論文閱讀:2023_Semantic Hearing: Programming Acoustic Scenes with Binaural Hearables
論文地址:語意聽覺:用雙耳可聽器程式設計聲學場景
論文程式碼:https://semantichearing.cs.washington.edu/
參照格式:Veluri B, Itani M, Chan J, et al. Semantic Hearing: Programming Acoustic Scenes with Binaural Hearables[C]//Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. 2023: 1-15.
摘要
想象一下,你可以在公園裡聽到鳥兒的啁啾,而不會聽到其他徒步者的閒聊,或者可以在繁忙的街道上遮蔽交通噪音,但仍能聽到緊急警報聲和汽車喇叭聲。我們引入語意聽覺,這是一種可聽到裝置的新功能,使它們能夠實時地關注或忽略來自現實世界環境的特定聲音,同時也保留空間線索。為實現這一目標,本文做出了兩個技術貢獻:1)提出了第一個神經網路,可以在干擾聲音和背景噪聲存在的情況下實現雙耳目標聲音提取,2)設計了一種訓練方法,使系統可以泛化到現實世界的使用。結果表明,該系統可以在20種聲音類別下執行,基於transformer的網路在連線的智慧手機上的執行時間為6.56 ms。在以前未見過的室內和室外場景中對參與者進行的野外評估表明,所提出的概念驗證系統可以提取目標聲音並進行泛化,以保留其雙耳輸出中的空間線索。
關鍵字:空間計算,雙耳目標聲音提取,可聽計算,噪聲抵消,注意力,因果神經網路
1 介紹
在過去的十年中,我們見證了耳機、耳塞等可聽裝置數量的增加,全球有數百萬人在使用它們[50]。在這裡,我們介紹一種可聽裝置的新功能,我們稱之為「語意聽力」。
設想一個場景,一個使用者在海灘上戴著耳聾的裝置,希望在遮蔽附近任何人類語音的同時,傾聽海洋的平靜聲音。同樣,在繁忙的街道上行走時,使用者可能希望減少除緊急警報器外的所有聲音;或者在睡覺時,他們可能想聽鬧鐘或嬰兒的聲音,但不想聽街上的噪音。在另一種情況下,使用者可能在飛機上,希望聽到人類的講話和廣播,但不想聽到嬰兒的哭聲。或者在徒步旅行時,使用者可能想聽鳥兒的啁啾聲,但不是來自其他徒步者的閒聊(見圖1中的範例)。這些以及其他潛在的使用案例需要降噪耳機來消除所有聲音,然後需要一種機制來將所需的聲音引入耳機。後者是我們工作的重點,它需要通過語意將個人傳入的聲音與使用者輸入相關聯來實時程式設計輸出的聲學場景,以確定哪些聲音允許進入可聽裝置,哪些聲音要遮蔽。

圖1: 語意聽力應用。a)戴著雙耳耳機的使用者可以在遮蔽吸塵器噪音的同時關注語音,b)遮蔽街道噪音並專注於鳥鳴,c)遮蔽建築噪音但聽到汽車鳴笛,d)正在冥想的使用者可以使用耳機遮蔽外面的交通噪音但聽到鬧鐘的聲音。

圖2:語意聽覺架構。雙耳輸入的聲音被有線降噪耳機捕捉並行送到手機上,我們在我們的聲音提取網路上執行
這提取了捕獲目標聲音(例如,警笛和貓的聲音)並抑制噪音和干擾聲音(例如,真空和交通噪音)的雙耳輸出。這種雙耳輸出是實時回放的
動物經過數百萬年的進化,已經專注於目標聲音和相關方向[32]。然而,通過耳機等入耳式裝置實現這種能力具有挑戰性,原因有三個。
- 實時要求。我們的設計輸出的聲音應該與使用者的視覺感官同步。這需要實時處理,滿足嚴格的延遲要求。對醫療助聽器和增強音訊的研究表明,我們要求延遲小於20-50 ms[24,59]。這需要使用10毫秒或更少的音訊塊識別目標聲音,將它們與干擾聲音分離,然後播放它們,所有這些都在智慧手機等計算能力受限的裝置上。
- 雙耳處理。聲音以不同的延遲和衰減到達雙耳[64]。兩耳之間的物理分離和來自佩戴者頭部的反射/衍射(即與頭部相關的傳遞函數),為空間感知提供線索。為了儲存這些線索,我們需要雙耳輸出來儲存或恢復跨兩耳的目標聲音的這種空間資訊。
- 現實世界的泛化。雖然在合成資料上訓練和測試神經網路在音訊機器學習研究中很常見,但設計一個能泛化到現實世界可聽應用的雙耳目標聲音提取網路是具有挑戰性的。
這是因為在模擬中很難完全捕捉真實世界混響和頭部相關傳遞函數(HRTF)的複雜性。然而,我們需要將其泛化到不同使用者在未見過的聲學環境中進行野外使用。
本文解決了上述挑戰,並使用可聽裝置演示了語意聽力(我們對「語意聽覺」這個名字的啟發是定向聽覺,它是從特定方向聽到聲音的能力[10,16,67]。同樣,語意聽覺是指聽到某些語意描述(如聲音類)所指定的聲音的能力)。為了實現我們的目標,我們做出了兩個關鍵的技術貢獻。
- 我們設計了第一個能夠實現雙耳目標聲音提取的神經網路。我們的網路將來自兩耳處麥克風的兩個音訊訊號作為雙耳輸入,並輸出兩個音訊訊號作為雙耳輸出,同時保留了目標聲音在聲學場景中的方向性。為了做到這一點,我們從我們最近的用於目標聲音提取的單通道(不是雙耳)transformer模型開始[66],該模型既沒有現實世界的評估,也沒有實時的智慧手機操作。首先,我們優化了網路以實現智慧手機上的實時操作。然後,我們設計了一個聯合處理雙耳輸入訊號的網路,使其能夠保留關於目標聲音的空間資訊並輸出雙耳音訊(見§3.2)。這種聯合處理在雙耳目標聲音提取方面更有效,並且比單獨處理雙耳輸入訊號的計算成本低一半。
- 我們還設計了一種訓練方法,以確保我們的雙耳網路可以推廣到現實世界的情況,如混響、多路徑和HRTF。在完全自然的環境中獲得訓練資料可能是困難的,因為我們可能捕獲混合物,但是缺乏獲得監督學習所需的真實聲音的途徑。此外,訓練一個可以用可聽裝置推廣到野外使用的網路需要訓練資料在大量使用者中捕獲迴響、多徑和頭部相關的傳遞函數。為了實現這一點,我們使用多個資料集來合成我們的訓練資料。首先,我們使用了一個HRTF資料集,其中包括來自41個使用者在非混響環境中的測量。我們將房間脈衝響應與來自20個不同音訊類別的數千個範例進行折積,以生成我們的混合物和真實的雙耳音訊。然而,這並沒有捕捉到現實環境中的混響和多徑。因此,我們用從三個不同的資料集合成的訓練資料來增強這些合成的混合物,這些資料集提供了在真實房間中捕獲的雙耳房間脈衝響應。這有助於我們的網路泛化到訓練資料集中沒有的使用者和現實世界環境。
為了證明概念,我們用商用有線雙耳耳機增強了現有的降噪耳機,該耳機可以存取兩個麥克風的資料。我們在連線的智慧手機上實現我們的神經網路,並用20種不同的聲音類別對其進行訓練,包括警笛聲、嬰兒啼哭聲、語音、吸塵器、鬧鐘和鳥叫聲。我們的結果如下。
- 在干擾聲音和城市背景噪聲存在的情況下,我們實現了20種目標聲音的平均訊號改善7.17 dB。我們的實時網路在iPhone 11上處理10毫秒的雙耳音訊時執行時間為6.56毫秒。
- 使用我們的硬體在各種室內和室外場景中對參與者進行的野外評估表明,我們的系統可以提取目標聲音(圖3)並泛化到以前未見過的參與者和環境,而不需要使用我們的可聽硬體收集任何訓練資料。
- 在一項空間聽覺研究中,我們在以前未見過的房間中播放來自不同方向的聲音,參與者能夠預測我們系統輸出的目標聲音的方向,第50和90百分位誤差分別為22.5◦和45◦。對於無噪音的乾淨聲音,這些誤差是相似的。
- 在一項有22名參與者的使用者研究中,他們花了超過330分鐘對來自真實室內和室外環境的雙耳資料進行評級,我們的系統對目標聲音取得了比雙耳輸入更高的平均意見分數和干擾消除。
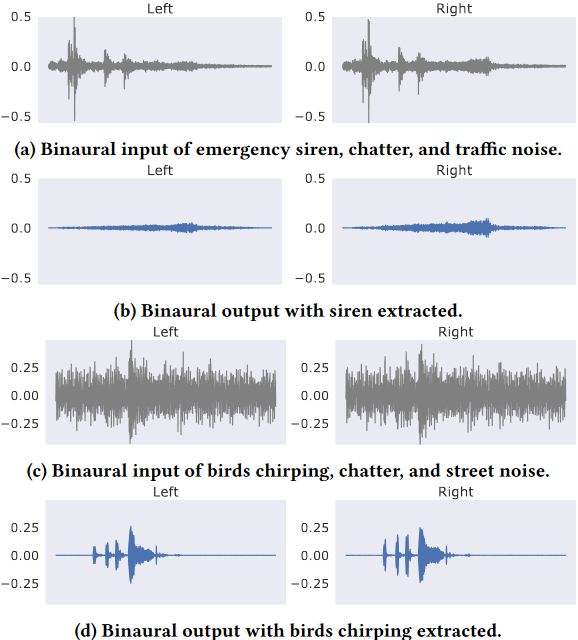
圖3: 用我們的語意聽覺系統獲得的真實世界的雙耳輸入和輸出錄音
貢獻。我們引入了語意聽覺的概念,我們可以基於語意聲音描述來程式設計雙耳聲學場景。我們的工作做出了五個關鍵貢獻。
- 1) 提出了第一個實現雙耳目標聲音分離的神經網路,並證明了我們的網路可以在智慧手機上實時執行,
- 2) 設計了一種訓練方法,將我們的系統泛化到未見過的現實世界環境和使用者,
- 3) 用現成的硬體實現了概念驗證,並表明我們的系統在現實世界環境中實現了上述目標,
- 4) 強調了我們當前系統的失敗之處和未來研究的機會
- 5) 通過公開我們的雙耳模型和資料集,我們希望啟動社群未來的研究,進一步在實際的可聽應用中發展語意聽力的概念。
2 背景及相關工作
在過去的十年中,降噪耳機和耳塞經歷了顯著的改進,現在可以更有效地衰減環境中的所有聲音。事實上,在我們的實驗中,我們給戴著索尼WH-1000XM4耳機的人類受試者播放白噪聲,顯示了這些現代系統令人印象深刻的衰減能力(圖4)。我們認為這是一個機會,為我們提供了一個聲學上的全新記錄,可以從環境中引入目標雙耳聲音。據我們所知,之前的工作都沒有探索可聽裝置的語意聽力能力。在本節的其餘部分,我們將介紹可聽系統、音訊訊號處理和機器學習以及互動工具方面的相關工作。
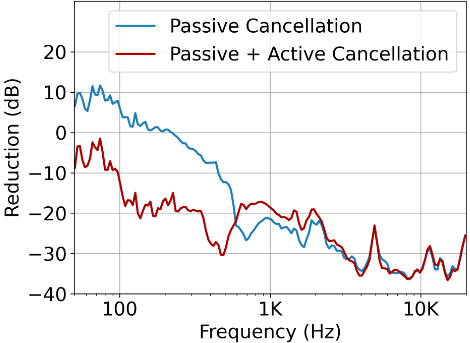
圖4: 索尼WH-1000XM4耳機的降噪效果——開啟和不開啟主動降噪——使用耳機耳罩的入耳式麥克風進行測量
降噪是相對於耳杯外的麥克風錄音測量的。低頻(< 100hz)下的偽大值是由於入耳式麥克風採集了佩戴者的血液脈搏
