向量資料庫Pinecone,治療ChatGPT幻覺的藥方?

大白話瞭解新鮮事,今天講講以Pinecone為代表的向量資料庫。向量資料庫Pinecone一夜爆火,4月27日B輪拿到了1億美元的融資,估值達到7.5億美元,一個2021年剛剛推出的資料庫產品,火爆背後的原因是什麼?
01 背景
自從AutoGPT,以及ChatGPT的Retrieval plugin推出之後(二者都推薦使用Pinecone),Pinecone的熱度就快速上升,那麼向量資料庫和ChatGPT有什麼關係?
「人們常常把大語言模型比喻成大腦,但這是一個被切除了顳葉的大腦,缺乏記憶,並且常常出現幻覺。」解決這些問題,我們常常需要藉助向量資料庫,這是它近期出現熱度的原因。
失憶:ChatGPT沒有記憶能力,有的人可能要說它明明記得我前面說過的話,這其實是因為你每一次prompt的時候,使用者端會把「當前對談」所有的聊天記錄作為一個大的prompt發給ChatGPT。因此,當你點選ChatGPT左側的「New chat」新建對談後,ChatGPT就會忘了你說過的所有內容。
幻覺:大型語言模型會產生幻覺(Hallucination),指的是它會返回語法正確但語意上不正確的回答,這種胡說八道的情況,相信只要用過幾次ChatGPT的小夥伴應該都遇到過。幻覺出現的原因是眼下的大語言模型還做不到真正理解語意(指像人類一樣理解),它更多的是一種數學上的抽象推理,就像Meta的首席科學家Yann LeCun的所說,「大型語言模型正在編造東西,努力生成合理的文字字串,而不理解它們的含義。」
