一篇文章帶你掌握效能測試工具——Jmeter
一篇文章帶你掌握效能測試工具——Jmeter
在目前的中大型企業中,僅僅進行功能測試已經不足以滿足企業的需求,在重大客戶基數下效能測試將會直接影響到使用者體驗
所以在這篇文章中我們將會學習效能測試的相關知識以及常用工具Jmeter
我們將會從以下角度進行介紹:
- 效能測試基礎資訊
- 效能測試工具介紹
效能測試基礎資訊
首先我們需要去系統的瞭解一下效能測試的相關資訊
效能測試簡述
首先我們需要了解我們為什麼需要學習效能測試:
- 在目前企業裡功能測試是最基本的需求,但隨著使用者量的增加,產品的品質也需要逐漸優化
- 效能測試主要是針對產品的執行速率,執行佔用資源,並行度,最大可承受執行次數等多方面進行測試並判斷是否滿足產品需求
接下來我們需要理解效能主要針對什麼:
- 效能測試主要針對兩方面進行評估
- 時間層面:使用者執行該操作最後效果展現所消耗的時間
- 資源層面:使用者執行該操作對自身計算機所佔用CPU等資源的消耗比率
那麼效能測試就是在多種情況下對效能情況進行測試得出結果:
- 使用自動化工具,模擬不同場景下,對軟體各項效能指標進行測試和評估的過程
最後我們簡單講一下效能測試的目的:
- 評估當前系統能力
- 尋找效能瓶頸,優化效能
- 評估軟體是否滿足未來需求,是否需要優化
效能測試對比
我們在之前的文章中已經學習了功能測試,那麼我們簡單給出兩者的區別:
# 功能測試
# 目的:主要為了驗證系統的功能需求規格是否滿足產品需求
# 正向功能測試:採用完整正確的測試用例進行測試,判斷是否滿足產品需求
# 逆向功能測試:採用不完整或部分錯誤或錯誤的測試用例進行測試,判斷是否滿足產品需求
# 效能測試
# 目的:主要為了判斷產品是否滿足其業務需求場景
# 時間效能測試:採用業務需求場景下的測試用例獲取最終時間結果,判斷是否滿足產品需求
# 資源效能測試:採用業務需求場景下的測試用例獲取計算機資源佔比,判斷是否滿足產品需求
我們還需要知道其兩者之間的先後順序關係:
- 在前後端提測之後,我們首先需要進行功能測試並回歸完完全功能之後,判斷該產品無任何問題後再進行效能測試
- 在完成功能測試和效能測試後,兩者自動化的書寫無先後順序關係
效能測試分類
我們下面來介紹效能測試的多種測試方式
基準測試
首先我們需要介紹基準測試:
- 狹義:基準測試其實就是單使用者測試
- 廣義:基準測試是採用單使用者測試在某一固定場景下進行測試並得到具體資料,以該資料作為基準和後續測試資料進行對比
我們給出一個簡單範例來說明基準測試:
-
我們在最開始採用一種情況進行測試並得到結果進行記錄,後續我們採用其他方式進行測試並與基準測試結果進行對比
-
基準測試:專案1.0版本,測試機設定(8G+16G),單使用者查詢一萬條資料採用3.0s
-
後續測試:專案1.0版本,測試機設定(8G+32G),單使用者查詢一萬條資料採用2.0s
-
後續測試:專案1.1版本,測試機設定(8G+16G),單使用者查詢一萬條資料採用2.5s
那麼基準測試的用途也很明顯:
- 基準測試從不會單獨出現,它需要與其他資料比較才有意義
- 基準測試採用單使用者測試,主要是為了給後續多使用者測試綜合測試場景提供參考意義