主動噪聲消除和聲學透明(acoustic transparency)。主動噪聲抵消是一個得到充分研究的問題,其中外向麥克風用於捕獲聲音[58]。然後傳輸一個抗噪聲訊號來抵消所有外部聲音和噪聲,這比語意聽力有更嚴格的延遲要求。傳統的降噪系統需要笨重的耳機。然而近年來,像AirPods Pro這樣的輕量級入耳式耳塞系統在許多實際場景中都可以實現合理的降噪[1]。語意聽力利用降噪耳機來消除所有聲音,然後利用本文中的機制來實時程式設計聲學場景。
入耳裝置的聲學透明模式試圖通過將適當的訊號傳輸到耳道[31]來模仿開耳系統的聲音響應。就像主動噪聲消除一樣,這與聲音類別無關。蘋果airpods上的自適應透明度設計可以自動降低大聲聲音的振幅[3]。雖然相關,但這並不允許使用者挑選和選擇要聽的聲音類別。
語音系統。之前的系統主要專注於改善入耳式裝置(如Airpods)、電話(如微軟團隊)和語音的語音相關任務的效能助手(如谷歌Home)。這包括語音增強[14,41]、目標語音提取[17,22]和語音分離[37,60]。通常情況下,這些系統將所有非語音聲音統稱為噪聲。相比之下,語意聽覺要求在干擾聲音存在的情況下,實時理解各種自然和人工聲音的語意,並根據使用者的輸入,決定允許哪些聲音,阻止哪些聲音。語音是我們系統中許多其他聲音類中的一種。
目標聲音提取的神經網路。目標聲音提取是將一個或有限數量的目標聲音從混合聲音中分離出來的任務。與語音系統相比,這是音訊機器學習社群中一個未被充分探索的問題。然而,最近的工作提出了可以實現目標聲音提取的神經網路,其中有關目標聲音的線索可以通過音訊[15,21]、影象[19,69]、文字[33,35]、擬聲詞[46]或one-hot向量[45]提供。所有這些模型都是為音訊片段的精細處理而設計的,其中神經網路可以存取整個音訊fle(≥1 s),因此不能支援我們的實時可聽用例。
最相關的工作是我們最近對Waveformer[66]的研究,它引入了一種用於目標聲音提取的神經網路架構。Waveformer在臺式計算機上實時執行。我們的工作在兩個重要維度上與[66]不同。首先,Waveformer是一個單通道模型,在一個麥克風上工作。相比之下,我們的目標用例需要跨雙耳進行雙耳處理。正如我們在§4.4中所示,在兩個麥克風上獨立執行之前的模型計算成本很高,無法滿足智慧手機上的實時性要求。其次,該領域的所有之前工作都是在合成資料集上進行評估的,並沒有在現實世界的場景中在硬體上進行演示。相比之下,本文提出了第一個可以在智慧手機上實時執行的雙耳目標聲音提取系統。我們設計了一種訓練方法,使我們的系統能夠泛化到未見過的室內和室外真實環境。
可聽應用程式。最近的工作將入耳式感測器用於健康應用[11-13]和活動跟蹤[39,52]。之前的工作還探索了入耳裝置的各種互動方式,如超聲波感測[68]和麵部互動[70]。與我們的工作最接近的是Clearbuds[14],它專注於使用兩個無線耳塞的同步音訊訊號來增強佩戴者的語音。之前的這項工作專注於語音增強,與我們的系統互為補充。此外,由於[14]的目標應用程式是電話,它使用44.8 ms的look-ahead,並具有109 ms的延遲。
基於音訊的工具。之前的工作探索了使用聲音來為可穿戴裝置和智慧家居應用程式執行活動識別[28,29,34,36,43,63,71]。這些系統在大約1s的音訊塊上執行,因為目標用例不具有入耳音訊應用的O(10 ms)延遲要求。之前的工作還設計了用於音訊編輯的互動工具[49,55]。我們的工作是互補的,因為它專注於具有更嚴格延遲要求的入耳音訊應用和語意聽力。
3 語意聽力
我們首先描述我們的系統需求,然後介紹我們用於智慧手機上實時雙耳目標聲音提取的網路架構。接下來,我們介紹了我們的訓練方法——將我們的設計推廣到現實世界的使用。
3.1 系統需求
我們設計的目標是對具有不可察覺的延遲的聲學環境進行程式設計,以便留下感興趣的目標聲音,但所有其他干擾聲音都被抑制。考慮到嚴格的延遲限制,我們不能在雲端執行必要的計算,而必須使用計算受限的裝置(如智慧手機)進行實時操作。此外,模型生成的目標聲音必須來自與現實世界目標聲音相同的空間方向。因此,我們的設計必須滿足兩個關鍵要求: 1)實時低延遲操作,以及2)雙耳真實世界泛化。
實時低延遲操作。圖5顯示了雙耳聲學處理系統中影響端到端延遲的不同元件。第一步是將聲音訊號輸入到雙耳麥克風的兩個記憶緩衝器中。然後將來自每個塊中的兩個麥克風的聲學資料輸入到我們的神經網路中,該神經網路輸出一個塊長度的雙耳目標聲音資料。然後通過耳機上的兩個揚聲器播放這個雙耳輸出。

圖5: 系統需求。在雙耳目標聲音提取中,影響延遲的不同元件
為了確保通過耳機播放的音訊與使用者的視覺感官同步,我們需要這個端到端的延遲小於20-50 ms[24, 59, 67]。為了實現這一點,我們需要減少緩衝時長、向前看時長和處理時間。這是一個具有挑戰性的問題,原因有很多。1)較小的緩衝持續時間,比如10 ms,意味著該演演算法只有10 ms的當前資料塊,不僅可以理解聲學場景的語意,還可以將目標聲音與其他干擾聲音分開。雖然我們可以使用在當前塊之前到達的聲學訊號,但我們的許多目標聲音(例如敲門聲)不是連續的。從作業系統的角度來看,進一步減少緩衝區大小(比如2 ms)可能具有挑戰性,因為它可能增加系統呼叫的數量。2)雖然一個大的looka-head可以為神經網路提取目標聲音提供更多的上下文,但滿足我們的端到端延遲要求將我們在可用lookahead方面的餘地減少到幾毫秒。3)實時操作需要在塊本身的持續時間內處理每個聲學塊。這意味著處理一個10 ms的buffer需要少於10 ms的時間[67]。這可能具有挑戰性,因為神經網路並不以輕量級計算而聞名。此外,由於我們無法將資料傳送到雲端,處理必須在計算受限的裝置(如智慧手機)上進行。除了上述所有限制,作業系統也有I/O延遲,對於iOS上的音訊來說,I/O延遲約為4毫秒,具體取決於緩衝區大小[2]。
雙耳現實世界泛化。在現實生活中,目標聲音由於來自牆壁和環境中其他物體的反射而經歷混響和多徑傳播。更進一步,人的頭部和軀幹會反射和阻擋聲音。因此,目標聲音以不同的振幅和延遲到達兩耳。兩耳接收到的聲音的差異為人類提供了空間意識。因此,在我們的設計中,保持這些差異並通過耳機的兩個揚聲器以不同的振幅和延遲播放目標聲音至關重要。這是具有挑戰性的,因為目標聲音和干擾聲音可能位於不同的位置,並從與頭部相關的傳遞函數中體驗到不同的迴響和反射。此外,在現實世界的環境中,多徑效應和混響都很難預測,更不用說頭部相關的傳遞函數會在不同佩戴者之間發生變化。
3.2 雙耳目標聲音提取網路
我們首先解釋我們的雙耳目標聲音提取神經網路的高層框架。然後我們解釋這個網路的因果關係和流適應。最後,我們提供了網路架構的詳細描述。
3.2.1 高層框架。將$s\in R^{2*T}$視為提供給目標聲音提取網路的輸入雙耳訊號。由於時域模型也已被證明能夠學習類似於STFT特徵[38]的表示,因此我們的網路在時域雙耳訊號上執行。如圖6a所示,通過使用核大小$\ge $L,步長等於$L$的一維折積層,訊號首先被對映到潛空間中的表示$x\in R^{D*(T/L)}$。$D$和$L$是模型的可調超引數。$D$是模型的維度,對引數計數有顯著影響,進而對計算和記憶複雜性有顯著影響。L確定可以用該模型處理的最小音訊塊的持續時間。隱空間表示$x$,然後傳遞給掩碼生成器,M,它估計一個元素級mask:
$$公式1:m=\mathcal{M}(x, q) \mid m \in R^{D \times(T / L)} ; q \in\{0,1\}^{N_c} \text {, }$$
其中$N_c$為模型訓練的聲音類的總數。目標聲音對應的表示是通過輸入表示(x)和掩碼(m)的元素相乘得到的,如下所示:
$$公式2:y=x \odot m \mid y \in R^{D \times(T / L)}$$
然後,通過對y應用1D轉置折積,步幅為L,獲得輸出音訊訊號$\hat{s}\in R^{2*T}$。
相比於專門為語音提出的更復雜的雙耳提取框架,其中每個通道都是單獨和並行處理的[23,25],我們的設計聯合處理兩個通道以提高計算效率。在我們的實驗中,我們表明,我們更簡單的框架在目標聲音提取精度方面與之前的並行處理框架具有競爭力,即使執行時成本降低了50%。
3.2.2 流式推理和因果關係。對於裝置上的實時操作,模型必須在接收到輸入音訊後立即輸出與目標聲音相對應的音訊,即在§3.1詳細的延遲要求內。由於音訊是從裝置緩衝區饋送給模型的,緩衝區大小決定了模型在每個時間步上接收的音訊塊的持續時間。假設緩衝區大小可以被步幅大小L整除,則音訊塊大小可以表示為步幅數K,即大小為K的音訊塊的緩衝區大小等於KL個樣本。這種實時設定意味著模型只能存取當前和以前的塊,而不能存取將來的塊。這要求模型與緩衝區大小的時間解析度(即KL音訊樣本)是因果關係。因此,在上面描述的高階框架中,輸入折積、掩碼估計塊、元素乘法和輸出轉置折積必須在每個時間步對一個音訊塊進行操作。
在§3.2.1中描述的雙耳目標聲音提取框架可以適應如下塊流式推理。考慮與第k塊對應的輸入音訊訊號為$s_k\in R^{2*KL}$。輸入1D折積將這個音訊塊對映到它的潛在空間表示$x_k\in R^{D*K}$。然後使用掩碼估計塊根據當前塊以及有限個之前的塊來估計目標聲音對應的掩碼:
$$公式3:m_k=\mathcal{M}\left(x_k, q, x_{k-1}, x_{k-2}, \ldots\right) \mid m_k \in R^{D \times K}$$
