從零開始的 dbt 入門教學 (dbt-core 基礎篇)

最近一直在處理資料分析和資料建模的事情,所以接觸了 dbt 等資料分析的工具,國內目前對於 dbt 比較詳細的資料不多,所以打算寫四道五篇 dbt 相關的文章,本文屬於 dbt 系列的第一篇,本篇主要闡述 dbt 一些基本概念,教會你如何設定 dbt 連線遠端資料庫,並執行你的第一個資料模型,那麼本文開始。
一、一些資料分析可能需要知曉的前置概念
1.1 什麼是 dbt?
DBT(Data Build Tools)是一種資料轉換工作流工具,作為資料分析師,我們需要將原始的資料進行各類加工組合來應對更為複雜的資料分析需求。準確來說,dbt 還是來寫 sql 做各種資料查詢,你可能會想,那我自己寫 sql 不就完事了,還用啥 dbt。事實上,由於資料庫種類繁多,sql 會存在相容問題;其次,資料轉換會存在資料依賴,比如底層原始資料層層轉變為業務資料,你可能需要自己來維護這個依賴關係,其實仔細一想,你就會發現自己做會非常麻煩。
我們可以把 DBT 想象成一個廚師,而原始資料就像是食材。廚師(DBT)的工作就是把食材(原始資料)加工成好吃的菜(有用的資料模型)。這個過程就像是烹飪一樣,需要按照一定的順序和步驟來操作。
DBT 的工作流程就像是烹飪的步驟,我們只需要告訴 DBT 想做什麼菜(即你想要的資料模型是什麼樣的,當然 sql 肯定得自己寫),然後,DBT 會按照你的指示,一步步地處理食材(即處理原始資料),最後做出你想要的菜餚(即生成你需要的資料模型)。
其實說到這,你就能明白 dbt 能讓我們更聚焦在我們想要什麼資料,定義怎樣的資料模型,其餘的工作流全權交給 dbt 即可,這就是 dbt 的作用。
1.2 dbt core 與 dbt cloud 的區別
我們在 dbt 檔案開頭會留意到兩個比較重要的名詞,dbt core 和 dbt cloud,新手可能已經不知道該從哪個入手了,這裡先解釋下區別:
- dbt core:
dbt Core是dbt的開源部分,它提供了資料建模、轉換和管理的核心功能。使用dbt Core,你可以定義和執行資料轉換模型,生成 SQL 查詢,並將資料寫入目標資料倉儲(如BigQuery、Snowflake等)。總而言之,你接下來要使用的 dbt 命令都是基於 dbt core,所以這個必須安裝(後面細說)。 - dbt Cloud:
dbt Cloud是dbt的雲服務,構建在dbt Core的基礎之上。它提供了託管服務,CI/CD 部署以及圖形化的使用者介面,能讓你直接在平臺執行dbt模型而無需自己設定和搭建基礎設施,關於 dbt cloud 我後續單獨出一篇文章。
總而言之,就是 saas 付費服務和開源在地化自行搭建的區別,那麼本文自然是從 dbt core 的視角出發了。
1.3 什麼是 dbt adapters?
除了 dbt core,第二個重要的概念是 dbt adapters,也就是 dbt 介面卡,而且我們要做資料處理一定是安裝 dbt core + 某個資料庫所對應的介面卡。
大家都知道不同的資料庫在 SQL 查詢上都會有些許差異,要記住所有型別的特定語法成本高但收益低,介面卡正好幫我們做了這件事,介面卡的作用之一是提供一種標準化的介面,讓你可以使用相同的 SQL 語法來與不同的底層資料平臺互動,而不需要關注 SQL 語句本身。
dbt 本身提供的介面卡就非常多,除了官網維護的介面卡之外,還有社群自行維護且受 dbt 官方認可的介面卡,所以從資料平臺(比如 bigQuery、Postgres)到資料庫(比如 mysql)本身。
dbt 為所有的介面卡都提供了獨立的檔案,以及設定說明,大家根據自己的資料庫型別可以直接來這個檔案目錄搜尋檢視即可。
1.4 什麼是 ELT 和 ETL ,它們區別在哪?
