聊聊分散式 SQL 資料庫Doris(九)
優化器的作用是優化查詢語句的執行效率,它通過評估不同的執行計劃並選擇最優的執行計劃來實現這一目標。
CBO: 一種基於成本的優化器,它通過評估不同查詢執行計劃的成本來選擇最優的執行計劃。CBO會根據資料庫系統定義的統計資訊以及其他因素,對不同的執行計劃進行評估,並選擇成本最低的執行計劃。CBO的目標是找到一個最優的執行計劃,使得查詢的執行成本最低。
RBO: 一種基於規則的優化器,它通過應用一系列的優化規則來選擇最優的執行計劃。RBO會根據預定義的規則對查詢進行優化,這些規則基於資料庫系統的特定邏輯和語意。RBO的優點是實現簡單,適用於特定的查詢模式和資料分佈。然而,RBO可能無法找到最優的執行計劃,特別是對於複雜的查詢和大規模的資料集。
Doris主要整合了Google Mesa(資料模型),Apache Impala(MPP查詢引擎)和Apache ORCFile (儲存格式,編碼和壓縮) 的技術。 Doris的查詢優化器則是基於Impala改造實現的。Doris官方提供的 Nereids優化器 檔案。
優化器元件
查詢優化器由多個部分組成,分別是: 詞法語法解析、語意解析、query改寫、生成執行計劃。最後這步根據演演算法實現與業務場景的不同會有些許差異。
詞法語法解析
這個步驟,其實是做兩件事情,首先是解析SQL文字,提取關鍵字出來,比如(select、from等); 然後分析SQL文字是否滿足SQL語法,最終生成一個AST樹。其結構如下:
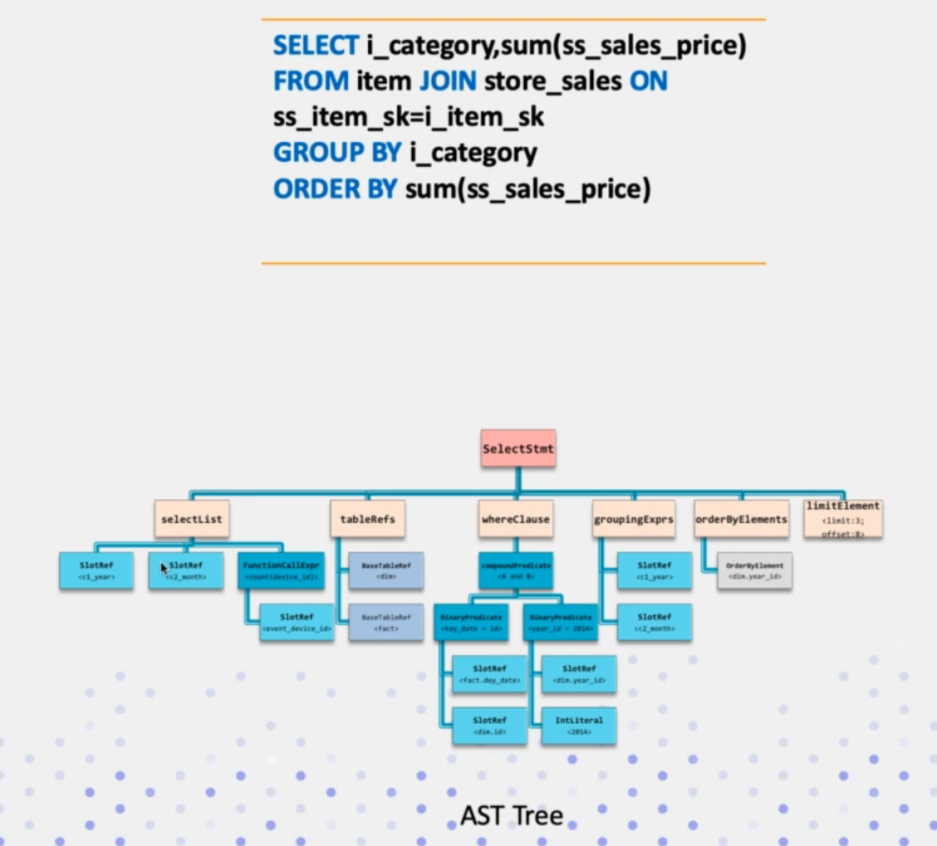
對於不同型別的SQL,其語法樹的根節點型別也是不一樣的。一般是InsertStmt、UpdateStmt、DeleteStmt、SelectStmt等。而這些概念其實是impala中的,Doris的SQL查詢引擎是參考自impala。在其原始碼中有這麼一段註釋:
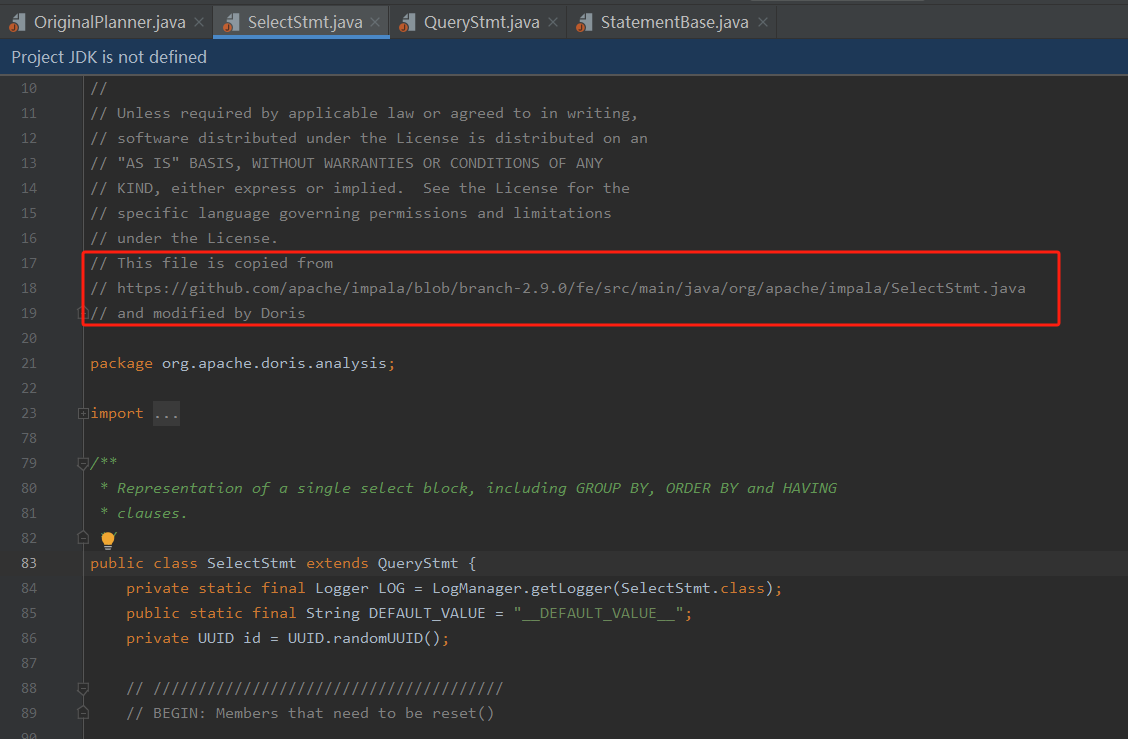
Impala是用於處理儲存在Hadoop叢集中的大量資料的MPP(大規模並行處理)sql查詢引擎。 它是一個用C ++和Java編寫的開源軟體。 與其他Hadoop的SQL引擎相比,它提供了高效能和低延遲。其相關資訊及檔案可參考: impala中文手冊
語意解析
根據AST樹與後設資料中的表、列資訊等做一個語意校驗,比如,表、欄位是否在後設資料中存在。其步驟一般如下:
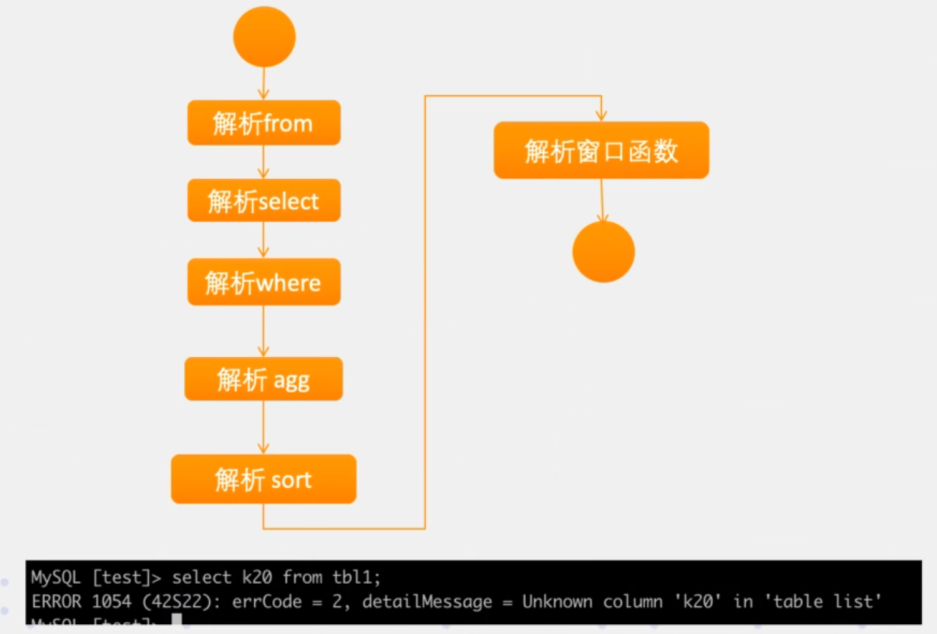
query改寫
對原始的sql文字做一定程度的改寫使得SQL更簡單,執行效率更高;一般是條件表示式改寫、子查詢改寫等。