前面的塊充當神經網路的音訊上下文,稱為模型的感受野。1-1.5s的感受野被證明會導致良好的效能[38]。目標聲音對應的當前分塊的輸出表示$y_k\in R^{D*K}$則可以得到如下:
$$公式4:y_k=x_k\odot m_k$$
然後通過應用1D轉置折積,將得到的輸出表示轉換為輸出訊號$\hat{s}_k\in R^{2xKL}$。
3.2.3 掩碼估計網路。文獻中已經提出了幾種用於掩碼估計的架構,如convt - tasnet[38]、U-Net[30]、SepFormer[60]、ReSepFormer[61]和Waveformer[66]。Waveformer是最近提出的一種高效的流架構,實現了基於塊的處理,這使得它適合我們的任務。在這項工作中,我們提出了一個改進版本的Waveformer,以進一步提高效率而不損失任何效能。掩碼估計網路是一個編碼器-解碼器神經網路架構,其中編碼器是純折積的,解碼器是一個變壓器解碼器。
與Waveformer不同的是,在這項工作中,我們對編碼器和解碼器使用相同的維度。這允許我們使用標準的transformer解碼器[65],而不是在Waveformer中使用的修改過的。與模型的其餘部分相比,Waveformer為解碼器塊提供了更小的維度。不同維度之間的過渡是通過使用投影層(核大小等於1的一維折積層)實現的。
然而,這會破壞剩餘路徑,結果可能會影響梯度跟蹤,這在Waveformer中使用繞過解碼器的長剩餘連線來減輕。然而,對於我們的雙耳應用程式,我們發現不同維度並不一定提供保證投影層和長殘差連線複雜性的收益。
編碼器。公式3中的掩碼估計涉及除當前塊之外的許多先前塊的處理,以獲得與當前塊相對應的掩碼。對每個迭代的整個感受野的重複處理對於實時裝置上的應用程式來說可能會變得難以處理。為了減輕這種低效率,在實現大接受域的同時,我們的掩碼估計網路實現了一個Wavenet[47]風格的擴充套件因果折積來處理輸入和之前的塊。在這項工作中,為了有效的裝置上推理,我們實現了Fast Wavenet[48]中提出的動態規劃演演算法。如圖6b所示,通過重用之前迭代中計算的中間結果,實現了更高的效率。編碼器函數$\varepsilon $處理輸入塊$x_k$,編碼器上下文$\xi_k$生成輸入塊的編碼表示:
$$公式5:e_k, \xi_{k+1}=\mathcal{E}\left(x_k, \xi_k\right) \mid e_k \in R^{D \times K}$$
上下文$\xi_k$的大小取決於編碼器的超引數。在我們的實現中,編碼器由一堆10個擴張的因果折積層組成。所有層的核大小都等於3,膨脹因子從1開始在每層之後逐漸翻倍,導致膨脹因子$\{2^0,2^1,...,2^9\}$。由於核心大小等於3,每個擴充套件折積層所需的上下文是該層擴充套件因子的兩倍。只要在每次迭代之後儲存此上下文,並在下一個迭代中填充輸入塊,那麼與前一個塊對應的中間結果就不必重新計算。因此上下文的大小$\xi_k$等於$2\sum_{o=0}^92^i=2046$。
解碼器。首先使用線性層將查詢向量q嵌入到嵌入空間中以生成嵌入$l \in R^D$的標籤。與目標聲音$m_k$對應的掩碼是使用變壓器解碼器層[65]來估計的,這裡表示為$d$。編碼的表示首先通過元素乘法來約束標籤嵌入$l$。編碼表示和條件編碼表示首先在時間維度上與來自前一個時間步長的表示進行連線,然後再與變壓器解碼器層$d$進行處理。來自前一個時間步長的編碼表示$e_{k-1}$充當解碼器上下文。掩碼估計可以寫成:
$$m_k=\mathcal{D}\left(\left\{l \cdot e_{k-1}, l \cdot e_k\right\},\left\{e_{k-1}, e_k\right\},\right)$$
其中{}表示時間維度上的連線。如圖6c所示,transformer解碼器D首先使用第一個多頭注意力塊計算條件編碼表示$\{l*e_{k-1},l*e_k\}$的自注意力結果,然後使用第二個多頭注意力塊計算自注意力結果與非條件編碼表示$\{e_{k-1},e_k\}$之間的交叉注意力。 前饋塊與殘差連線一起生成對應於目標聲音的最終掩模。

圖6:雙耳目標聲音提取網路架構。a)我們的高層雙耳提取框架。掩碼估計網路是一個基於雙耳訊號潛空間表示的編碼器-解碼器架構,以基於查詢向量為目標聲音提取掩碼。B)和c)顯示了掩碼估計網路中使用的編碼器和解碼器架構。編碼器處理之前的輸入上下文,不考慮標籤嵌入。解碼器首先用標籤嵌入條件所編碼的表示,然後使用條件表示生成與目標聲音對應的掩碼。
3.3 真實世界泛化的訓練
我們首先描述了我們的音訊類資料集策劃,然後介紹了我們的訓練方法,以泛化到現實世界的場景。
3.3.1選擇音訊類。我們的主要目標是建立一個系統,有效地處理在現實世界中遇到的目標聲音。通過專注於實際應用,我們確定了一組可管理的目標聲音類別來提取。然而,在現實中,我們會遇到範圍廣泛的背景聲音,其中許多並不屬於我們的目標聲音類別。為了整理我們的聲音類資料集,我們遵循AudioSet本體[20],它提供了各種聲音類之間關係的全面和結構化表示。該本體將聲音類安排為圖中的節點,並將其分組為7個主要聲音類別。每個聲音類節點都有一個唯一的AudioSet ID,並且可以包含一個或多個代表更具體聲音類的子節點。例如,「雙手」聲音類有兩個子節點,即「掰手指」和「拍手」。在本節的其餘部分,我們將描述如何選擇我們的目標聲音類以及干擾類。
•目標聲音類別。我們首先考慮系統可能執行的各種室內和室外場景,如海灘、公園、街道、客廳、ofces和咖啡館。基於這些場景,我們識別了在這些位置普遍存在的潛在聲源,如人類語音、狗、貓、鳥類、海浪和音樂。然後,我們編譯與這些選定的目標聲音相關聯的聲音類列表,並將這些類中的每個對映到AudioSet本體中的標籤。我們最終選擇了20個聲音類別,我們認為人類聽眾可以以相當高的精度區分它們。
•其他聲音類別。在現實世界中,干擾聲音和噪聲往往不屬於我們的20個目標聲音類別。為了建立一個能夠概括這些聲音干擾的神經網路,我們需要在資料集中有一組不同的干擾聲音類別(注意,目標聲音類別也可能相互干擾。),這帶來了幾個挑戰。首先,這些聲音可能來自非常多的來源,使其不可能詳盡地列舉所有的來源。其次,由於我們想要將它們用作干擾訊號,我們必須確保這些聲音類別不與我們的目標類別集合重疊。為了克服這些限制,我們使用AudioSet分層結構和我們的20個目標類的集合來生成一個包含141個其他聲音類的大型集合。具體地說,根據AudioSet層次結構,我們可以將此集合定義為既不是更具體也不是任何目標(或已知)類的更一般範例的節點。換句話說,通過將AudioSet本體視為一個有向無環圖,其邊從每個聲音類節點指向其子節點,我們將未知聲音類定義為與所有目標聲音類節點斷開的AudioSet節點集。
3.3.2音訊資料集策劃。給定目標和其他聲音類別的集合,我們接下來獲得每個聲音類別的帶標籤的音訊錄音。挑戰在於,我們不能像之前的單通道工作[66]那樣只依賴單一的通用音訊標記資料集,這是因為這樣的資料集不包含所有20個目標聲音類別的音訊樣本,而可能包含來自其他聲音類別的音訊樣本數量有限。因此,我們結合了來自四個不同資料集的音訊樣本: FSD50K[18](通用),ESC-50[51](環境聲音),MUSDB18[53](音樂和人聲)和DISCO[44]資料集的噪聲(噪音)。由於每個資料集使用不同的類名,我們通過將每個資料集中的每個類對映到AudioSet本體中語意上最接近的標籤(如果有的話),將類標籤標準化為AudioSet標籤。對於FSD50K和MUSDB18,我們執行了額外的資料集特定的預處理程式。具體來說,因為我們的目標是建立來自多個方向的單個聲源的雙耳混合,我們排除了來自FSD50K的音訊樣本,這些樣本已經是多個不同聲源的混合。對於MUSDB18,我們將音訊提取並拆分為人聲流和器樂流,並分別為它們分配AudioSet標籤「Singing」和「Melody」。
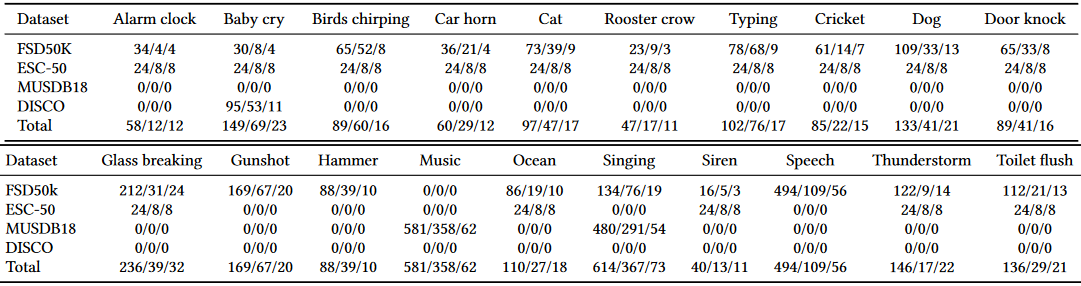
我們將產生的音訊樣本劃分為15秒的片段,並丟棄所有無聲的片段。我們將每個資料集分成互斥的訓練集、測試集和驗證集,然後將它們組合成我們的fnal資料集。對於FSD50K和MUSDB18,我們對來自開發分裂(90-10分裂)的訓練和驗證音訊檔以及來自評估分裂的測試樣本進行取樣。對於ESC-50資料集,我們使用前三倍用於訓練,第四倍用於驗證,第五倍用於測試。對於DISCO噪聲資料集,每個聲音類的音訊樣本在與其他資料集結合之前被分成訓練集、測試集和驗證集(60-33-7)。最終組合資料集由20個目標類組成,分佈如表1所示,以及141個其他聲音類。
表1: 為我們潛在的目標類別從每個資料集為訓練/測試/驗證收集的原始音訊類內的數量。我們使用這些用於訓練、測試和驗證生成的混合總數分別為100k、10k和1k
