Serverless冷擴機器在壓測中被擊穿問題
一、現象回顧
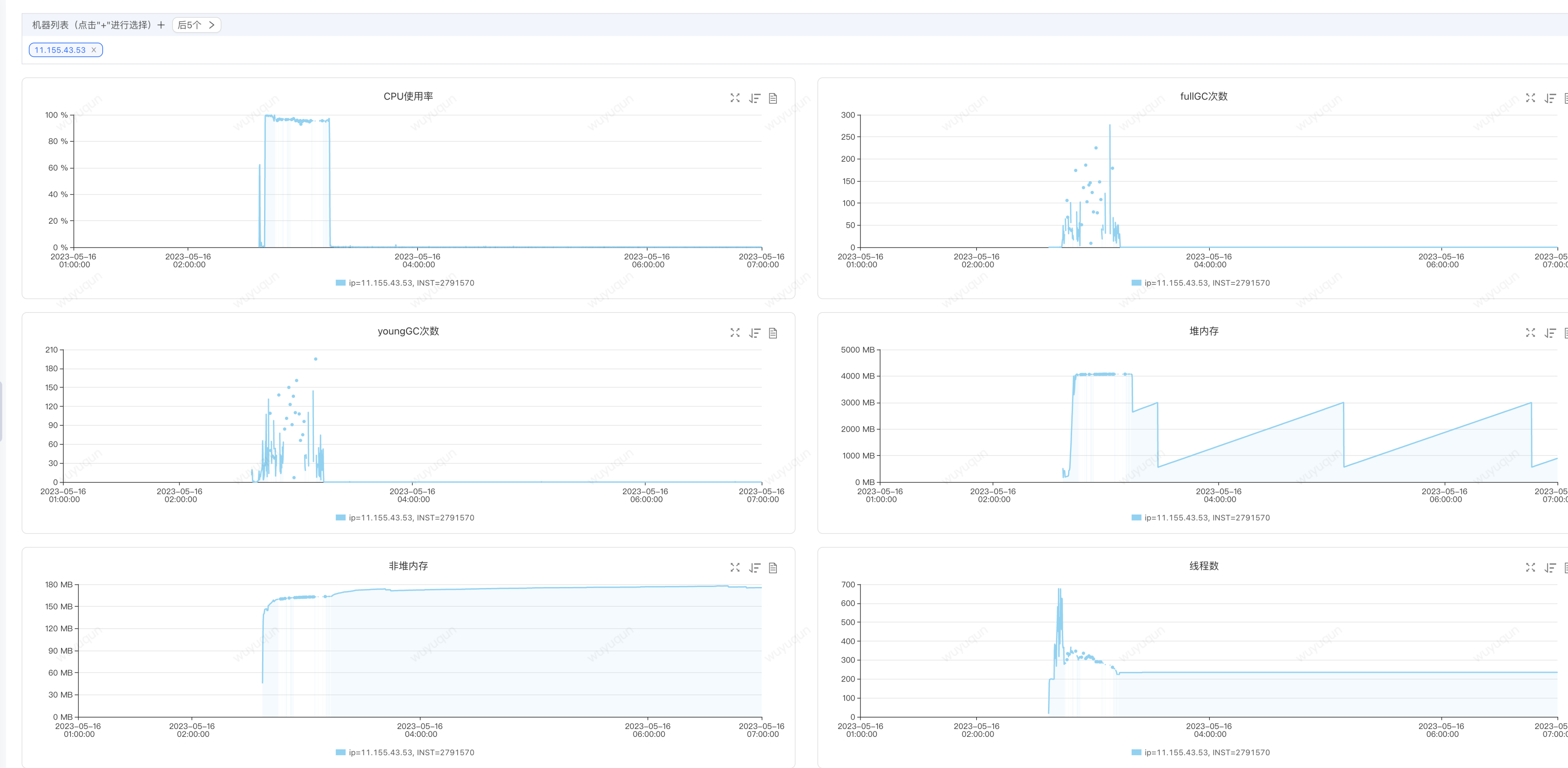
在今天ForceBot全鏈路壓測中,有位同事負責的服務做Serverless擴容(負載達到50%之後自動擴容並上線接入流量)中,發現新擴容的機器被擊穿,監控如下(關注2:40-3:15時間段的資料),我們可以看到,超高CPU,頻繁FullGC,並且每次FullGC之後對記憶體並不回收(見FullGC時間段對應的堆記憶體的曲線,是一條橫線)