在Doris中,有一個介面 ExprRewriteRule 負責表示式的改寫規則,基於該介面與各種不同的規則有不同的實現,在 Analyzer類的內部類 GlobalState 建構函式中,註冊了諸多的規則到rules集合中,而該list會被傳遞到ExprRewriter類中被應用。
StmtRewriter 類處理子查詢改寫邏輯,其中的方法會處理各種場景下的子查詢改寫,比如rewriteSelectStatement方法.
這一步驟的處理是基於詞法語法解析後生成的AST樹進行的。
public class GlobalState(Env env, ConnectContext context) {
this.env = env;
this.context = context;
List<ExprRewriteRule> rules = Lists.newArrayList();
// BetweenPredicates must be rewritten to be executable. Other non-essential
// expr rewrites can be disabled via a query option. When rewrites are enabled
// BetweenPredicates should be rewritten first to help trigger other rules.
rules.add(BetweenToCompoundRule.INSTANCE);
// Binary predicates must be rewritten to a canonical form for both predicate
// pushdown and Parquet row group pruning based on min/max statistics.
rules.add(NormalizeBinaryPredicatesRule.INSTANCE);
// Put it after NormalizeBinaryPredicatesRule, make sure slotRef is on the left and Literal is on the right.
rules.add(RewriteBinaryPredicatesRule.INSTANCE);
rules.add(RewriteImplicitCastRule.INSTANCE);
rules.add(RoundLiteralInBinaryPredicatesRule.INSTANCE);
