OCR -- 文字檢測
目標檢測:
不僅要解決定位問題,還要解決目標分類問題,給定影象或者視訊,找出目標的位置(box),並給出目標的類別;

文字檢測:
給定輸入影象或者視訊,找出文字的區域,可以是單字元位置或者整個文字行位置;

檢測難點:
- 自然場景中文字具有多樣性:文字檢測受到文字顏色、大小、字型、形狀、方向、語言、以及文字長度的影響;
- 複雜的背景和干擾;文字檢測受到影象失真,模糊,低解析度,陰影,亮度等因素的影響;
- 文字密集甚至重疊會影響文字的檢測;
- 文字存在區域性一致性,文字行的一小部分,也可視為是獨立的文字;

檢測方法:
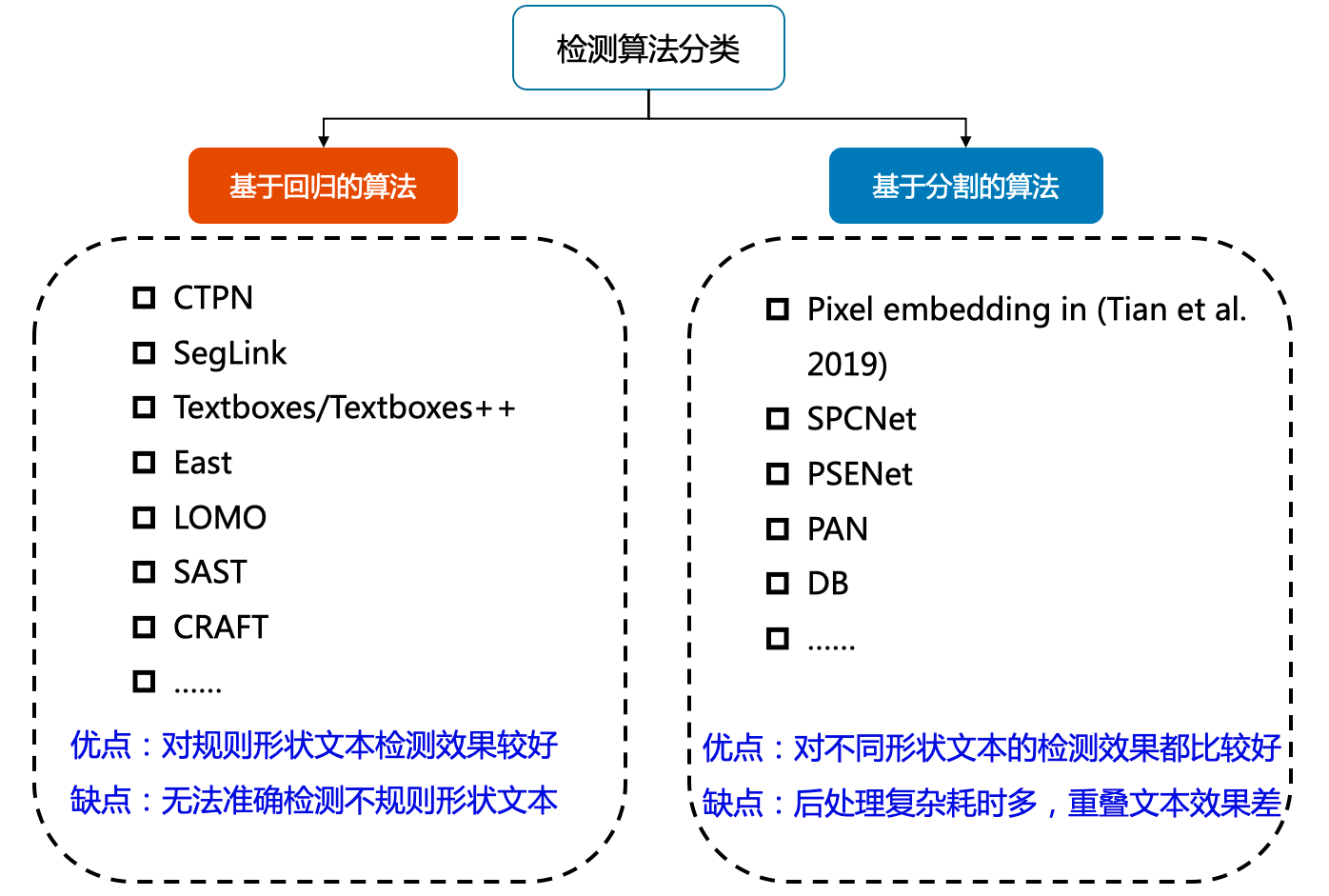
目前較為流行的文字檢測演演算法可以大致分為基於迴歸和基於分割的兩大類文字檢測演演算法
- 基於迴歸
優點:對規則形狀文字檢測效果較好
缺點:無法準確檢測不規則形狀文字 - 基於分割
優點:對不同形狀文字的檢測效果都比較好
缺點:後處理複雜耗時多,重疊文字效果差
基於迴歸的文字檢測
基於迴歸文字檢測方法和目標檢測演演算法的方法相似,文字檢測方法只有兩個類別,影象中的文字視為待檢測的目標,其餘部分視為背景。
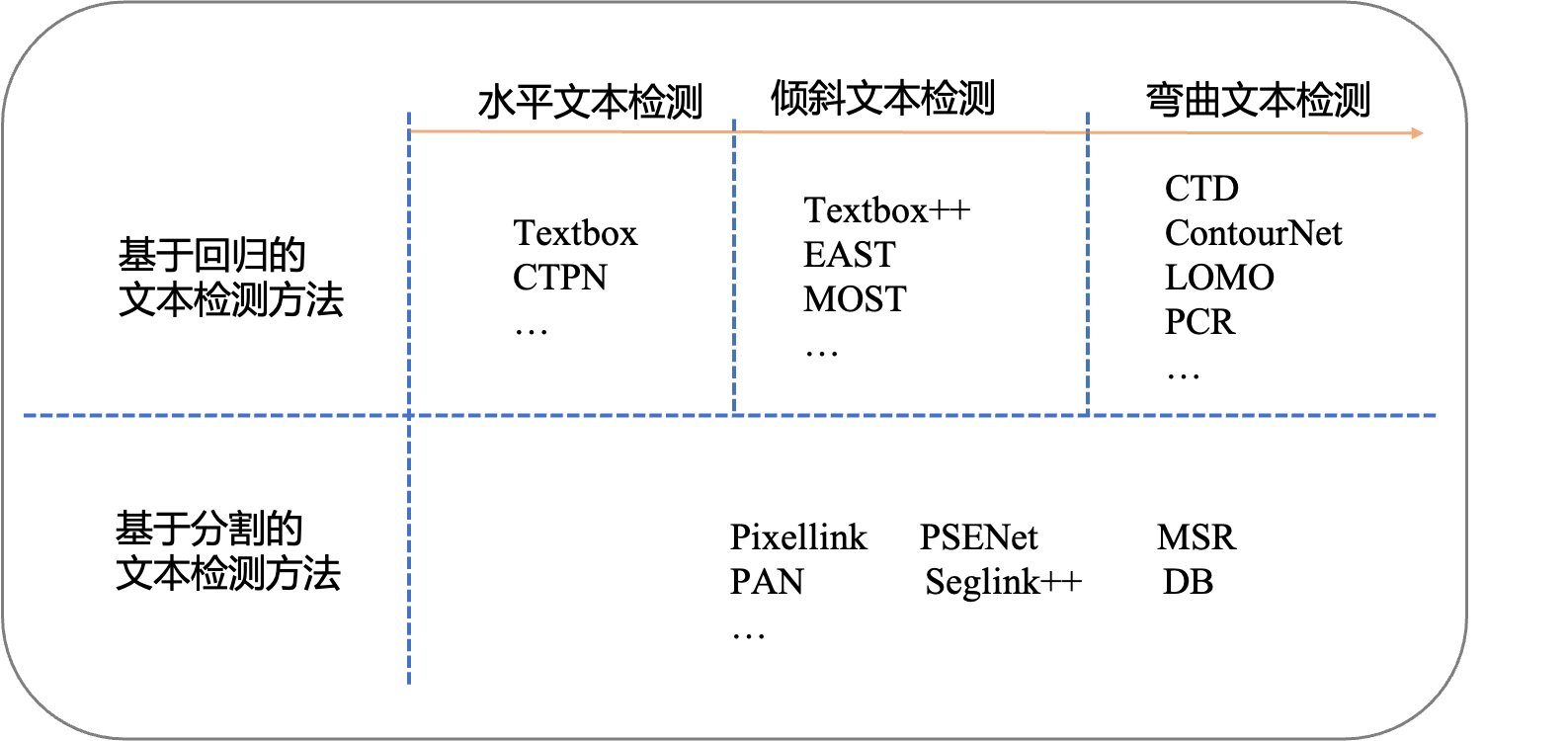
水平文字檢測
早期基於深度學習的文字檢測演演算法是從目標檢測的方法改進而來,支援水平文字檢測。比如Textbox演演算法基於SSD (Single Shot MultiBox Detector)演演算法改進而來,CTPN (connection text proposal network)根據二階段目標檢測Fast-RCNN演演算法改進而來。
TextBoxes 演演算法根據一階段目標檢測器SSD調整,將預設文字方塊更改為適應文字方向和寬高比的規格的四邊形,提供了一種端對端訓練的文字檢測方法,並且無需複雜的後處理。
- 採用更大長寬比的預選框
- 折積核從3x3變成了1x5,更適合長文字檢測
- 採用多尺度輸入
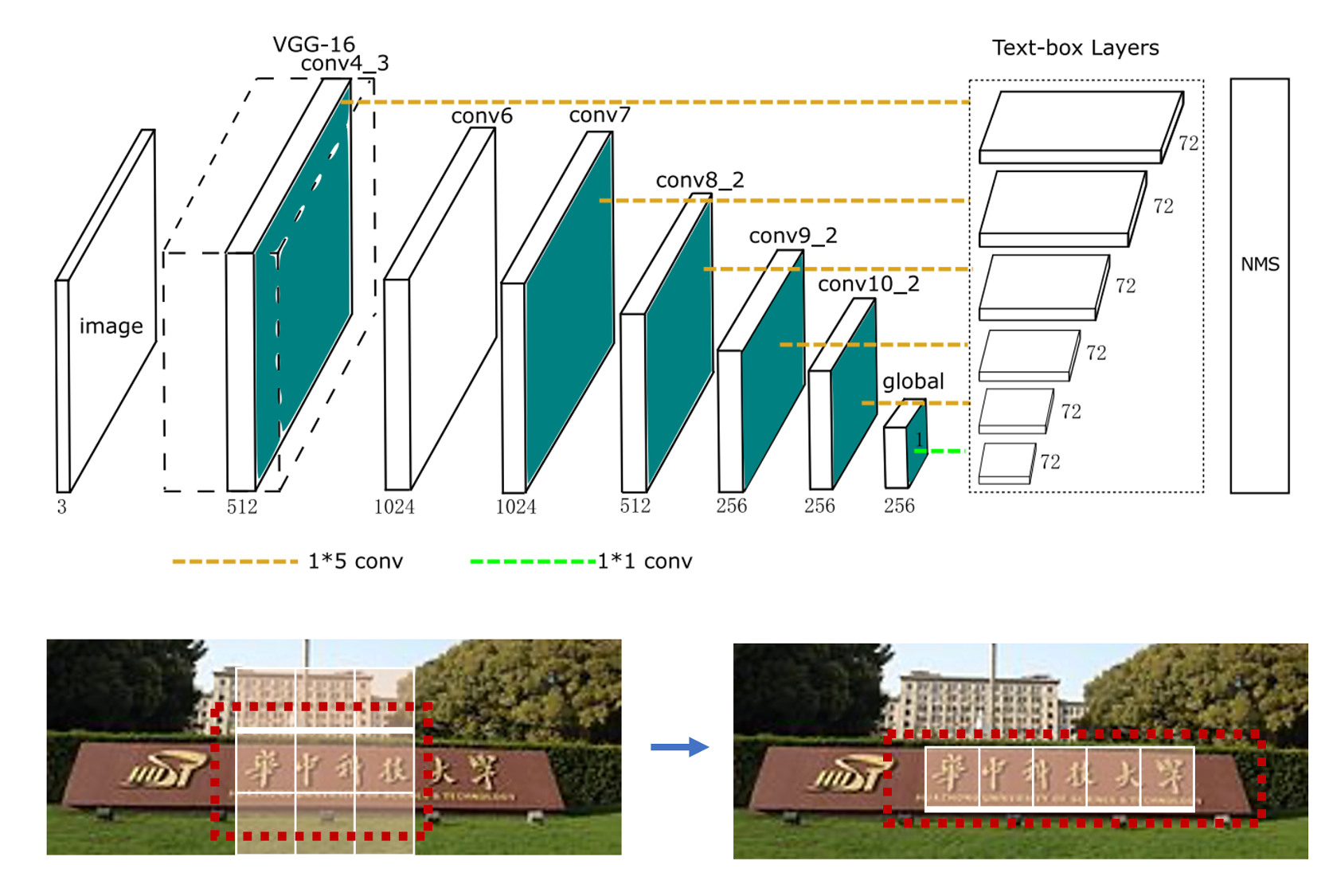
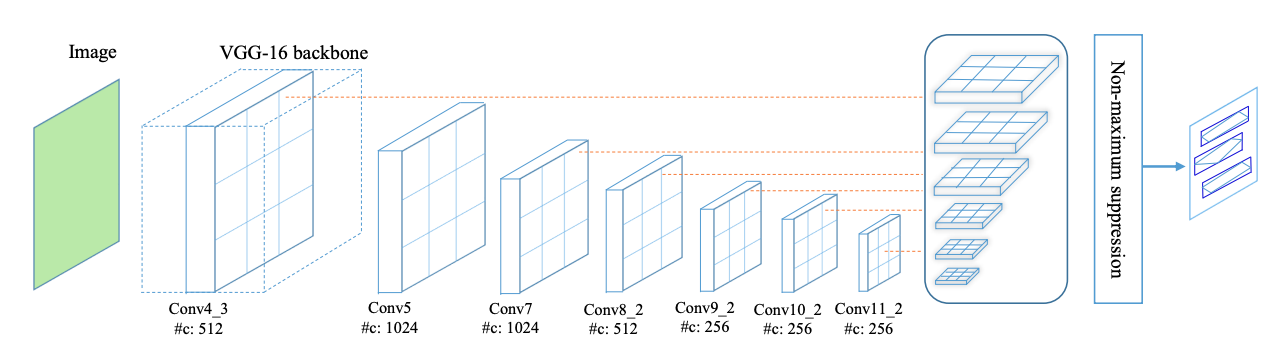
