資料庫系列:MySQL InnoDB鎖機制介紹
資料庫系列:MySQL慢查詢分析和效能優化
資料庫系列:MySQL索引優化總結(綜合版)
資料庫系列:高並行下的資料欄位變更
資料庫系列:覆蓋索引和規避回表
資料庫系列:資料庫高可用及無失真擴容
資料庫系列:使用高區分度索引列提升效能
資料庫系列:字首索引和索引長度的取捨
資料庫系列:MySQL引擎MyISAM和InnoDB的比較
資料庫系列:InnoDB下實現高並行控制
資料庫系列:事務的4種隔離級別
資料庫系列:RR和RC下,快照讀的區別
1 背景
隨著網際網路的發展,高並行業務的盛行,MySQL InnoDB引擎的細粒度行鎖,變成很核心的特性之一。
在並行高的情況下,如果使用不當,會導致嚴重的效能問題。比如細粒度行鎖,是實現在索引記錄上的,但如果沒有命中索引,就回退化成表鎖,那對效能是災難的。
下面我們從索引角度出發, 介紹下MySQL InnoDB的鎖機制。
2 InnoDB的索引回顧
Innodb中有2種索引:主鍵索引(也叫聚集索引 Clustered Index)、輔助索引(也叫非聚集索引 Secondary Index)。
主鍵索引: 每個表只有一個主鍵索引,b+樹結構,葉子節點儲存主鍵的值以及對應整條記錄的資料,非葉子節點不儲存記錄的資料,只儲存主鍵的值。
當表中未指定主鍵時,MySQL內部會自動給每條記錄新增一個隱藏的rowid欄位(預設4個位元組)作為主鍵,用rowid構建聚集索引。聚集索引在MySQL中即主鍵索引。
輔助索引: 每個表可以有多個輔助索引,b+樹結構,非聚集索引葉子節點儲存欄位(索引欄位)的值以及對應記錄主鍵的值,其他節點只儲存欄位的值(索引欄位),這就是與聚集索引不同的地方。每個表可以有多個非聚集索引。
InnoDB的每一個表都會有聚集索引:
- 假設表定義了PK,則PK就是聚集索引
- 如果未定義PK,則第一個非空unique列即是聚集索引
- 如果沒有PK也沒有非空unique列,InnoDB會建立一個隱含的row_id作為聚集索引使用
下圖更形象說明這兩種索引的區別,這邊假設了一個儲存4行資料的表。Id為主鍵索引,Name作為輔助索引,圖中清晰的體現了聚簇索引和非聚簇索引的差異。
表中有四條記錄:
5, Gates, Microsoft
7, Bezos, Amazon
11, Jobs, Apple
14, Elison, Oracle
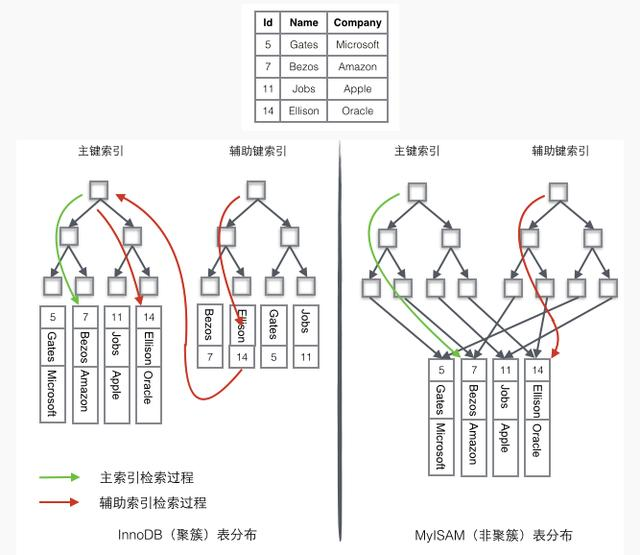
InnoDB資料檢索過程
上面的表中有2個索引:id作為主鍵索引,name作為輔助索引。
如果需要查詢id=14的資料,只需要在左邊的主鍵索引中檢索就可以了。
如果需要搜尋name='Ellison'的資料,需要2步:
- 先在輔助索引中檢索到name='Ellison'的資料,獲取id為14
- 再到主鍵索引中檢索id為14的記錄
輔助索引這個查詢過程在mysql中叫做回表,相對於主鍵索引多了第二步操作。
MyISAM資料檢索過程
- 在索引中找到對應的關鍵字,獲取關鍵字對應的記錄的地址
- 通過記錄的地址查詢到對應的資料記錄
對比發現:Innodb中最好是採用主鍵索引查詢,這樣只需要一次索引,如果使用輔助索引檢索,涉及多一步的回表操作,比主鍵查詢要耗時一些。
所以,InnoDB的普通索引,實際上會掃描兩遍:
第1遍,由普通索引找到PK:檢索到name='Ellison'的資料,獲取id為14
第2遍,由PK找到行記錄:即到主鍵索引中檢索id為14的記錄
對索引有興趣的,可以參考作者的這幾篇文章:
MySQL全面瓦解22:索引的介紹和原理分析
MySQL全面瓦解23:MySQL索引實現和使用
MySQL全面瓦解24:構建高效能索引(策略篇)
3 InnoDB 幾種常見鎖
★InnoDB預設的事務隔離級別為可重複讀(Repeated Read, RR),我們當下的所有介紹都是基於這個隔離級別為前提的。
- 記錄鎖(Record Locks):鎖定單一行記錄,InnoDB 使用記錄鎖來實現行級鎖,這樣允許多個事務並行存取不同的行。
- 間隙鎖(Gap Locks):InnoDB 的特性,用於鎖定一個範圍,但不包括實際的記錄。這主要用於防止幻讀(Phantom Reads)。
- 臨鍵鎖(Next-Key Locks):InnoDB 儲存引擎的一種鎖定機制,在執行查詢語句時,根據查詢條件所鎖定的一個範圍。這個範圍中包含有間隙鎖和記錄鎖。它的設計目的是為了解決幻讀(Phantom Reads)。
3.1 記錄鎖(Record Locks)
記錄鎖,它封鎖索引記錄,例如:
select * from table where id=5 for update;
它會在id=1的索引記錄上加鎖,以阻止其他事務插入,更新,刪除id=1的這一行。
需要說明的是:
select * from table where id=5;
則是快照讀(SnapShot Read),它並不加鎖,快照讀可以參考作者這篇文章:資料庫系列:RR和RC下,快照讀的區別
3.2 間隙鎖(Gap Locks)
間隙鎖,它封鎖索引記錄中的間隔,或者第一條索引記錄之前的範圍,又或者最後一條索引記錄之後的範圍。
延續上面的那個例子繼續演示:
# 表結構
table (Id PK, Name , Company);
# 表中包含四條記錄
5, Gates, Microsoft
7, Bezos, Amazon
11, Jobs, Apple
14, Elison, Oracle
執行SQL語句如下:
select * from table
where id between 7 and 13
for update;
這樣的話,會封鎖資料的區間,以防止其他事務插入id=8的記錄。
假設沒有間隙鎖,則可能夠插入成功,而之前的select事務,會發現檢索的結果集莫名多了一條記錄,即幻影資料。
所以間隙鎖主要目的用於防止幻讀(Phantom Reads),避免其他事務在間隔中插入資料,導致 『不可重複讀』。
如果把事務的隔離級別降級為讀提交(Read Committed, RC),對,就是網際網路最常用的隔離級別,間隙鎖則會自動失效。
3.3 臨鍵鎖(Next-Key Locks)
臨鍵鎖(Next-Key Locks)是資料庫管理系統InnoDB中的一種重要鎖定機制。這種鎖是查詢時根據查詢條件鎖定的一個範圍,這個範圍包括間隙鎖和記錄鎖,左開右閉,即不鎖住左邊界,但會鎖住右邊界。臨鍵鎖的主要設計目的是為了解決所謂的「幻讀」問題。
# 左開右閉 範例
(-infinity, 1]
(1, 7]
(7, 9]
(9, +infinity]
依然沿用上面的例子,InnoDB引擎,RR隔離級別:
-- 建立一個範例表
CREATE TABLE users (
Id INT PRIMARY KEY,
Name VARCHAR(255) NOT NULL,
Company VARCHAR(255) NOT NULL,
);
-- 插入一些範例資料
INSERT INTO users (id, name, company) VALUES (1, 'Alice', 'ali');
INSERT INTO users (id, name, company) VALUES (2, 'Brand', 'tencent');
INSERT INTO users (id, name, company) VALUES (3, 'Charlie', 'baidu');
-- 開始一個事務,並使用臨鍵鎖查詢資料
START TRANSACTION;
SELECT * FROM users WHERE id > 1 FOR UPDATE;
-- 在另一個事務中嘗試插入新資料,將會被阻塞直到第一個事務釋放鎖
START TRANSACTION;
INSERT INTO users (id, name, age) VALUES (4, 'David', 30);
COMMIT;
-- 第一個事務提交後,第二個事務可以繼續執行插入操作
COMMIT;
臨鍵鎖的主要目的,也是為了避免幻讀(Phantom Read),在事務隔離級別為可重複讀的情況下,InnoDB儲存引擎預設使用臨鍵鎖。這種鎖提供了一種有效的機制來保證在並行環境中資料的完整性和一致性。
如果把事務的隔離級別降級為RC,臨鍵鎖則也會失效。
4 總結
- InnoDB的索引與行記錄儲存在一起,MyISAM則是通過索引的地址查詢到對應的資料記錄,效率低一些
- InnoDB的聚集索引儲存行記錄,普通索引儲存PK,所以普通索引要查詢兩次
- 記錄鎖鎖定索引關聯的具體記錄
- 間隙鎖鎖定間隔,防止間隔中被其他事務插入
- 臨鍵鎖鎖定索引記錄+間隔,防止幻讀
- elect...for update加鎖的幾種情況:
- 主鍵欄位:加行鎖。
- 唯一索引欄位:加行鎖。
- 普通索引欄位:加行鎖。
- 主鍵範圍:加多個行鎖。
- 普通欄位:加表鎖。
- 查詢空資料:不加鎖。
- 行鎖與表鎖的區別
- 如果事務1加了行鎖,一直未釋放鎖,事務2操作相同記錄,會一直等待直至超時。
- 如果事務1加了表鎖,一直未釋放鎖,事務2無論操作哪一行記錄,都會一直等待直到超時