分析結論: 記憶體已經被處理執行緒全部佔完,FullGC之後基本收不回多少記憶體,那麼意味著很快又會繼續FullGC,頻繁FullGC佔用大量CPU時間片段和暫停會導致系統處理能力劇烈下降,最終導致整個JVM進入崩潰狀態
二、問題重現
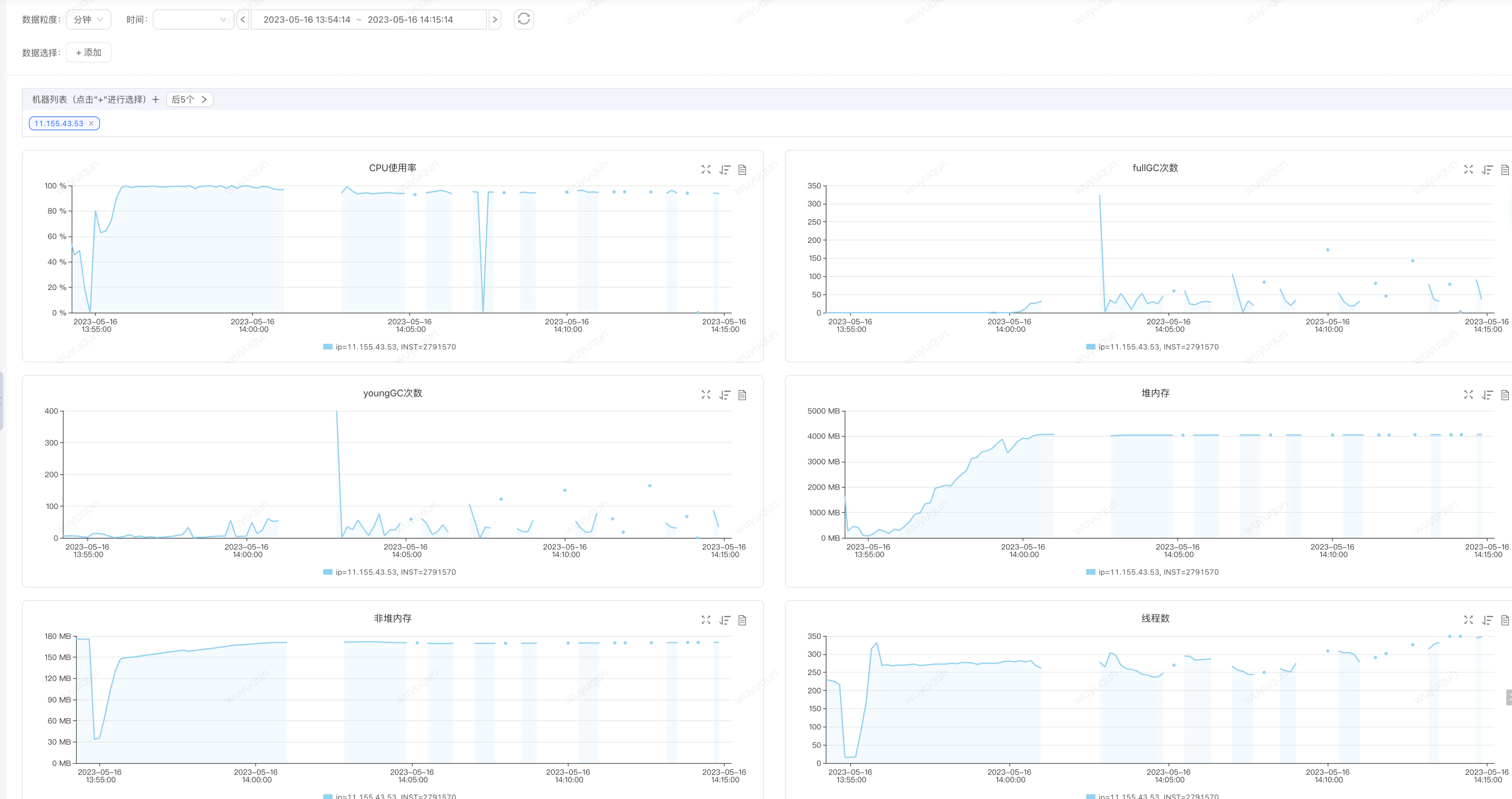
如上只是我們的理論分析,我們重新進行現象回放,模擬問題重現,目前訂單單機400QPS下,CPU大概是達到30-40%,我們模擬一下在沒有提前預熱(重啟Java服務)的情況下,使用壓測指令碼對服務進行請求回放,如下是我們一次重現的結果 (非必定,會有一定的概率重現),同樣的高CPU、頻繁FullGC,對記憶體無法被回收,JVM直接進入崩潰狀態