02 向量
一個物體在平面上的位置可以用一個二維向量表示,如[3, 4],其中3表示橫向的距離,4表示縱向的距離。又或者,一個飛機在三維空間中的位置可以用一個三維向量表示,如[2, 3, 4]。更高維的向量以此類推。不嚴格地說,向量就是一個陣列,陣列的長度就是向量的維度。
也可以具象化的理解向量,以上面的飛機為例,向量就是從三維座標系原點出髮指向飛機所在位置的一段箭頭。
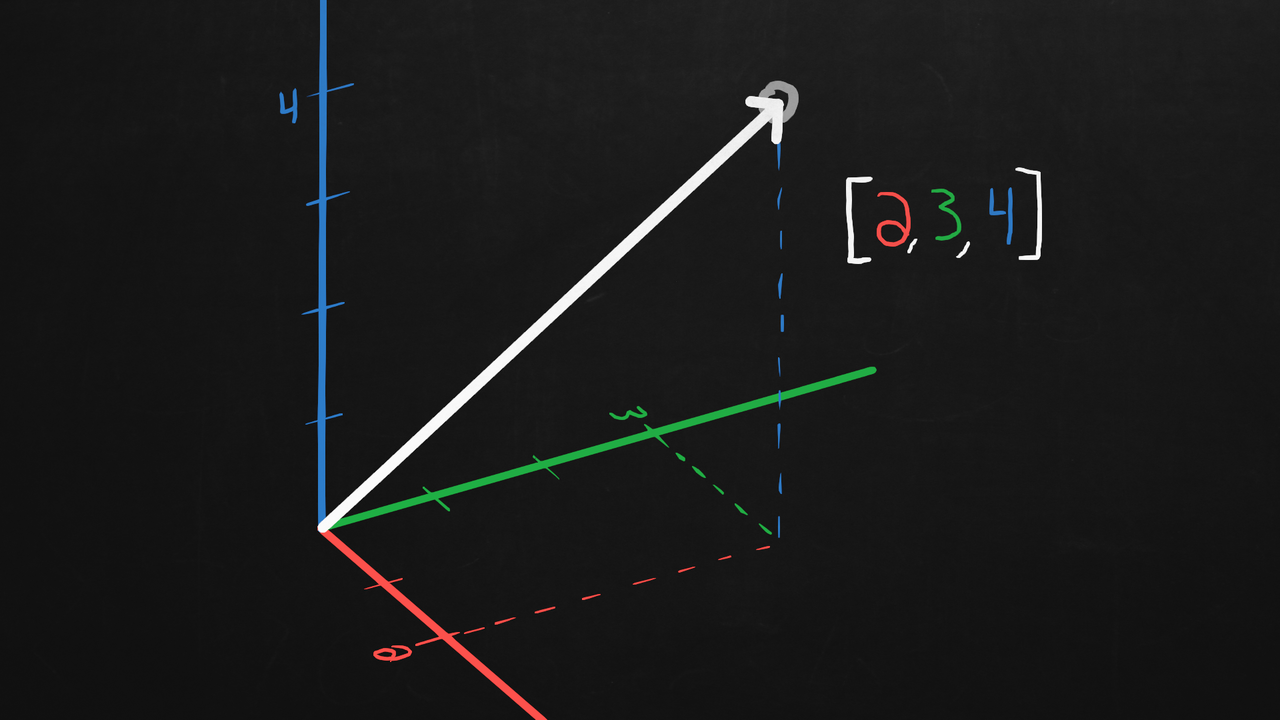
這樣幫助我們後面更容易理解什麼是向量之間的「相似度」——即兩個箭頭靠近的程度。怎麼計算呢?最簡單的就是「餘弦相似度」——兩個箭頭之間的夾角越小,則兩個向量相似度越高。
03 向量化
怎麼將單詞轉化為向量表示呢?你可以寫死,例如如果你的世界裡只有蘋果和梨,我們可以將蘋果寫死為二維向量[1, 0],將梨寫死為[0, 1]

當然世界並不是只有蘋果和梨,還有許多其他東西,這樣向量化的維度太高(陣列太長)、太稀疏(0值太多)、而且缺乏語意。現在人們都是用模型來生成向量(即embeddings),可以壓縮維度,還能保留語意。保留語意的意思是,語意越相近的文字(如「ocean」和「sea」),embedding生成的向量相似度也越高。
Huggingface上有不少開源的embeddings模型,OpenAI也提供了text-embedding-ada-002模型來將文字向量化,有興趣的可以看看。
04 向量資料庫