- 基準測試採用測試機測試,主要是為了給後續不同設定測試機測試綜合測試場景提供參考意義
負載測試
我們同樣首先來介紹負載測試的意義:
- 通過逐步增加系統負載,確定滿足系統效能指標情況下(響應時間或CPU佔用率),找到該系統的最大承受量
我們給出一個簡單範例來說明負載測試:
- 我們首先會從產品那裡得到一個客戶效能需求,例如該電梯從1樓運輸到5樓的執行時間控制在15s內
- 那麼我們就需要採用不同重量進行測試,判斷是否滿足客戶需求並將該負載結果告訴產品
- 我們會從下述case中選擇最大的滿足效能需求的重量作為負載測試的最終結果
- case1:100KG物品在電梯中從1樓運輸到5樓的執行時間是10s
- case2:500KG物品在電梯中從1樓運輸到5樓的執行時間是10s
- case3:700KG物品在電梯中從1樓運輸到5樓的執行時間是14s
- case4:900KG物品在電梯中從1樓運輸到5樓的執行時間是17s
針對負載測試我們還需要知道這些內容:
- 系統對外宣稱的一般是最大負載量
- 負載測試的測試時間一般為1-2小時
- 通過負載測試可以確定系統的最大負載量和極限負載量
負載測試的用途主要針對客戶需求:
- 系統最大負載量達到客戶需求時,系統才能正式上線使用
穩定測試
我們首先給出穩定性測試的概念:
- 穩定性測試主要是針對產品在穩定執行(正常業務負載下)的情況下進行長時間測試,並保證產品滿足線上業務需求
我們現實中其實存在很多案例:
- 因為不同業務存在不同業務場景,所以穩定性測試的測試時間是不同的
- 例如12306鐵路搶票軟體,每天的0點到6點之間是不允許搶票的,那麼我們只需要測試在一天情況下能否滿足業務需求
- 例如淘寶京東購物軟體,每天無時無刻都可以進行購物,那麼我們測試時長就需要稍微拉長一些來判斷能否滿足業務需求
負載測試的用途主要針對產品永續性:
- 系統在使用者要求的業務負載下達到規定的執行時間時,系統才能正式上線使用
壓力測試
我們首先給出壓力測試的概念:
- 壓力測試主要針對在高壓情況下,檢視系統是否存在功能隱患,判斷是否是否良好的容錯能力和可恢復能力
針對壓力測試主要分為兩方面的壓力測試:
- 系統在持續高壓情況下的穩定性測試
- 系統在超高壓情況下崩潰後的恢復能力測試
我們分別給出兩個案例:
# 持續高壓下壓力測試
# 例如B站中某個視訊爆火,在一段時間內,該視訊的點選率一直上升,一直呼叫get介面
# 那麼我們就需要去測試該介面在高負荷情況下(超過正常呼叫頻率)在一段時間內(一天或三天)是否能夠正常呼叫且無錯誤
# 超高壓情況下恢復測試
# 例如某個功能爆火,導致該功能的點選量/介面呼叫率突然提升超過預期,導致該介面/資料庫資訊報錯
# 那麼我們就需要測試在該功能崩潰情況下,是否能在較短時間內恢復該功能的正常執行/介面呼叫無異常
並行測試
我們同樣給出並行測試的概念:
- 並行測試是在極短的時間內,傳送多個請求,判斷是否出現資源爭奪導致的異常情況
我們在日常生活中可以見到很多案例:
- 雙十一定時搶券活動
- 春節火車票搶購時間
但是我們需要注意到的是並行測試和負載測試雖然都是測試資源消耗或者說是資源的最大承受量,但兩者是不同的:
- 負載測試:是指一段時間內,在高負載的情況對於資源的消耗,是否會存在資源耗盡問題
- 並行測試:是指在極短時間內,判斷是否會出現由於資源互相搶奪而導致功能無法實現問題
其實並行測試的主要測試點更像是我們作業系統中出現的死鎖情況:
- 假設我們的資源A存在10個,資源B存在10個
- 同時存在20個執行緒都需要資源A和資源B,同時啟動導致10個執行緒得到資源A,10個執行緒得到資源B
- 但兩者都無法得到剩餘的執行緒,從而出現資源死鎖問題,導致資源無法釋放,功能無法實現從而出現並行問題
效能測試指標
我們在進行效能測試時,當然不能只根據我們的感覺來判斷該效能是否符合標準,因此就出現指標這一概念
響應時間
首先我們來介紹響應時間:
- 狹義:使用者進行操作後,得到最後結果之間所消耗的時間
- 廣義:主要包含瀏覽器傳輸時間,伺服器處理時間,伺服器傳輸時間,資料庫處理時間等多時間彙總所得到的結果
我們可以簡單給出一張圖片進行解釋:
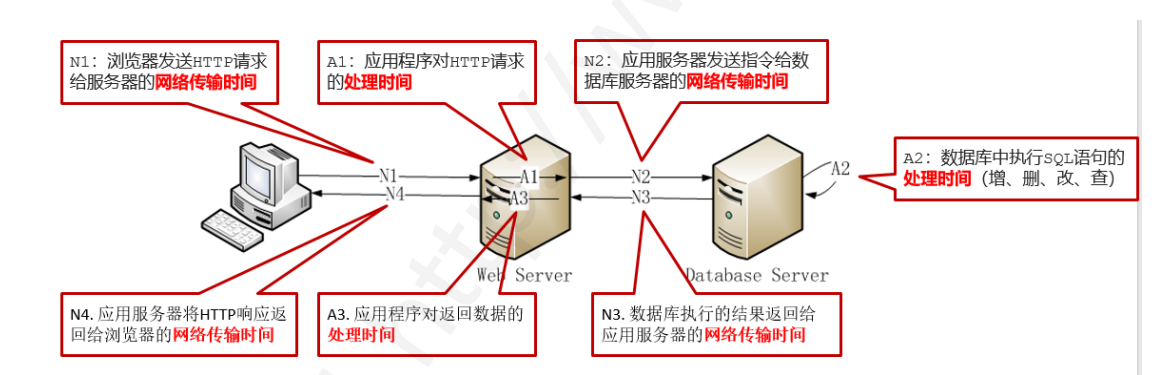
我們的響應時間通常是我們進行效能測試最直接的判斷結果:
- 例如我們查詢一萬條資料時所需要得到的響應時間在3s之內
但我們還需要注意一點:
- 我們所獲取的響應時間並不能是單次執行所得到的時間
- 而是在多次執行下,所得到的所有執行時間的平均值(Jmeter會有一個欄位儲存平均響應時間)
吞吐量
我們來簡單介紹一下吞吐量:
- 吞吐量指單位時間內處理使用者端的請求數量,可以直接體現出系統的效能承載能力
吞吐量主要分為兩種:
-
TPS每秒事務數
-
QPS每秒查詢數
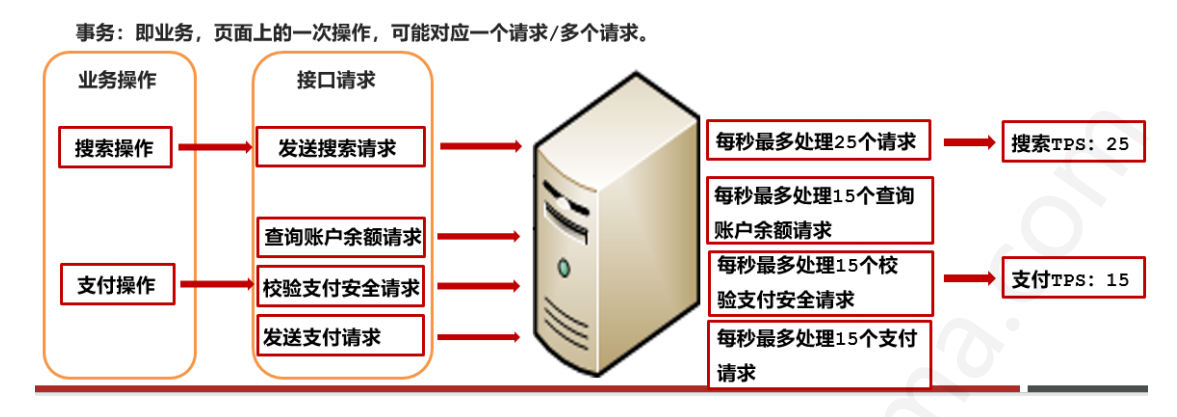
我們首先來介紹TPS:
- 即控制伺服器每秒處理的事務請求的數量
- 該計算僅僅針對事務的數量進行計算,一次事務(一次點選)可能會出現1個或多個請求,而這些請求都被劃分為一次事務
我們採用一張圖片解釋:
我們再來介紹QPS:
- 即控制伺服器每秒處理的指定請求的數量
- 該計算是指標對某單一介面請求,去統計該單位時間內所處理的請求個數
我們同樣採用一張圖片解釋:

資源利用率
我們來簡單介紹一下資源利用率:
- 即計算機內各種資源的使用情況
- 通常是一個比率值,採用當前使用資源數/計算機全部資源數來獲取
我們常見的一些計算機資源包括有:
- CPU使用率
- 顯示卡使用率
- 記憶體使用率
- 磁碟IO效率
- 網路傳輸率
效能測試流程
首先我們直接給出一張效能測試流程圖:
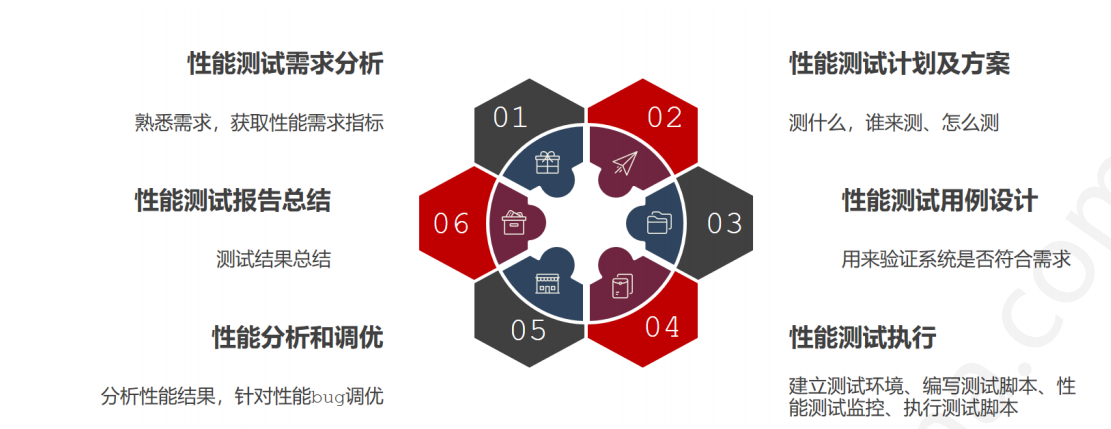
需求分析
首先我們來講解效能測試需求分析:
- 所有測試的需求分析的過程都是相同的,由產品給出具體指標,由我們進行解析梳理
我們通常將效能測試需求分析劃分為四步:
# 1.明確被測系統
# 我們首先需要了解我們所測試的系統的業務功能和技術架構
# 我們需要去了解我們所測試的系統的常用模組,並瞭解其執行步驟
# 2.明確測試內容
# 在產品給出需求的情況下,我們直接去測試產品需求點即可
# 若產品未給出需求,那麼我們主要針對使用者使用最頻繁的部分進行測試或者針對效能過低的部分進行測試優化
# 3.明確測試策略
# 該測試策略就是我們前面所提到的測試分類方法
# 該測試策略並非需要全部執行,我們需要針對不同情況採用不同測試策略進行測試
# 4.明確測試指標
# 同樣,我們以產品的需求為主,如果存在需求,則滿足需求即可
# 若不存在需求,我們可以參考其他軟體或之前版本的測試資料進行判斷其指標
測試計劃