3.3.3 雙耳資料合成。上面的過程描述了我們如何從各種音訊資料集中取樣單通道聲音類。然而,我們的目標是建立雙耳混合(1)代表不同聽眾群體感知的空間聲音,(2)捕捉真實世界混響環境的特質。為此,我們使用已有的43個人類頭部相關傳遞函數(HRTF)測量資料集(CIPIC[8])來解決第一個挑戰。我們還用測量的(SBSBRIR [57], RRBRIR[26])和模擬的(CATT RIR[27])混響雙耳房間脈衝響應(BRIRs)的三個資料集來增強這一點,以解決第二個要求。我們將房間和聽眾之間的每個資料集劃分為訓練、測試和驗證集(70-20-10)。我們確保沒有BRIR受試者或房間在不同的集合中抽樣。對於訓練期間的每個樣本,我們隨機選擇一個資料集,並從其訓練集中取樣單個房間和參與者。然後,為了建立一個有K個源的雙耳混合,我們從這個房間和資料集中這個參與者的所有可用的源方向中,獨立地為每個K個源選擇一個源方向。請注意,由於聲源方向是獨立選擇的,因此兩個不同的聲源最終可能位於佩戴者的同一方向。
然後我們得到一組2K房間脈衝響應$h_{1,L},h_{1,R},h_{2,L},...,h_{K,R} \in R^N$,其中N是房間脈衝響應的長度。因此,對於輸入音訊訊號長度為T個樣本的訓練樣本,用$x_1,x_2,...,x_n\in R^T$表示,我們可以將左右耳接收到的聲音$s_L$和$s_R$分別計算為,$s_L=\sum_{k=1}^Kx_k*h_{k,L}$和$s_R=\sum_{k=1}^Kx_k*h_{k,R}$。這裡的*表示折積運算。合成的雙耳音訊混合在44.1 kHz取樣。如果我們的HRTF資料集中的房間脈衝響應具有不同的取樣率,我們在折積之前和之後重新取樣訊號。
3.3.4 訓練程式。在訓練過程中,我們使用Scaper工具包[56]在上動態合成雙耳混合物。為了訓練和驗證,我們的雙耳混合由兩個隨機選擇的目標類別組成,每個類別相對於背景聲音的訊雜比為5-15,以及1-2個其他類別,每個類別相對於背景聲音的訊雜比為0-5。我們還在我們的混合物中使用了來自TAU城市聲學場景2019資料集[42]的背景聲音。每個混合物長度為6秒。目標類和其他背景類的聲音時長在3 - 5秒之間,而背景城市聲音則會在整個混合過程中持續。除了混合之外,我們還對每個選定的目標聲源$y_L=x_t*h_{t,l}$和$y_R=x_t*h_{t,R}$分別在左通道和右通道合成ground truth y_L和y_R。
然後訓練網路以產生一對左右通道目標聲音估計$\hat{y}_L$和$\hat{y}_R$。為了保留空間線索,如耳間時差(ITD)和耳間電平差(ILD),我們使用樣本敏感和尺度敏感的訊雜比(SNR)損失函數,分別獨立應用,然後對左右訊雜比進行平均,得到損失函數:
$$\begin{gathered}
S N R(\hat{x}, x)=10 \log \left(\frac{\|x\|^2}{\|x-\hat{x}\|^2}\right) \\
L=-\left(\frac{1}{2} S N R\left(\hat{y_L}, y_L\right)+\frac{1}{2} S N R\left(\hat{y_R}, y_R\right)\right) .
\end{gathered}$$
最後,我們訓練了80個epoch的transformer模型,初始學習率為5e-4。在完成40個epoch後,如果超過5個epoch的驗證SNR沒有改善,我們將學習率減半。我們在這裡強調,訓練資料不包括使用我們的雙耳硬體的任何測量,我們在本文中報告的結果評估了對我們的硬體、未見過的使用者和環境的泛化。
4 結果
我們首先描述了我們的真實世界評估的設定,然後介紹了我們的雙耳網路基準。
硬體原型。我們的硬體設定包括一對SonicPresence SP15C雙耳麥克風,連線到捕捉高質量的錄音。我們使用iPhone 12處理錄製的資料,並通過JBL Live 650BTNC和NUBWO遊戲耳機等降噪耳機輸出音訊。我們使用lightning-to-aux介面卡將耳機通過電線連線到iPhone上。我們還使用USB集線器將麥克風和耳機連線到智慧手機上。
參與者。我們在野外和空間線索評估中招募了9個個體(3個女性,6個男性)。我們還邀請了22名參與者(6名女性,16名男性)參加我們的線上聽力研究。
4.1 野外評價
為了在現實場景中評估所提出的系統,我們進行了野外實驗來評估我們系統的有效性。
野外場景。5個人(3名女性和2名男性)戴著我們的硬體,在現實世界中收集聲音。這些實驗是在典型的應用程式設定中進行的: ofces、客廳、街道、屋頂、公園和洗手間。由於一些聲音類相對不太常見,我們的野外實驗有一個最常見的類的子集出現在我們的錄音中: 鬧鐘,汽車喇叭,敲門聲,語音,電腦打字,錘子,鳥叫和音樂。聲源的位置和運動是不受控制的,反映了現實世界的場景,其中聲源是可以移動的。此外,在所有的實驗中,參與者都擁有完全的自由移動他們的頭部,導致相對於麥克風的聲源位置隨時間變化(圖7)。因此,我們的野外評估既捕獲了移動佩戴者,也捕獲了現實世界場景中自然出現的移動聲源(例如,移動的汽車或飛行的鳥類)。

圖7: 在我們的野外評估中,目標聲音是存在城市環境噪聲下的鳥類啁啾聲的參與者。參與者可以自由地移動頭部,目標聲源也可以是移動的
評價過程。與我們的模擬訓練資料不同,我們沒有乾淨的、樣本對齊的ground True訊號來客觀地比較我們系統的雙耳輸出。因此,我們進行了一項聽力研究,以計算關於聲音提取準確性的平均意見得分(MOS)。這個指標對於評估我們的演演算法對終端使用者的感知質量至關重要,儘管它在之前的非語音聲音提取研究中經常被忽略。我們邀請了22名參與者(6名女性,16名男性,平均年齡34.6歲)參加線上聽力研究。該研究由16個部分組成。在每個部分,參與者評估3或4個5.0-8.5秒的音訊樣本的質量。每個部分播放的音訊樣本都是經過以下三種方式處理的野生錄音,針對相同的目標標籤: (1)原始錄音,(2)我們的128維雙耳網路的輸出,(3)我們的256維雙耳網路的輸出。對於涉及語音作為目標聲音的評估子集,我們還包括一個額外的第四個音訊樣本,該樣本是通過提取干擾類(例如敲門聲),然後從輸入錄音中減去它來估計目標語音。
我們進行了一個預篩選過程,以確保參與者使用合適的雙耳耳機。這包括播放兩個白噪音樣本,一個只來自左聲道,一個只來自右聲道。參與者被要求確認他們只聽到了來自正確的渠道。我們的參與者中有11人使用耳機,在我們的線上使用者研究中有11人使用耳塞。
我們基於干擾抑制和總體平均意見評分(MOS)來測量聲音提取質量,因為它們通常包含在語音增強質量評估中:
(1) 噪聲抑制: 背景聲音的干擾程度/可察覺程度?1 -非常干擾,2 -有點干擾,3 -明顯,但不干擾,4 -稍微明顯,5 -不明顯
(2) 總體MOS: 如果目標是專注於<TARGET>聲音,你的總體體驗如何?1 -差,2 -差,3 -尚可,4 -好,5 -優秀
結果。在圖8中,我們展示了使用者對我們的系統針對不同目標聲音標籤的干擾聲音抑制和整體質量提升的評價結果。結果表明,該系統具有顯著降低不需要的背景聲音的能力,如128維模型的總體噪聲抑制分數從2.01(對應於2 -有點干擾)增加到3.61(在3 -可注意,但不干擾和4 -輕微可注意之間),256維模型增加到3.84(略差於4 -輕微可注意)。我們在整體MOS改進方面也觀察到類似的趨勢,從輸入訊號的2.63分別改善到128維和256維模型處理後的3.54和3.80。圖3d和圖9還表明,我們的網路保留了目標聲音的時序,並且可以靜音目標聲音持續時間之外的噪聲。
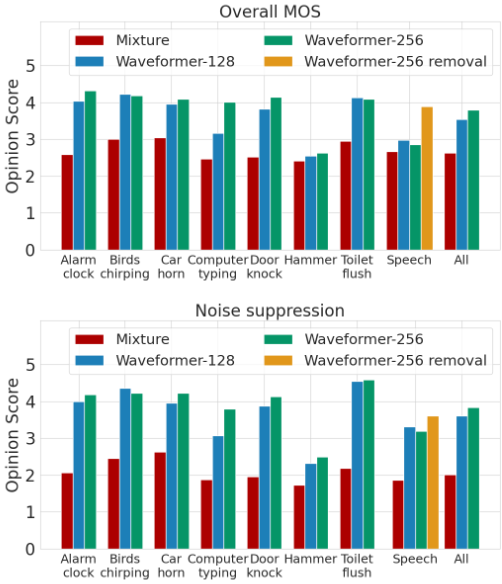
圖8: 實際資料收集中發生的各種類別的(a)平均意見評分(MOS)和(b)噪聲抑制的野外評估結果

圖9: 真實世界錄音的定性結果
結果還在每個類別的水平上提供了有趣的見解。一般來說,128通道模型在幾乎所有類別中只比256通道模型稍差,除了「計算機打字」類別,兩個模型之間的總體MOS差距幾乎為0.84 MOS點。這可能是由於在執行的發電機附近拍攝的特別嘈雜的錄音,128通道模型產生了微弱的、令人不快的偽影,這是256通道模型所沒有觀察到的。然而,兩個模型在「錘子」類中表現都很差,目標錘子的聲音是在干擾音樂存在的情況下錄製的。雖然網路正確地靜音了不包含錘子聲音的時間片段,但當有錘子聲音時,音樂中有明顯的殘留,聽眾發現這是干擾。這項研究的另一項重要發現是通過去除干擾訊號而獲得的顯著改善目標為語音時的輸入錄音。通過從錄製的訊號中去除敲門聲等短長度的聲音,而不是直接提取語音(見圖10),我們能夠將整體MOS提高0.91分。最後,值得注意的是,這些在野外的結果是從僅在合成資料上訓練的模型中獲得的,沒有對從我們的硬體收集的資料或為參與者進行任何訓練。

圖10: 在這裡提取語音作為目標會導致短暫的訊號過度衰減(在b中突出顯示),因為網路試圖刪除敲門聲和背景聲音。
然而,如果我們提取然後減去敲門聲,背景噪聲仍然是隱約存在的,得到的訊號聽起來不那麼刺耳。
4.2 評估使用者感知的空間線索
本文提出在fve普通的混響房間中進行的實驗,以評估我們的設計儲存或恢復使用者感知的空間線索的能力。與野外評估一樣,我們的訓練資料既沒有來自我們的硬體的樣本,也沒有來自經過測試的真實世界環境的樣本。