TextBoxes整體網路結構如圖1所示,在VGG-16的基礎上新增9個額外的折積層,共28層,類似於SSD,在不同的層之後都有輸出層,稱之為 text-box layers, text-box layers的輸出通道是72(2個通道預測分數,4個通道預測位置偏移量,共12個anchor(這裡說的anchor就是SSD中講的default box),所以共(2+4)*12=72個通道),整合所有的 text-box layers的輸出結果後再使用 NMS (non maximum suppression - 即非極大值抑制) 處理,就得到了最終的結果。
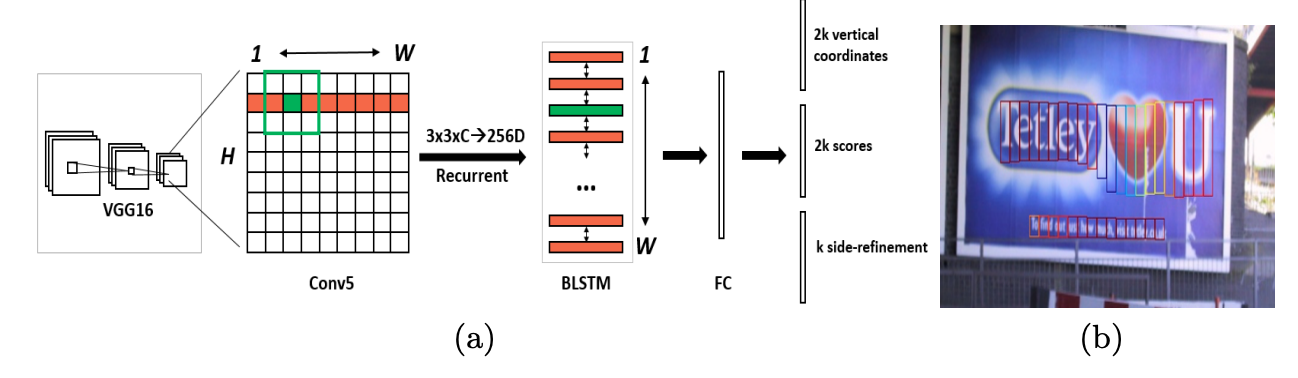
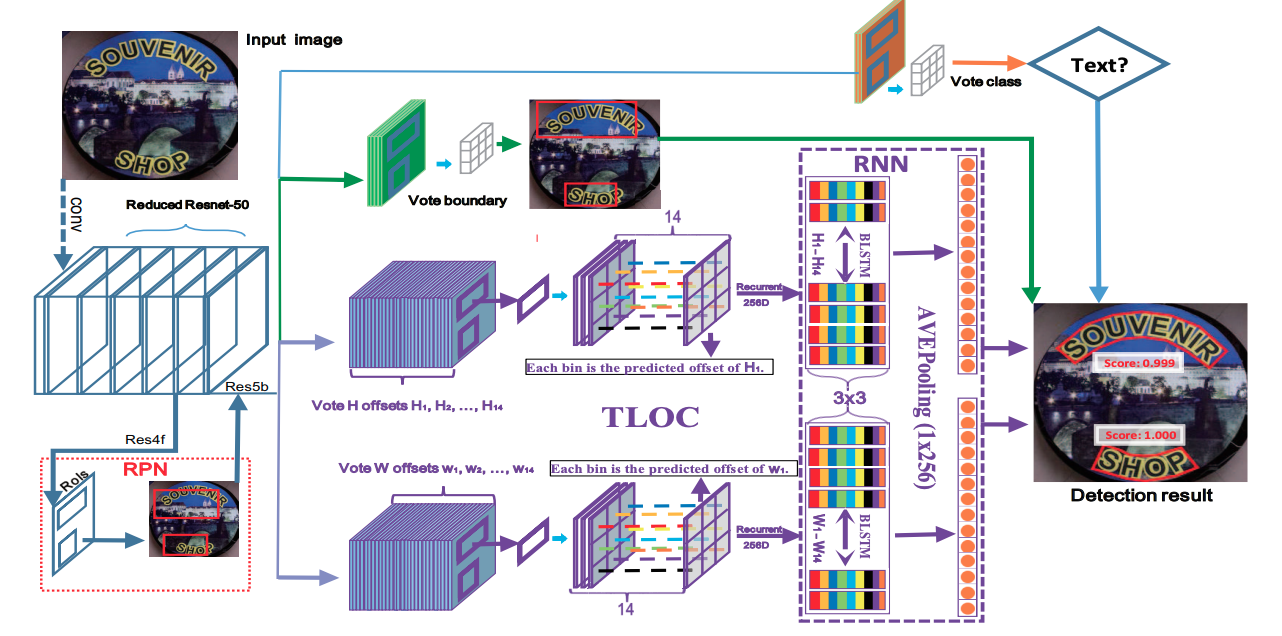
CTPN 基於Fast-RCNN 演演算法,擴充套件RPN模組並且設計了基於CRNN的模組讓整個網路從折積特徵中檢測到文字序列,二階段的方法通過ROI Pooling獲得了更準確的特徵定位。但是TextBoxes和CTPN只支援檢測橫向文字。
任意角度文字檢測
TextBoxes++ 在TextBoxes基礎上進行改進,支援檢測任意角度的文字。從結構上來說,不同於TextBoxes,TextBoxes++針對多角度文字進行檢測,首先修改預選框的寬高比,調整寬高比aspect ratio為1、2、3、5、1/2、1/3、1/5。其次是將
\(1∗5\)的折積核改為 \(3∗5\),更好的學習傾斜文字的特徵;最後,TextBoxes++ 的輸出旋轉框的表示資訊。
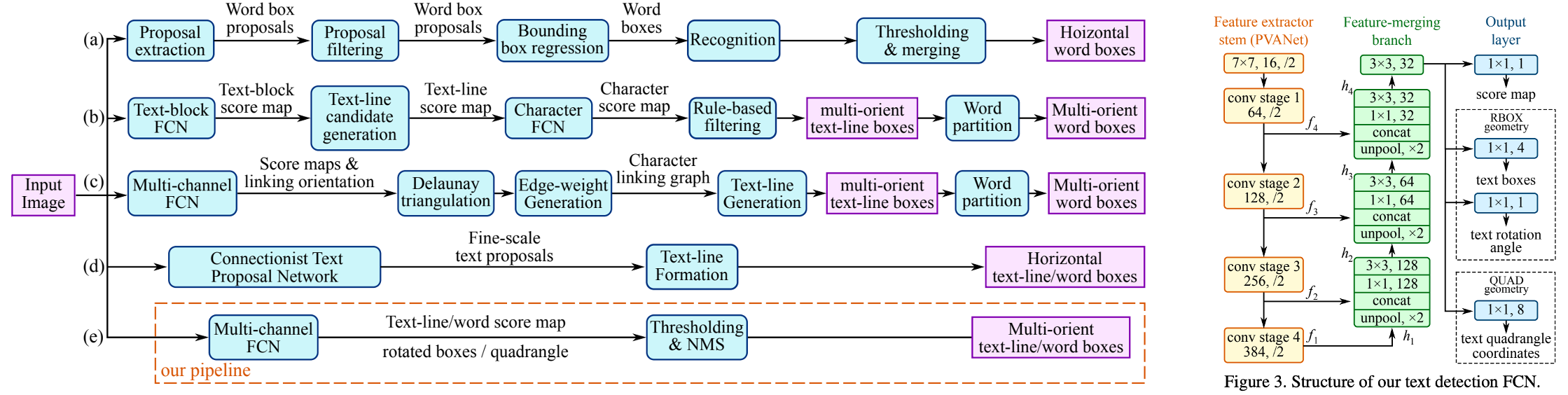
EAST 針對傾斜文字的定位問題,提出了two-stage的文字檢測方法,包含 FCN特徵提取和NMS部分。EAST提出了一種新的文字檢測pipline結構,可以端對端訓練並且支援檢測任意朝向的文字,並且具有結構簡單,效能高的特點。FCN支援輸出傾斜的矩形框和水平框,可以自由選擇輸出格式。
- 如果輸出檢測形狀為RBox,則輸出Box旋轉角度以及AABB文字形狀資訊,AABB表示到文字方塊上下左右邊的偏移。RBox可以旋轉矩形的文字。
