分散式機器學習:模型平均MA與彈性平均EASGD(PySpark)
電腦科學一大定律:許多看似過時的東西可能過一段時間又會以新的形式再次迴歸。
1 模型平均方法(MA)
1.1 演演算法描述與實現
我們在部落格《分散式機器學習:同步並行SGD演演算法的實現與複雜度分析(PySpark)》中介紹的SSGD演演算法由於通訊比較頻繁,在通訊與計算比較大時(不同節點位於不同的地理位置),難以取得理想的加速效果。接下來我們介紹一種通訊頻率比較低的同步演演算法——模型平均方法(Model Average, MA)[1]。在MA演演算法中,每個工作節點會根據本地資料對本地模型進行多輪的迭代更新,直到本地模型收斂說本地迭代輪數超過一個預設的閾值,再進行一次全域性的模型平均,並以此均值做為最新的全域性模型繼續訓練,其具體流程如下:

MA演演算法按照通訊間隔的不同,可分為下面兩種情況:
- 只在所有工作節點完成本地訓練之後,做一次模型平均。這種情況下所需通訊量極小,本地模型在迭代過程中沒有任何互動,可以完全獨立地完成平行計算,通訊只在模型訓練的最後發生一次。這類演演算法只在強凸情形下收斂率有保障,但對非凸問題不一定適用(如神經網路),因為本地模型可能落到了不同的區域性凸子域,對引數的平均無法保證最終模型的效能。
- 在本地完成一定輪數的迭代之後,就做一次模型平均,然後用這次平均的模型的結果做為接下來的訓練起點,然後繼續迭代,迴圈往復。相比只在最終做一次模型平均,中間的多次平均控制了各工作節點模型之間的差異,降低了它們落在區域性凸子域的可能性,從而保證了最終的模型精度。這種方法被廣發應用於很多實際的機器學習系統(如CNTK)中,此外該思想在聯邦學習[2]中也應用廣泛)。
該演演算法的PySpark實現如下(我們將全域性迭代輪數設定為300,本地迭代輪數\(M\)設定為5,方便後面與SSGD演演算法進行對比):
from typing import Tuple
from sklearn.datasets import load_breast_cancer
import numpy as np
from pyspark.sql import SparkSession
from operator import add
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
n_slices = 4 # Number of Slices
n_iterations = 300 # Number of iterations
eta = 0.1
mini_batch_fraction = 0.1 # the fraction of mini batch sample
n_local_iterations = 5 # the number local epochs
def logistic_f(x, w):
return 1 / (np.exp(-x.dot(w)) + 1 +1e-6)
def gradient(pt_w: Tuple):
""" Compute linear regression gradient for a matrix of data points
"""
idx, (point, w) = pt_w
y = point[-1] # point label
x = point[:-1] # point coordinate
# For each point (x, y), compute gradient function, then sum these up
return (idx, (w, - (y - logistic_f(x, w)) * x))
def update_local_w(iter):
iter = list(iter)
idx, (w, _) = iter[0]
g_mean = np.mean(np.array([ g for _, (_, g) in iter]), axis=0)
return [(idx, w - eta * g_mean)]
def draw_acc_plot(accs, n_iterations):
def ewma_smooth(accs, alpha=0.9):
s_accs = np.zeros(n_iterations)
for idx, acc in enumerate(accs):
if idx == 0:
s_accs[idx] = acc
else:
s_accs[idx] = alpha * s_accs[idx-1] + (1 - alpha) * acc
return s_accs
s_accs = ewma_smooth(accs, alpha=0.9)