分析結論: 我們需要避免瞬間流量讓服務進入超高負載,進而被擊穿
三、解決方案
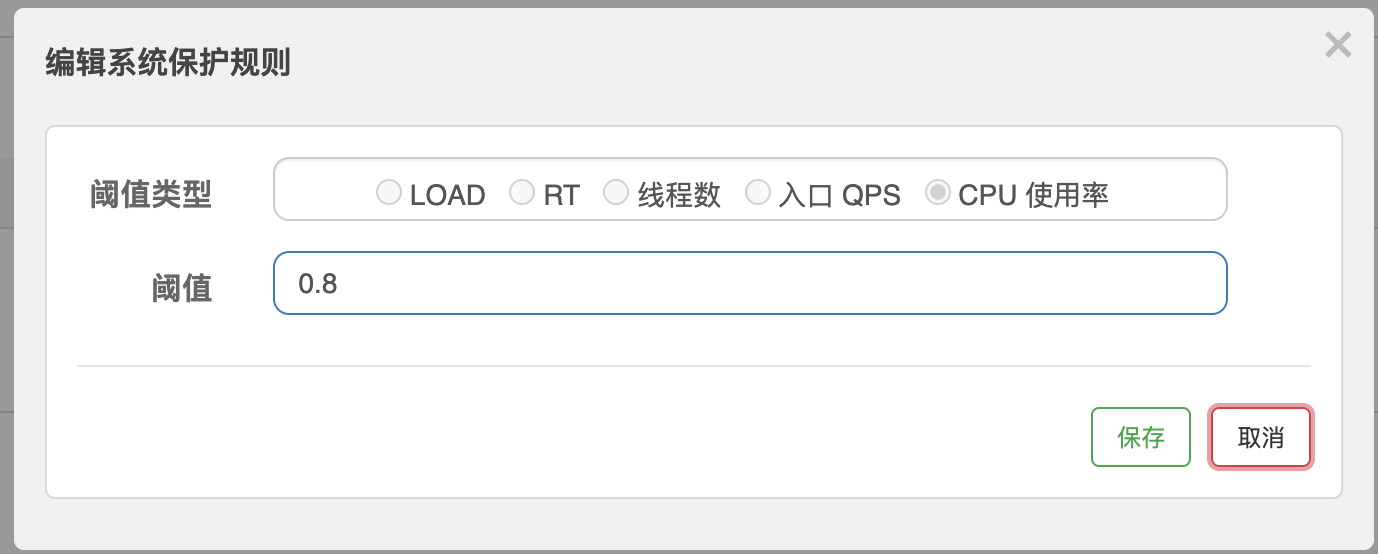
針對如上情況,我們嘗試使用Sentinel的系統規則,在系統負載過高的時候自動進行熔斷,避免系統過載導致被擊穿,我們設定一條CPU不超過80%的系統保護規則,如下,通過後面幾個過程,我們對比一下這條規則對我們系統的影響
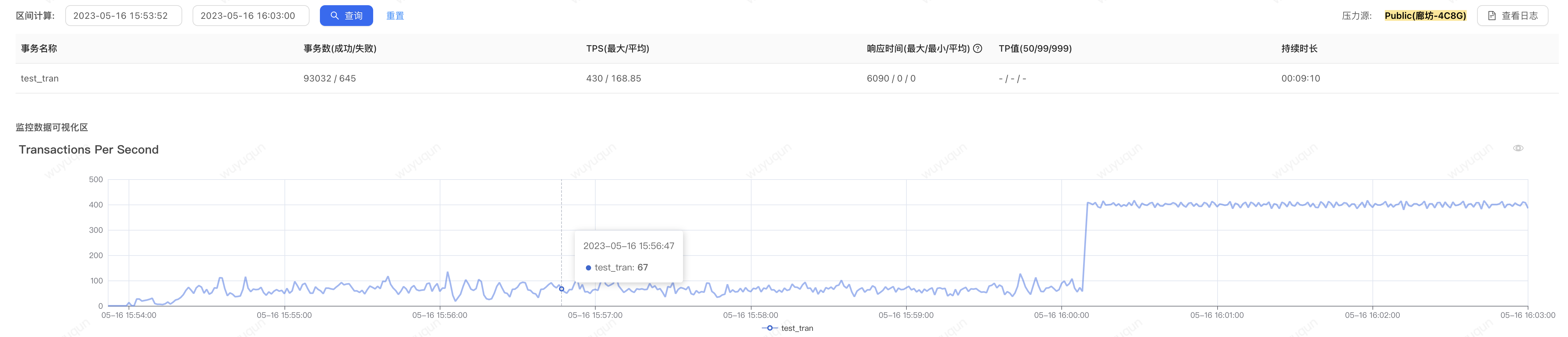
1.冷啟動狀態下,沒有設定系統保護規則的場景