資料收集。我們從已知方向收集了目標聲音的真實音訊錄音。為了實現這一目標,fve參與者(3名男性,2名女性)被安裝了雙耳麥克風,並坐在位於一個巨大的、列印的半圓形量角器中心的旋轉椅子上,量角器的尺寸為70 ×36英寸,如圖11所示。量角器按常規22.5◦間隔(共9條線)排列,以進行精確的旋轉測量。Sony SRS-XB10揚聲器放置在量角器90◦線的固定三腳架上,以發出不同的聲音訊號。為了控制聲音訊號相對於聽者的到達角度,參與者被要求旋轉椅子,並與量角器的一條線對齊。資料收集分9個階段進行。在每個階段,使用者被旋轉到不同的角度。第一個階段從參與者面對180◦線開始。完成每個階段後,參與者順時針旋轉22.5◦到下一個標記的角度。在每個階段,揚聲器播放4個5秒的音訊樣本: (1)白噪聲,(2-3)兩個屬於目標聲音類的測試樣本,(4)一個屬於干擾其他聲音類的測試樣本。在資料收集的所有階段中,所選擇的音訊樣本正好包括來自9個不同的干擾其他聲音類別的9個測試樣本和來自6個不同的目標聲音類別的6個測試樣本。值得注意的是,來自目標類別的每個測試樣本都被記錄為3個不同的相對角度。
評價過程。由於我們的目標是開發一個能夠準確保留人類聽眾感知到的空間線索的系統,因此我們設計了一個使用者研究來計算我們系統輸出的目標雙耳聲音的感知到達角。為此,基於收集到的音訊記錄,我們首先通過從目標類別中取樣兩個音訊片段和從干擾其他類別中取樣1-2個片段來建立聲音混合物。使用Scaper生成這些混合物。我們選擇背景的參考響度為-50 LUFS,將目標類聲音的訊雜比設定為15-25 dB,將干擾其他類聲音的訊雜比設定為0-10 dB。我們通過選擇一個目標類別,並通過我們的網路執行混合聲音來處理每個混合聲音。
我們通過一對雙耳耳機將單個乾淨目標聲音的錄音不受干擾地播放,以及網路從建立的混合物中估計這些目標聲音的輸出樣本,播放給同一組參與者。由於感知到的空間線索在很大程度上依賴於人體測量特徵,所以播放給給定參與者的所有聲音訊號都來自於在資料收集步驟中從同一參與者獲得的雙耳資料。在聽每個樣本之前,參與者被告知他們應該定位的目標類別。聽完後,他們被要求預測聲源的方向。為了防止參與者將每個輸出樣本與其對應的單獨錄製的目標聲音相關聯,這些樣本按隨機順序播放。為了幫助參與者建立一個方向參考,我們在評估開始時按照遞增的順序播放每個角度的白噪聲樣本。此外,在兩個特定源角度之間存在不確定性的情況下,允許參與者重新收聽為這些角度錄製的白噪聲樣本。每名使用者的研究持續約20分鐘。
結果。我們比較了地面真值源方向和使用者感知到的到達方向之間的誤差,這些方向包括乾淨的無干擾目標聲音記錄,以及由我們的系統生成的雙耳目標聲音訊號的混合訊號輸入。我們的發現,如圖11所示,顯示平均角度誤差略有增加,從18◦到23.25◦。另外,我們觀察到,內插的第50和第90百分位誤差也分別從5◦增加到9◦和從38◦增加到42◦略有增加。這表明,我們的模型在其輸出中保留了目標聲音的空間線索,並且對使用者如何感知源方向的影響可以忽略不計。
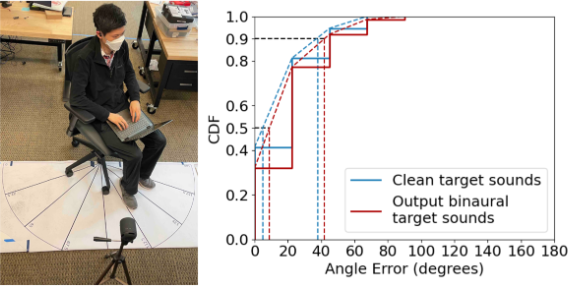
圖11: 空間線索評估。(左)評估設定,(右)聽了孤立的乾淨目標聲音以及網路輸出雙耳目標聲音後,ground True源方向和使用者感知源方向之間誤差的CDF
虛線是插值的cdf,用於計算插值的中位數和第90百分位誤差
4.3 與消噪耳機整合
到目前為止,我們將語意聽力和主動消噪視為兩個獨立執行的系統。然而,在實踐中,端到端系統還需要一些額外的考慮。首先,許多主動噪聲消除系統依靠耳罩內的記錄訊號自適應地靜音噪聲訊號,實現自適應噪聲消除。因此,我們回放用於執行語意聽力的音訊可能會影響噪聲消除演演算法。其次,主動噪聲消除系統並不完善,它們可能仍然會讓一些聲音通過。為了解決這些問題,我們在使用者使用我們的端到端系統時實時記錄資料。使用者戴著一副帶有主動降噪功能的索尼WH-1000XM4耳機。除了用於捕捉外部聲音進行處理的外部麥克風外,他們還在耳罩內佩戴雙耳麥克風,將主動降噪和語意聽覺系統產生的聲音記錄在一起,即使用者聽到的聲音。當附近的吸塵器開啟時,使用者會選擇聽敲門聲。僅就這個實驗而言,我們在一臺裝有英特爾酷睿i5 CPU的筆記型電腦上,對從外部麥克風錄製的音訊執行我們的語意聽覺演演算法。處理後的音訊通過耳機播放。
圖12(a)-(c)給出了三種雙耳訊號的聲譜圖: 記錄在外部麥克風的訊號,通過耳機播放的訊號,以及記錄在耳罩內部的訊號。我們證明,雖然內層耳罩錄製的聲音稍顯嘈雜,但我們清楚地看到,該系統可以抑制不需要的聲音(吸塵器),同時保留目標聲音(敲門聲)。這證明了這樣一個系統可以與主動降噪系統共存的可行性。我們注意到,為了減少殘餘噪聲,語意聽力子系統可能必須整合來自降噪耳機的殘餘音訊,以使回放訊號也適應殘餘噪聲。然而,這具有更嚴格的延遲要求,因此我們將其留給未來的工作。
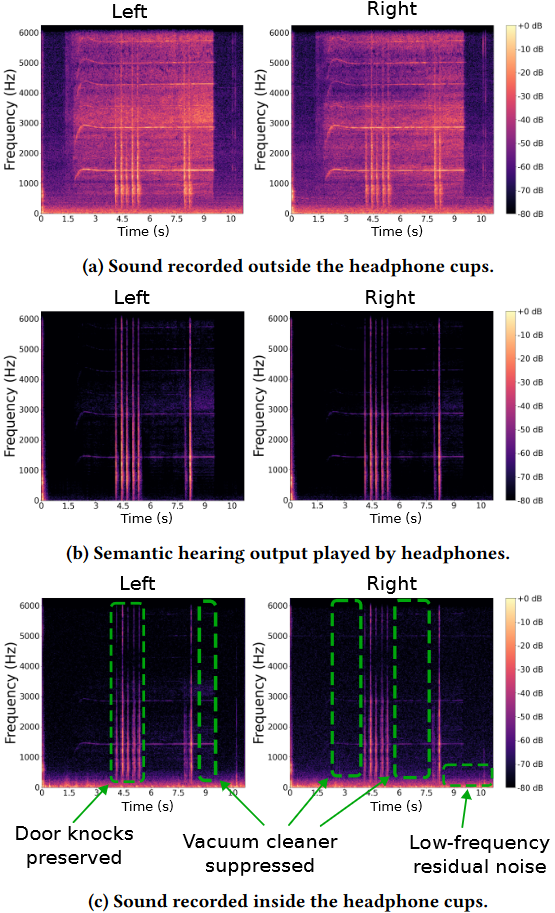
圖12: 雙耳錄音的聲譜圖顯示了我們使用穿戴式頭戴式裝置進行的端到端實驗的結果。在這裡,我們在附近有主動吸塵器的環境中提取敲門聲
4.4 對神經網路進行基準測試
由人類評估者進行的野外評估最接近真實世界的使用。然而,由於缺乏地面真實訊號,以及由於在獲得較小效能差距的統計顯著性所需的大量測試資料方面面臨挑戰,因此很難客觀地比較不同的模型。為了解決這些實際限制,本文還在一個廣泛的混響雙耳測試集上評估了所提出的模型,該測試集包括10000對混合和地面真值對。我們按照§3.3中的方法合成了基準資料集以模擬現實世界的情況。
為了評估我們的雙耳提取模型的效能,如表2所示,我們比較了以下三種雙耳目標聲音提取框架。
•Dual-ch。這是我們在§3.2.1中提出的用於高效雙耳目標聲音提取的雙連結架構。在這個框架中,雙耳訊號在進行掩模估計之前被轉換為組合潛空間表示。由於左右兩個通道被組合成一個共同的表示,因此使用掩碼估計網路的單個範例來估計目標聲音對應的掩碼。我們用�= 128和�= 256來考慮我們的掩碼估計架構。
•Parallel。這是[25]中提出的雙耳框架,它實現了左右通道的並行處理,以及通道之間的一些交叉通訊。[25]中的雙耳框架最初是為雙耳語音分離而提出的。我們在我們的掩碼估計網路D = 128和折積- tasnet[38]中實現了這個框架。我們包括折積網路,因為它是最廣泛使用的訊號增強模型體系結構之一。我們選擇了一種與我們的模型執行時相似的convt - tasnet設定,並使用我們的訓練資料集訓練了這兩個模型。
•Single-ch。除了上述兩種雙耳提取框架,我們還與單通道提取基線進行了效能評估和比較。由於我們考慮的目標聲音提取模型是樣本對齊的,因此用單聲道輸入和輸出訓練的模型可以獨立應用於左右通道。與平行的情況類似,這也涉及到掩模估計網路的兩個範例。然而,相比之下,應用於左右通道的模型引數是相同的,通道之間沒有交叉通訊。我們實現了模型的最佳設定(D= 256),因此這是一個強大的基線。
對於每個模型,我們在訊號質量、空間線索的準確性和裝置上的執行時間要求方面比較效能。我們使用與混合訊號相比,輸出的尺度不變訊雜比[54]改進(SI-SNRi)來測量訊號質量,並根據接地真值計算。SI-SNRi結果在整個測試集的左、右通道上取平均值。在[25]之後,使用輸出雙耳訊號與ground-truth雙耳訊號之間的雙耳時間差(ITDs)和雙耳水平差(ILDs)來測量空間線索準確性,記為ΔITD和ΔILD。我們使用互相關計算ITD,將它們限制在±1 ms內,就像在[40]中所做的那樣。模型執行時間是在iPhone 11上測量的,通過將它們轉換為ONNX格式[9],然後使用iOS的ONNX執行時執行它們。執行時間是在計算一個10毫秒的輸出塊時測量的,平均超過100次執行。因此,部署時的執行時間必須小於10 ms,這正是我們的D= 128的雙連結模型所滿足的。
在我們的實驗中,我們觀察到當只使用訊雜比損失進行訓練時,因果Conv-TasNet收斂到產生恆定零訊號的區域性最小值。這一現象也在文獻[66]中被觀察到,該文獻建議以90%訊雜比+ 10% SI-SNR損失的方式訓練Conv-TasNet。造成這種情況的可能原因是,與最初設計的語音資料集不同,聲音資料集具有大量的沉默,導致Conv-TasNet優化過程收斂到產生零訊號。另一方面,在雙耳情況下使用90% SNR + 10% SI-SNR的損失,導致其中一個通道相對於另一個通道輸出非常低的幅度訊號,因為SI-SNR對訊號增益不敏感。我們證實了這個訊號在頻譜上是有意義的,儘管它的大小是錯誤的。因此,只有SI-SNRi和ΔITD結果對Conv-TasNet模型有意義。ΔILD計算結果是無窮大,所以我們在表中省略了它。
在表2中,我們觀察到雙連結框架與並行和單通道框架在SI-SNRi方面具有競爭力,而在ΔILD方面表現優於並行和單通道框架。關於ΔITD,它導致了非常邊際的增長。這些結果直觀上是有意義的,因為雙連結框架對左右通道都有一個樣本對齊的共同表示。因此,它可以保持左右通道的相對振幅。另一方面,平行和單通道框架有獨立的分支,獨立處理不同的通道,有利於保持樣本與各自通道的對齊。這種現象在單通道框架中更為明顯,其中SI-SNRi和ΔITD很有前途,但ΔILD很差,因為左右通道處理之間沒有交叉通訊。最後,我們注意到,我們的雙連結框架只需要它們的並行或單通道對應程式所需的50%多一點的執行時間,這使它成為我們語意聽覺系統的一個很好的實用選擇。最後,我們注意到我們的雙連結框架使用240 MFLOPS,而vanilla Waveformer在兩個麥克風上使用357 MFLOPS。
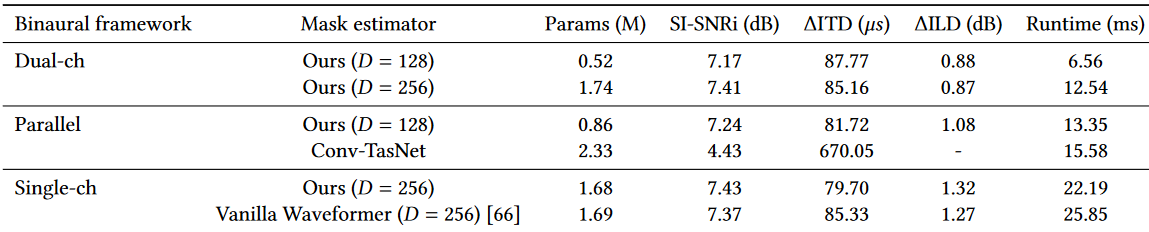
表2: 不同雙耳目標聲音提取框架和掩膜估計架構在使用§3.3中描述的方法生成的20個目標類的大型測試資料集上的效能和效率比較。