ELT 和 ETL 是兩種常見的資料分析模式,它們在資料處理流程中的步驟順序上有所不同。
-
ETL:
- 提取(Extract): 從源系統中提取資料。
- 轉換(Transform): 對提取的資料進行清洗(比如去除空值)、加工、轉換。
- 載入(Load): 將經過轉換的資料載入到目標系統,通常是資料倉儲。
在 ETL 模式中,資料在提取後經過一系列複雜的轉換操作,然後再載入到目標系統。這種模式適用於需要對資料進行多次、複雜轉換的情況,比如將多個源的資料合併,進行聚合等。
-
ELT(提取、載入、轉換):
顧名思義,在資料處理順序上有所不同。ELT 模式中,資料首先載入到目標系統,然後在目標系統內進行轉換。這種模式適用於目標系統有足夠計算資源的情況,可以在目標系統中直接處理原始資料。
兩者區別:
- ETL 的優勢: ETL 適用於需要在資料到達目標系統前進行復雜的資料淨化和轉換的情況。它可以將清洗和轉換的邏輯分離出來,確保目標系統中的資料是高質量的。
- ELT 的優勢: ELT 更適用於雲資料倉儲等具有強大計算能力的系統( 比如 bigQuery )。它允許直接在目標系統中處理原始資料,減少了資料傳輸的複雜性,適用於大規模資料處理。
1.5 Dbt ,bigQuery 與 Fivetran 的作用
理解 ELT(Extract, Load, Transform)和 ETL(Extract, Transform, Load)的概念有助於更好地理解這三個工具在資料處理和分析中的角色。
- Fivetran:
- ELT角色: Fivetran 主要負責從各種資料來源提取(Extract)資料,並將這些資料載入(Load)到目標資料倉儲,如 BigQuery。
- 作用: Fivetran 簡化了資料提取和載入的過程,使資料準備的階段更加快速和無縫,除此之外,Fivetran 還會做部分資料預處理工作,大致能力:
- 資料格式轉換: Fivetran 可以處理來自不同資料來源的資料,並將其轉換為適合目標資料倉儲的格式。這可能涉及日期格式、數位格式等的調整。
- Schema對映: Fivetran 會根據目標資料倉儲的結構對映,將資料來源的表和欄位對映到目標倉庫中的對應結構。
- 增量同步: Fivetran 通常支援增量同步,只同步源資料中發生變化的部分,以減少資料傳輸的成本。
- 錯誤處理: 處理在資料載入過程中可能出現的錯誤,確保資料的完整性。
- 效能優化: 優化資料載入的效能,以確保資料能夠及時可用。
- BigQuery:
- ELT角色: BigQuery 在 ELT 流程中扮演 Load 階段的角色。它是一個雲資料倉儲,負責儲存和處理載入進來的原始資料。
- 作用: BigQuery 提供強大的分散式查詢引擎,允許使用者在原始資料上執行復雜的 SQL 查詢,進行初步的資料分析。
- dbt:
- ELT和ETL角色: dbt 既可以在 ELT 模式下使用,也可以在 ETL 模式下使用,取決於具體的架構設計。在 ELT 中,dbt 用於資料轉換和建模,通常在載入後的原始資料上執行。在 ETL 中,dbt 可以與其他 ETL 工具配合使用,用於定義和執行更復雜的資料轉換邏輯。
- 作用: dbt 的主要作用是定義和執行資料模型,提供了一種可維護、可測試的方法來構建和管理分析模型。
整體流程:
- ELT流程:
- Extract(Fivetran): 從各種資料來源提取資料。
- Load(Fivetran和BigQuery): Fivetran 將資料載入到 BigQuery 中。
- Transform(dbt): 使用 dbt 在 BigQuery 中建立和維護分析模型。
- ETL流程:
- Extract(Fivetran): 從各種資料來源提取資料。
- Transform(dbt等工具): 使用 dbt 或其他 ETL 工具定義和執行資料轉換邏輯。
- Load(BigQuery): 將轉換後的資料載入到 BigQuery 或其他資料儲存中。
這種結合 ELT 和 ETL 的方式,利用了 Fivetran 的強巨量資料載入能力,同時通過 dbt 提供的資料建模工具,實現了靈活而可維護的資料處理和分析流程。
1.6 dbt 負責的資料轉換,而 Fivetran 也能做資料轉換,那為什麼還需要dbt?