rules.add(FoldConstantsRule.INSTANCE);
rules.add(EraseRedundantCastExpr.INSTANCE);
rules.add(RewriteFromUnixTimeRule.INSTANCE);
rules.add(CompoundPredicateWriteRule.INSTANCE);
rules.add(RewriteDateLiteralRule.INSTANCE);
rules.add(RewriteEncryptKeyRule.INSTANCE);
rules.add(RewriteInPredicateRule.INSTANCE);
rules.add(RewriteAliasFunctionRule.INSTANCE);
rules.add(RewriteIsNullIsNotNullRule.INSTANCE);
rules.add(MatchPredicateRule.INSTANCE);
rules.add(EliminateUnnecessaryFunctions.INSTANCE);
List<ExprRewriteRule> onceRules = Lists.newArrayList();
onceRules.add(ExtractCommonFactorsRule.INSTANCE);
onceRules.add(InferFiltersRule.INSTANCE);
exprRewriter = new ExprRewriter(rules, onceRules);
// init mv rewriter
List<ExprRewriteRule> mvRewriteRules = Lists.newArrayList();
mvRewriteRules.add(new ExprToSlotRefRule());
mvRewriteRules.add(ToBitmapToSlotRefRule.INSTANCE);
mvRewriteRules.add(CountDistinctToBitmapOrHLLRule.INSTANCE);
mvRewriteRules.add(CountDistinctToBitmap.INSTANCE);
mvRewriteRules.add(NDVToHll.INSTANCE);
mvRewriteRules.add(HLLHashToSlotRefRule.INSTANCE);
mvExprRewriter = new ExprRewriter(mvRewriteRules);
// context maybe null. eg, for StreamLoadPlanner.
