
前面的「google.com. 172800 IN NS ns4.google.com.」就是NS解析。
- TXT記錄,爲某個主機名或域名設定說明
如可以爲google.com設定TXT記錄爲「谷歌|中國」這樣的說明。
4.5 網路抓包分析##
Linux虛擬機器測試,使用命令 wget www.linux178.com 來請求,發現直接使用chrome瀏覽器請求時,幹擾請求比較多,所以就使用wget命令來請求,不過使用wget命令只能把index.html請求回來,並不會對index.html中包含的靜態資源(js、css等檔案)進行請求。
抓包截圖如下:

1號包,這個是那臺虛擬機器在廣播,要獲取192.168.100.254(也就是閘道器)的MAC地址,
因爲區域網的通訊靠的是MAC地址,它爲什麼需要跟閘道器進行通訊是因爲我們的DNS伺服器IP是外圍IP,要出去必須要依靠閘道器幫我們出去才行。2號包,這個是閘道器收到了虛擬機器的廣播之後,
迴應給虛擬機器的迴應,告訴虛擬機器自己的MAC地址,於是用戶端找到了路由出口。3號包,這個包是wget命令向系統設定的DNS伺服器提出域名解析請求(準確的說應該是wget發起了一個DNS解析的系統呼叫),請求的域名www.linux178.com,
期望得到的是IP6的地址(AAAA代表的是IPv6地址)。4號包,這個DNS伺服器給系統的響應,很顯然目前使用IPv6的還是極少數,所以得不到AAAA記錄的。
5&6號包,這個還是請求解析IPv6地址,但是www.linux178.com.leo.com這個主機名是不存在的,所以得到結果就是no such name。
7號包,這個纔是請求的域名對應的IPv4地址(A記錄)。
8號包,
DNS伺服器不管是從快取裏面,還是進行迭代查詢最終得到了域名的IP地址,響應給了系統,系統再給了wget命令,wget於是得到了www.linux178.com的IP地址,這裏也可以看出用戶端和原生的DNS伺服器是遞回的查詢(也就是伺服器必須給用戶端一個結果)這就可以開始下一步了,進行TCP的三次握手。
5 發起TCP的3次握手#
拿到域名對應的IP地址之後,User-Agent(一般是指瀏覽器)會以一個隨機埠(1024 < 埠 < 65535)向伺服器的WEB程式(常用的有httpd,nginx等)80埠發起TCP的連線請求。這個連線請求(原始的http請求經過TCP/IP4層模型的層層封包)到達伺服器端後(這中間通過各種路由裝置,區域網內除外),進入到網絡卡,然後是進入到內核的TCP/IP協定棧(用於識別該連線請求,解封包,一層一層的剝開),還有可能要經過Netfilter防火牆(屬於內核的模組)的過濾,最終到達WEB程式,最終建立了TCP/IP的連線。
如下圖所示:
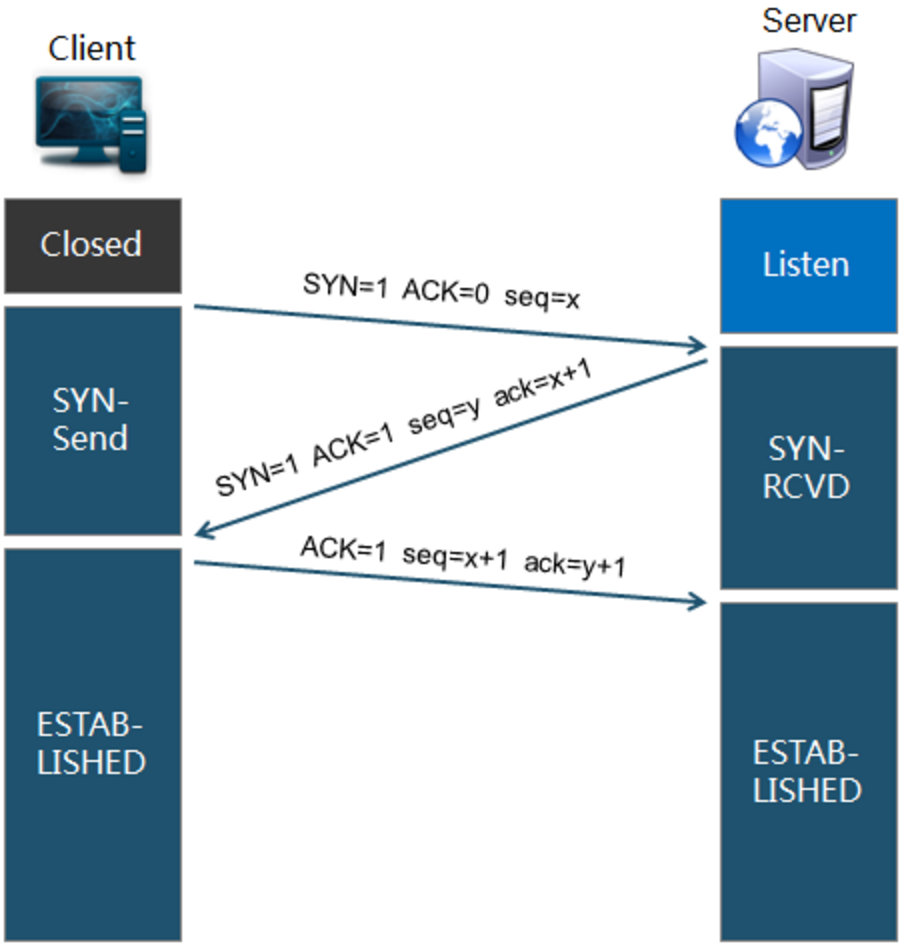
Client首先發送一個連線試探,ACK=0 表示確認號無效,SYN = 1 表示這是一個連線請求或連線接受報文,同時表示這個數據報不能攜帶數據,seq = x 表示Client自己的初始序號(seq = 0 就代表這是第0號包),這時候Client進入syn_sent狀態,表示用戶端等待伺服器的回覆 回復。
Server監聽到連線請求報文後,如同意建立連線,則向Client發送確認。TCP報文首部中的SYN 和 ACK都置1 ,ack = x + 1表示期望收到對方下一個報文段的第一個數據位元組序號是x+1,同時表明x爲止的所有數據都已正確收到(ack=1其實是ack=0+1,也就是期望用戶端的第1個包),seq = y 表示Server自己的初始序號(seq=0就代表這是伺服器這邊發出的第0號包)。這時伺服器進入syn_rcvd,表示伺服器已經收到Client的連線請求,等待client的確認。
Client收到確認後還需再次發送確認,同時攜帶要發送給Server的數據。ACK 置1 表示確認號ack= y + 1 有效(代表期望收到伺服器的第1個包),Client自己的序號seq= x + 1(表示這就是我的第1個包,相對於第0個包來說的),一旦收到Client的確認之後,這個TCP連線就進入Established狀態,就可以發起http請求了。
看抓包截圖:

TCP 爲什麼需要3次握手?
舉個例子:假設一個老外在故宮裏面迷路了,看到了小明,於是就有下面 下麪的對話:
老外: Excuse me,Can you Speak English?
小明: yes 。
老外: OK,I want ...
在問路之前,老外先問小明是否會說英語,小明回答是的,這時老外纔開始問路。
2個計算機通訊是靠協定(目前流行的TCP/IP協定)來實現,如果2個計算機使用的協定不一樣,那是不能進行通訊的,所以這個3次握手就相當於試探一下對方是否遵循TCP/IP協定,協商完成後就可以進行通訊了,當然這樣理解不是那麼準確。
爲什麼HTTP協定要基於TCP來實現?
目前在Internet中所有的傳輸都是通過TCP/IP進行的,HTTP協定作爲TCP/IP模型中應用層的協定也不例外,TCP是一個端到端的可靠的面向連接的協定,所以HTTP基於傳輸層TCP協定不用擔心數據的傳輸的各種問題。
6 建立TCP連線後發起http請求#
經過TCP3次握手之後,瀏覽器發起了http的請求(看第⑫包),使用的http的方法 GET 方法,請求的URL是 / ,協定是HTTP/1.0:

下面 下麪是第12號包的詳細內容:
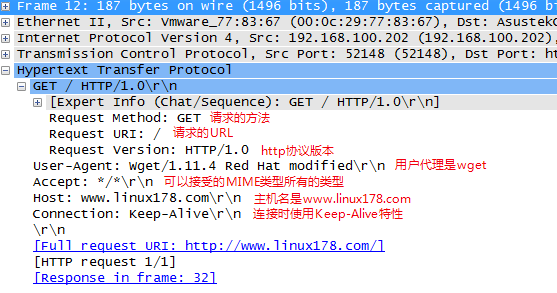
以上的報文是HTTP請求報文。那麼HTTP請求報文和響應報文會是什麼格式呢?