- 如果輸出檢測框為四點框,則輸出的最後一個維度為8個數位,表示從四邊形的四個角頂點的位置偏移。該輸出方式可以預測不規則四邊形的文字。
考慮到FCN輸出的文字方塊是比較冗餘的,比如一個文字區域的鄰近的畫素生成的框重合度較高,但不是同一個文字生成的檢測框,重合度都很小,因此EAST提出先按行合併預測框,最後再把剩下的四邊形用原始的NMS篩選。
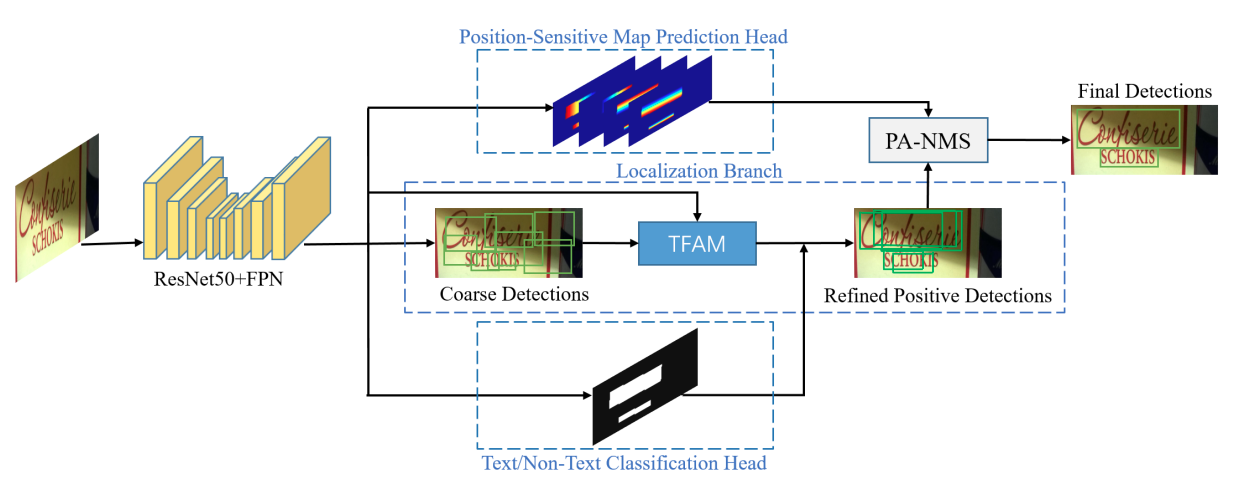
MOST 提出TFAM模組動態的調整粗粒度的檢測結果的感受野,另外提出PA-NMS根據位置資訊合併可靠的檢測預測結果。此外,訓練中還提出 Instance-wise IoU 損失函數,用於平衡訓練,以處理不同尺度的文字範例。該方法可以和EAST方法結合,在檢測極端長寬比和不同尺度的文字有更好的檢測效果和效能。
彎曲文字檢測
利用迴歸的方法解決彎曲文字的檢測問題,一個簡單的思路是用多點座標描述彎曲文字的邊界多邊形,然後直接預測多邊形的頂點座標
CTD 提出了直接預測彎曲文字14個頂點的邊界多邊形,網路中利用Bi-LSTM 層以細化頂點的預測座標,實現了基於迴歸方法的彎曲文字檢測。
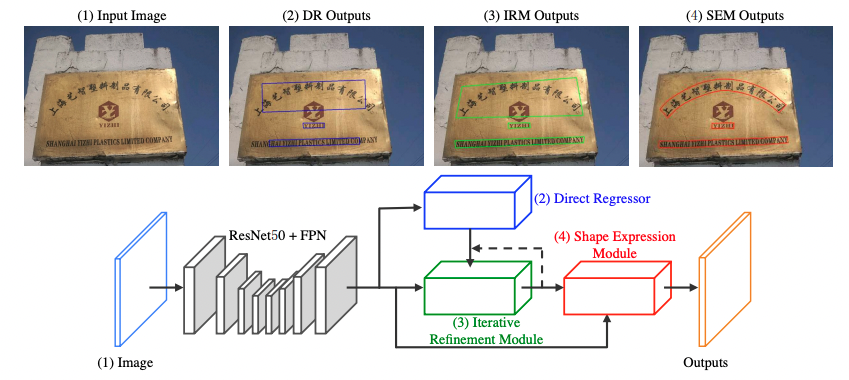
LOMO 針對長文字和彎曲文字問題,提出迭代的優化文字定位特徵獲取更精細的文字定位,該方法包括三個部分,座標迴歸模組DR,迭代優化模組IRM以及任意形狀表達模組SEM。分別用於生成文字大致區域,迭代優化文字定位特徵,預測文字區域、文字中心線以及文字邊界。迭代的優化文字特徵可以更好的解決長文字定位問題以及獲得更精確的文字區域定位。
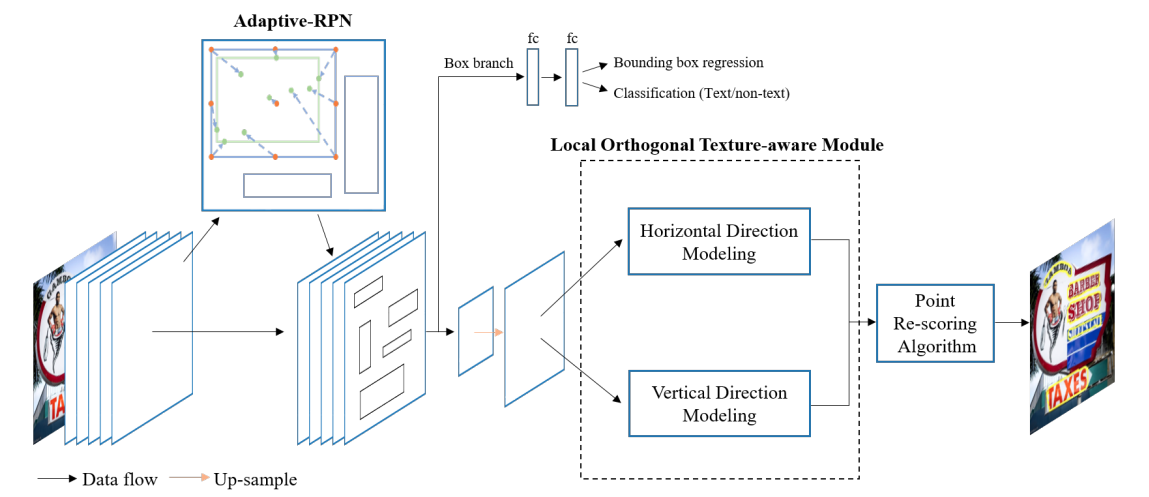
Contournet 基於提出對文字輪廓點建模獲取彎曲文字檢測框,該方法首先使用Adaptive-RPN獲取文字區域的proposal特徵,然後設計了區域性正交紋理感知LOTM模組學習水平與豎直方向的紋理特徵,並用輪廓點表示,最後,通過同時考慮兩個正交方向上的特徵響應,利用Point Re-Scoring演演算法可以有效地濾除強單向或弱正交啟用的預測,最終文字輪廓可以用一組高質量的輪廓點表示出來。
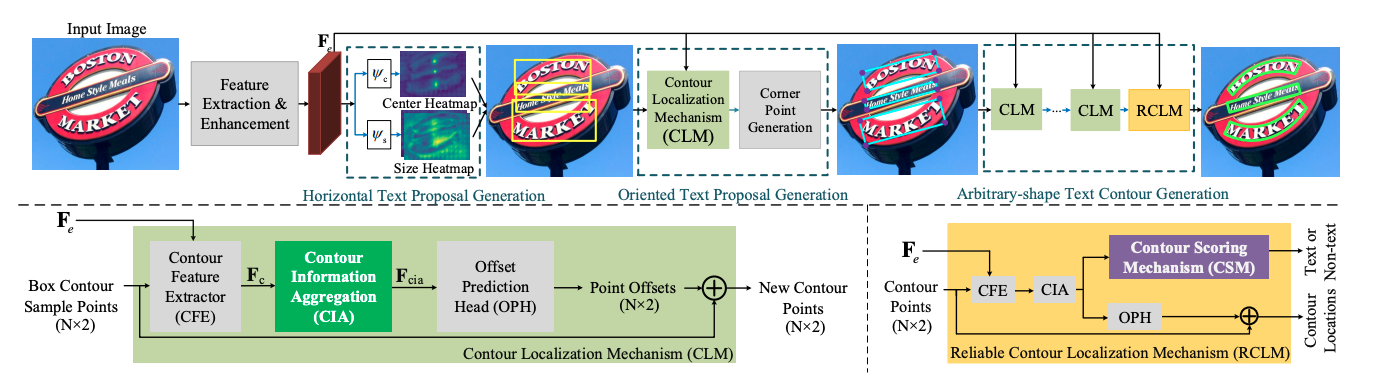