測試計劃其實主要依照公司主管所制定的計劃:
- 所測內容:依據專案背景,給出測試目的及測試範圍即可
- 所測人員:由主管進行分配各個人員的分工以及完成時間等資訊
- 所測方法:測試方法可以由主管指定,也可以由各個人員進行判斷
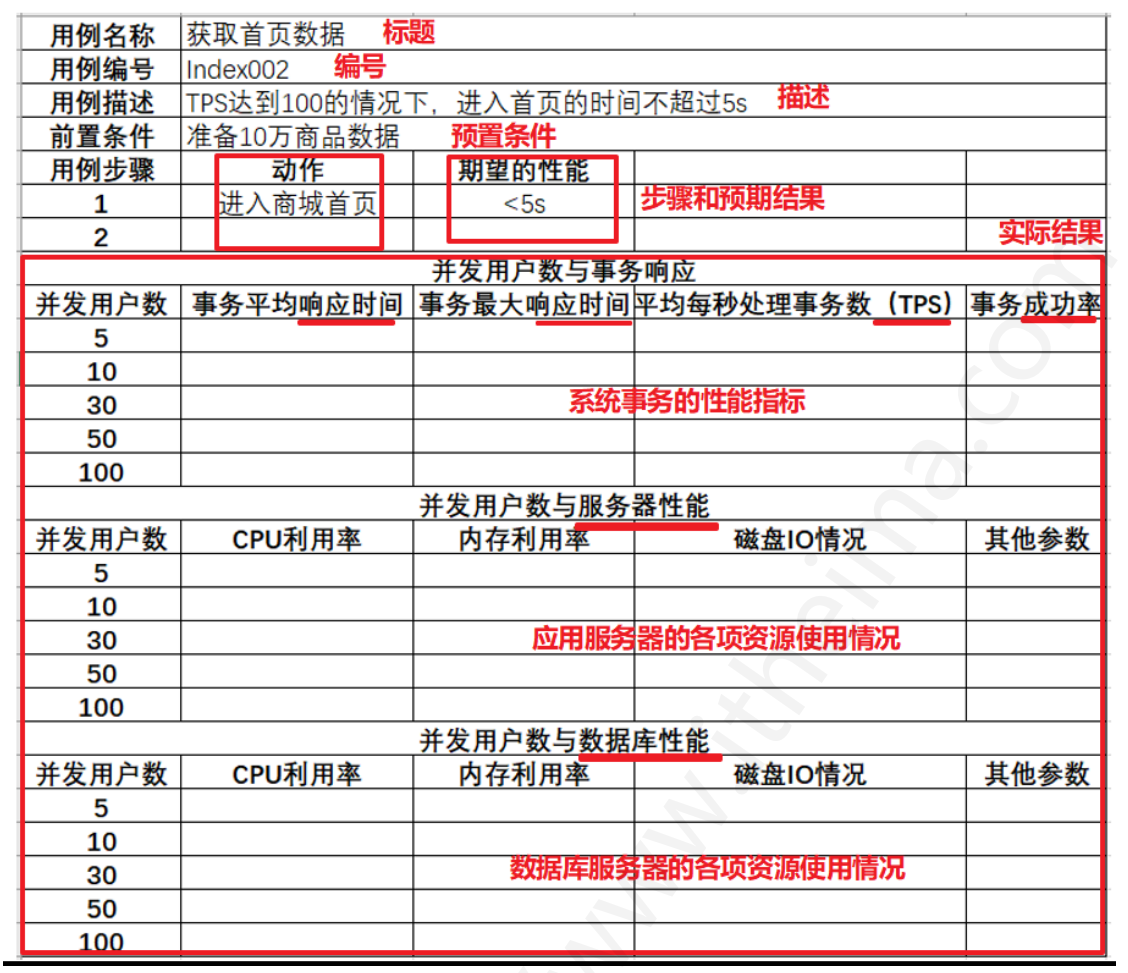
測試用例
我們給出一張測試用例的常用模板圖即可:
測試執行
我們的效能測試通常通過工具進行測試:
- 由於效能測試需要長時間點選或頻繁點選,人工無法實現
- 我們通常通過引數化和指令碼等,然後結合測試工具Jmeter或其他效能測試工具等去結合執行
我們的效能測試執行大概劃分為四階段:
# 1.建立測試環境
# 搭建效能測試環境,包括硬體環境,軟體環境,網路環境
# 2.編寫測試指令碼
# 按照效能測試需求用例,使用效能測試工具書寫測試指令碼
# 3.效能測試監控
# 一般我們所使用的指令碼工具都會存在效能測試監控視窗,我們只需要檢視資料是否存在問題即可
# 4.執行測試指令碼
# 設定效能執行場景,執行效能測試,收集測試結果並與指標進行對比
測試分析
我們在執行測試用例之後會獲取到其效能測試結果,我們只需要對比即可:
- 針對不滿足產品需求的效能測試結果,我們需要要求後端對其進行優化,並在優化後迴歸測試
測試報告
我們在測試結束之後通常需要去書寫測試報告,主要是為了我們後續測試作為對照,主要包含以下內容:
- 測試流程記錄
- 測試風險評估
- 測試結果記錄
- 測試分析記錄
- 測試總結改進
效能測試工具介紹
接下來我們開始正式介紹Jmeter工具的使用
Jmeter效能比較
其實除了Jmeter之外,我們還有很多效能測試工具,其中之前比較出名的就是Loadrunner,我們這裡簡單介紹一下兩者的區別:
# 首先我們來簡單說一下Loadrunner
# Loadrunner實際上算是一款很知名的效能測試工具
# Loadrunner的主要特點是:高收費,佔用記憶體較大,功能全面無閹割,同時可模擬上萬人同步操作
# 而Jmeter其實就是針對Loadrunner所做出來的閹割版效能測試工具
# 但是由於Jmeter的免費且開源使得它在如今社會滿足企業需求且可以由我們自己插入第三方外掛
# Jmeter的主要特點是:免費且開源,佔用記憶體極小,基本滿足企業需求,同時可模擬千人同步操作,可以手動匯入第三方實現企業需求
# 且兩者都包容多協定,像我們常用的Http,Https,FTP等協定,兩者都可以使用
# 且兩者都存在監聽件,我們所做的效能操作都會直接體現在監聽件中,不需要我們手動記錄
Jmeter下載安裝
Jmeter的下載非常簡單,我們只需要到官網下載對應壓縮包即可:Apache JMeter - Download Apache JMeter
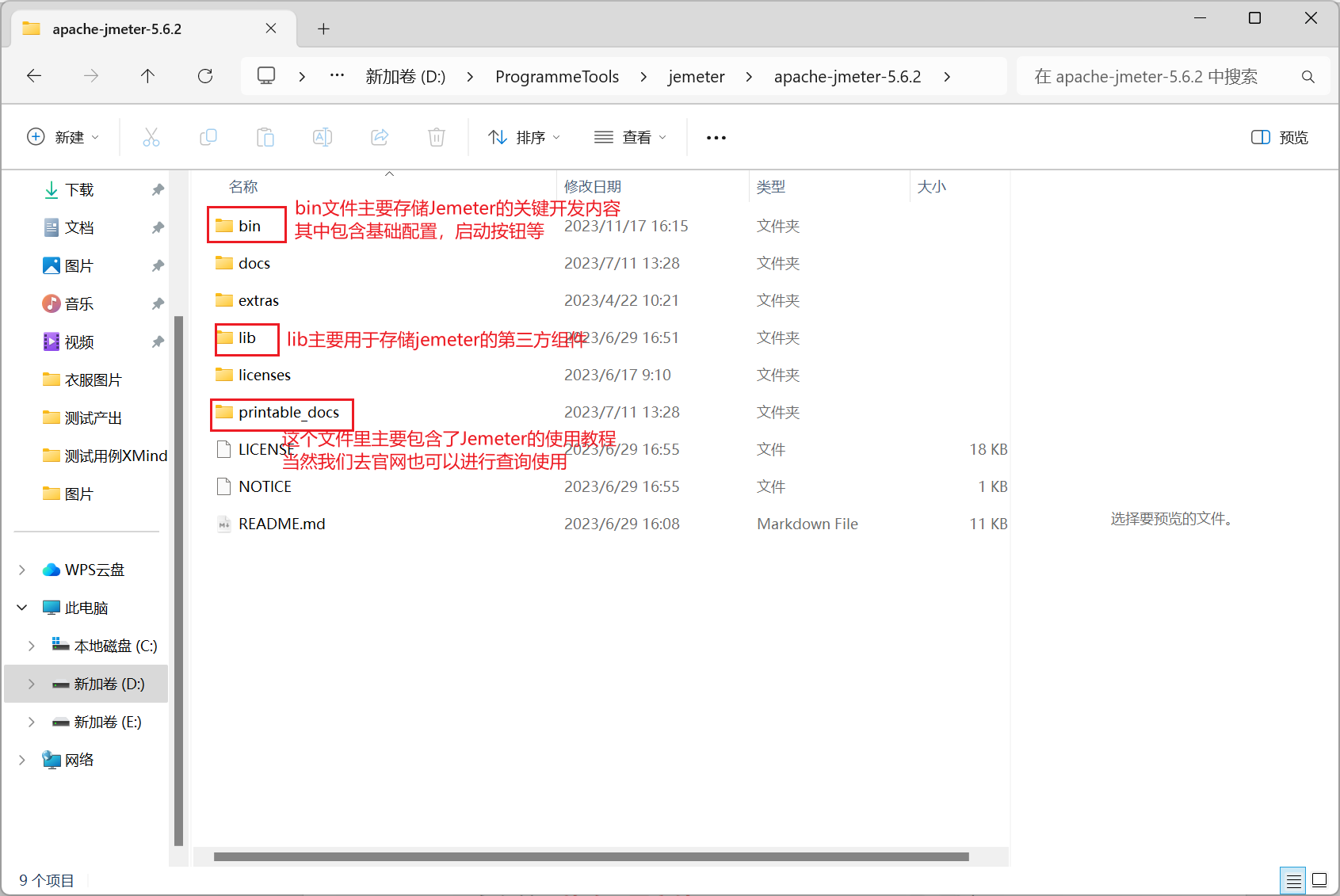