起始行:如 GET / HTTP/1.0 (請求的方法 請求的URL 請求所使用的協定)
頭部資訊:User-Agent Host等成對出現的值
主體
不管是請求報文還是響應報文都會遵循以上的格式。那麼起始行中的請求方法有哪些種呢?
GET: 完整請求一個資源 (常用)
HEAD: 僅請求響應首部
POST: 提交表單 (常用)
PUT: 上傳
DELETE: 刪除
OPTIONS: 返回請求的資源所支援的方法的方法
TRACE: 追求一個資源請求中間所經過的代理
那什麼是URL、URI、URN?
URI Uniform Resource Identifier 統一資源識別符號,如:scheme://[username:password@]HOST:port/path/to/source
URL Uniform Resource Locator 統一資源定位符,如:http://www.magedu.com/downloads/nginx-1.5.tar.gz
URN Uniform Resource Name 統一資源名稱
URL和URN都屬於URI,爲了方便就把URL和URI暫時都通指一個東西。
請求的協定有哪些種?有以下幾種:
http/0.9: stateless
http/1.0: MIME, keep-alive (保持連線), 快取
http/1.1: 更多的請求方法,更精細的快取控制,持久連線(persistent connection) 比較常用
下面 下麪是Chrome發起的http請求報文頭部資訊:

Accept 就是告訴伺服器端,接受那些MIME型別
Accept-Encoding 這個看起來是接受那些壓縮方式的檔案
Accept-Lanague 告訴伺服器能夠發送哪些語言
Connection 告訴伺服器支援keep-alive特性,TCP連線在發送後將仍然保持開啓狀態,於是,
瀏覽器可以繼續通過相同的TCP連線發送請求。保持連線節省了爲每個請求建立新連線所需的時間,還節約了網路頻寬。Cookie 每次請求時都會攜帶上Cookie以方便伺服器端識別是否是同一個用戶端
Host 用來標識請求伺服器上的那個虛擬主機,比如Nginx裏面可以定義很多個虛擬主機,那這裏就是用來標識要存取那個虛擬主機。
User-Agent 使用者代理,一般情況是瀏覽器,也有其他型別,如:wget curl 搜尋引擎的蜘蛛等
條件請求頭部:If-Modified-Since是瀏覽器向伺服器端詢問某個資原始檔如果自從什麼時間修改過,那麼重新發給我,這樣就保證伺服器端資原始檔更新時,瀏覽器再次去請求,而不是使用快取中的檔案。
安全請求頭部:Authorization: 用戶端提供給伺服器的認證資訊;
什麼是MIME?
MIME(Multipurpose Internet Mail Extesions 多用途網際網路郵件擴充套件)是一個網際網路標準,它擴充套件了電子郵件標準,使其能夠支援非ASCII字元、二進制格式附件等多種格式的郵件訊息,這個標準被定義在RFC 2045、RFC 2046、RFC 2047、RFC 2048、RFC 2049等RFC中。 由RFC 822轉變而來的RFC 2822,規定電子郵件標準並不允許在郵件訊息中使用7位ASCII字元集以外的字元。正因如此,一些非英語字元訊息和二進制檔案,影象,聲音等非文字訊息都不能在電子郵件中傳輸。
MIME規定了用於表示各種各樣的數據型別的符號化方法。此外,在萬維網中使用的HTTP協定中也使用了MIME的框架,標準被擴充套件爲網際網路媒體型別。
MIME 遵循以下格式:major/minor 主型別/次型別 例如:
image/jpg
image/gif
text/html
video/quicktime
appliation/x-httpd-php
作者:猿碼架構
鏈接:https://www.jianshu.com/p/558455228c43
來源:簡書
著作權歸作者所有。商業轉載請聯繫作者獲得授權,非商業轉載請註明出處。