PCR 提出漸進式的座標迴歸處理彎曲文字檢測問題,總體分為三個階段,首先大致檢測到文字區域,獲得文字方塊,另外通過所設計的Contour Localization Mechanism預測文字最小包圍框的角點座標,然後通過疊加多個CLM模組和RCLM模組預測得到彎曲文字。該方法利用文字輪廓資訊聚合得到豐富的文字輪廓特徵表示,不僅能抑制冗餘的噪聲點對座標迴歸的影響,還能更精確的定位文字區域。
基於分割的文字檢測
基於迴歸的方法雖然在文字檢測上取得了很好的效果,但是對解決彎曲文字往往難以得到平滑的文字包圍曲線,並且模型較為複雜不具備效能優勢。於是研究者們提出了基於影象分割的文字分割方法,先從畫素層面做分類,判別每一個畫素點是否屬於一個文字目標,得到文字區域的概率圖,通過後處理方式得到文字分割區域的包圍曲線。
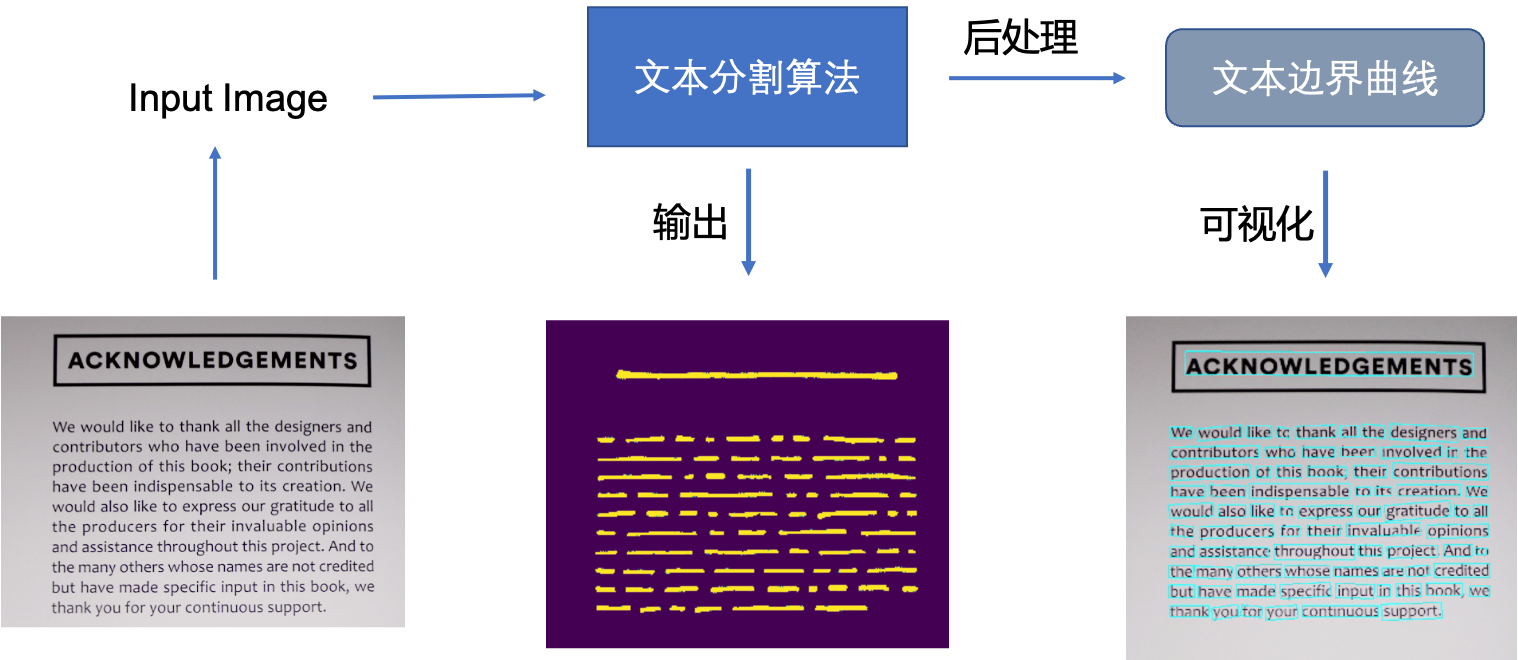
此類方法通常是基於分割的方法實現文字檢測,基於分割的方法對不規則形狀的文字檢測有著天然的優勢。基於分割的文字檢測方法主體思想為,通過分割方法得到影象中文字區域,再利用opencv,polygon等後處理得到文字區域的最小包圍曲線。
Pixellink採用分割的方法解決文字檢測問題,分割物件為文字區域,將同屬於一個文字行(單詞)中的畫素連結在一起來分割文字,直接從分割結果中提取文字邊界框,無需位置迴歸就能達到基於迴歸的文字檢測的效果。但是基於分割的方法存在一個問題,對於位置相近的文字,文字分割區域容易出現「粘連「問題。Wu, Yue等人提出分割文字的同時,學習文字的邊界位置,用於更好的區分文字區域。另外Tian等人提出將同一文字的畫素對映到對映空間,在對映空間中令統一文字的對映向量距離相近,不同文字的對映向量距離變遠。
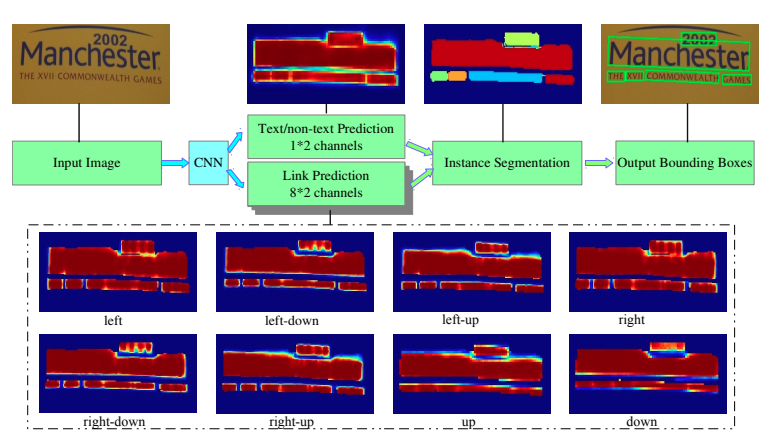
MSR 針對文字檢測的多尺度問題,提出提取相同影象的多個scale的特徵,然後將這些特徵融合並上取樣到原圖尺寸,網路最後預測文字中心區域、文字中心區域每個點到最近的邊界點的x座標偏移和y座標偏移,最終可以得到文字區域的輪廓座標集合。
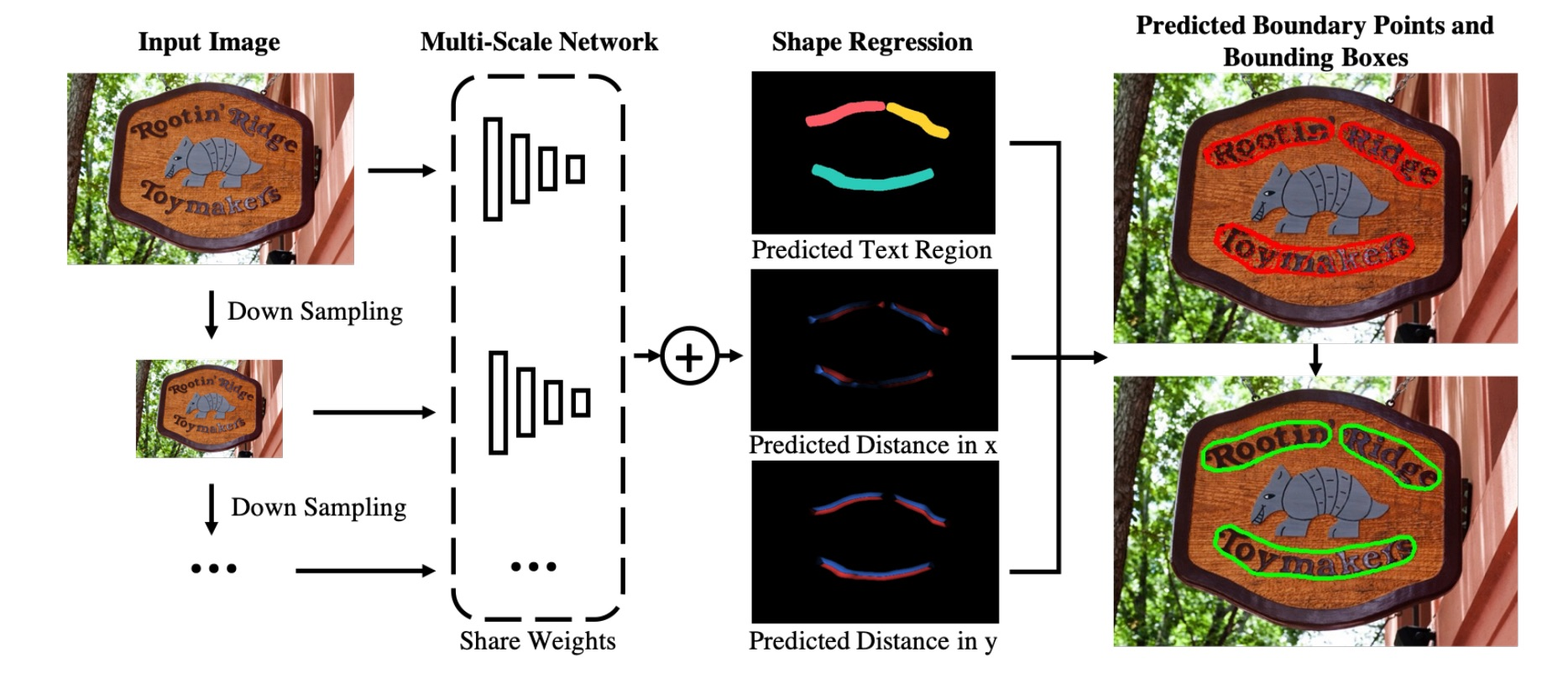