plt.plot(np.arange(1, n_iterations + 1), accs, color="C0", alpha=0.3)
plt.plot(np.arange(1, n_iterations + 1), s_accs, color="C0")
plt.title(label="Accuracy on test dataset")
plt.xlabel("Round")
plt.ylabel("Accuracy")
plt.savefig("ma_acc_plot.png")
if __name__ == "__main__":
X, y = load_breast_cancer(return_X_y=True)
D = X.shape[1]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0, shuffle=True)
n_train, n_test = X_train.shape[0], X_test.shape[0]
spark = SparkSession\
.builder\
.appName("Model Average")\
.getOrCreate()
matrix = np.concatenate(
[X_train, np.ones((n_train, 1)), y_train.reshape(-1, 1)], axis=1)
points = spark.sparkContext.parallelize(matrix, n_slices).cache()
points = points.mapPartitionsWithIndex(lambda idx, iter: [ (idx, arr) for arr in iter])
ws = spark.sparkContext.parallelize(2 * np.random.ranf(size=(n_slices, D + 1)) - 1, n_slices).cache()
ws = ws.mapPartitionsWithIndex(lambda idx, iter: [(idx, next(iter))])
w = 2 * np.random.ranf(size=D + 1) - 1
print("Initial w: " + str(w))
accs = []
for t in range(n_iterations):
print("On iteration %d" % (t + 1))
w_br = spark.sparkContext.broadcast(w)
ws = ws.mapPartitions(lambda iter: [(iter[0][0], w_br.value)])
for local_t in range(n_local_iterations):
ws = points.sample(False, mini_batch_fraction, 42 + t)\
.join(ws, numPartitions=n_slices)\
.map(lambda pt_w: gradient(pt_w))\
.mapPartitions(update_local_w)
par_w_sum = ws.mapPartitions(lambda iter: [iter[0][1]]).treeAggregate(0.0, add, add)
w = par_w_sum / n_slices
y_pred = logistic_f(np.concatenate(
[X_test, np.ones((n_test, 1))], axis=1), w)
pred_label = np.where(y_pred < 0.5, 0, 1)
acc = accuracy_score(y_test, pred_label)
accs.append(acc)
print("iterations: %d, accuracy: %f" % (t, acc))
print("Final w: %s " % w)
print("Final acc: %f" % acc)
spark.stop()
draw_acc_plot(accs, n_iterations)
1.2 演演算法收斂表現
演演算法初始化權重如下:
Initial w: [-4.59895046e-01 4.81609930e-01 -2.98562178e-01 4.37876789e-02
-9.12956525e-01 6.72295704e-01 6.02029280e-01 -4.01078397e-01
9.08559315e-02 -1.07924749e-01 4.64202010e-01 -6.69343161e-01