對於我們的因果模型,感受野僅是過去的音訊。因此,它對演演算法延遲沒有影響。我們模型的演演算法延遲是塊大小KL和輸入折積的前瞻L的總和,其中L是輸入折積的步幅(第3.2.2節)。表2使用stride L= 32個樣本,K= 13,得到的塊大小為KL= 416個樣本,forward L= 32個樣本。。這分別相當於9.4 ms和0.7 ms。表3展示了我們的雙耳模型在不同塊大小下的效能,以瞭解演演算法延遲對效能的影響。結果顯示,我們的模型以低至1.4 ms的演演算法延遲實現了合理的效能。因此,通過ASIC實現,如助聽器中的實現,我們可以設想超低延遲的語意聽力系統。
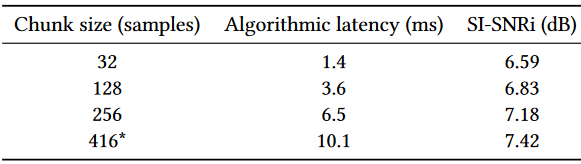
表3: 演演算法延遲對效能的影響。端到端延遲為20 ms的擬議系統
在我們的野外評估中,使用者自由地移動他們的頭並遇到移動源(例如。塞壬)。在人類測試人員的評估過程中,該模型也表現得非常穩健,沒有故障。該模型適應相對運動很快,因為它輸出小塊(<10ms),同時更新其內部狀態。該模型還可以利用軌跡中L和R通道之間有更好的水位差的空間位置。除了這種定性的評價,表4還提供了聽者和聲源之間不同數量的相對角運動的效能的定量比較。對於這個比較,我們使用了D=256維的dual-ch模型。我們使用Steam Audio SDK[7]模擬運動,它模擬給定SimpleFreeFieldHRIR格式[6]的HRTF檔案的雙耳運動。我們在回聲環境和混響環境中進行了不同角速度的對照實驗,聲源以給定的角速度從弧線上的隨機位置移動。我們使用CIPIC [8] HRTF資料集進行暗聲模擬,使用RRBRIR [26] BRIR資料集進行混響模擬,因為它們以SimpleFreeFieldHRIR格式提供了im脈衝響應。我們通過在每一幀使用雙線性插值與插值脈衝響應進行折積,在1024個樣本的幀中合成雙耳音訊。由於ILD和ITD現在是時變的,我們以250 ms的塊計算ΔILD和ΔITD,丟棄任何在兩個通道上乾淨訊號靜音的塊,並對剩餘塊取平均值。我們觀察到,在存在運動的情況下,SI-SNRi和ΔILD略好,因為模型能夠更好地利用不同相對角度位置的L和R之間的電平差,同時在消聲情況下實現較低的ΔITD,在混響情況下實現略高的ΔITD。

表4: 聽者和聲源之間存在相對角度運動時的效能比較。本次評估使用的是D=256的Dual-ch模型
4.5 概念驗證的使用者介面
最後,一個很自然的問題是: 使用者如何在類之間進行選擇?為了回答這個問題,我們製作了一個帶有三種不同聲音選擇使用者介面的iOS應用原型: 語音、文字和聲音的撥動開關網格(圖13),並評估了它們的準確性、速度和易用性。

圖13: 智慧手機上目標聲音選擇的使用者介面設計。
每種設計都使用了不同的輸入法來捕捉使用者的意圖: (從左到右)語音、文字和撥動開關
前兩個介面使用ChatGPT API將自然語言轉換為系統的類輸入
對於語音和文字介面,我們的目標是研究是否可以使用電話[4]的ChatGPT API將自然語言(我想聽救護車的聲音)轉換為我們系統的已知聲音類輸入(警報器+)。為此,我們使用提示符初始化了Chat-GPT: 下面是一個聲音類列表: [' alarm_clock ', ' baby_cry ',[…]我會給你提供一個句子,涉及保留或刪除這些聲音類中的一個。我希望你從列表中輸出與句子中的聲音(語意上)最匹配的聲音類。如果沒有足夠接近的類,則輸出` na `。請不要輸出任何其他字元。如果你找到一個接近的類,並且句子涉及到從這個標籤中保留聲音,在輸出後新增一個「+」,否則,新增「-」。例如,如果我說「mute cat」,你應該說「cat-」。如果我說「mute cow」,你應該說「na」。
10名參與者被展示了以下形式的10個場景: 你嬰兒的哭聲打破了沉默。你的手機播放了一段旋律。可以聽到風聲的沙沙聲。我們讓參與者選擇一個要新增或刪除的單一聲音事件,並通過三個使用者介面(ui)嚮應用程式傳達他們的意圖。為了評估每個介面的準確性,我們將通過每個UI選擇的聲音事件與我們對使用者所說的最佳解釋進行了比較。語音和文字協定率為92%,撥動開關協定率為93%。對於語音和文字,分歧是由於ChatGPT的混淆(例如,廁所太大聲對映到toilet_ush +),或者當ChatGPT將資料集中未選擇的聲音對映到資料集中類似的聲音時(例如,風和噴泉的聲音對映到海洋)。對於撥動開關,當無法找到所需的聲音類時,會發生不一致。
語音傳遞意圖的平均時間最短(5.5±1.0s),其次是切換(6.3±3.3s),文字傳遞意圖的平均時間最長(8.3±3.7s)。語音偏好評分(1=非常不可能,5=非常可能)最高(4.0±1.1),然後是文字(2.9±1.2),切換最低(2.7±1.4)。這些發現表明,從使用者介面的角度來看,Speech將是一個實用的介面選擇,並且隨著支援的類數量的增加,它將比切換介面具有更好的可伸縮性。一位參與者指出,他們在公共環境中使用系統時更喜歡文字介面,即使輸入他們的意圖需要更長的時間。
5 侷限性和討論
如表1所示,我們在跨類別的範例數量上存在不平衡。例如,「語音」類有494個訓練樣本,而「汽車喇叭」只有60個訓練樣本。在所有類別中收集更多的範例可以潛在地提高效能。最後,有些類別可能天生就比較難分離。例如,音樂和人類語言有許多共同的特徵,包括聲音和和聲。因此,儘管有大量的訓練樣本,但我們的模型仍然很難在背景音樂也有人聲的情況下執行分離佩戴者周圍人的語音等任務。同樣,將音樂與其他類別(如鬧鐘聲或鳥鳴聲)分開也是具有挑戰性的。此外,我們的訓練方法沒有利用任何現實世界的資料與我們的硬體。然而,我們的真實世界測試結果證明了對我們的可聽硬體以及未見過的真實世界環境的泛化能力。然而,仍然有可能在現實世界的場景中以及用實際的硬體收集訓練資料,可以幫助提高系統效能。
另一個限制是我們在評估中使用的可聽硬體的外形因素,我們在評估中除了使用降噪耳機外,還使用了雙耳耳機。如果我們使用單一裝置進行錄音和回放,外形因素可以簡化。目前,有一些商業降噪耳機可以為使用者提供麥克風資料的存取,比如Sennheiser AMBEO智慧耳機,這是我們在評估後發現的。我們的系統實現在這樣的裝置上,導線會更少,並且會在一個點上直接連線到智慧手機,而不需要額外的一對雙耳耳機。
雙耳目標聲音提取還可以用來減去目標聲音,並將剩餘的聲音播放到耳朵裡。圖10顯示了通過減去目標聲音(例如,計算機打字或錘子)來專注於人類語音的結果。當用戶知道他們感到討厭的特定型別的環境噪音時(例如,在ofce房間裡的電腦打字),這可能是有益的,因為這種方法將只刪除指定的噪音,從而允許使用者專注於環境中的語音和其他聲音。
為了進行概念驗證演示,我們已經在連線的智慧手機上實現了我們的神經網路。雖然連線到智慧手機的有線頭戴裝置是實際應用的重要用例,可以從我們的實現中受益,但將我們的系統擴充套件到無線頭戴裝置需要將計算與頭戴裝置硬體本身整合。考慮到目前正在為可穿戴裝置[5]設計的超低功耗多核嵌入式gpu,這可能是可行的。此外,隨著用於語音和自然語言處理的片上深度學習的客製化矽的最新進展[62],用於語意聽力的商業可聽裝置很可能會使用這種客製化矽來降低可穿戴裝置的功耗和端到端延遲。
6 結論
本文朝著利用聲音的語意描述在雙耳可聽裝置上實現聲學場景的實時程式設計邁出了重要的第一步。其核心是兩個關鍵的
技術貢獻: 1)第一個雙耳目標聲音提取神經網路。我們的網路可以實時執行,使用10 ms或更少的音訊塊,同時保留空間資訊,以及2)一種訓練方法,允許我們的系統泛化到未見過的現實世界環境。對參與者進行的野外實驗表明,我們的概念驗證的軟硬體系統可以保留目標聲音的方向,並將這些聲音實時地從背景噪聲和環境中的其他聲音中分離出來。
參考文獻
[1] 2023. Apple AirPods. https://www.apple.com/airpods/. (2023).
[2] 2023. Audio Latency Meter for iOS. https://onyx3.com/LatencyMeter/. (2023).
[3] 2023. Customize Transparency mode for AirPods Pro. https://support.apple.com/ guide/airpods/customize-transparency-mode-dev966f5f818/web. (2023).
[4] 2023. GPT models. https://platform.openai.com/docs/guides/gpt. (2023).
[5] 2023. GPU-WEAR, Ultra-low power heterogeneous Graphics Processing Units for Wearable/IoT devices. https://cordis.europa.eu/project/id/717850. (2023).
[6] 2023. SimpleFreeFieldHRIR. https://www.sofaconventions.org/mediawiki/index. php. (2023).
[7] 2023. Steam Audio SDK. https://valvesoftware.github.io/steam-audio/. (2023).