針對基於分割的文字演演算法難以區分相鄰文字的問題,PSENet 提出漸進式的尺度擴張網路學習文字分割區域,預測不同收縮比例的文字區域,並逐個擴大檢測到的文字區域,該方法本質上是邊界學習方法的變體,可以有效解決任意形狀相鄰文字的檢測問題。
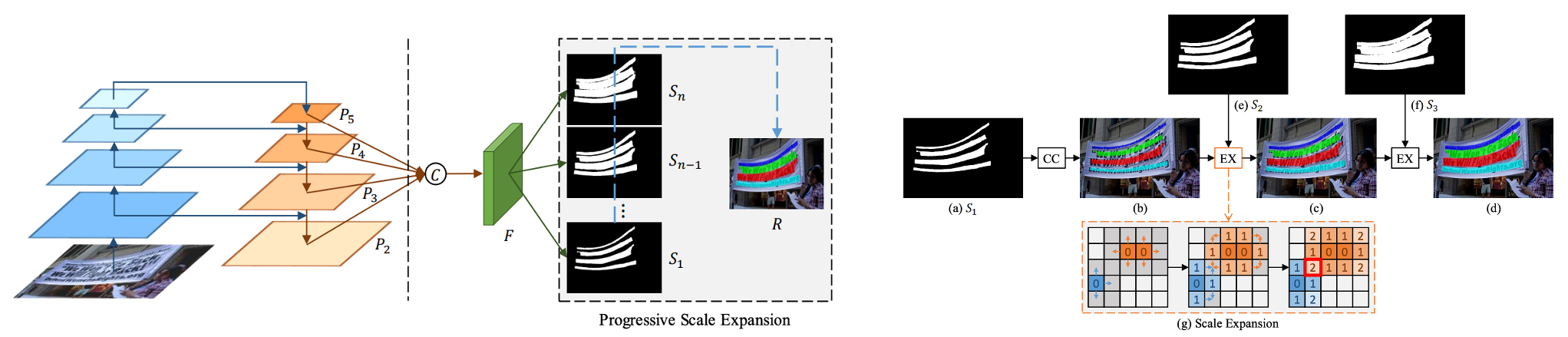
假設用了PSENet後處理用了3個不同尺度的kernel,如上圖s1,s2,s3所示。首先,從最小kernel s1開始,計算文字分割區域的連通域,得到(b),然後,對連通域沿著上下左右做尺度擴張,對於擴張區域屬於s2但不屬於s1的畫素,進行歸類,遇到衝突點時,採用「先到先得」原則,重複尺度擴張的操作,最終可以得到不同文字行的獨立的分割區域。
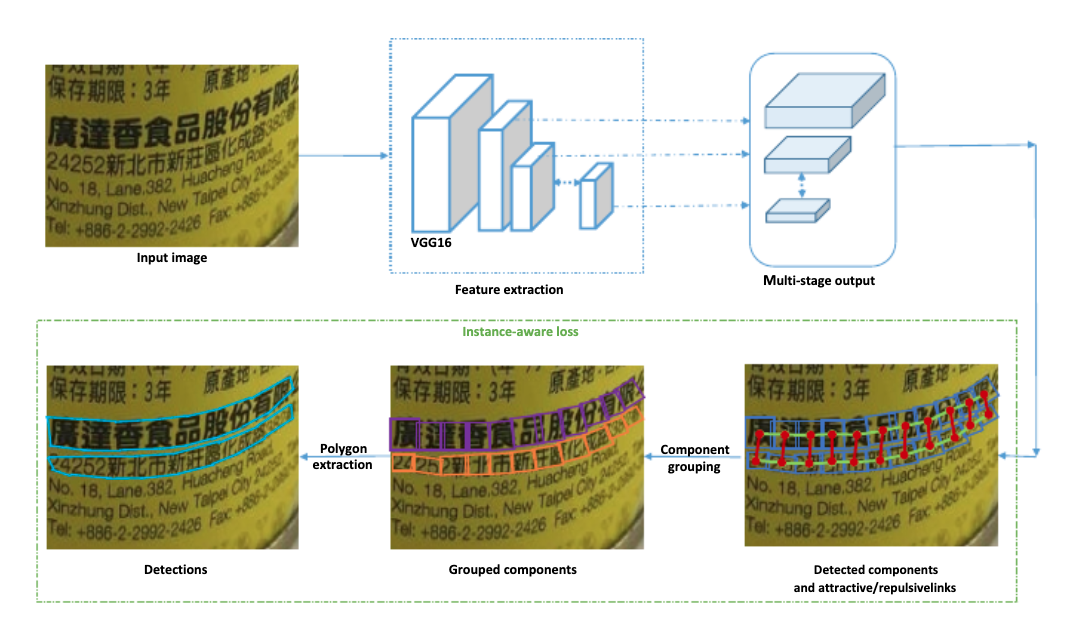
Seglink++ 針對彎曲文字和密集文字問題,提出了一種文字塊單元之間的吸引關係和排斥關係的表徵,然後設計了一種最小生成樹演演算法進行單元組合得到最終的文字檢測框,並提出instance-aware 損失函數使Seglink++方法可以端對端訓練。
雖然分割方法解決了彎曲文字的檢測問題,但是複雜的後處理邏輯以及預測速度也是需要優化的目標。
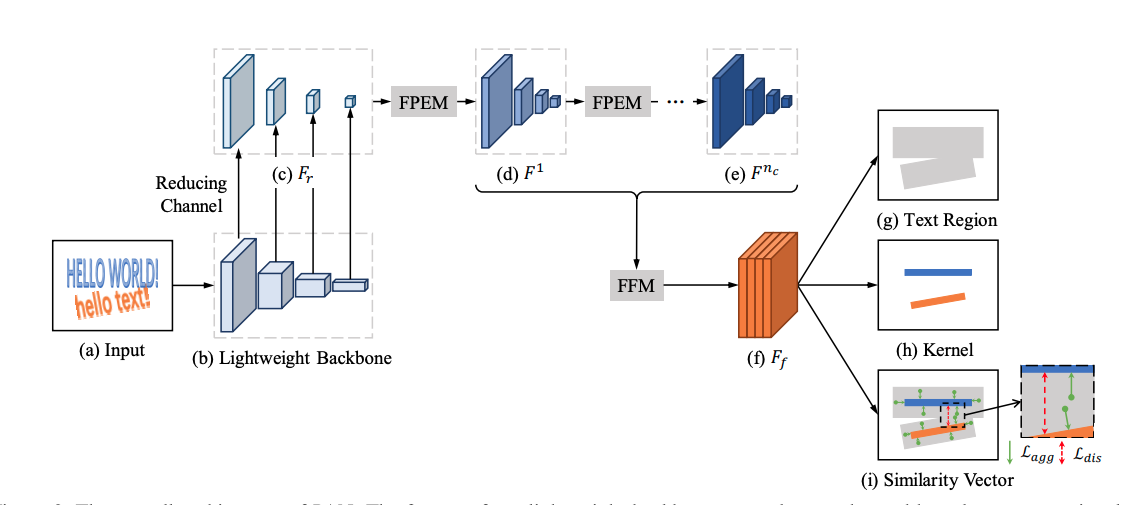
PAN 針對文字檢測預測速度慢的問題,從網路設計和後處理方面進行改進,提升演演算法效能。首先,PAN使用了輕量級的ResNet18作為Backbone,另外設計了輕量級的特徵增強模組FPEM和特徵融合模組FFM增強Backbone提取的特徵。在後處理方面,採用畫素聚類方法,沿著預測的文字中心(kernel)四周合併與kernel的距離小於閾值d的畫素。PAN保證高精度的同時具有更快的預測速度。
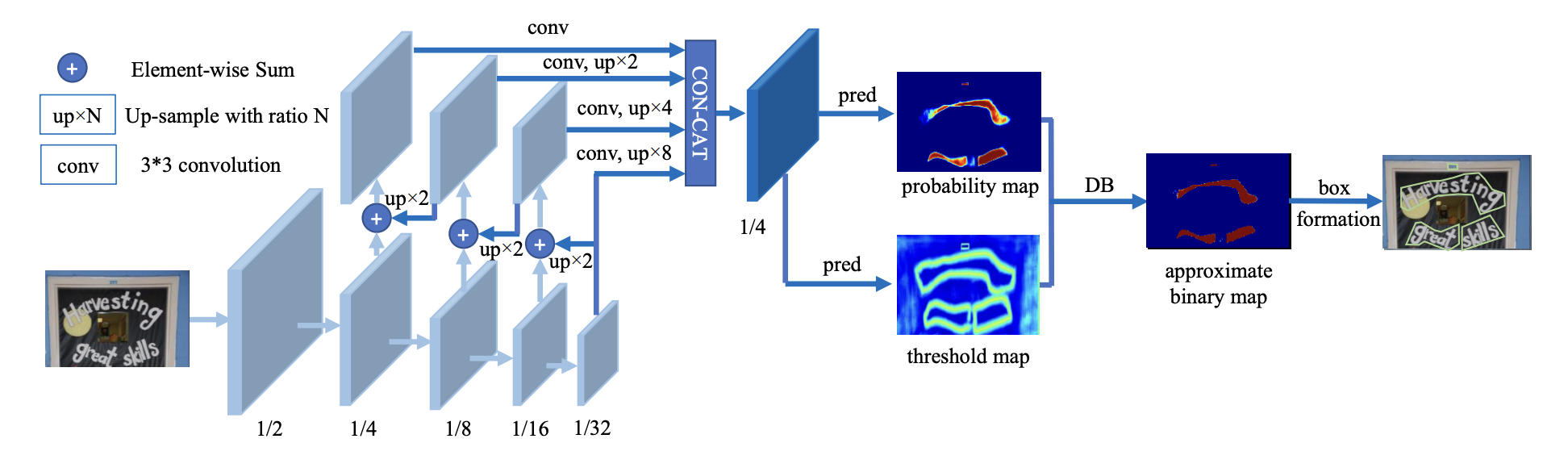
DBNet 針對基於分割的方法需要使用閾值進行二值化處理而導致後處理耗時的問題,提出了可學習閾值並巧妙地設計了一個近似於階躍函數的二值化函數,使得分割網路在訓練的時候能端對端的學習文字分割的閾值。自動調節閾值不僅帶來精度的提升,同時簡化了後處理,提高了文字檢測的效能。
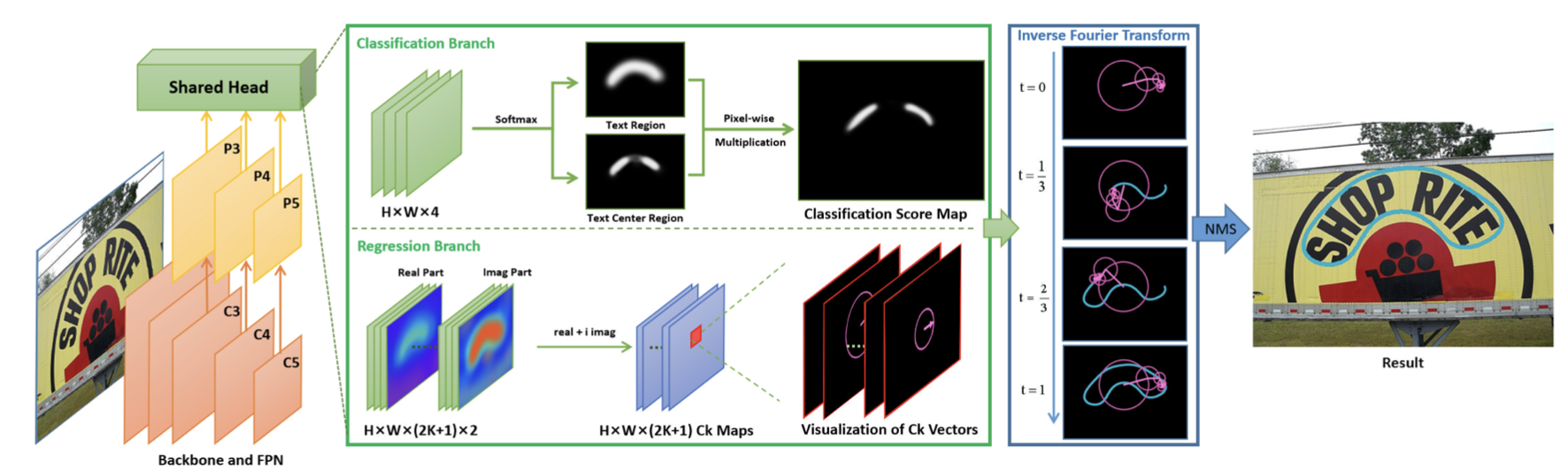