-7.98638952e-01 2.56715359e-01 -4.08737254e-01 -6.20120002e-01
-8.59081121e-01 9.25086249e-01 -8.64084351e-01 6.18274961e-01
-3.05928664e-01 -6.96321445e-01 -3.70347891e-01 8.45658259e-01
-3.46329338e-01 9.75573025e-01 -2.37675425e-01 1.26656795e-01
-6.79589868e-01 9.48379550e-01 -2.04796940e-04]
演演算法的終止權重和acc如下:
Final w: [ 3.61341700e+01 5.45002149e+01 2.13992526e+02 1.09001657e+02
-1.51389834e-03 3.94825208e-01 -9.31372452e-01 -7.19189889e-01
3.73256677e-01 4.47409722e-01 2.15583787e-01 3.54025928e+00
-2.36514711e+00 -1.33926557e+02 -3.50239176e-01 -3.85030823e-01
6.86489587e-01 -9.21881175e-01 -5.91052918e-01 -6.89098538e-01
3.72997343e+01 6.89626320e+01 2.16316126e+02 -1.45316947e+02
-5.57393906e-01 -2.76067571e-01 -1.97759353e+00 1.54739454e-01
1.26245157e-01 7.73083761e-01 4.00455457e+00]
Final acc: 0.853801
注意,正如我們在上一篇部落格《分散式機器學習:同步並行SGD演演算法的實現與複雜度分析(PySpark)》中所說,SSGD最終達到的精度為 0.929825,可見MA雖然可以減少通訊次數,但容易帶來精度損失。
MA演演算法的在測試集上的ACC曲線如下(注意全域性迭代輪數\(T=300\),本地迭代輪數\(M=5\),這裡的橫軸只包括全域性迭代輪數):
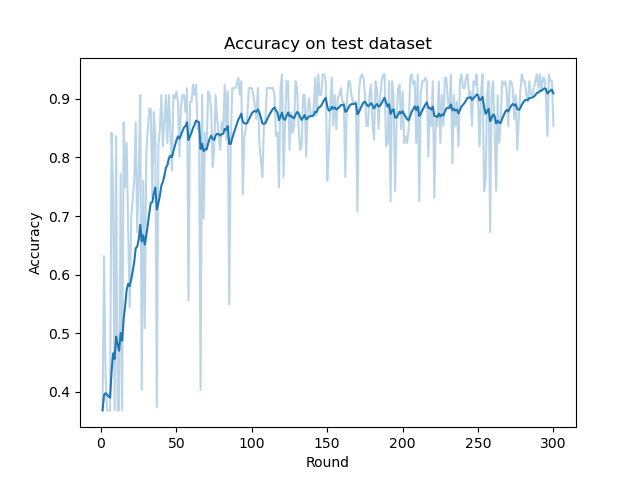
下面我們可以嘗試與全域性迭代輪數\(T=300\)的SSGD演演算法的ACC曲線做對比(下列是SSGD演演算法的ACC曲線):
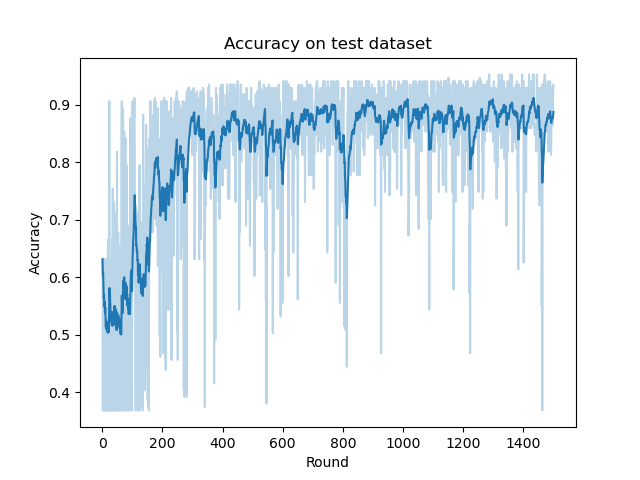
可以看到雖然MA演演算法在精度上有一定損失,但二者有著相似的收斂速率(如果我們考慮MA演演算法原生的迭代輪數的話)。事實上對於光滑強凸函數二者的收斂速率都為\(\mathcal{O}(\frac{1}{T})\)。
2 模型平均方法的改進——BMUF演演算法
2.1 演演算法描述與實現
在MA演演算法中,不論引數本地更新流程是什麼策略,在聚合的時候都只是將來自各個工作節點的模型進行簡單平均。如果把每次平均之間的本地更新稱作一個資料塊(block)的話,那麼模型平均可以看做基於資料塊的全域性模型更新流程。我們知道,在單機優化演演算法中,常常會加入動量[3]以有效利用歷史更新資訊來減少隨機梯度下降中梯度噪聲的影響。類似地,我們也可以考慮在MA演演算法中對每次全域性模型的更新引入動量的概念。一種稱為塊模型更新過濾(Block-wise Model Update Filtering, BMUF)[4]的演演算法基於資料塊的動量思想對MA進行了改進,其有效性在相關文獻中被驗證。BMUF演演算法實際上是想利用全域性的動量,使歷史上本地迭代對全域性模型更新的影響有一定的延續性,從而達到加速模型優化程序的作用。具體流程如下:

該演演算法的PySpark實現只需要在MA演演算法的基礎上對引數聚合部分做如下修改即可(同樣,我們將全域性迭代輪數設定為300,本地迭代輪數\(M\)設定為5):
mu = 0.9
zeta = 0.1
# weight update
delta_w = 2 * np.random.ranf(size=D + 1) - 1
for t in range(n_iterations):
...
w_avg = par_w_sum / n_slices
delta_w = mu * delta_w + zeta * (w_avg - w)
w = w + delta_w
2.2 演演算法收斂表現
BMUF演演算法的終止權重和acc如下:
Final w: [ 3.41516794e+01 5.11372499e+01 2.04081002e+02 1.03632914e+02