在沒有設定如上規則的情況下,即便沒有被擊穿,我們看到,在冷啟動的狀態下,系統大概需要5-7分鐘的時間來讓系統從「準崩潰狀態」中恢復回來,如下是CPU監控檢視(大概6分鐘左右處於高負載的CPU狀態下,一旦恢復回來,CPU僅在30-40%左右)
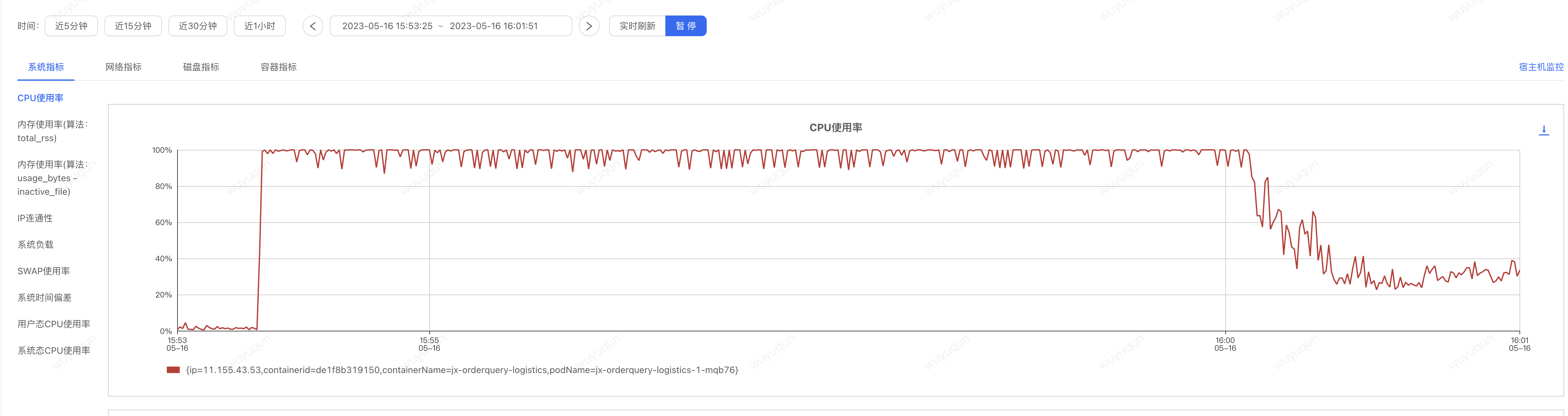
壓測端在高CPU階段QPS上不去,僅在50-100之間波動,CPU恢復之後,QPS迅速上漲到400,整個過程Sentinel無熔斷髮生
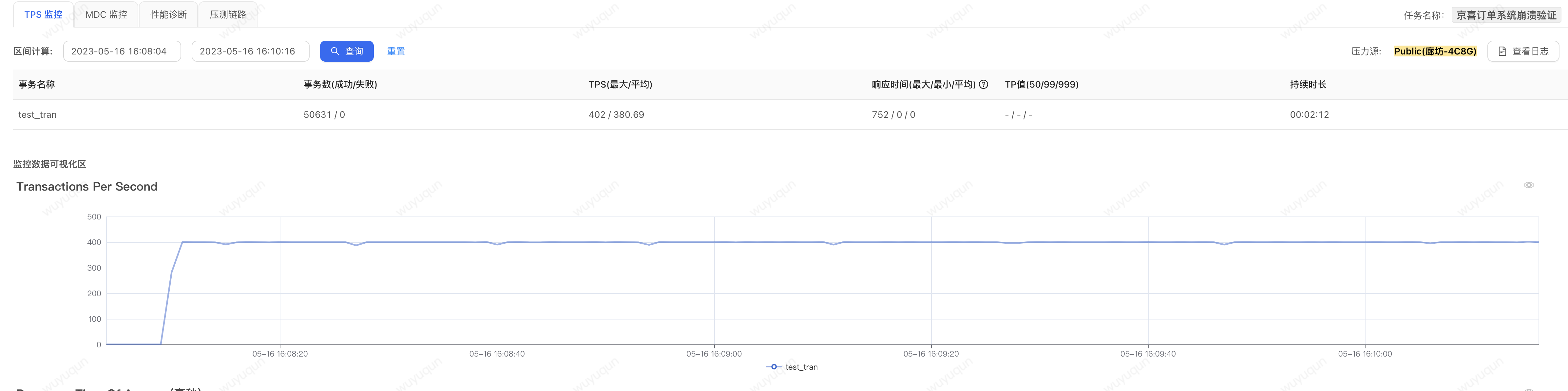
