如何保證使用者重試操作的冪等性
服務不穩定是一類常態,面對此類場景恰當的應對策略應該是什麼?退一步說,即使我們能夠確保第一方服務的穩定性,我們又應該如何面對網路延遲以及掌控以外的不確定性?這都是本篇文章會談到的內容
本文是團隊內部分享的文字版,敏感資訊已經抹去或者重寫。我們通過三個實際的線上問題來看看在今後的開發過程中可以如何避免此類問題
校驗是可選還是必選
用例1:學生可以在網站選擇指定的日期和時間預約老師進行會議,老師也需要設定在某一時間段內可以並行服務學生的數量,畢竟她的頻寬有限。但線上出現了老師在同一時間內被多個學生預約成功的情況,即預約數超出了她可以提供服務的上限。
用例2:在使用者第一次存取網站前,他需要簽署一系列協定。但我們發現有些協定被連續簽署了多次,導致後續的功能出現了異常。在重現問題的過程中我們得知,確實可以通過複製瀏覽器標籤的方式來重複簽署同一份協定
這兩個問題的修復方式是顯而易見的:給後端有關介面新增校驗。但問題是,它們是否可以算作開發功能的失誤?用「九轉大腸」問句就是:是故意的還是不小心的?
經典的風險應對模型告訴我們,根據風險的危害和發生概率,我們可以使用四種策略來處理問題:avoid、reduce、retain、transfer
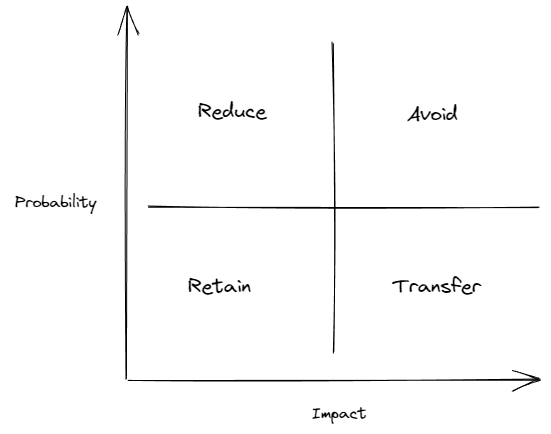
在我看來模型傳達給我們的不止於此;
- 對於 retain,我認為它更想表達的不僅僅接納(什麼都不做),而是儘可能用低成本的方式去做;
- 對於 avoid,你可能無法完美 avoid,但也許你可以把風險往其他象限轉移,畢竟降低風險也是一種策略
回到這段開頭的兩個 case 上,我認為在功能設計之初,考慮到有限的使用頻率和可承受的風險,以及無從考證的交付壓力,不去介面校驗沒有問題。(我們一直以來缺乏對於資料增長的監控,很多問題的產生,尤其是效能問題都是在稍不留神間達到了程式碼能夠支撐的閾值,這個問題之後再談)。但我們真就可以什麼都不用做了嗎?至少我們可以讓程式碼變得靈活一些:不需要去預測未來發生什麼,讓程式碼可能應對未來的變化即可:
於是,我們傾向於將演進能力構建到軟體中,如果專案可以輕鬆應對變化,那麼架構師就不再需要水晶球 ——《演進式架構》人民郵電出版社
關鍵在於,你並不需要去預測什麼會變化,你需要知道的是,變化必然會發生。程式應該保證儘可能的靈活性,這樣,不管未來發生什麼變化,都可以應付得了——《簡約之美:軟體設計之道》人民郵電出版社
更復雜的問題
如果說前兩個用例的癥結和方案都清晰可見的話,下面這個用例也許可以帶來一些思考。
假設我們需要在頁面上展示申請處理進展,進展由步驟(step)構成。步驟的型別分為主步驟(step)和子步驟(sub step),可以混合使用進行串聯,如下圖所示
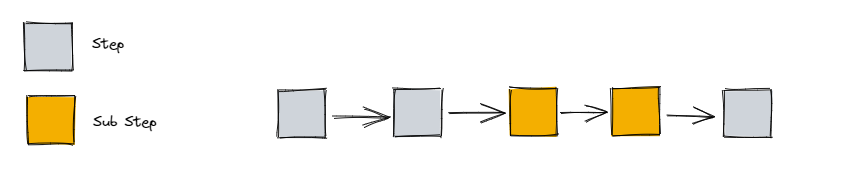