-7.95309541e+00 6.00459407e+00 -9.58634353e+00 -4.56611790e+00
-3.12493046e+00 7.20375548e+00 -6.13087884e+00 5.02524913e+00
-9.99930137e+00 -1.26079312e+02 -7.53719022e+00 -4.93277200e-01
-9.28534294e+00 -7.81058362e+00 1.78073479e+00 -1.49910377e-01
3.93256717e+01 7.52357494e+01 2.09020272e+02 -1.33107647e+02
8.22423217e+00 7.29714646e+00 -8.21168535e+00 -4.55323584e-02
2.08715673e+00 -9.04949770e+00 -9.35055238e-01]
Final acc: 0.929825
可以看到BMUF演演算法對MA演演算法的精度損失問題進行了一定程度上的解決。
BMUF演演算法的在測試集上的ACC曲線如下注意全域性迭代輪數\(T=300\),本地迭代輪數\(M=5\),這裡的橫軸只包括全域性迭代輪數):
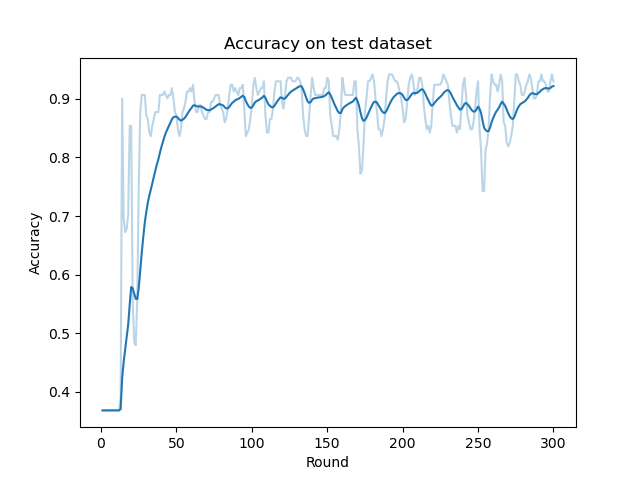
我們發現BMUF演演算法的收斂速率要略快於MA演演算法。由於利用了歷史動量資訊,其ACC曲線也要略為穩定一些。
3 彈性平均SGD演演算法(EASGD)
3.1 演演算法描述與實現
前面介紹的幾種演演算法無論本地模型用什麼方法更新,都會在某個時刻聚合出一個全域性模型,並且用其替代本地模型。但這種處理方法對於深度學習這種有很多個區域性極小點的優化問題而言,是否是最合適的選擇呢?答案是不確定的。由於各個工作節點所使用的訓練資料不同,本地模型訓練的模型有所差別,各個工作節點實際上是在不同的搜尋空間裡尋找區域性最優點,由於探索的方向不同,得到的模型有可能是大相徑庭的(最極端的情況也就是聯邦學習,不同節點間資料直接是Non-IID的)。簡單的中心化聚合可能會抹殺各個工作節點自身探索的有益資訊。
為了解決以上問題,研究人員提出了一種非完全一致的分散式機器學習演演算法,稱為彈性平均SGD(簡稱EASGD)[5]。該方法不強求各個工作節點繼承全域性模型(也是後來聯邦學習中個性化聯邦學習的思想。如果我們定義\(w_k\)為第\(k\)個工作節點上的模型,\(\overline{w}\)為全域性模型,則可將分散式優化描述為如下式子:
換言之,分散式優化有兩個目標:
- 使得各個工作節點本身的損失函數得到最小化。
- 希望各個工作節點上的本地模型和全域性模型之間的差距比較小。
按照這個優化目標,如果分別對\(w_k\),\(\overline{w}\)求導,就可以得到下列演演算法中的更新公式:

如果我們將EASGD與SSGD或者MA進行對比,可以看出EASGD在本地模型和伺服器模型更新時都兼顧全域性一致性和本地模型的獨立性。具體而言,是指:
- 當對本地模型進行更新時,在按照本地資料計算梯度的同時,也力求用全域性模型來約束本地模型不要偏離太遠。
- 在對全域性模型進行更新時,不直接把各個本地模型的平均值做為下一輪的全域性模型,而是部分保留了歷史上全域性模型的引數資訊。
這種彈性更新的方法,即可保持工作節點探索各自的探索方向,同時也不會讓它們彼此相差太遠(事實上,該思想也體現於ICML2021個性化聯邦學習論文Ditto[6]中)實驗表明,EASGD演演算法的精度和穩定性都有較好的表現。除了同步的設定,EASGD演演算法也有非同步的版本,我們後面再進行介紹。
該演演算法的PySpark實現只需要在MA演演算法的基礎上去掉用全域性引數對本地引數的覆蓋,並引數聚合部分和本地更新的部分修改即可:
rho = 0.1 # penalty constraint coefficient
alpha = eta * rho # iterative constraint coefficient
beta = n_slices * alpha # the parameter of history information
def update_local_w(iter, w):
iter = list(iter)
idx, (local_w, _) = iter[0]
g_mean = np.mean(np.array([ g for _, (_, g) in iter]), axis=0)
return [(idx, local_w - eta * g_mean - alpha * (local_w - w))]
...
if __name__ == "__main__":
...