[8] V.R. Algazi, R.O. Duda, D.M. Thompson, and C. Avendano. 2001. The CIPIC HRTF database. In Proceedings of the 2001 IEEE Workshop on the Applications of Signal Processing to Audio and Acoustics (Cat. No.01TH8575). 99–102. https://doi.org/10.1109/ASPAA.2001.969552
[9] Junjie Bai, Fang Lu, Ke Zhang, et al. 2019. ONNX: Open Neural Network Exchange. https://github.com/onnx/onnx. (2019).
[10] Luca Brayda, Federico Traverso, Luca Giuliani, Francesco Diotalevi, Stefania Repetto, Sara Sansalone, Andrea Trucco, and Giulio Sandini. 2015. Spatially selective binaural hearing aids. In Adjunct Proceedings of IMWUT/ISWC.
[11] Nam Bui, Nhat Pham, Jessica Jacqueline Barnitz, Zhanan Zou, Phuc Nguyen, Hoang Truong, Taeho Kim, Nicholas Farrow, Anh Nguyen, Jianliang Xiao, Robin Deterding, Thang Dinh, and Tam Vu. 2021. EBP: An Ear-Worn Device for Frequent and Comfortable Blood Pressure Monitoring. Commun. ACM (2021).
[12] Justin Chan, Nada Ali, Ali Najaf, Anna Meehan, Lisa Mancl, Emily Gallagher, Ran- dall Bly, and Shyamnath Gollakota. 2022. An of-the-shelf otoacoustic-emission probe for hearing screening via a smartphone. Nature Biomedical Engineering 6 (10 2022), 1–11. https://doi.org/10.1038/s41551-022-00947-6
[13] Justin Chan, Sharat Raju, Rajalakshmi Nandakumar, Randall Bly, and Shyamnath Gollakota. 2019. Detecting middle ear fuid using smartphones. Science Trans- lational Medicine 11 (05 2019), eaav1102. https://doi.org/10.1126/scitranslmed.aav1102
[14] Ishan Chatterjee, Maruchi Kim, Vivek Jayaram, Shyamnath Gollakota, Ira Kemel- macher, Shwetak Patel, and Steven M Seitz. 2022. ClearBuds: wireless binaural earbuds for learning-based speech enhancement. In ACM MobiSys.
[15] Marc Delcroix, Jorge Bennasar Vázquez, Tsubasa Ochiai, Keisuke Kinoshita, Yasunori Ohishi, and Shoko Araki. 2022. SoundBeam: Target sound extraction conditioned on sound-class labels and enrollment clues for increased performance and continuous learning. In arXiv.
[16] Simon Doclo, Sharon Gannot, Marc Moonen, Ann Spriet, Simon Haykin, and KJ Ray Liu. 2010. Acoustic beamforming for hearing aid applications. Handbook on array processing and sensor networks (2010), 269–302.
[17] Sefk Emre Eskimez, Takuya Yoshioka, Huaming Wang, Xiaofei Wang, Zhuo Chen, and Xuedong Huang. 2022. Personalized speech enhancement: New models and comprehensive evaluation. In IEEE ICASSP.
[18] Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, and Xavier Serra. 2022. FSD50K: An Open Dataset of Human-Labeled Sound Events. (2022).arXiv:cs.SD/2010.00475
[19] Ruohan Gao and Kristen Grauman. 2019. Co-separating sounds of visual objects. In IEEE /CVF ICCV.
[20] Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. Audio Set: An ontology and human-labeled dataset for audio events. In IEEE ICASSP.
[21] Beat Gfeller, Dominik Roblek, and Marco Tagliasacchi. 2021. One-shot conditional audio fltering of arbitrary sounds. In ICASSP. IEEE.
[22] Ritwik Giri, Shrikant Venkataramani, Jean-Marc Valin, Umut Isik, and Arvindh Krishnaswamy. 2021. Personalized percepnet: Real-time, low-complexity target voice separation and enhancement. In arXiv.
[23] Rongzhi Gu, Jian Wu, Shi-Xiong Zhang, Lianwu Chen, Yong Xu, Meng Yu, Dan Su, Yuexian Zou, and Dong Yu. 2019. End-to-End Multi-Channel Speech Separation. In arXiv. arXiv:cs.SD/1905.06286
[24] Rishabh Gupta, Rishabh Ranjan, Jianjun He, Woon-Seng Gan, and Santi Peksi. 2020. Acoustic transparency in hearables for augmented reality audio: Hear- through techniques review and challenges. In Audio Engineering Society Confer- ence on Audio for Virtual and Augmented Reality.
[25] Cong Han, Yi Luo, and Nima Mesgarani. 2020. Real-time binaural speech separa- tion with preserved spatial cues. In arXiv. arXiv:eess.AS/2002.06637
[26] IoSR-Surrey. 2016. IoSR-surrey/realroombrirs: Binaural impulse responses cap- tured in real rooms. https://github.com/IoSR-Surrey/RealRoomBRIRs. (2016).
[27] IoSR-Surrey. 2023. Simulated Room Impulse Responses. https://iosr.uk/software/ index.php. (2023).