顧名思義,進展允許前進也就允許回滾。兩類步驟分別有屬於自己的回滾介面:
- step 回滾:使用 PUT method 呼叫 /{progressID}/back
- sub step 回滾:使用 PUT method 呼叫 /{progressID}/back,但是需要在 payload 里加上需要回滾的 sub step 所屬的 step ID
假設目前存在一個如下圖所示的步驟序列,當前的步驟位置處於尾聲
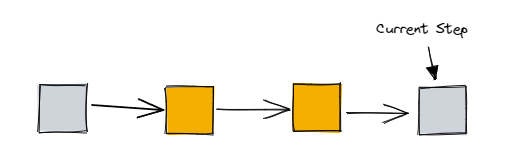
如果想要把這一系列步驟正確回滾,介面的呼叫順序如下:

但在排查一個問題時,我們發現使用者側的實際呼叫順序是這樣的:
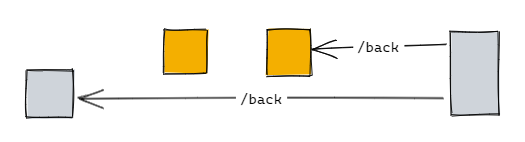
這便導致當中的某個 sub step 被略過,資料沒有被正常清除
而為什麼會出現這種情況?通過 Application Insights 我們發現,使用者在從點選選擇傳送回滾請求到伺服器接收到請求,存在12秒的網路延遲,實際程式碼只花費了 276ms 來處理這個請求
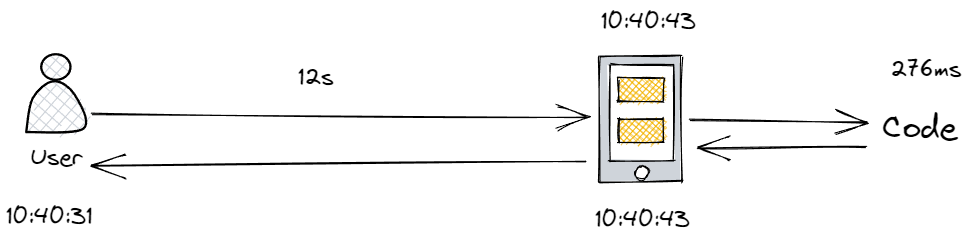
而恰好 UI 又允許使用者在等待請求的返回過程中選擇重新取消等待介面,重新點選傳送
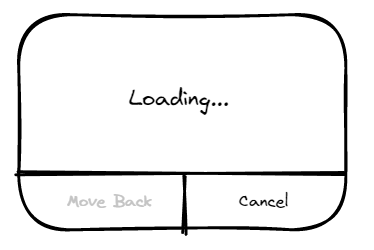
於是使用者在等待的過程中選擇不斷的重試
問題在哪
允許重試?
重試沒有罪,恰恰相反,重試是我們最重要的機制。服務不穩定是一個常態,重試可以幫助我們解決相當一部分問題。例如我在排查死鎖問題時,發現一旦死鎖給使用者帶來負面影響,使用者會選擇重新整理頁面「自助」解決問題
甚至重試是應該根植在我們程式碼中,無論前端還是後端,用於網路請求的 client 應該對於首次失敗的請求預設進行重試,無需額外的程式碼。
好的「基礎設施」(例如紀錄檔、鑑權、重試,以及這裡的重試)程式碼應該是毫無存在感的,很容易、甚至無意識的讓人做對很多事
關於重試策略,一篇來自 AWS 社群的文章非常值得我們參考《Timeouts, retries, and backoff with jitter》,重試時我們不僅需要加入 backoff(延遲) 和 jitter(波動) 引數,還需要考慮重試給伺服器帶來的壓力等情況
介面不夠冪等?
不同的 HTTP method 是自帶冪等屬性的,例如 GET 天然冪等,而 POST 天然就是不冪等的。對於採用 PUT method 的 back 介面而言,也許冪等性沒有做好。但是冪等性不是所有問題的擋箭牌。
想象這麼一個場景:假如我們有一個用於上傳特殊檔案的 POST 介面 A,和只有在檔案上傳成功之後才能工作的功能 B。如果 B 工作時只能允許有一份上傳成功的檔案存在,而這個時候又是因為網路原因導致使用者選擇上傳兩遍,那麼出錯的是誰?