for t in range(n_iterations):
print("On iteration %d" % (t + 1))
w_br = spark.sparkContext.broadcast(w)
ws = points.sample(False, mini_batch_fraction, 42 + t)\
.join(ws, numPartitions=n_slices)\
.map(lambda pt_w: gradient(pt_w))\
.mapPartitions(lambda iter: update_local_w(iter, w=w_br.value))
par_w_sum = ws.mapPartitions(lambda iter: [iter[0][1]]).treeAggregate(0.0, add, add)
w = (1 - beta) * w + beta * par_w_sum / n_slices
3.2 演演算法收斂表現
EASGD演演算法的終止權重和acc如下:
Final w: [ 4.41003205e+01 6.87756972e+01 2.59527758e+02 1.43995756e+02
1.13597321e-01 -2.85033742e-01 -5.97111145e-01 -2.77260275e-01
4.96300761e-01 3.30914106e-01 -2.22883276e-01 4.26915865e+00
-2.62994199e+00 -1.43839576e+02 -1.78751529e-01 2.54613165e-01
-8.19158564e-02 4.12327013e-01 -1.13116759e-01 -2.01949538e-01
4.56239359e+01 8.74703134e+01 2.62017432e+02 -1.77434224e+02
3.78336511e-01 -4.12976475e-01 -1.31121349e+00 -3.16414474e-01
9.83796876e-01 2.30045103e-01 5.34560392e+00]
Final acc: 0.929825
EASGD演演算法的在測試集上的ACC曲線如下:
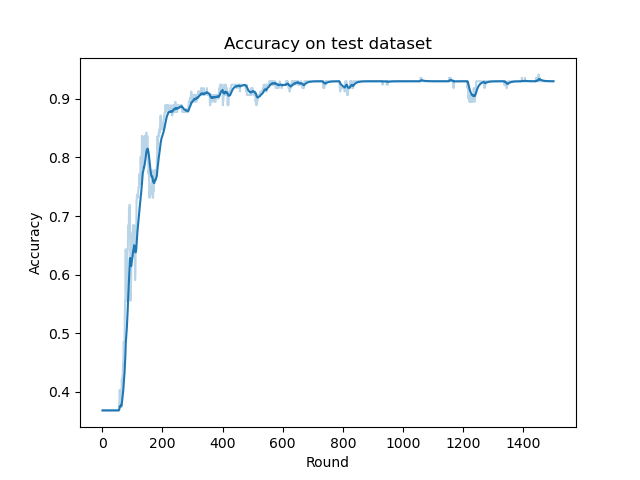
我們發現和BMUF演演算法類似,EASGD的演演算法收斂速率也要略快於SSGD演演算法和MA演演算法。而由於其彈性更新操作,其ACC曲線比上面介紹的所有演演算法都要穩定。
4 總結
上述介紹的都是分散式機器學習中常用的同步演演算法。MA相比SSGD,允許工作節點在本地進行多輪迭代(尤其適用於高通訊計算比的情況),因而更加高效。但是MA演演算法通常會帶來精度損失,實踐中需要仔細調整引數設定,或者通過增加資料塊粒度的動量來獲取更好的效果。EASGD方法則不強求全域性模型的一致性,而是為每個工作節點保持了獨立的探索能力。
以上這些演演算法的共性是:所有的工作節點會以一定的頻率進行全域性同步。當工作節點的計算效能存在差異,或者某些工作節點無法正常工作(比如宕機)時,分散式系統的整體執行效率不好,甚至無法完成訓練任務。而這就需要非同步的並行演演算法來解決了。
參考
-
[1]
McDonald R, Hall K, Mann G. Distributed training strategies for the structured perceptron[C]//Human language technologies: The 2010 annual conference of the North American chapter of the association for computational linguistics. 2010: 456-464. -
[2] McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Artificial intelligence and statistics. PMLR, 2017: 1273-1282.
-
[3] Sutskever I, Martens J, Dahl G, et al. On the importance of initialization and momentum in deep learning[C]//International conference on machine learning. PMLR, 2013: 1139-1147.
-
[4] Chen K, Huo Q. Scalable training of deep learning machines by incremental block training with intra-block parallel optimization and blockwise model-update filtering[C]//2016 ieee international conference on acoustics, speech and signal processing (icassp). IEEE, 2016: 5880-5884.
-
[5]
Zhang S, Choromanska A E, LeCun Y. Deep learning with elastic averaging SGD[J]. Advances in neural information processing systems, 2015, 28. -
[6] Li T, Hu S, Beirami A, et al. Ditto: Fair and robust federated learning through personalization[C]//International Conference on Machine Learning. PMLR, 2021: 6357-6368.
-
[7] 劉浩洋,戶將等. 最佳化:建模、演演算法與理論[M]. 高教出版社, 2020.
-
[8] 劉鐵巖,陳薇等. 分散式機器學習:演演算法、理論與實踐[M]. 機械工業出版社, 2018.
-
[9] Stanford CME 323: Distributed Algorithms and Optimization (Lecture 7)