2.熱啟動狀態下,沒有設定系統保護規則:
在熱啟動狀態下,我們在上面壓測完一輪之後再壓測一輪,我們可以看到這個時候系統就沒有一個「預熱過程」的「準崩潰狀態」了
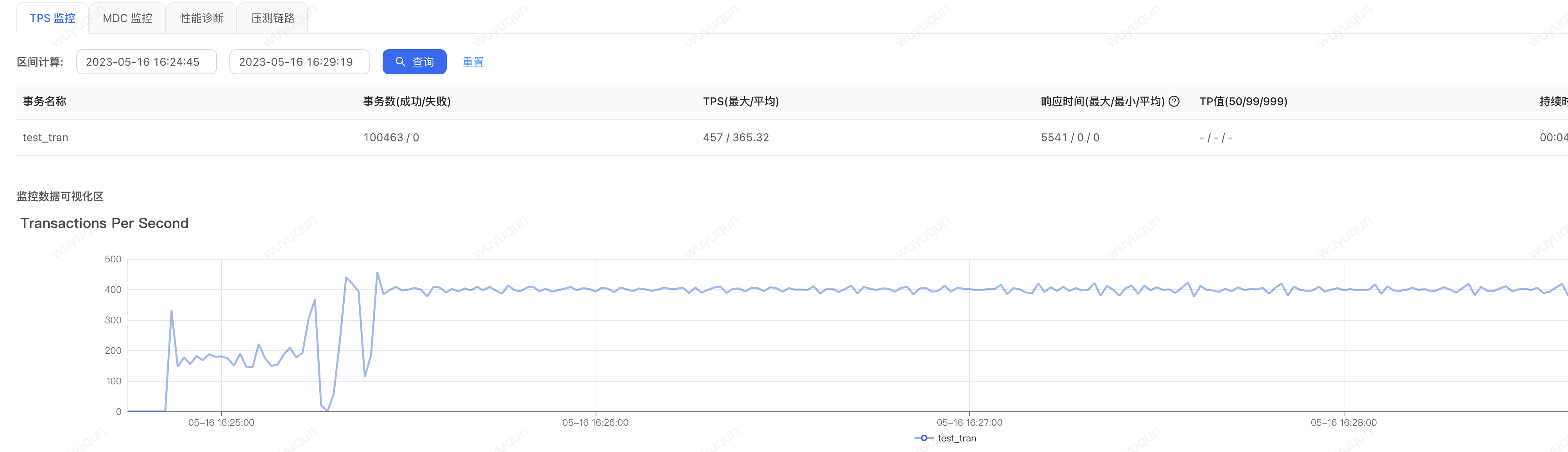
3.冷啟動狀態下,設定系統保護規則
我們再壓測一下冷啟動狀態下設定系統保護規則的情況(壓測前重新啟動一下Java程序,讓應用處於「冷啟動」的狀態),看如下監控圖,只要系統不進入「準崩潰狀態」,那麼系統會很快就恢復到正常狀態,從下面圖上看冷啟動下對系統的影響只有前一分鐘
如下是壓測端檢視
如下是CPU的情況