// and autoBroadcastJoinThreshold is only used for Query's DistributedPlanner.
// so it is ok to not set autoBroadcastJoinThreshold if context is null
if (context != null) {
// compute max exec mem could be used for broadcast join
long perNodeMemLimit = context.getSessionVariable().getMaxExecMemByte();
double autoBroadcastJoinThresholdPercentage = context.getSessionVariable().autoBroadcastJoinThreshold;
if (autoBroadcastJoinThresholdPercentage > 1) {
autoBroadcastJoinThresholdPercentage = 1.0;
} else if (autoBroadcastJoinThresholdPercentage <= 0) {
autoBroadcastJoinThresholdPercentage = -1.0;
}
autoBroadcastJoinThreshold = (long) (perNodeMemLimit * autoBroadcastJoinThresholdPercentage);
} else {
// autoBroadcastJoinThreshold is a "final" field, must set an initial value for it
autoBroadcastJoinThreshold = 0;
}
}
單機執行計劃
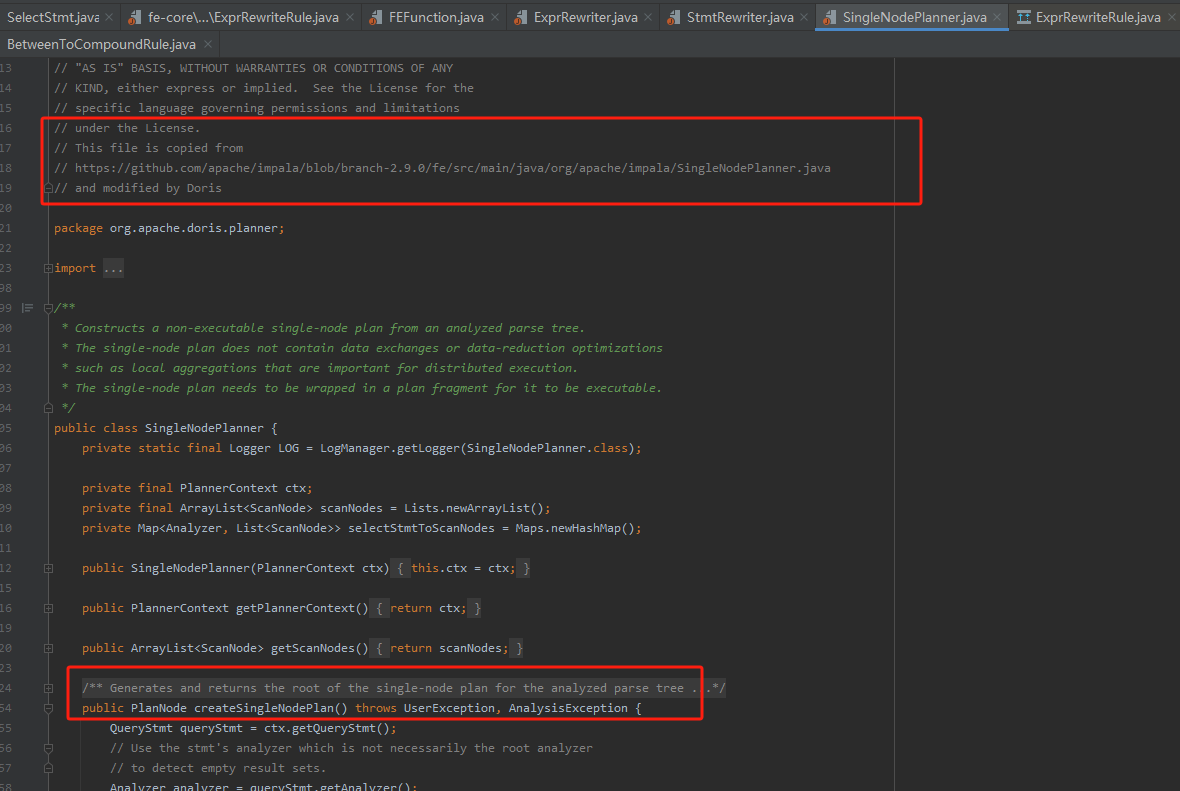
這一過程會生成PlanNodeTree,一般用於處理Join Reorder場景下的join調優與謂詞下推等下推優化。
SingleNodePlanner類用於生成單擊執行計劃,該類其實也是基於impala框架改寫適用於Doris的。在這個類中,除了謂詞下推與join reorder外,還有類似列裁剪之類的優化,都在這個類中有處理。
分散式執行計劃
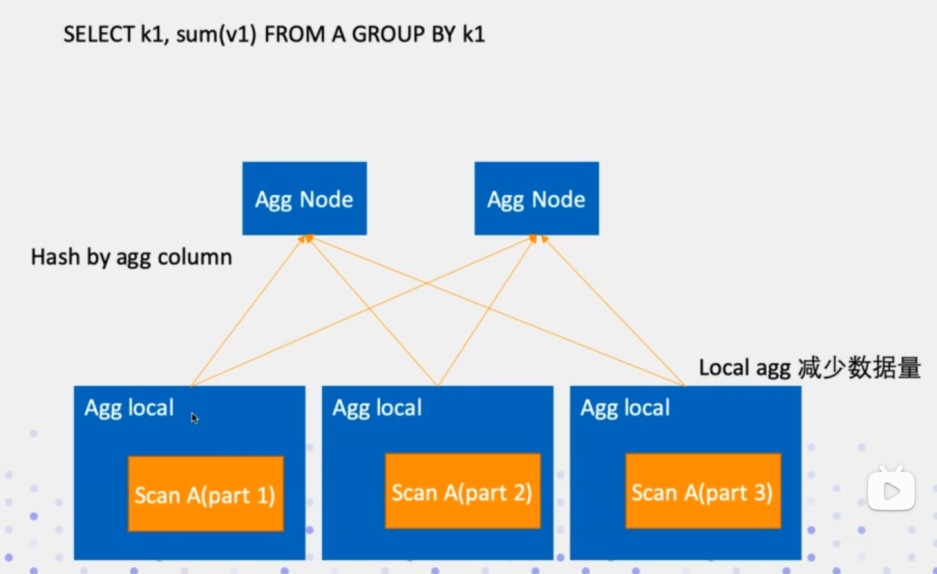
DistributedPlanner類負責分散式執行計劃的優化,其中會處理Join場景下的分散式執行,選擇最優的Join執行路徑;其次就是Agg聚合函數的分散式執行邏輯,Agg會分兩步執行,先會在local本地scan,然後再Agg Node上在做一次scan聚合;當然還有一些運算元需要做分散式邏輯執行優化. 都可以在這個類中找到。當然這個類也是基於impala框架改寫的。
如下是AggNode的分散式執行計劃優化:
總結
Doris的很多設計,其實都是有據可依,參考借鑑已有的框架/論文,再依據實際的業務場景做改寫;這也正是我們要學習瞭解的東西,通過一個點,然後鋪開去了解學習相關的其他點,慢慢的串聯起來形成面。查詢優化器結合如下部落格再加上自己去閱讀一下程式碼,對整個脈絡及機制就算是掌握了。
聊聊分散式 SQL 資料庫Doris(五) 這是之前寫的對查詢優化器相關的一些知識普及.
查詢優化器詳解 Doris團隊針對查詢優化器的視訊講解.
Doris SQL 原理解析 小米工程師寫的,更深入的剖析.