- Fivetran: Fivetran 主要專注於資料整合,即將資料從不同的源頭傳輸到目標資料倉儲。它強調的是資料的可靠、高效的移動。雖然 Fivetran 提供了一些基本的預處理功能,但它並不是一個專門用於複雜資料轉換和業務邏輯的工具。它的目標是提供一個易於使用的平臺,使得資料工程師可以快速地設定和管理資料流。
- dbt: dbt(data build tool)則專注於資料轉換和建模。它在資料倉儲中執行轉換和彙總,以便為分析提供更具可讀性和易用性的資料結構。dbt 允許分析師定義業務邏輯、建立衍生欄位、執行聚合等操作,將原始的倉庫資料轉化為更容易理解和使用的形式。dbt 的強項在於支援分析人員更好地理解和使用資料,而不僅僅是資料的傳輸和儲存。
綜合考慮,Fivetran 和 dbt 可以協同工作。Fivetran 負責將資料從源頭搬移到資料倉儲,而 dbt 則負責在資料倉儲中進行進一步的處理和建模,以便更輕鬆地進行復雜的查詢和分析。簡單理解,Fivetran 只提供了基礎的資料淨化和轉換,而 dbt 提供更專業更強大更自由的資料轉換。
二、 dbt 環境準備(這裡以 Python 為例)
2.1 Python 版本注意
與 npm 需要依賴 node 一樣,pip 命令也需要安裝 Python,關於版本這裡推薦安裝 3.8 3.9 即可,不要安裝 3.10。我在安裝了 Python 3.10 後出現了安裝 mysql 介面卡和 core 包時,一直只能安裝 0.19.2 的情況,而 core 最新的版本都到了1.1.6,導致我一直陷入了包版本是對的,但是 core 與 mysql 介面卡依賴包版本錯誤需要解決版本衝突的怪圈中,這點切記。
2.2 安裝 dbt core
上文已經提到 dbt core 屬於 dbt 的開源核心,我們後續使用的命令都由這個包提供。安裝 dbt core 的方式有很多,官方支援 pip、docker、homebrew 等等。
上文我們已經安裝了 Python ,所以我們在終端執行如下命令即可:
pip install dbt-core
dbt 預設全域性安裝,所以即便你在某個專案路徑下,它還是會基於全域性安裝,在安裝完成之後,我們能執行如下命令檢查安裝是否完成。
pip show dbt-core
比如我安裝的就是 core 1.1.6 版本,這裡就能看到安裝的版本,路徑等相關資訊。

2.3 安裝 dbt adapters
我們後續所有工作,都將基於 core 與 adapters 兩個包來完成,其實準備來說,當我們執行安裝某個介面卡時,這個命令會預設安裝與之關聯的 core 包,也就是一個命令自動安裝兩個包,這裡我們以 bigQuery 為例:
pip install dbt-bigquery
同理,安裝之後可以執行命令檢查安裝包的版本等資訊:
pip show dbt-bigquery
某些情況下,你先執行了下載介面卡的命令,會預設幫你 core 包,你也許想單獨再安裝更高版本的 core 包,你可以通過解除安裝重灌的形式來完成,比如:
## 先解除安裝
pip uninstall dbt-core
## 再安裝執行版本包
pip install dbt-core==1.1.6
以上就是 dbt 兩個核心的包了,我們只需要安裝這兩個包就能支撐接下來的所有工作,再做個總結,解釋下兩個包的作用:
- dbt-core:開源的核心包,安裝了這個你才能執行 dbt 命令。
- 介面卡包(dbt-bigquery):資料庫平臺、資料庫相容的包,幫你抹平不同資料庫的命令差異,而且接下來我們連結對應的資料庫,都需要提前安裝對應的介面卡。
四、初始化 dbt
4.1 通過命令
可能到這裡,大家覺得安裝完介面卡以及dbt core 就已經夠了,然後我們在終端直接通過命令連結資料庫進行操作,其實不是的。我們需要初始化一個專案,而且我們還需要在專案中編寫資料模型語句,以及一些基本的設定程式碼。
初始化一個 dbt 專案有兩種方式,第一種是直接通過命令:
## 你可以在你的專案目錄下執行
dbt init