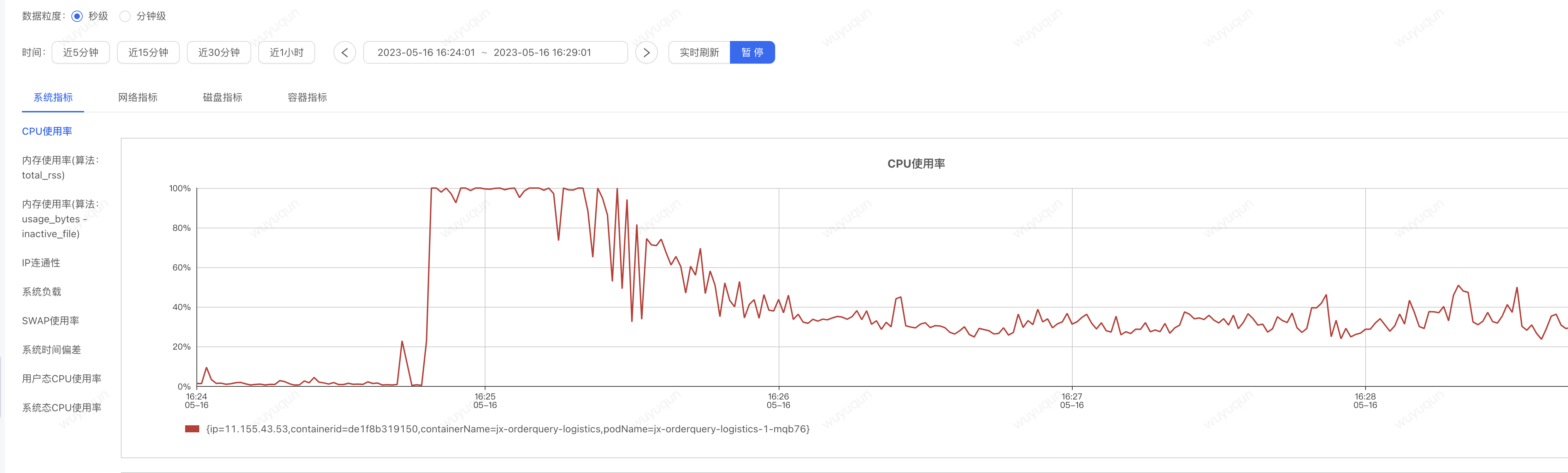
如下是Sentinel熔斷情況,有1分鐘左右有熔斷髮生
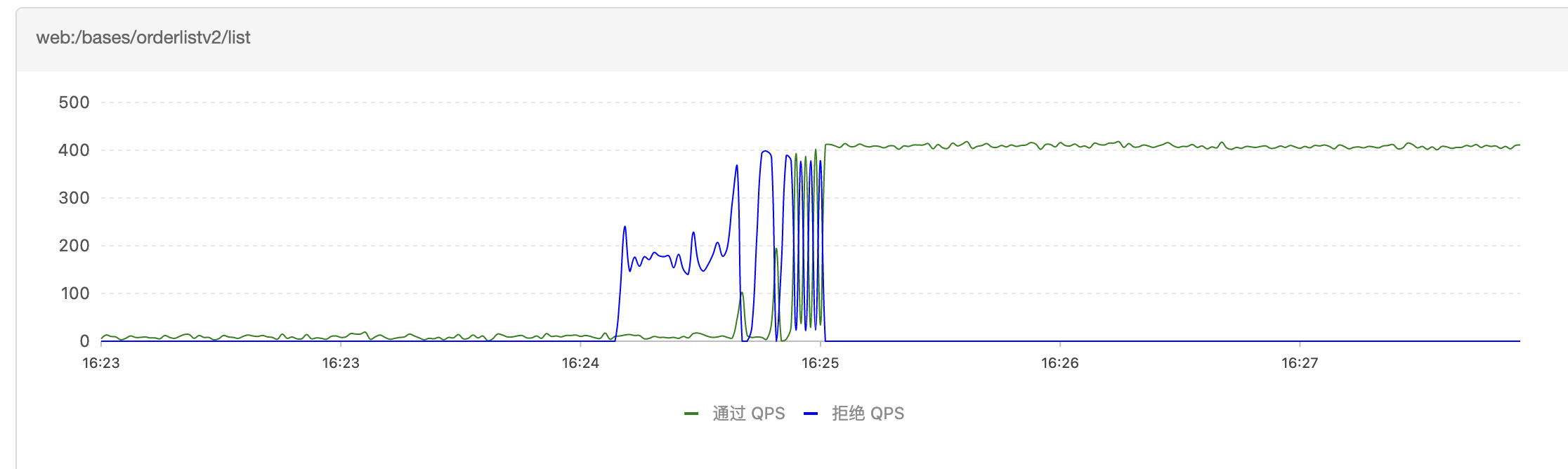
4.冷啟動效能差之謎
冷啟動過程效能比較慢,主要是有幾方面因素導致:
1)HotSpot JVM優化:熱點監測JVM會在程式執行期間不斷對程式碼進行不同級別的優化,高頻執行程式碼會被JIT Compiler優化到最佳的狀態,而在冷啟動開始執行的時候,程式碼還處於原始狀態,效能相對會差
2)資源就緒情況:譬如一些執行緒池在開始執行之後才會被建立,或者程式中有一些連線是在啟動之後才會開始建立
3)崩潰迴圈:當CPU升高之後,執行緒切換等操作本身可能會導致CPU更高,從而讓系統螺旋式進入一種越來越糟糕的狀態,直到達到一個平衡點,而上面的1)和2)隨著執行的優化會在達到平衡點之後打破平衡點,螺旋式下降讓系統恢復到比較好的狀態,但最糟糕的情況是達不到平衡點系統直接崩潰無法恢復
四、題外話
這個問題不僅僅出現在Serverless冷擴,如果有一天,你發現請求量暴漲負載過高,於是你擴容了機器,然後你接入了流量,哐當,被打崩了......這個場景是不是太過慘淡了
作者:京東零售 吳毓群
內容來源:京東雲開發者社群