[28] Dhruv Jain, Kelly Mack, Akli Amrous, Matt Wright, Steven Goodman, Leah Findlater, and Jon E. Froehlich. 2020. HomeSound: An Iterative Field Deployment of an In-Home Sound Awareness System for Deaf or Hard of Hearing Users. In ACM CHI.
[29] Dhruv Jain, Hung Ngo, Pratyush Patel, Steven Goodman, Leah Findlater, and Jon Froehlich. 2020. SoundWatch: Exploring Smartwatch-Based Deep Learning Approaches to Support Sound Awareness for Deaf and Hard of Hearing Users. In ACM SIGACCESS ASSETS.
[30] Andreas Jansson, Eric J. Humphrey, Nicola Montecchio, Rachel M. Bittner, Aparna Kumar, and Tillman Weyde. 2017. Singing Voice Separation with Deep U-Net Convolutional Networks. In ISMIR.
[31] Wenyu Jin, Tim Schoof, and Henning Schepker. 2022. Individualized Hear- Through For Acoustic Transparency Using PCA-Based Sound Pressure Estimation At The Eardrum. In ICASSP.
[32] Gabriel Jorgewich-Cohen, Simon Townsend, Linilson Padovese, Nicole Klein, Peter Praschag, Camila Ferrara, Stephan Ettmar, Sabrina Menezes, Arthur Varani, Jaren Serano, and Marcelo Sánchez-Villagra. 2022. Common evolutionary origin of acoustic communication in choanate vertebrates. Nature Communications 13 (10 2022). https://doi.org/10.1038/s41467-022-33741-8
[33] Kevin Kilgour, Beat Gfeller, Qingqing Huang, Aren Jansen, Scott Wisdom, and Marco Tagliasacchi. 2022. Text-Driven Separation of Arbitrary Sounds. In arXiv.
[34] Gierad Laput, Karan Ahuja, Mayank Goel, and Chris Harrison. 2018. Ubicoustics: Plug-and-Play Acoustic Activity Recognition. In ACM UIST.
[35] Xubo Liu, Haohe Liu, Qiuqiang Kong, Xinhao Mei, Jinzheng Zhao, Qiushi Huang, Mark D Plumbley, and Wenwu Wang. 2022. Separate What You Describe: Language-Queried Audio Source Separation. In arXiv.
[36] Hong Lu, Wei Pan, Nicholas D. Lane, Tanzeem Choudhury, and Andrew T. Camp- bell. 2009. SoundSense: Scalable Sound Sensing for People-Centric Applications on Mobile Phones. In ACM MobiSys.
[37] Jian Luo, Jianzong Wang, Ning Cheng, Edward Xiao, Xulong Zhang, and Jing Xiao. 2022. Tiny-Sepformer: A Tiny Time-Domain Transformer Network for Speech Separation. In arXiv.
[38] Yi Luo and Nima Mesgarani. 2019. Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM transactions on audio, speech, and language processing (2019).
[39] Dong Ma, Andrea Ferlini, and Cecilia Mascolo. 2021. OESense: Employing Occlusion Efect for in-Ear Human Sensing. In MobiSys.
[40] Tobias May, Steven van de Par, and Armin Kohlrausch. 2011. A Probabilistic Model for Robust Localization Based on a Binaural Auditory Front-End. IEEE Transactions on Audio, Speech, and Language Processing 19, 1 (2011), 1–13. https://doi.org/10.1109/TASL.2010.2042128
[41] Emma McDonnell, Soo Hyun Moon, Lucy Jiang, Steven Goodman, Raja Kushal- naga, Jon Froehlich, and Leah Findlater. 2023. 「Easier or Harder, Depending on Who the Hearing Person Is」: Codesigning Videoconferencing Tools for Small Groups with Mixed Hearing Status. In ACM CHI.
[42] Annamaria Mesaros, Toni Heittola, and Tuomas Virtanen. 2018. A multi-device dataset for urban acoustic scene classifcation. In DCASE. https://arxiv.org/abs/1807.09840
[43] Vimal Mollyn, Karan Ahuja, Dhruv Verma, Chris Harrison, and Mayank Goel. 2022. SAMoSA: Sensing Activities with Motion and Subsampled Audio. IMWUT(2022).
[44] Furnon Nicolas. 2020. Noise fles for the DISCO dataset. (2020). https://github.com/nfurnon/disco.
[45] Tsubasa Ochiai, Marc Delcroix, Yuma Koizumi, Hiroaki Ito, Keisuke Kinoshita, and Shoko Araki. 2020. Listen to What You Want: Neural Network-based Universal Sound Selector, In arXiv. arXiv e-prints. arXiv:eess.AS/2006.05712
[46] Yuki Okamoto, Shota Horiguchi, Masaaki Yamamoto, Keisuke Imoto, and Yohei Kawaguchi. 2022. Environmental Sound Extraction Using Onomatopoeic Words. In IEEE ICASSP.
[47] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. 2016. WaveNet: A Generative Model for Raw Audio. In arXiv. https://doi.org/10.48550/ARXIV.1609.03499
[48] Tom Le Paine, Pooya Khorrami, Shiyu Chang, Yang Zhang, Prajit Ramachan- dran, Mark A. Hasegawa-Johnson, and Thomas S. Huang. 2016. Fast Wavenet Generation Algorithm. In arXiv. arXiv:cs.SD/1611.09482
[49] Amy Pavel, Gabriel Reyes, and Jefrey P. Bigham. 2020. Rescribe: Authoring and Automatically Editing Audio Descriptions. In ACM UIST.
[50] Mike Peterson. 2021. Apple AirPods, Beats dominated audio wearable market in 2020. https://appleinsider.com/articles/21/03/30/apple-airpods-beats-dominated- audio-wearable-market-in-2020. (2021).
[51] Karol J. Piczak. 2015. ESC: Dataset for Environmental Sound Classifcation. In ACM Multimedia.
[52] Jay Prakash, Zhijian Yang, Yu-Lin Wei, Haitham Hassanieh, and Romit Roy Choudhury. 2020. EarSense: Earphones as a Teeth Activity Sensor. In MobiCom.
[53] Zafar Rafi, Antoine Liutkus, Fabian-Robert Stöter, Stylianos Ioannis Mimilakis, and Rachel Bittner. 2017. MUSDB18 - a corpus for music separation. (2017).
[54] Jonathan Le Roux, Scott Wisdom, Hakan Erdogan, and John R. Hershey. 2018. SDR - half-baked or well done?. In arXiv.
[55] Steve Rubin, Floraine Berthouzoz, Gautham J. Mysore, Wilmot Li, and Maneesh Agrawala. 2013. Content-Based Tools for Editing Audio Stories. In ACM UIST.
[56] Justin Salamon, Duncan MacConnell, Mark Cartwright, Peter Li, and Juan Pablo Bello. 2017. Scaper: A library for soundscape synthesis and augmentation. In WASPAA. https://doi.org/10.1109/WASPAA.2017.8170052
[57] Darius Satongar, Yiu W Lam, Chris Pike, et al. 2014. The Salford BBC Spatially- sampled Binaural Room Impulse Response dataset. (2014).
[58] Sheng Shen, Nirupam Roy, Junfeng Guan, Haitham Hassanieh, and Romit Roy Choudhury. 2018. MUTE: Bringing IoT to Noise Cancellation. In ACM SIGCOMM.https://doi.org/10.1145/3230543.3230550
[59] Michael A Stone and Brian CJ Moore. 1999. Tolerable hearing aid delays. I. Estimation of limits imposed by the auditory path alone using simulated hearing losses. Ear and Hearing 20, 3 (1999), 182–192.
[60] Cem Subakan, Mirco Ravanelli, Samuele Cornell, Mirko Bronzi, and Jianyuan Zhong. 2021. Attention is all you need in speech separation. In IEEE ICASSP.
[61] Cem Subakan, Mirco Ravanelli, Samuele Cornell, Frédéric Lepoutre, and François Grondin. 2022. Resource-Efcient Separation Transformer. In arXiv.
[62] Thierry Tambe, En-Yu Yang, Glenn Ko, Yuji Chai, Coleman Hooper, Marco Donato, Paul Whatmough, Alexander Rush, David Brooks, and Gu-Yeon Wei. 2022. A 16-nm SoC for Noise-Robust Speech and NLP Edge AI Inference With Bayesian Sound Source Separation and Attention-Based DNNs. IEEE Journal of Solid-State Circuits (2022). https://doi.org/10.1109/JSSC.2022.3179303
[63] Noriyuki Tonami, Keisuke Imoto, Ryotaro Nagase, Yuki Okamoto, Takahiro Fuku- mori, and Yoichi Yamashita. 2022. Sound Event Detection Guided by Semantic Contexts of Scenes. In arXiv. arXiv:cs.SD/2110.03243
[64] Vesa Valimaki, Andreas Franck, Jussi Ramo, Hannes Gamper, and Lauri Savioja. 2015. Assisted Listening Using a Headset: Enhancing audio perception in real, augmented, and virtual environments. IEEE Signal Processing Magazine 32, 2 (2015), 92–99. https://doi.org/10.1109/MSP.2014.2369191
[65] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. In arXiv. https://doi.org/10.48550/ARXIV.1706.03762
[66] Bandhav Veluri, Justin Chan, Malek Itani, Tuochao Chen, Takuya Yoshioka, and Shyamnath Gollakota. 2023. Real-Time Target Sound Extraction. In IEEE ICASSP.
[67] Anran Wang, Maruchi Kim, Hao Zhang, and Shyamnath Gollakota. 2022. Hybrid Neural Networks for On-Device Directional Hearing. AAAI (2022). https://ojs.aaai.org/index.php/AAAI/article/view/21394
[68] Yuntao Wang, Jiexin Ding, Ishan Chatterjee, Farshid Salemi Parizi, Yuzhou Zhuang, Yukang Yan, Shwetak Patel, and Yuanchun Shi. 2022. FaceOri: Tracking Head Position and Orientation Using Ultrasonic Ranging on Earphones. In ACMCHI.
[69] Xudong Xu, Bo Dai, and Dahua Lin. 2019. Recursive visual sound separation using minus-plus net. In IEEE/CVF ICCV.
[70] Xuhai Xu, Haitian Shi, Xin Yi, WenJia Liu, Yukang Yan, Yuanchun Shi, Alex Mariakakis, Jennifer Mankof, and Anind K. Dey. 2020. EarBuddy: Enabling On- Face Interaction via Wireless Earbuds. In CHI. https://doi.org/10.1145/3313831.3376836
[71] Koji Yatani and Khai N. Truong. 2012. BodyScope: A Wearable Acoustic Sensor for Activity Recognition. In UbiComp.