之後 dbt 會幫你建立一個模版專案,假設你出現了 dbt 命令不存在的報錯,那麼就是你的 dbt core 包沒安裝好,你應該重新走上文的命令,以及通過 pip show dbt-core 來檢查你的 core 版本資訊。
4.2 使用官網模版專案
除了命令,其實我更推薦使用官網的模版專案,因為 dbt 命令除了資料做轉化,還包含資料寫入資料庫的命令,而 init 建立的模版只是最基礎的模版,不包含模擬資料,也不包含模擬的資料模型,一切從零開始還是會存在部分難度。
大家可以直接跳轉 jaffle_shop,然後 git clone下載本地,之前由於我們已經安裝了 core 和對應的介面卡,所以我們直接拿這個專案練手就好了。
需要注意的是,我第一次使用 dbt init 初始化專案,這個命令很奇怪會在電腦根路徑建立一個profiles.yml設定,而專案本身就是依賴這個設定來與資料庫建立聯絡。
其實大家應該都想得到,這種核心設定肯定得跟著專案走,全域性即便有也應該會被專案內的設定所覆蓋,結果我在專案根目錄專門建立profiles.yml後執行命令每次還是走根路徑的設定,此問題可能跟我 dbt 版本有關,暫時解釋不了。
我查閱了官網的說明,官網也確定會優先走專案根目錄的設定,電腦根目錄設定只是起到預設兜底的作用。但假設大家使用 jaffle_shop 專案,因為缺少 init 過程,沒有根目錄建立設定的行為,起碼後續我的命令確實走了專案內的設定。
五、連結資料庫
萬事俱備,現在我們需要連結資料庫,接下來才能做資料轉換的工作,這裡我們以 bigquery 為例。
首先 bigquery 是 Google 的資料平臺,它支援四種連線方式,具體可參考:bigquery setup
這裡我以 Service Account File 的方式來連結。其次,由於 Google 資料庫不支援本地連線,所以我們需要把 clone 的專案整個上傳伺服器,通過遠端來聯調資料庫,前端同學如果不清楚,可以問下伺服器端同學日常開發怎麼做的就好了。
5.1 建立 profiles.yml 檔案
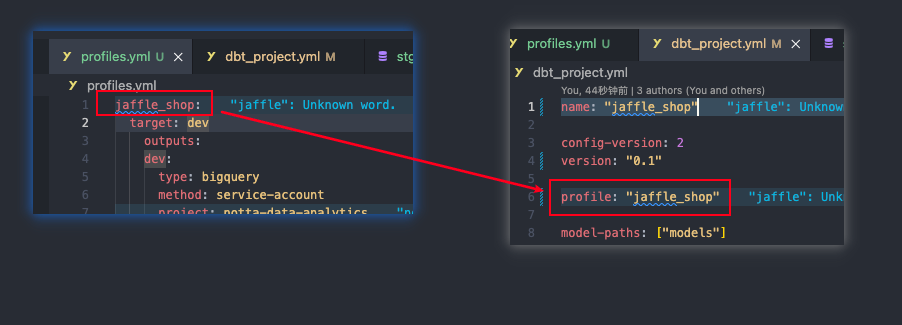
我們需要在之前 clone 的 jaffle_shop 專案下建立 profiles.yml 檔案,之後貼上如下程式碼到檔案即可:
jaffle_shop:
target: dev
outputs:
dev:
type: bigquery
method: service-account
project: demo-data-analytics
dataset: dev_data_statistics
threads: 4 # Must be a value of 1 or greater
keyfile: data-analytics-bef7505.json
5.2 解釋下設定
首先 jaffle_shop 這個欄位需要跟我們專案根目錄下 dbt_project.yml 中的 profile 屬性欄位相同,你可以取任何名字,但兩邊得保持一致。
target:dbt 專案本身也有分支和環境的區別,現在我們就是學習和測試,所以這裡環境可以定義為 dev 即可。
type:你所使用介面卡所對應的資料庫名稱,因為我們使用的是 bigquery,所以這裡填 bigquery 即可。
method:固定設定,不用改。
project:專案名,注意是你的專案名,當然也可能叫資料容器名,就是最外層的容器名。
dataset:資料集名稱,一般一個資料集下包含多張資料表,所以這個關係就是資料庫---資料集--資料表的關係。但需要注意的是,一般資料庫有N個資料集,我們運算元據也不可能只操作一個資料集,所以這裡的 dataset 只是作為預設值,如果大家有資料庫所有許可權,還是能查詢所有資料集,不過它會影響 dbt seed 資料庫新表的建立位置,一般我們 dataset 提供哪,seed 命令建立的新表就在哪。總而言之,不影響查詢資料轉換,但是影響 seed 和我們 model 新表、檢視建立的位置。
threads:用於指定執行 dbt 任務時的並行執行緒數。使用多個執行緒,可以加快 dbt 流水線的執行速度,這裡我們也預設 4 即可。