FCENet 提出將文字包圍曲線用傅立葉變換的參數列示,由於傅立葉係數表示在理論上可以擬合任意的封閉曲線,通過設計合適的模型預測基於傅立葉變換的任意形狀文字包圍框表示,從而實現了自然場景文字檢測中對於高度彎曲文字範例的檢測精度的提升。
程式碼範例
視覺化文字檢測預測
# 1. 從paddleocr中import PaddleOCR類
from paddleocr import PaddleOCR
import numpy as np
import cv2
import matplotlib.pyplot as plt
# 2. 宣告PaddleOCR類
ocr = PaddleOCR()
img_path = './PaddleOCR/doc/imgs/12.jpg'
# 3. 執行預測
result = ocr.ocr(img_path, rec=False)
print(f"The predicted text box of {img_path} are follows.")
print(result)
# 4. 視覺化檢測結果
image = cv2.imread(img_path)
boxes = [line[0] for line in result]
for box in result:
box = np.reshape(np.array(box), [-1, 1, 2]).astype(np.int64)
image = cv2.polylines(np.array(image), [box], True, (255, 0, 0), 2)
# 畫出讀取的圖片
plt.figure(figsize=(10, 10))
plt.imshow(image)
DB文字檢測模型構建
DB文字檢測模型可以分為三個部分:
- Backbone網路,負責提取影象的特徵
- FPN網路,特徵金字塔結構增強特徵
- Head網路,計算文字區域概率圖
# 首次執行需要開啟下一行的註釋,下載PaddleOCR程式碼
#!git clone https://gitee.com/paddlepaddle/PaddleOCR
# 安裝PaddleOCR第三方依賴
!pip install --upgrade pip