- 使用者?使用者遲遲得不到反饋於是選擇重新上傳我不認為有什麼錯
- 介面?上傳檔案用的 POST 介面天生不就是不冪等的嗎?
除此之外冪等性也是需要代價的,在我看來一個冪等介面的完美實現可以參考這篇同樣是來自 AWS 的文章《Making retries safe with idempotent APIs》,他們在請求中加入了 unique client request identifier 作為
識別符號,用於後續服務判斷是否已經處理過相同的請求。
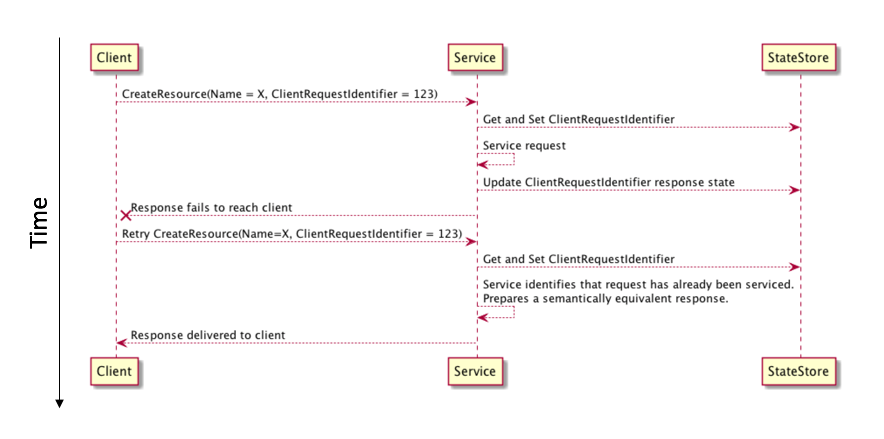
上面覆蓋的只是其中一類場景,實際的業務場景可能更復雜,例如要應對資源競爭的情況,如果想要了解更多介面的冪等實現,可以參考這篇文章《How to ensure idempotence》
使用者行為的冪等性
如何解決此類問題,尤其是在我們解決做解決方案的時候,需要注意保證使用者行為(或者說業務操作)的冪等性,而不是僅僅關注介面本身,因為一個操作通常是由多個請求,甚至前後端的配合同時完成的,例如一個 step 可不可以被回滾多次?假如一個回滾操作需要呼叫多個介面,部分成功會不會有任何的風險?
如何實現此類冪等性,我的建議是從以下這幾個維度考慮:
-
什麼都不做優於去做些什麼:我們是不是真的需要去保證冪等性?考慮到風險、概率、交付壓力,什麼都不做也是可以接受的
-
預防問題優於事後補救:優先考慮從輸入側解決問題,比如從前端 UI 上控制,或者介面入口處進行校驗。因為待問題出現之後再考慮修復資料的代價通常是不可控的,快速失敗很重要。
-
低成本優於高成本:如果真的要做冪等性校驗,我們是不是要做端到端的整套功能?大可不必。如果風險不大,我們可以只在紀錄檔中丟擲錯誤而不進行 UI 提示。某些校驗甚至可以通過建立資料庫約束來解決
-
轉移成本:GIGO (Garbage in, garbage out) 原則,不要嘗試去猜測並且修復使用者資料。校驗失敗之後我們可以把資料的修復工作交還給使用者。舉個不恰當的例子,假如某個後續功能需要與一個身份證件相關聯,程式碼如果發現了多個身份證件,我們應該丟擲的問題是:「我們發現了多個多個身份證件,請刪除額外的多個身份證件 再重試」,而不是「我們發現了 4 個多個身份證件,請問你需要選用哪一個?」
你可能也會喜歡:
- NodeJS 實戰系列:個人開發者應該如何選購雲服務
- NodeJS 實戰系列:模組設計與檔案分類
- NodeJS 實戰系列:DevOps 尚未解決的問題
- NodeJS 實戰系列:如何設計 try catch
- 做一個能對標阿里雲的前端APM工具(下)
- 做一個能對標阿里雲的前端APM工具(上)
- 小心 Serverless
- SQL Server 查詢語句優化入門
- 利用Node.js+express框實現圖片上傳
- 一篇來自前端同學對後端介面的吐槽
- 關於Node.js後端架構的一點後知後覺
- 在Node.js中搭建快取管理模組