keyfile:連結 Google 資料庫也需要授權,簡單理解就是一份祕鑰,因為我的祕鑰也直接放在了專案根路徑,所以我這裡直接引即可。
5.3 檢查連結是否成功
設定完成後,我們執行 dbt debug 可以檢查專案與資料庫的連結情況,比如:
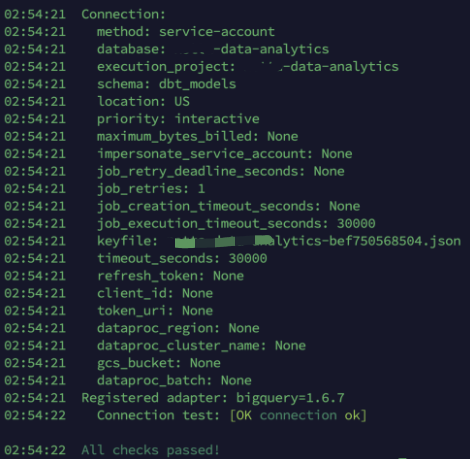
那麼到這裡,我們成功讓 dbt 專案連結到了遠端資料庫,要做資料分析或者建模,我們肯定得提前往資料庫寫入部分資料然後再基於資料做分析,使用上文提到的 jaffle_shop 模版專案的好處就是,專案直接為我們準備好了資料檔案和模型檔案,現在讓我們執行如下命令:
## 將專案中 scv 資料檔案寫入連線的資料庫
dbt seed
## 執行整個 dbt 專案,開始資料建模
dbt run
在執行完成後,當我們來到資料庫中的 dev_data_statistics 資料集,在此資料集下即可看到 jaffle_shop 中所定義的模型檔案。有一個小技巧,dbt 在資料庫中建立的所有模型名稱都預設是我們的 sql 檔名,這非常方便我們對應查詢表或者檢視。
那麼道理,我們基本走完了一個 dbt 流程,成功設定且執行了屬於我們第一批資料模型。
六、dbt 命令註解
順帶,我整理了部分 dbt 命令註解:
build:按照指定的順序執行所有的資料載入、資料模型、資料快照和資料測試。這個命令會編譯 SQL 並執行相應的操作,構建資料倉儲。- build 包含了 seed 、run、test、snapshot,也就是把原始資料加入資料庫,基於模型生成檢視,測試用例以及生成快照。
clean:刪除指定的資料夾,通常用於清理生成的檔案或目錄。clone:建立一個節點的副本,可以在專案中複製和重用節點。這個命令可以幫助你快速建立類似的資料模型。compile:將 dbt 專案中的程式碼轉換為可執行的 SQL 語句,這個命令可以幫助你檢查和驗證你的程式碼是否正確。debug:顯示當前 dbt 環境和設定的資訊(上面用過了),這個命令可以幫助你瞭解當前的 dbt 設定和環境變數。deps:更新專案中使用的依賴項,以獲取最新版本的依賴庫(dbt 也有三方包,後續文章講)。docs:生成或提供你的專案的檔案網站,這個命令可以幫助你生成和檢視專案的檔案,以便其他人瞭解你的資料模型和操作。init:初始化一個新的 dbt 專案,這個命令會建立一個新的 dbt 專案,並生成必要的檔案和目錄結構,以便你開始構建資料倉儲。list:列出專案中的資源,如資料模型、表、檢視等。這個命令可以幫助你檢視專案中的所有資源。parse:解析專案並提供關於效能的資訊,這個命令可以幫助你瞭解專案的結構和效能,以便進行優化。retry:重新執行上次執行失敗的節點,這個命令可以幫助你重新執行失敗的資料模型或操作,以解決錯誤。run:編譯 SQL 並執行指定的資料模型或操作。這個命令用於執行 dbt 專案中的資料模型和操作,以構建資料倉儲。- seed 和 run 的區別:
seed的主要目的是載入原始、靜態的資料,這些資料通常不需要經常變動,例如國家列表、產品類別等。seed會負責將這些靜態資料載入到資料庫中,為後續的分析和轉換提供基礎資料。run的主要目的是執行資料模型,通過執行 SQL 查詢和轉換邏輯,生成新的表、檢視或者其他的資料結構。這些模型可能依賴於seed匯入的資料,也可能依賴於其他模型生成的資料。
- 有時候我們只想執行某個 model 而不是所有 models ,通過 --model 可以執行執行某個 model,比如
dbt run --models model_name,或者dbt run --models model1,model2。 - 有時候我們希望通過命令區分環境,比如
dbt run --target dev 或者 prod
- seed 和 run 的區別:
run-operation:執行指定的宏(macro),並傳遞任何提供的引數。這個命令可以幫助你執行自定義的宏,以實現特定的資料處理邏輯。seed:從 CSV 檔案中載入資料到資料倉儲中。這個命令用於將資料載入到你的資料倉儲中,以供後續的資料模型使用。show:為指定的資料模型或操作生成可執行的 SQL。這個命令可以幫助你檢視指定資料模型或操作的 SQL 程式碼。snapshot:執行專案中定義的資料快照操作。這個命令用於執行 dbt 專案中定義的資料快照操作,以捕捉資料的歷史狀態。source:管理專案的資料來源。這個命令可以幫助你新增、設定和管理專案中的資料來源,以便從不同的資料來源中提取資料。test:這個命令用於在已部署的資料模型中執行資料測試,以確保資料的準確性和一致性,基本作用:- 驗證資料的準確性、完整性和一致性。
- 驗證資料轉換邏輯是否正確。
- 驗證資料之間的關係和約束。
舉個 test 的例子:
models:
- name: my_model
tests:
- my_test:
severity: error
description: "Check if column X contains null values"
check: "select count(*) from {{ ref('my_model') }} where X is null"
expect: "select 0"
在上面的範例中,my_test 是一個測試用例的名稱,my_model 是模型的名稱。check 查詢語句中使用了 {{ ref('my_model') }} 來參照模型,然後檢查模型中的列 X 是否包含空值。
七、dbt 檢視(view)和表(table)的區別
dbt run命令預設建立的是檢視(views),但是你可以通過在模型檔案中設定{{ config(materialized='table') }}來指定dbt run生成表(tables)而不是檢視,或者在 dbt_ project 設定中對資料夾進行定義。
舉個例子,我們在 dbt 模型檔案頂部新增以下程式碼:
{{ config(materialized='table', sort='timestamp', dist='user_id') }}
-- Your SQL code here
這樣,當我們執行dbt run命令時,dbt 會建立一個表而不是一個檢視。
關於檢視和表的區別,這裡我給一些比較生硬但明顯的區別:
- 檢視(view):檢視的主要作用是提供一個虛擬的表,它是基於一個或多個表的查詢結果而建立的。檢視可以看作是一個預定義的查詢,它將查詢邏輯封裝在其中,並提供一個簡化和抽象的介面來存取和運算元據,注意,檢視本身不儲存資料。檢視在以下情況下很有用:
- 檢視是一個虛擬的表,它是基於一個或多個表的查詢結果而建立的,你可以使用檢視來對原始資料進行聚合、計算和轉換,以生成更高層次的指標和洞察。(檢視唯讀,不能增刪改)
- 檢視不儲存實際的資料記錄,而是根據查詢邏輯動態生成結果。
- 檢視可以看作是一個預定義的查詢,它將查詢邏輯封裝在其中,並提供一個簡化和抽象的介面來存取和運算元據。
- 檢視可以簡化複雜的查詢操作,提高查詢的效率和可讀性。
- 檢視可以用來限制對資料的存取許可權,只暴露需要的資料給使用者,檢視可以用於限制使用者對敏感資料的存取。通過在檢視中應用過濾器、許可權和安全規則,你可以控制使用者對資料的存取許可權,確保只有授權的使用者可以檢視和使用特定的資料。
- 表格(table):這會在你的資料倉儲中建立一個實體表,並在每次
dbt run時重新填充。表是資料庫中儲存資料的主要結構。與檢視不同,表會儲存資料。當你查詢表時,你會直接獲取儲存在表中的資料,而不需要重新計算或檢索資料。表的一些特點:- 表是資料庫中的實際儲存物件,它包含了實際的資料記錄。
- 表可以儲存和管理大量的資料,可以進行增刪改查等操作。
- 表具有物理結構,包括列和行,每一行代表一個資料記錄,每一列代表一個屬性。
- 表的資料是實時更新的,當對錶進行增刪改操作時,資料會直接在表中進行修改。
總結起來,檢視和表在用途上可能有很多相似之處,但表是實打實的資料,而檢視是一箇中間態的資料,前者可以CRUD直接操作,而檢視只能查,像修改只能 dbt run 完整更新。
那麼到這裡,第一篇文章結束,第二篇我們詳細聊下 dbt 設定,以及一些更進階的用法,比如區分 dev prod 將模型寫入不同目標資料集等等,關於本文有任何走不通的地方或者疑問環境留言提問。