!pip install -r requirements.txt
backbone網路
DB文字檢測網路的Backbone部分採用的是影象分類網路,論文中使用了ResNet50
import os
# 加快訓練速度,採用MobileNetV3 large結構作為backbone。
from ppocr.modeling.backbones.det_mobilenet_v3 import MobileNetV3
import paddle
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
# 1. 宣告Backbone
model_backbone = MobileNetV3()
model_backbone.eval()
# 2. 執行預測
outs = model_backbone(fake_inputs)
# 3. 列印網路結構
print(model_backbone)
# 4. 列印輸出特徵形狀
for idx, out in enumerate(outs):
print("The index is ", idx, "and the shape of output is ", out.shape)
FPN網路
特徵金字塔結構FPN是一種折積網路來高效提取圖片中各維度特徵的常用方法。
FPN網路的輸入為Backbone部分的輸出,輸出特徵圖的高度和寬度為原圖的四分之一,假設輸入影象的形狀為[1, 3, 640, 640],FPN輸出特徵的高度和寬度為[160, 160]
import paddle
# 1. 從PaddleOCR中import DBFPN
from ppocr.modeling.necks.db_fpn import DBFPN
# 2. 獲得Backbone網路輸出結果
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
model_backbone = MobileNetV3()
in_channles = model_backbone.out_channels
# 3. 宣告FPN網路
model_fpn = DBFPN(in_channels=in_channles, out_channels=256)