向量資料庫是一種專門用於儲存和處理向量資料的資料庫系統,它能夠高效地進行向量相似度查詢,這個「向量相似度」我們上面介紹過了。
向量資料庫如何幫助大語言模型緩解記憶缺失和幻覺的問題呢?
原理很簡單,針對幻覺問題,可以將所需領域的專業知識存入向量資料庫,當要prompt時,系統自動的從向量資料庫中根據「相似度」查詢最相關的專業知識,把這些知識和你的prompt一同提交給ChatGPT,這樣就可以有效減少幻覺的出現。記憶的問題也類似,可以選擇把部分你和ChatGPT的聊天記錄存入向量資料庫,ChatGPT Retrieval plugin提供了這樣的介面。
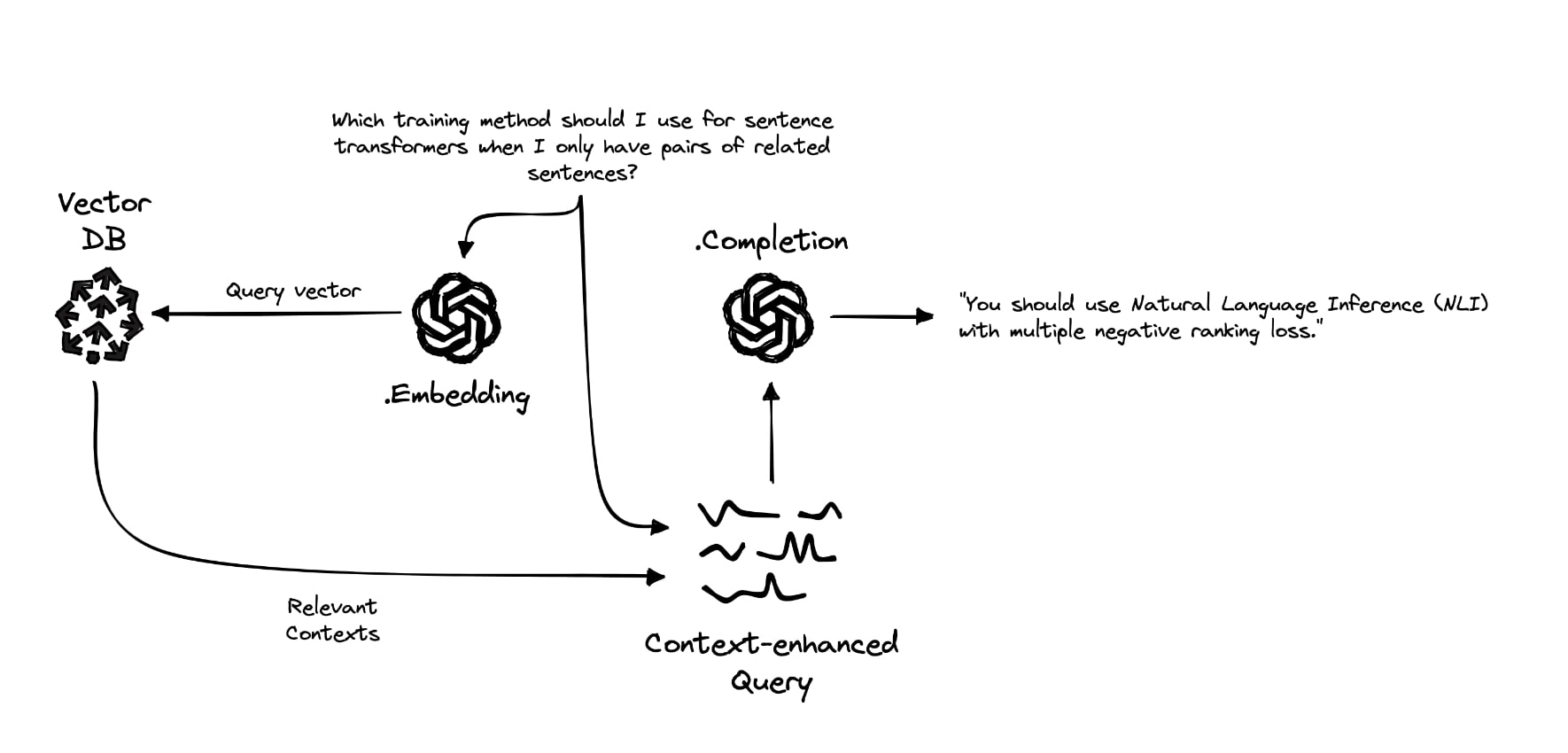
目前這種OP stack模式(OpenAI + Pinecone)已經逐漸在業界流行,連帶著包括Weaviate、Milvus這類競品的熱度也在上漲,前幾天翻看Redis官網的時候發現他們家也推出了向量資料庫產品Redis VSS。
靠著緊抱AI大腿,向量資料庫熱度將會持續。另外公有云廠商如阿里雲、AWS、GCP等,預計也會加大自己的向量資料庫的開發投入。而網際網路大廠作為各種AI模型的研發方和落地方,未來同樣免不了加大對自研向量資料庫的投入。所以,有興趣的小夥伴可以深入學習一下,看看這個領域裡還有什麼花樣可以玩。
(對了,如果有小夥伴還沒試用過ChatGPT,我搭了一個小跳板,關注公眾號「後廠村思維導圖館」,私信留言索要,同時,也可留言索要各類高清無水印思維導圖,記得留下郵箱哦)