【SQL經典50題】9.查詢和「 01 「號的同學學習的課程完全相同的其他同學的資訊【正解】
2020-08-14 23:07:49
SQL經典50題,第9題正解
正確解答需用到group_concat()函數,程式碼如下:
select
*
from
student
where
sid in (
select
sid
from
sc
group by
sid
having
group_concat(cid ORDER BY cid) = (
select
group_concat(cid ORDER BY cid) as str1
from
sc
where
sid = '01')
and sid != '01');
注: 解答此題時需要實現組內排序再拼接(group_concat方法自身可實現組內排序),不排序會導致結果出錯。
比如:s_id=01同學的c_id依次是01、02、03,但是s_id=02的某位同學的c_id是01、03、02,s_id=02同學是符合條件的,但是不排序會導致檢索不到,因爲s_id=01同學的字串是‘01,02,03’,而s_id=02同學的字串是‘01,03,02’。
MySQL中 group_concat() 用法解析:
作用:將組中的字串連線成爲具有各種選項的單個字串。
完整語法
group_concat([DISTINCT] 要連線的欄位 [Order BY ASC/DESC 排序欄位] [Separator '分隔符'])
範例
SELECT * FROM sc;

表結構與數據如上,現在的需求就是每個sid爲一行,然後一行內顯示該sid所有分數
接下來用group_concat !!!
select sid,group_concat(score)
from sc
GROUP BY sid;

可以看到結果根據id 分行,並且分數預設用逗號分割,每個id有重複數據
接下來去重
select sid,group_concat(DISTINCT score)
from sc
GROUP BY sid;

對內容進行排序
select sid,group_concat(DISTINCT score ORDER BY score DESC)
from sc
GROUP BY sid;

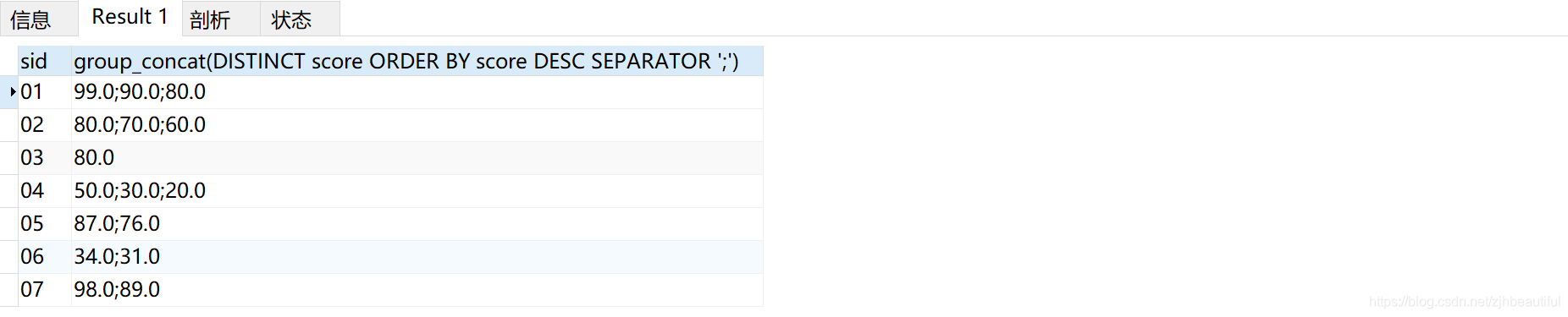
設定分隔符,把逗號換成分號
select sid,group_concat(DISTINCT score ORDER BY score DESC SEPARATOR ';')
from sc
GROUP BY sid;