# 4. 列印FPN網路
print(model_fpn)
# 5. 計算得到FPN接面果輸出
outs = model_backbone(fake_inputs)
fpn_outs = model_fpn(outs)
# 6. 列印FPN輸出特徵形狀
print(f"The shape of fpn outs {fpn_outs.shape}")
Head網路
計算文字區域概率圖,文字區域閾值圖以及文字區域二值圖。
DB Head網路會在FPN特徵的基礎上作上取樣,將FPN特徵由原圖的四分之一大小對映到原圖大小。
# 1. 從PaddleOCR中imort DBHead
from ppocr.modeling.heads.det_db_head import DBHead
import paddle
# 2. 計算DBFPN網路輸出結果
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
model_backbone = MobileNetV3()
in_channles = model_backbone.out_channels
model_fpn = DBFPN(in_channels=in_channles, out_channels=256)
outs = model_backbone(fake_inputs)
fpn_outs = model_fpn(outs)
# 3. 宣告Head網路
model_db_head = DBHead(in_channels=256)
# 4. 列印DBhead網路
print(model_db_head)
# 5. 計算Head網路的輸出
db_head_outs = model_db_head(fpn_outs)
print(f"The shape of fpn outs {fpn_outs.shape}")
print(f"The shape of DB head outs {db_head_outs['maps'].shape}")
參照:https://aistudio.baidu.com/aistudio/projectdetail/6232311