我們將其壓縮到對應資料夾即可,注意需要是全英文資料夾,下面我們使用一張圖來介紹各檔案內容:
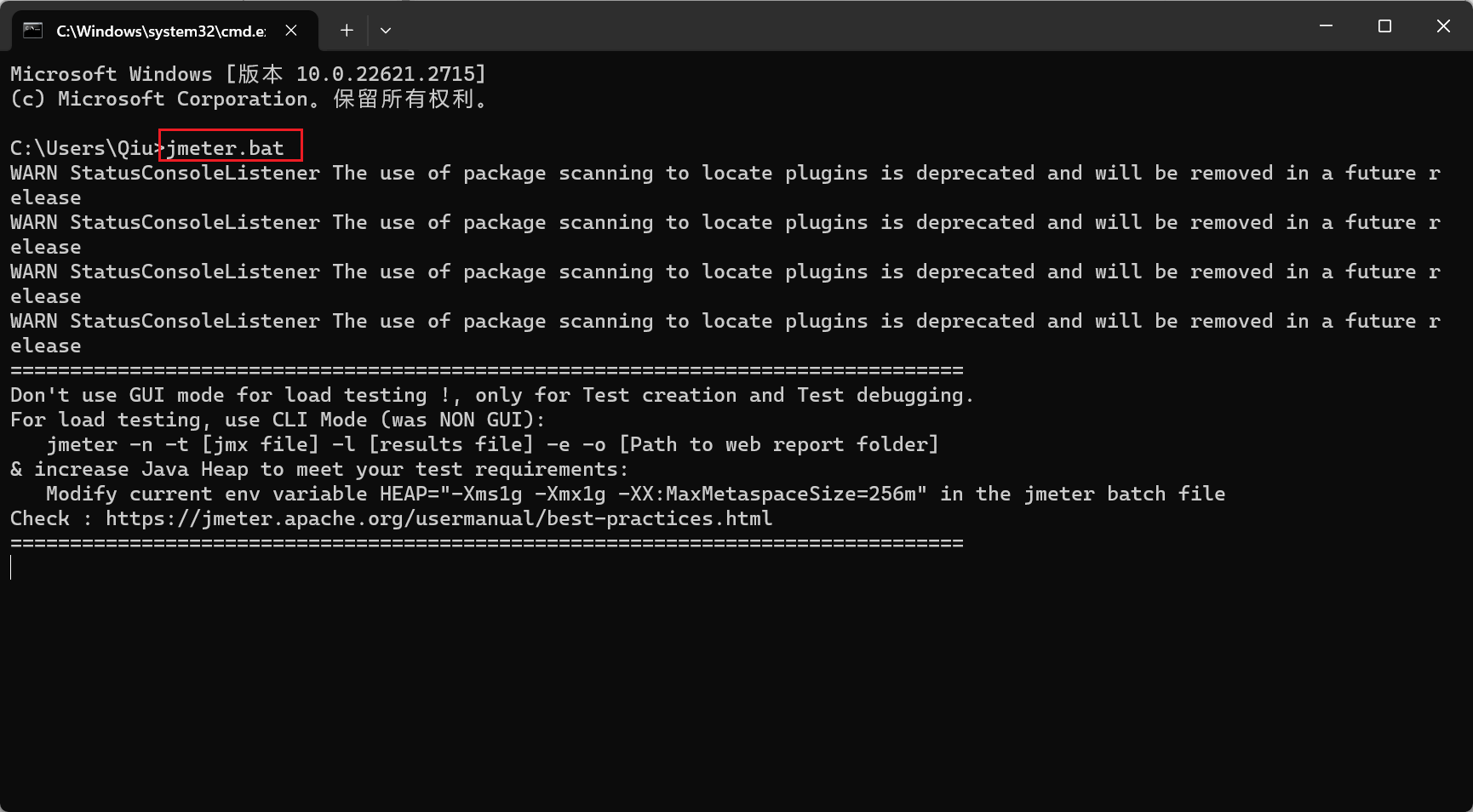
如果我們希望快速開啟Jmeter,我們通常會將該檔案的bin目錄放入我們的環境變數,那麼我們僅需要使用一行簡單命令就開啟服務:
最後我們給出一下Jmeter的一個頁面展示:
這裡我們所看到的是英文介面,當然我們可以將其變為中文介面,我只需要進入bin目錄的Jmeter.properties檔案修改:
最後我們給出一個小提示,因為我的電腦存在這個問題,所以記錄下來:
# 如果電腦是高重新整理率,像我的電腦是240HZ重新整理,就會導致Jmeter的GUI介面出現重疊問題
# 我們只需要在Jmeter.bat指令碼中的第一行,加入這行程式碼即可
set JVM_ARGS=-Dsun.java2d.d3d=false
Jmeter元件介紹
我們首先給出一張Jmeter工具的相關元件圖,我們會在下面進行解釋:
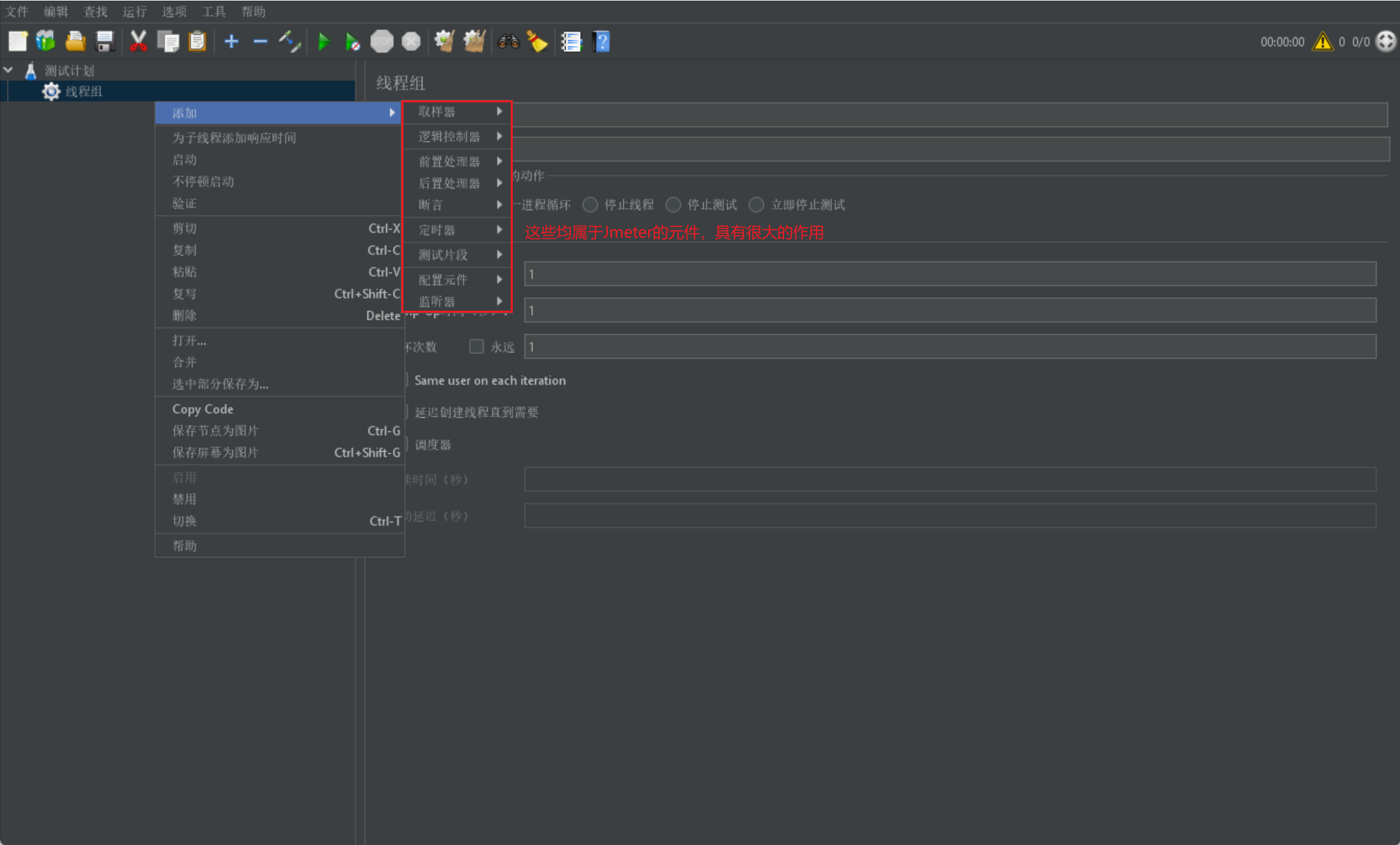
下面我們依次來介紹上述元件的作用:
# 取樣器
# 取樣器就是用來傳送請求的元件,我們在頁面上點選按鈕其實就是傳送請求,這裡就是模擬傳送請求
# 邏輯控制器
# 邏輯控制器就是控制我們的元件是否執行,包含我們常用的if,while,foreach等
# 前置處理器
# 前置處理器是對我們的請求引數在執行前進行處理
# 後置處理器
# 後置處理器是對我們請求後所返回的響應進行處理
# 斷言
# Python中常用的判斷結果是否符合預期的功能
# 定時器
# 定時器主要用來控制我們多久後執行該取樣器(傳送請求)
# 設定元件
# 設定元件內的元件都是用於進行初始化的東西
# 監聽器
# 監聽器主要是用來獲取我們使用取樣器傳送請求後的響應資料相關資訊
接下來我們需要知道元件的作用範圍都在哪裡:
# Ø取樣器:核心,沒有作用域
# Ø邏輯控制器:只對其子節點中的取樣器和邏輯控制器起作用
# Ø其他元件:
# •如果是某個取樣器的子節點,則該元件只對其父節點起作用
# •如果其父節點不是取樣器,則其作用域是該元件父節點下的其他所有後代節點(包括子節點,子節點的子節點等)
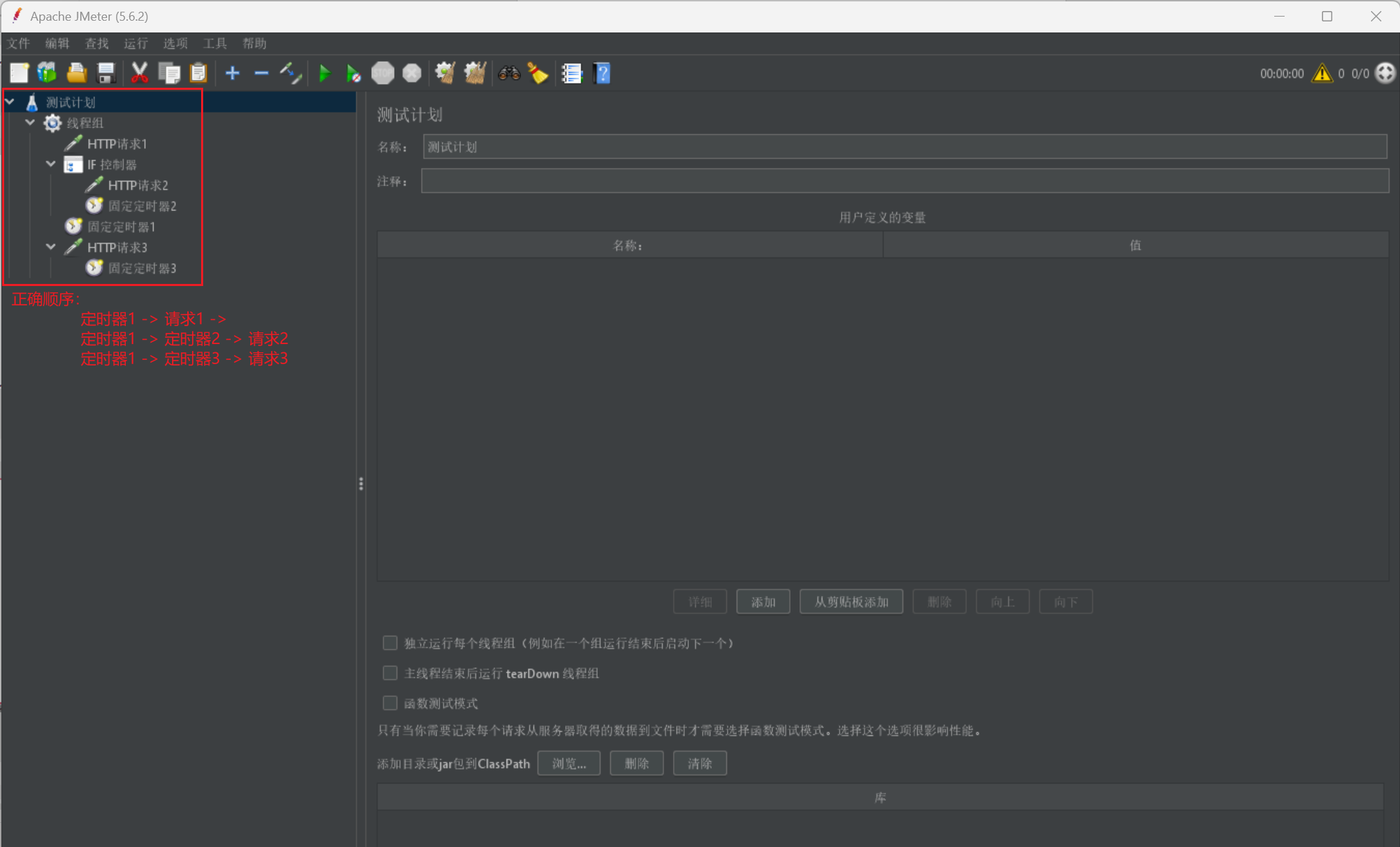
我們還需要注意其執行順序:
# 在同一個作用域(目錄/級別/縮排)的不同元件的執行順序:
# 設定元件 - 前置處理程式 - 定時器 - 取樣器 - 後置處理程式 - 斷言 - 監聽器
# 在同一個作用域(目錄/級別/縮排)的相同元件的執行順序:
# 從上到下的順序依次執行
我們給出一張圖,並給出它的執行順序,大家可以明白其作用範圍:
Jmeter案例展示
首先我們給出一個最簡單的案例進行展示:
# 步驟
# 1.啟動Jmeter
# 2.在「測試計劃」下新增執行緒組
# 3.在「執行緒組」下新增「http請求」取樣器
# 4.填寫「http請求」取樣器資訊
# 5.在「執行緒組」下新增「檢視結果樹」監聽器
# 6.點選啟動按鈕,並檢視結果
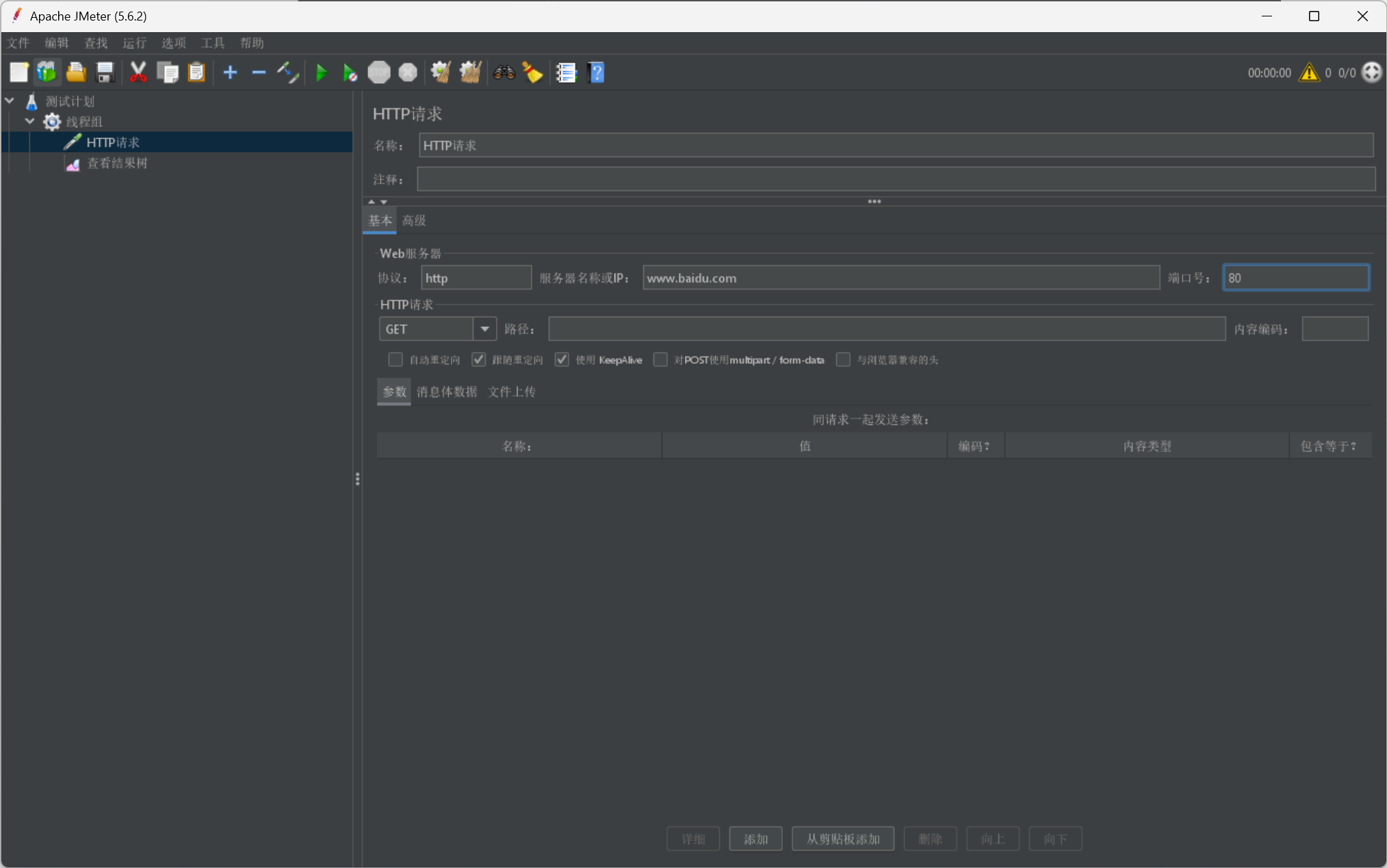
我們這裡首先給出http請求的介面展示,後續我們會詳細介紹:
然後我們這裡直接啟動,給出檢視結果樹的執行介面展示:
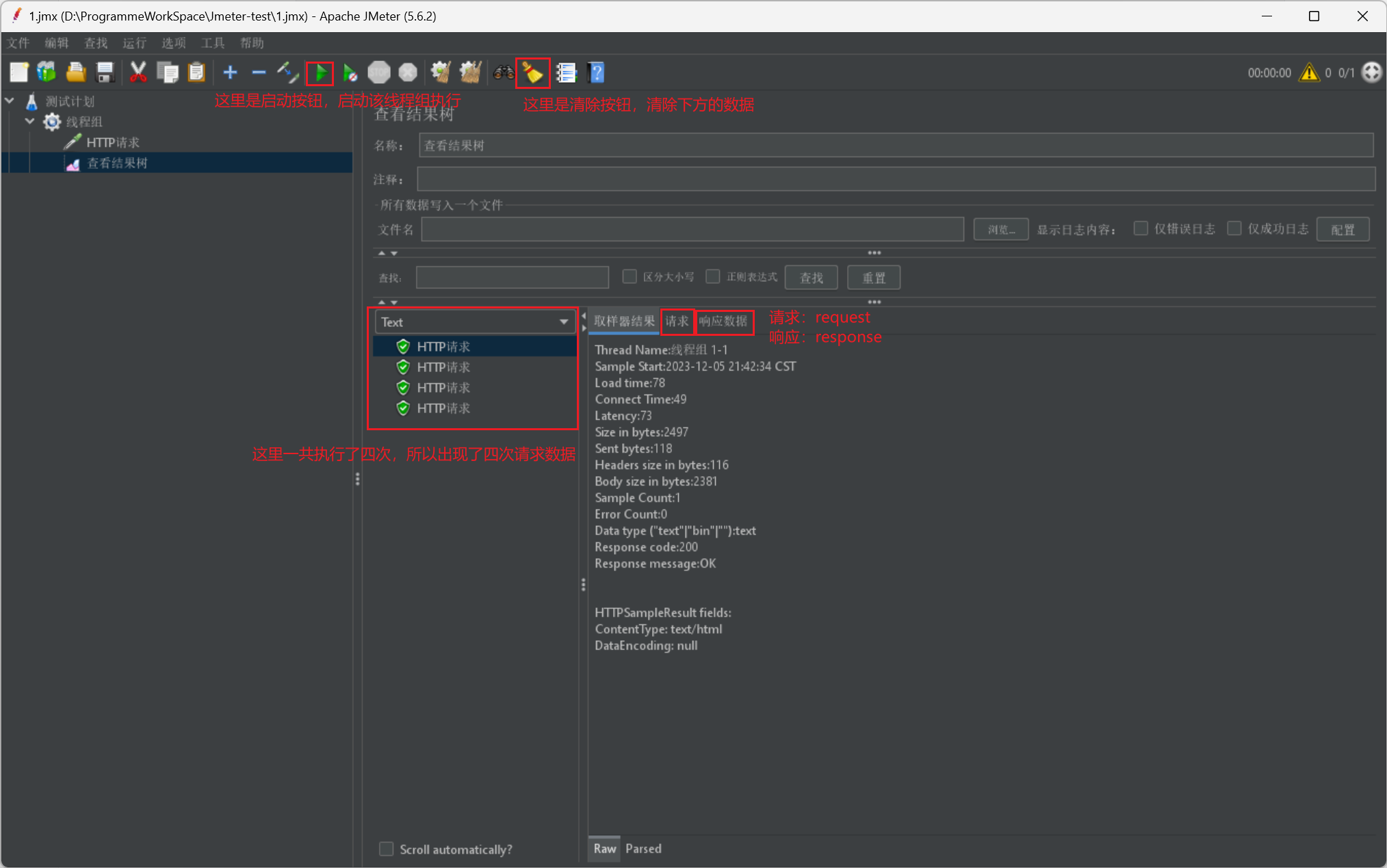
Jmeter執行緒介紹
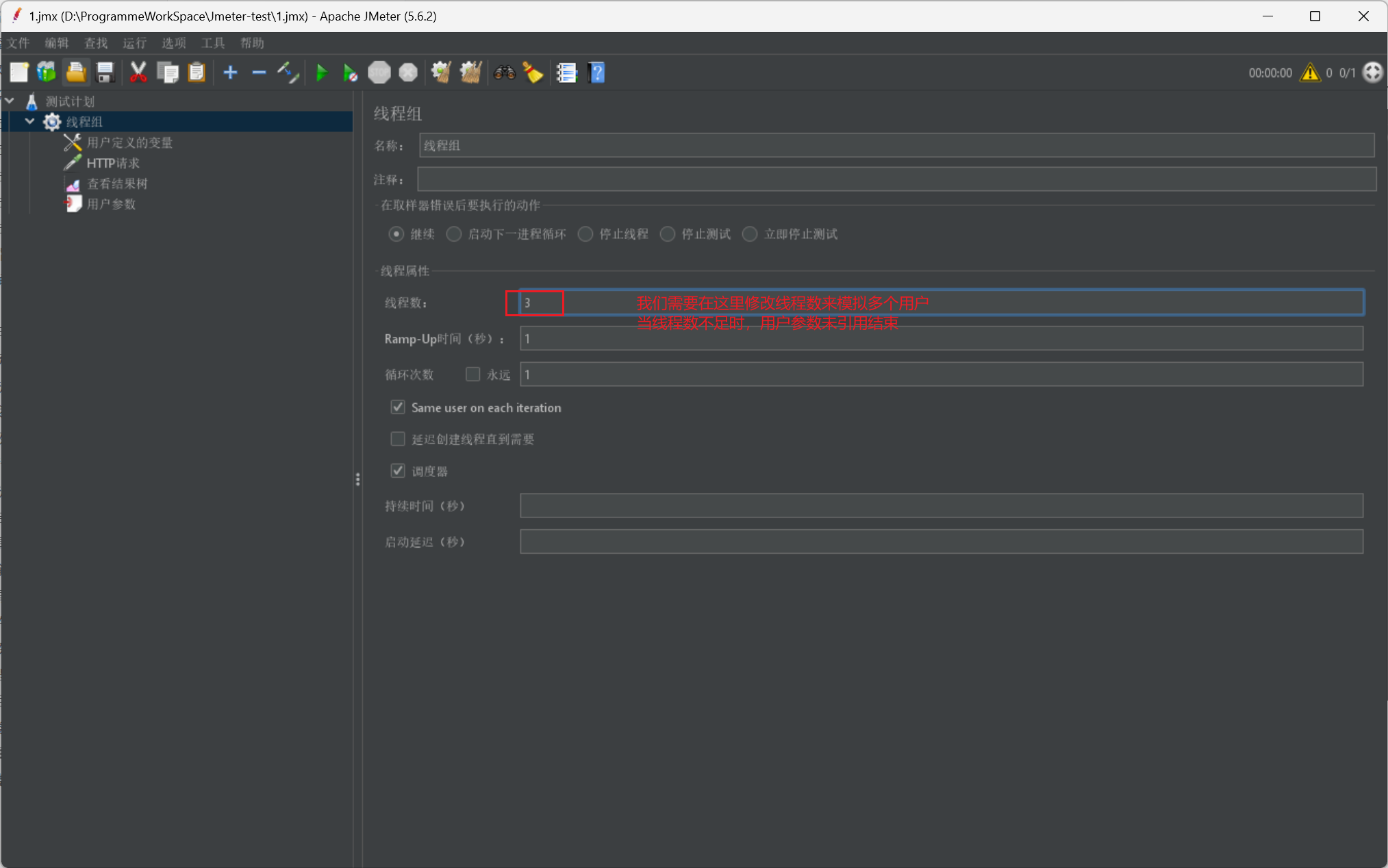
在瞭解其元組具體資訊之前,我們首先需要了解一下執行緒組:
# 執行緒組一共只有三種,我們右鍵測試計劃就可以建立執行緒組,這裡不給圖片展示了
# 1.執行緒組
# 控制Jmeter用於執行測試的一組使用者,用於執行測試用例,可以有1個或者多個(並行/序列),後續我們會給出具體引數資訊設定
# 2.Setup執行緒組
# 預測試操作,所有指令碼之前執行
# 類似於Pytest裡面的Setup方法
# 3.Teardown執行緒組
# 測試後操作,所有指令碼之後執行
# 類似於Pytest裡面的Teardown方法
我們給出執行緒組的展示圖並說明其具體使用引數資訊:
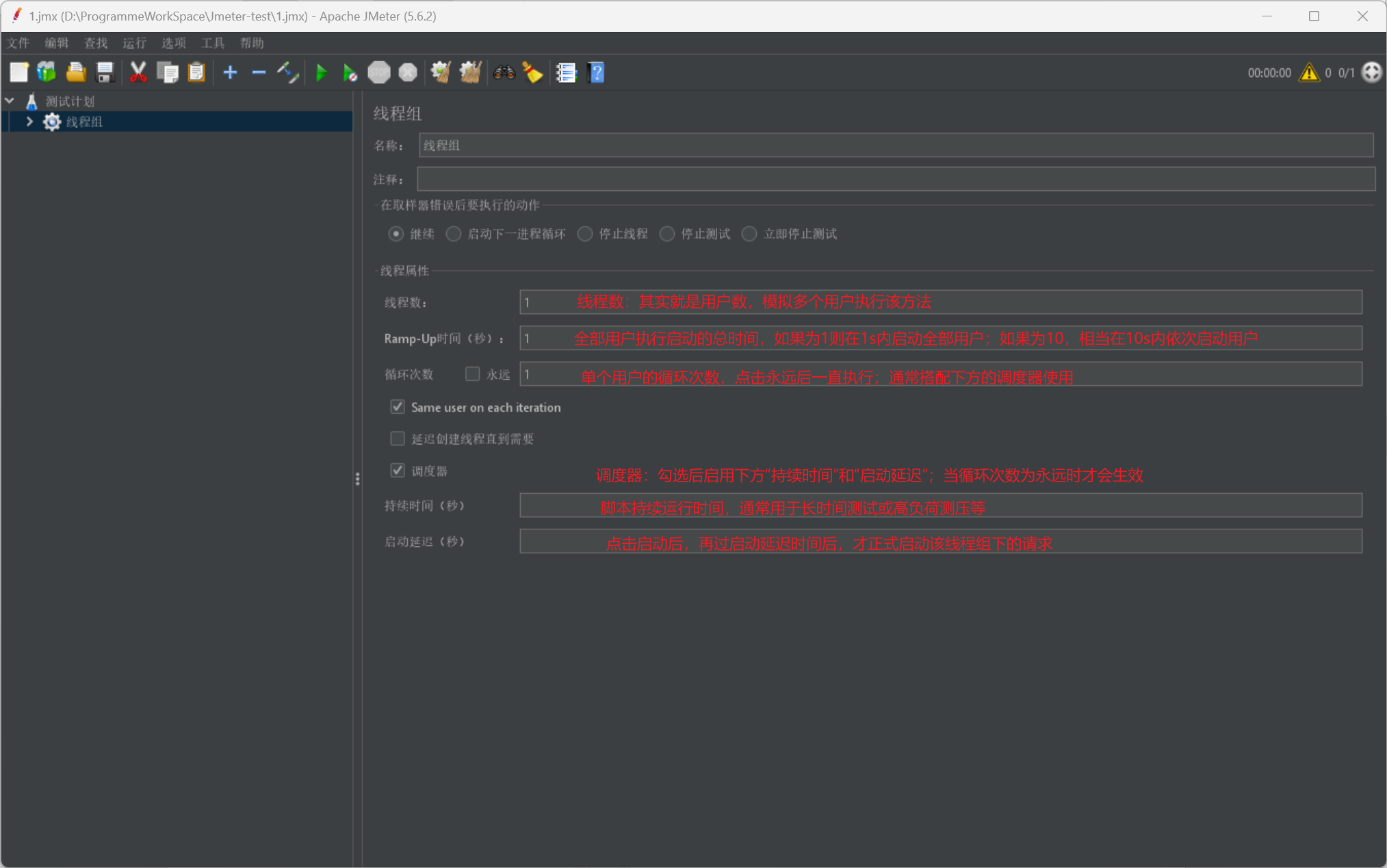
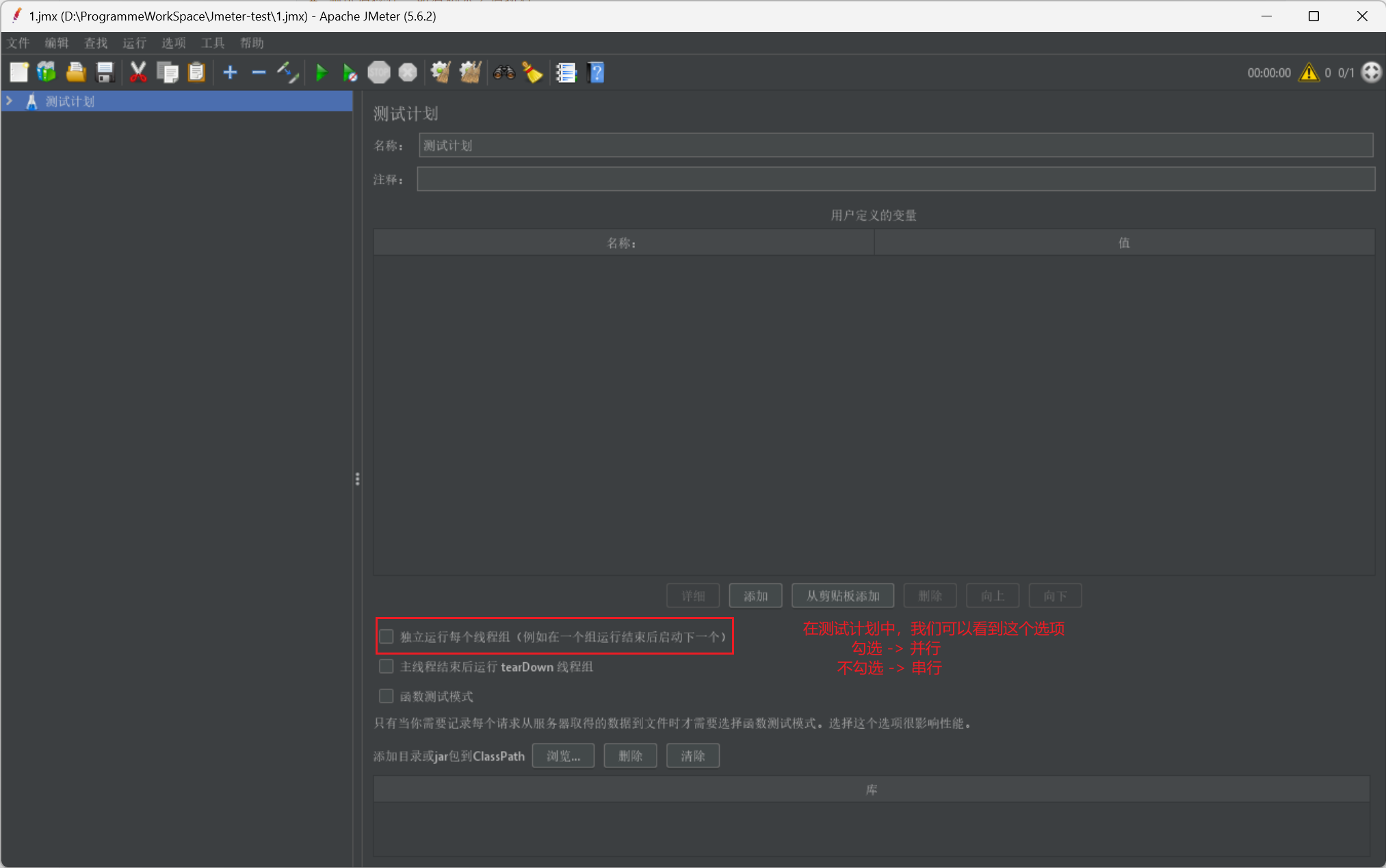
而最後我們在給出一個小貼士,是關於執行緒組的並行或序列啟動的開關按鈕:
Jmeter互動介紹
我們直接給出Jmeter請求的一張展示圖,並在該展示圖上進行介紹:
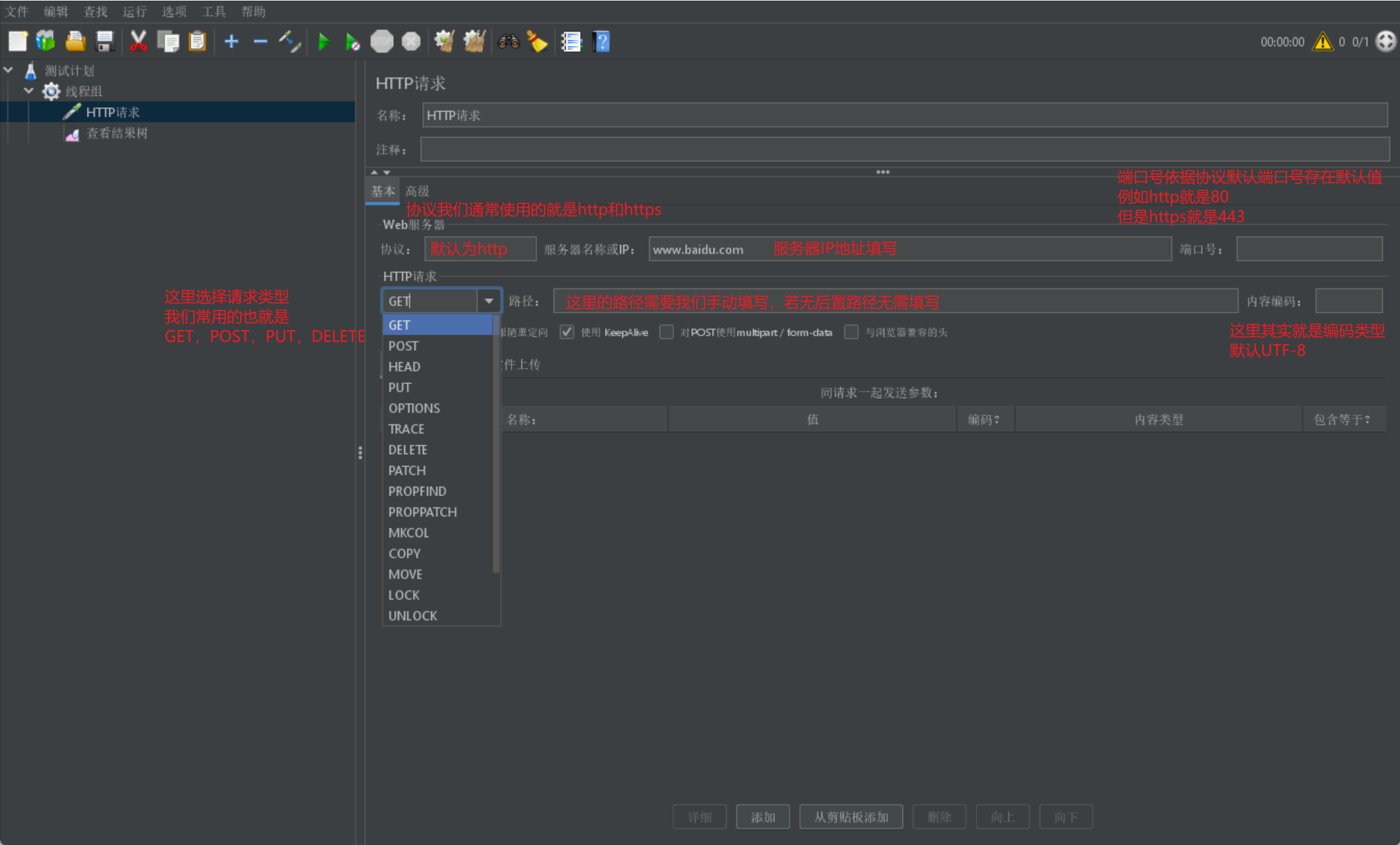
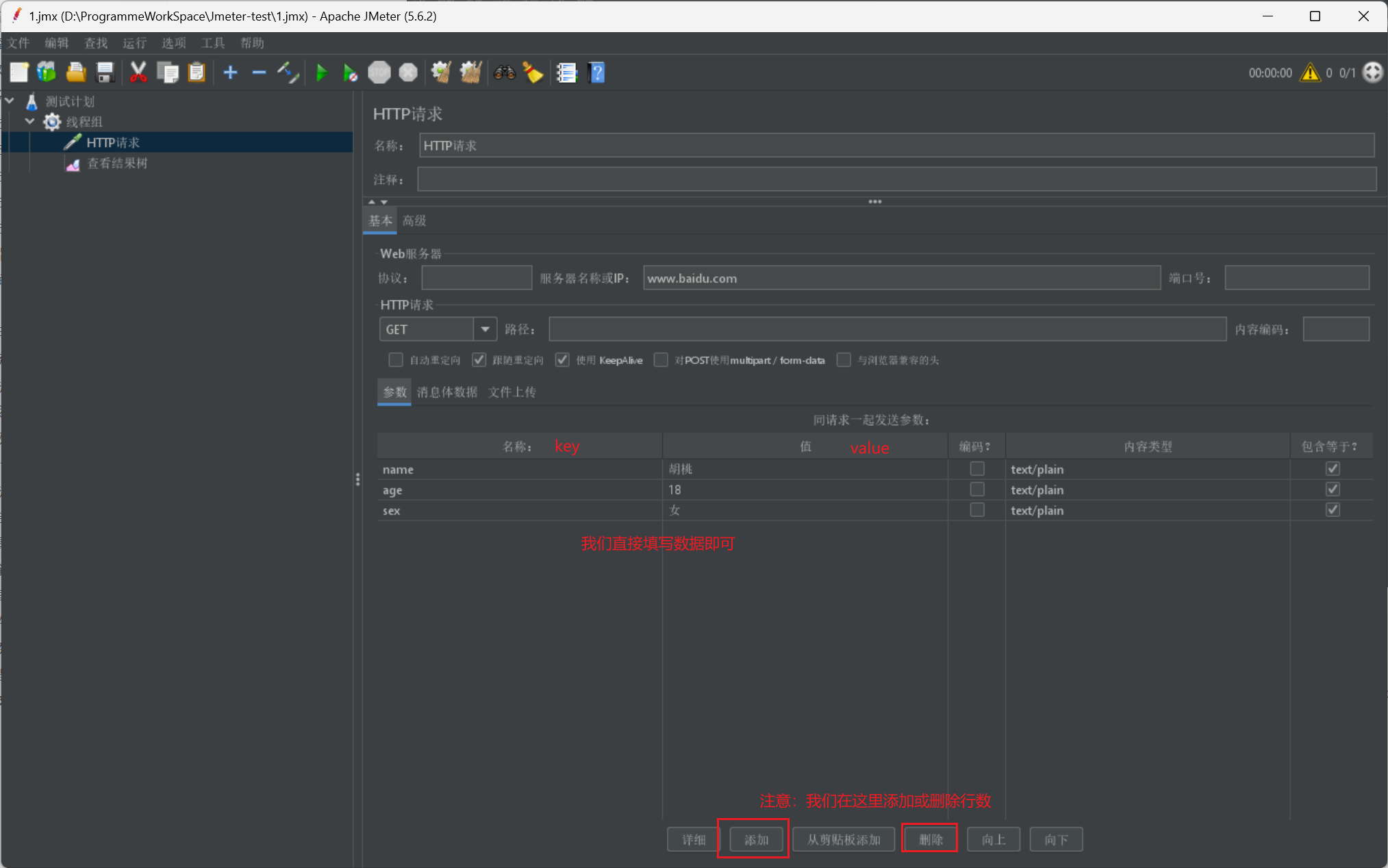
除了這些請求之外,我們在請求時,還需要傳遞引數資訊:
- 如果是get請求,我們可以直接在路徑後以?key1=value1&key2=value2的形式進行傳遞
- 其他請求型別,我們通常在下方的引數欄進行傳遞,也可以選擇訊息體資料採用JSON或其他格式傳遞,如果傳遞檔案可以選擇第三種
我們給出一張展示圖:
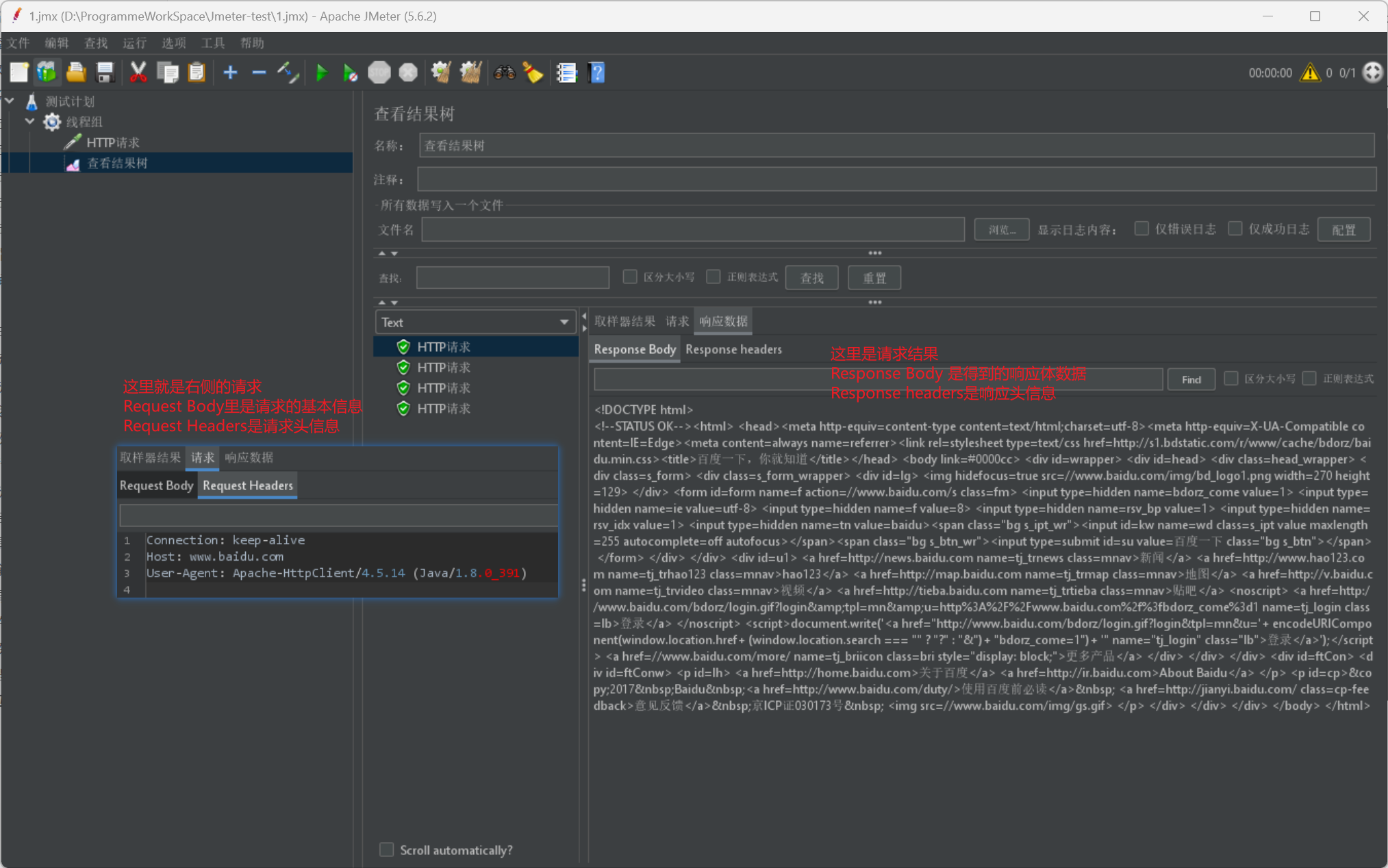
我們順便給出一張檢視結果樹的請求和響應展示圖:
Jmeter引數處理
我們在之前的自動化測試中也學習到了引數化,現在我們來學習Jmeter的引數化設定:
- 引數化的本質就是實現測試資料與測試方法的分離
- 引數化主要使用不同的測試資料,呼叫相同的測試方法進行測試
全域性變數
我們首先學習Jmeter引數化最基本的全域性變數:
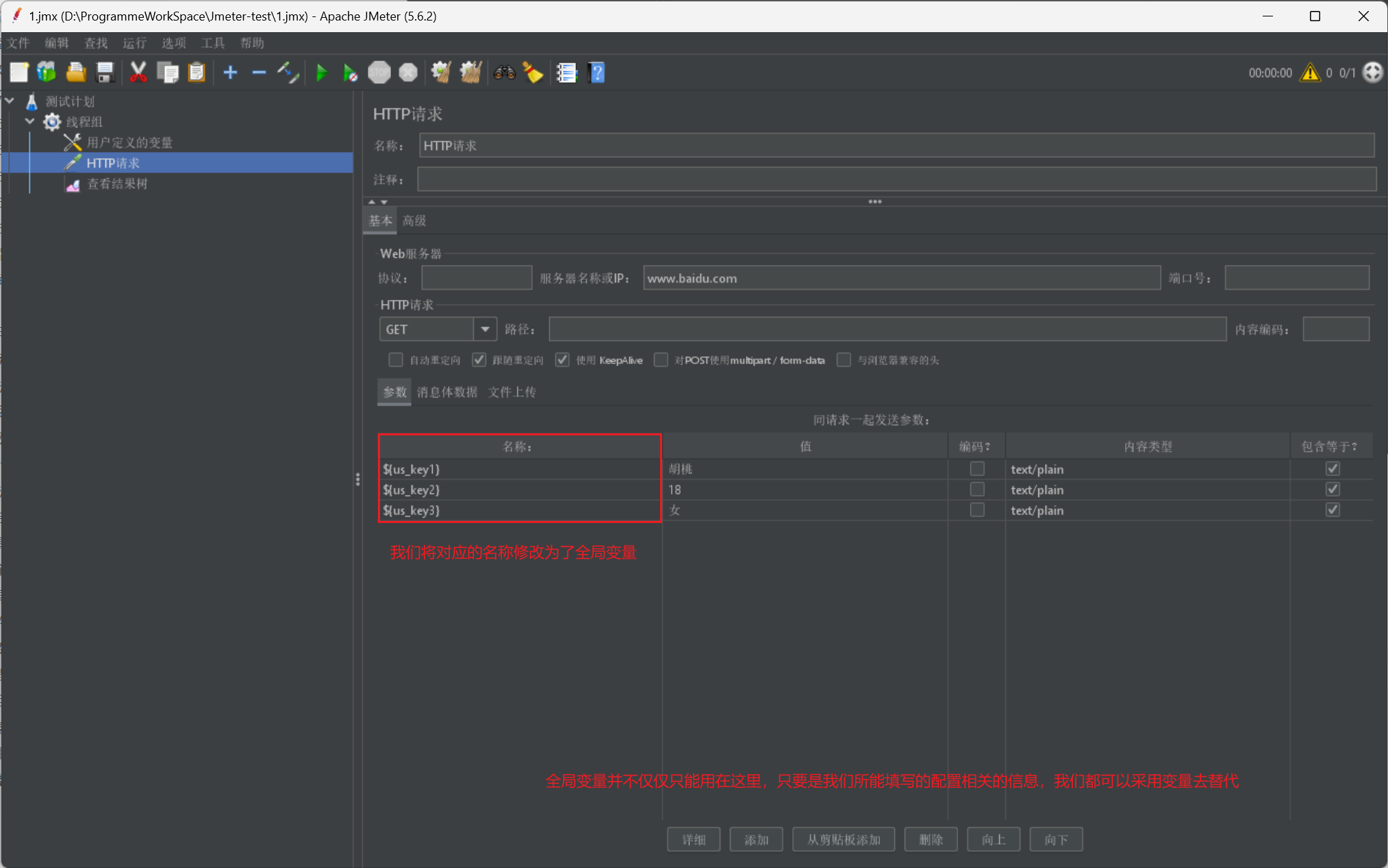
- 使用者定義的變數 —— 全域性變數
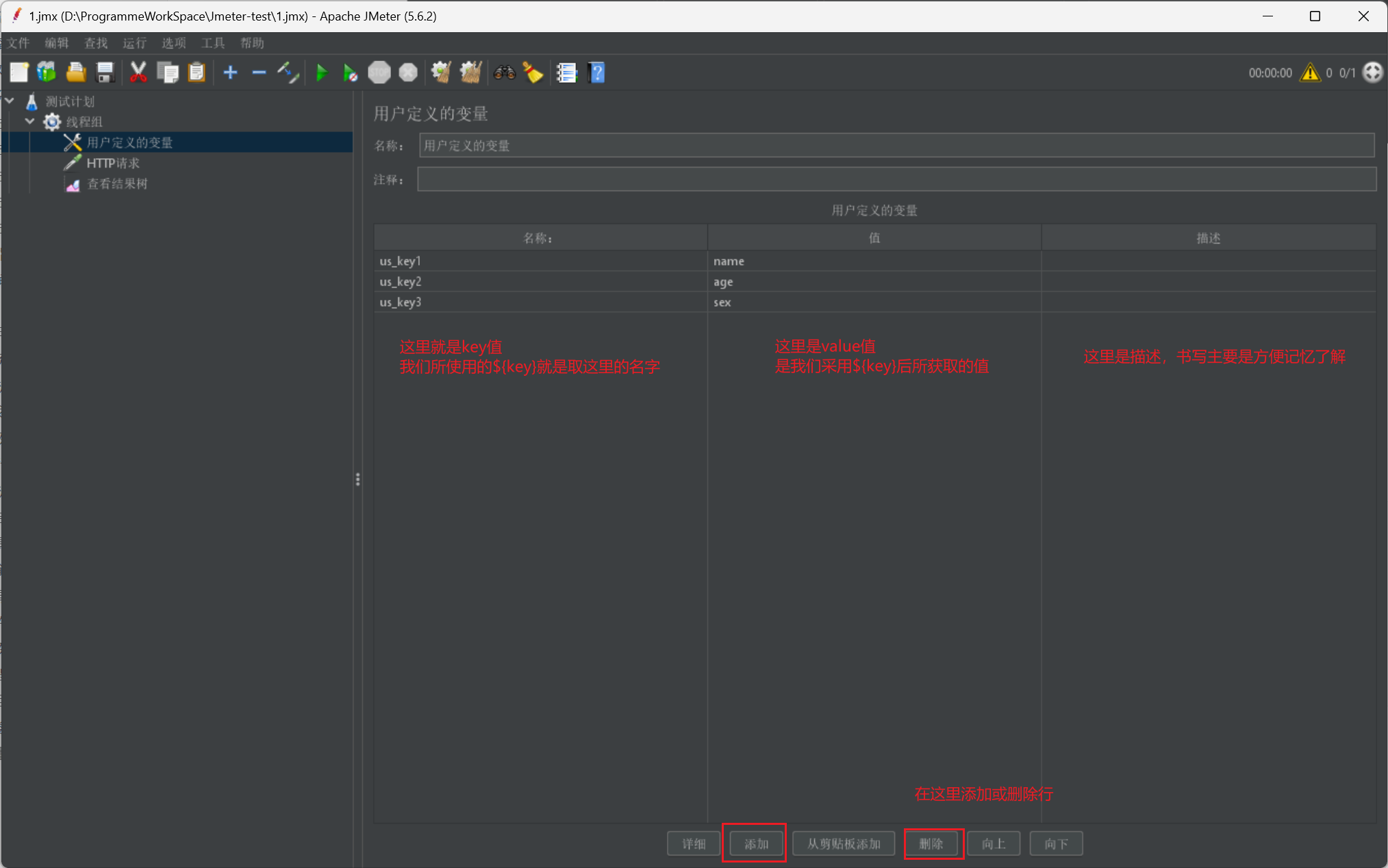
首先我們進行一些全域性變數資訊的講解:
# 如何定義?
# 我們可以線上程組下,建立設定元件的使用者定義的變數
# 具體作用?
# 定義一些全域性變數方便我們頻繁使用,例如我們頻繁使用某些欄位或某些資料,我們就可以定義為全域性變數進行使用
# 如何使用?
# 我們只需要在需要匯入的地方採用${變數名}就可以使用
我們直接給出全域性變數定義的介面:
我們再給出一張使用圖:
使用者引數
同樣我們首先給出使用者引數的相關概念:
- 使用者引數 —— 為每個使用者分配不同的引數值
我們先來進行簡單介紹:
# 如何定義?
# 我們可以線上程組下,建立前置處理器的使用者引數
# 具體作用?
# 針對一組引數,當不同使用者使用時,會獲取不同的資料
# 如何使用?
# 我們只需要在需要匯入的地方採用${變數名}就可以使用
我們首先給出一張使用者引數設定圖:
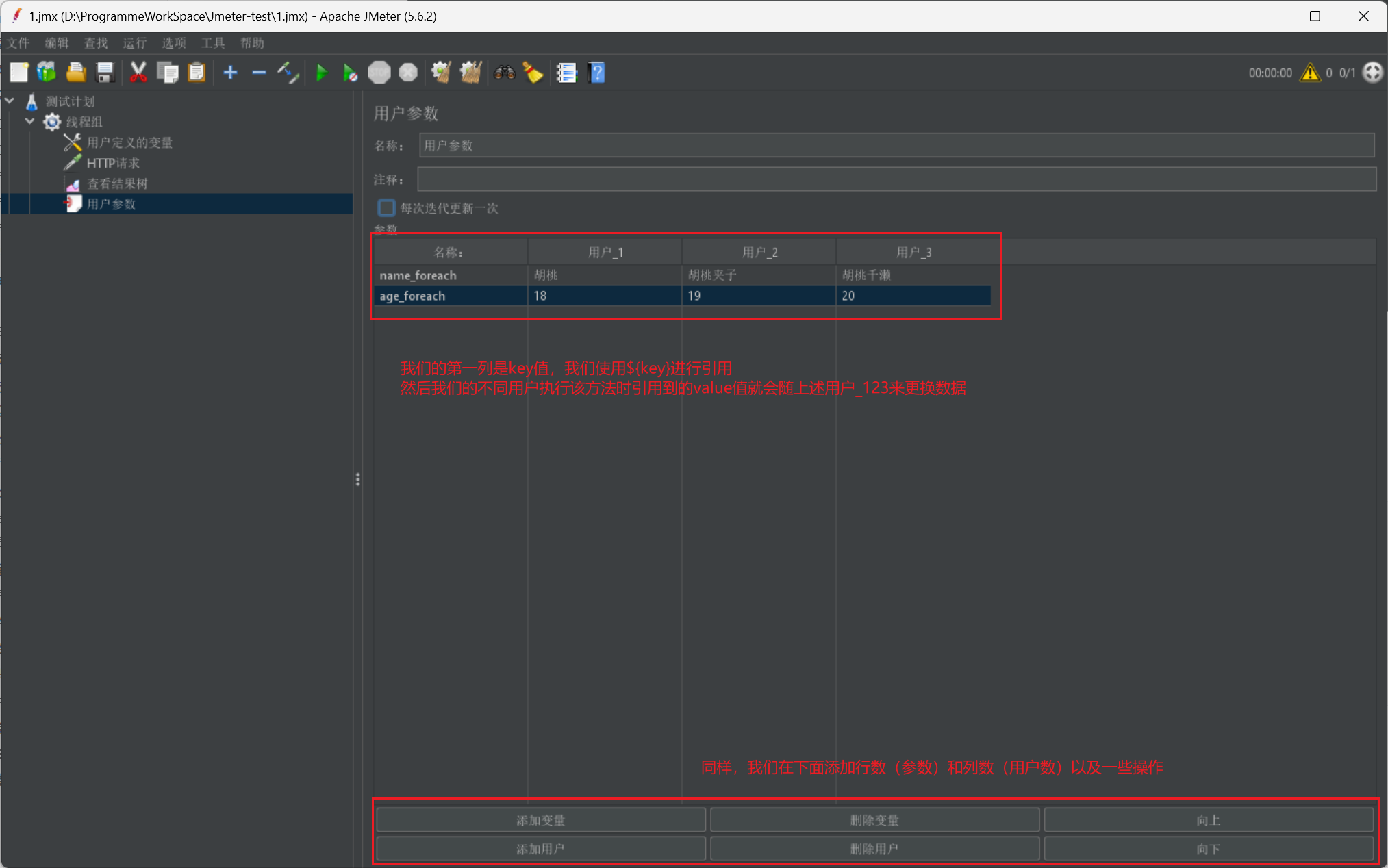
然後我們再給出一張使用圖或者說我們的設定圖:
資料檔案
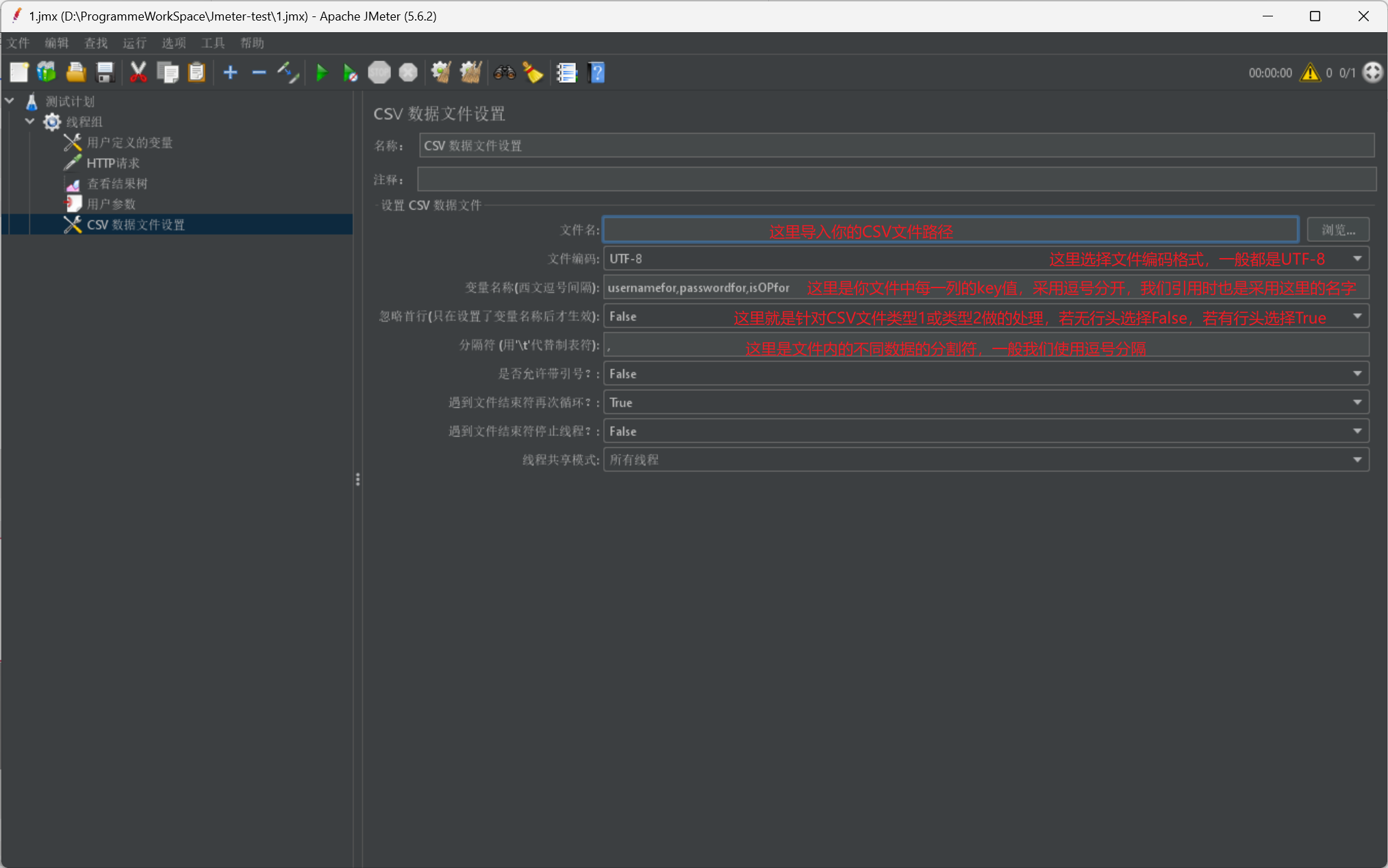
我們首先給出資料檔案的相關定義:
- CSV資料檔案設定 —— 檔案方式引數化
我們同樣給出介紹:
# CSV檔案?
# CSV檔案是一種分行儲存資料的檔案
# CSV檔案型別1(存在錶行頭)
username,password,isOP
user1,123456,True
user2,123321,False
user3,111111,True
# CSV檔案型別2(無表頭行)
user1,123456,True
user2,123321,False
user3,111111,True
# 如何定義?
# 我們可以線上程組下,建立設定元件的CSV 資料檔案設定
# 具體作用?
# 針對一組引數,當每次使用都會使用不同資料資訊
# 如何使用?
# 我們只需要在需要匯入的地方採用${變數名}就可以使用
我們首先給出一張CSV檔案匯入Jmeter的展示圖:
我們在使用時,同樣採用$符進行資料匯入,注意key值是我們在CSV資料檔案設定裡設定的變數名稱:
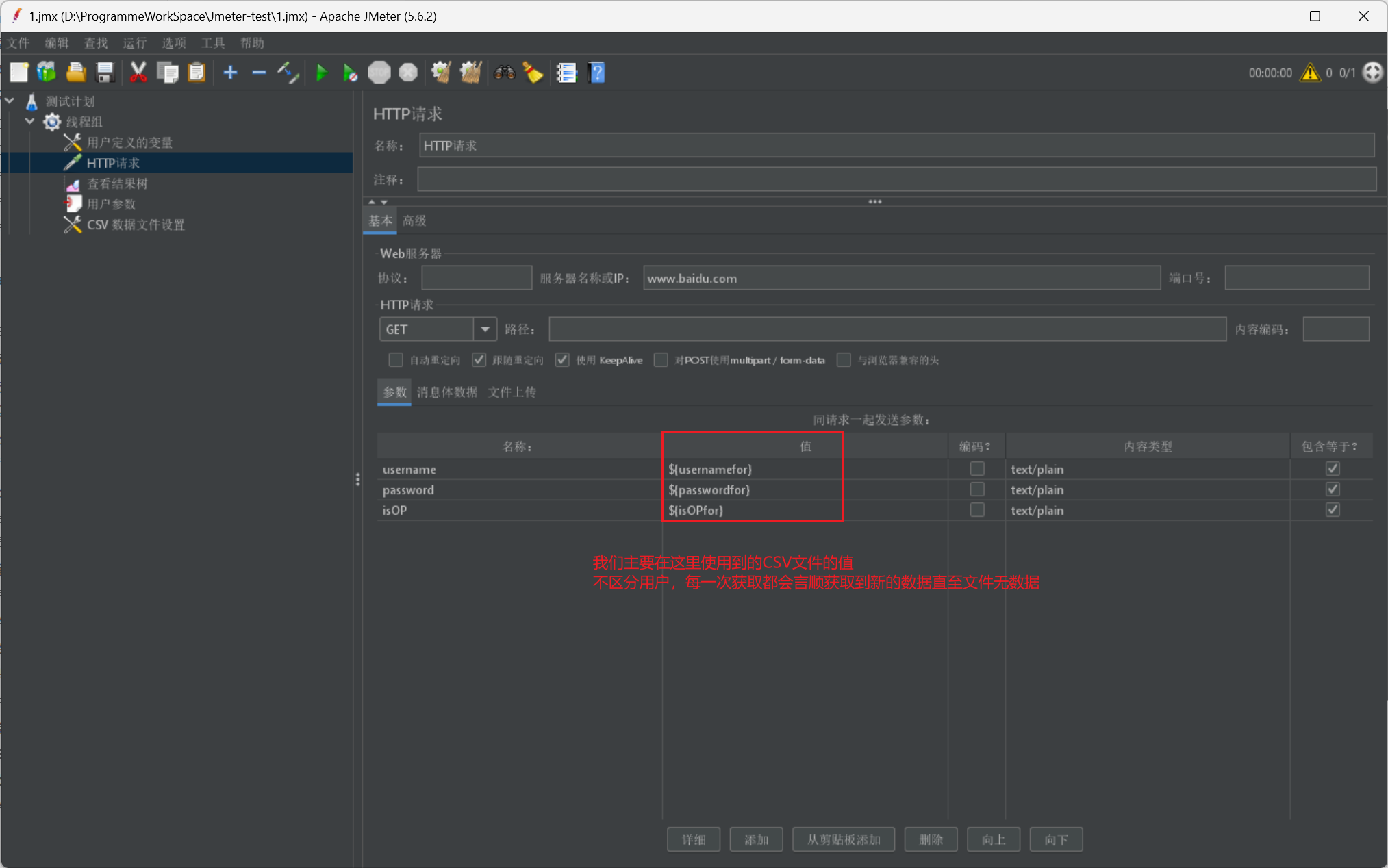
函數引數
最後我們介紹一下函數引數:
- 函數 —— 亂資料
我們同樣給出基本介紹:
# 如何定義?
# 我們點選工具列-選擇函數助手對話方塊-彈出對話方塊-選擇函數型別(這裡我們僅介紹__counter計數器)
# 具體作用?
# 自動生成不重複的資料,讓每個使用者每次迴圈都獲取到不同的資料,且不需要提前定義
# 如何使用?
# 我們只需要在需要匯入的地方採用${函數名}就可以使用
我們給出函數定義介面展示:
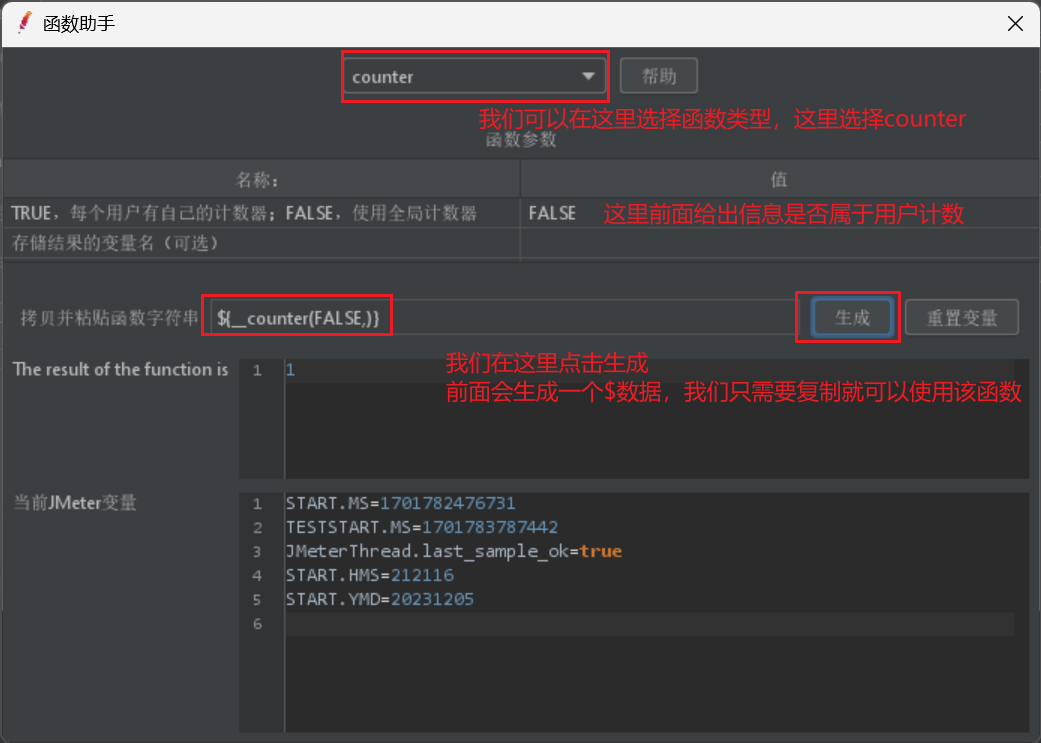
最後我們給出一個資料使用展示:
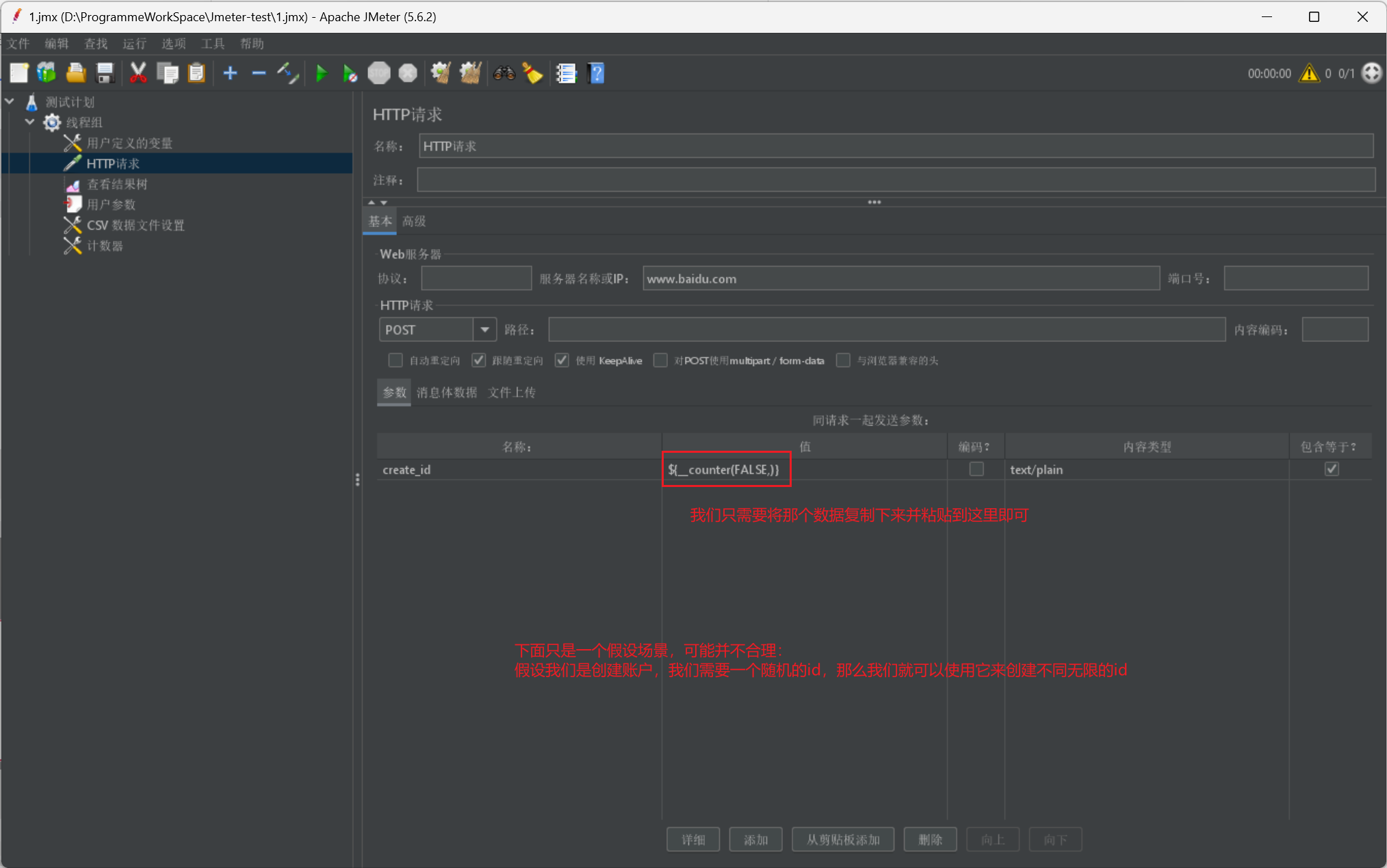
彙總展示
最後我們分別給出四種引數化處理的優缺點:
# 全域性變數
# 作用:定義全域性變數
# 侷限性:每次取值(無論使用者)都是固定值
# 使用者引數
# 作用:保證不同使用者針對同一引數,取到不同資料
# 侷限性:使用者在多次迴圈中會取到同一引數,導致資料重複
# 資料檔案
# 作用:保證不同使用者在不同迴圈中取到不同引數
# 侷限性:需要手動設定資料,當用戶迴圈過多,資料設定過多顯得繁雜
# 函數引數
# 作用:自動生成不重複的資料,讓每個使用者每次迴圈都獲取到不同的資料,且不需要提前定義
# 侷限性:針對特定要求的場景,無法使用,泛用性較低(例如需要輸入正確的賬號密碼進行登入時)
Jmeter斷言介紹
下面我們來介紹Jmeter中的結果自動判斷工具:
- 我們的Jmeter本身有一個響應碼自動判斷,若結果並非200就會進行報錯顯示
- 但是存在某些情況,即使響應碼為200但也可能因為結果不對從而導致功能不符合需求
- 所以我們需要學習斷言,我們採用斷言來完成欄位的匹配,若欄位不符合我們的需求則報錯顯示
響應斷言
我們首先給出一張響應斷言頁的圖片:
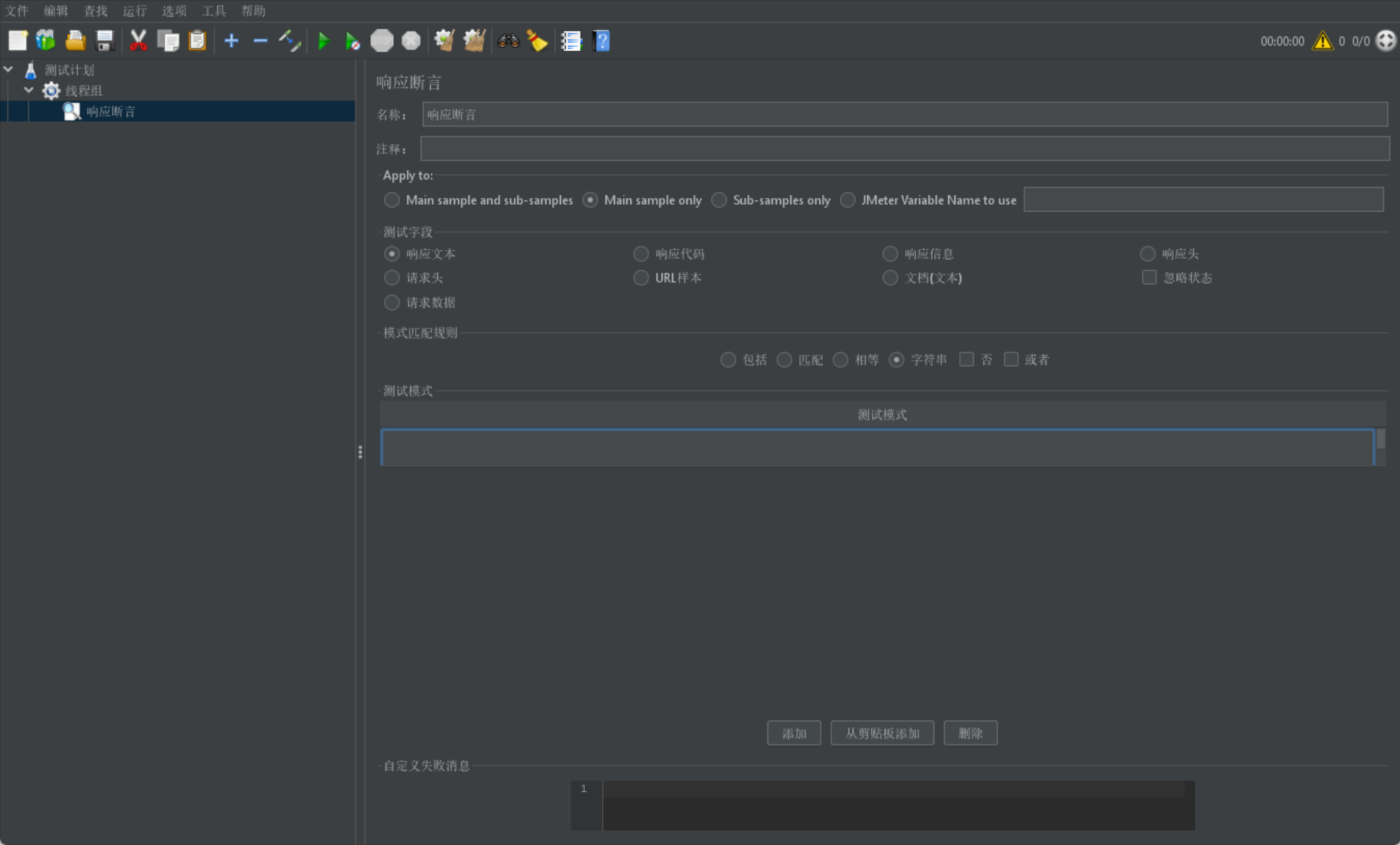
由於頁面內容過多無法在圖中展示所有欄位含義,我們單獨在下面介紹上述欄位意義:
# 1.響應斷言下方的名稱和註釋就是該響應斷言的展示屬性
# 2.apply to 這裡我們選擇預設 Main sample only 即可
# 3.測試欄位主要是指我們是根據response的哪一部分來進行斷言匹配
# 響應文字:來自伺服器的響應文字,即主題
# 響應程式碼:響應狀態碼,例如200
# 響應資訊:響應的資訊,例如OK
# 響應頭:響應頭部
# 請求頭:請求頭部
# URL樣本:請求URL路徑
# 文字:響應的整個文字資訊
# 請求資料:請求資料
# 忽略狀態:請注意這裡是核取方塊,因為我們的斷言有響應碼自動判斷機制,如果我們需要判斷響應碼為非200狀態,我們需要將其勾選防止報錯
# 4.模式匹配規則
# 包括:文字包含指定的正規表示式
# 匹配:整個文字完全匹配指定的正規表示式
# 相等:整個返回結果文字完全匹配指定的字串
# 字串:返回結果文字包含指定的字串
# 否:當存在多個測試模式時,預設為and(當全部滿足才通過斷言),如果勾選這裡相當於!(全部不滿足才通過斷言)
# 或者:當存在多個測試模式時,預設為and(當全部滿足才通過斷言),如果勾選這裡相當於or(存在一個滿足就通過斷言)
# 當然否和或者你也可以一起使用,相當於!or(存在一個不滿足就通過斷言)
# 5.測試模式
# 我們可以新增多個測試模式
# 測試模式其實就是斷言的判斷值,與response進行比較
# 其實整體如果採用pytest展示
# 結果值 比較方式 預期值 --> ${測試欄位} ${模式匹配規則} ${測試模式}
# text == "百度一下,你就知道"
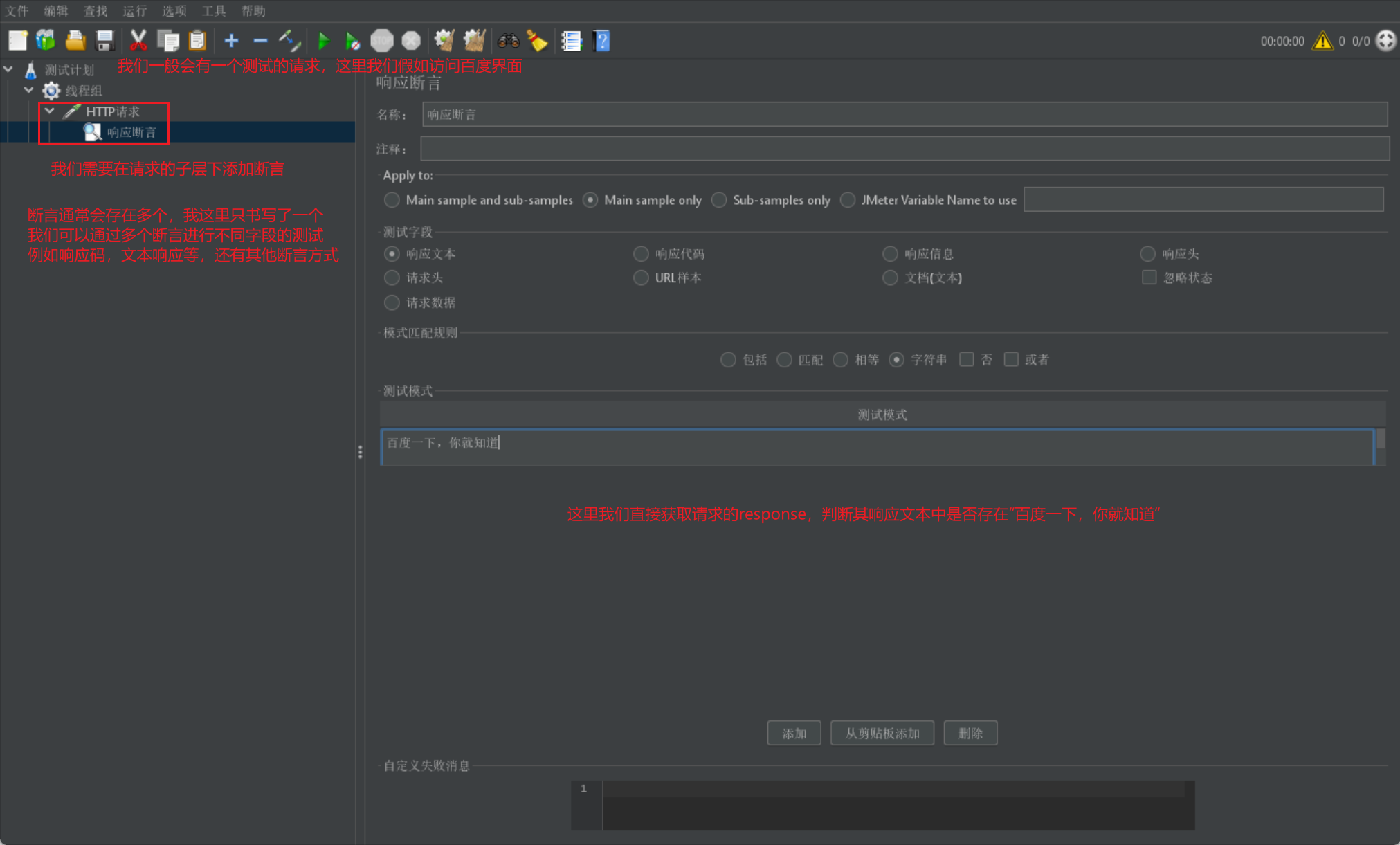
我們使用斷言一般是放在請求的下層,當請求執行後就會採用請求返回的response來進行斷言判斷:
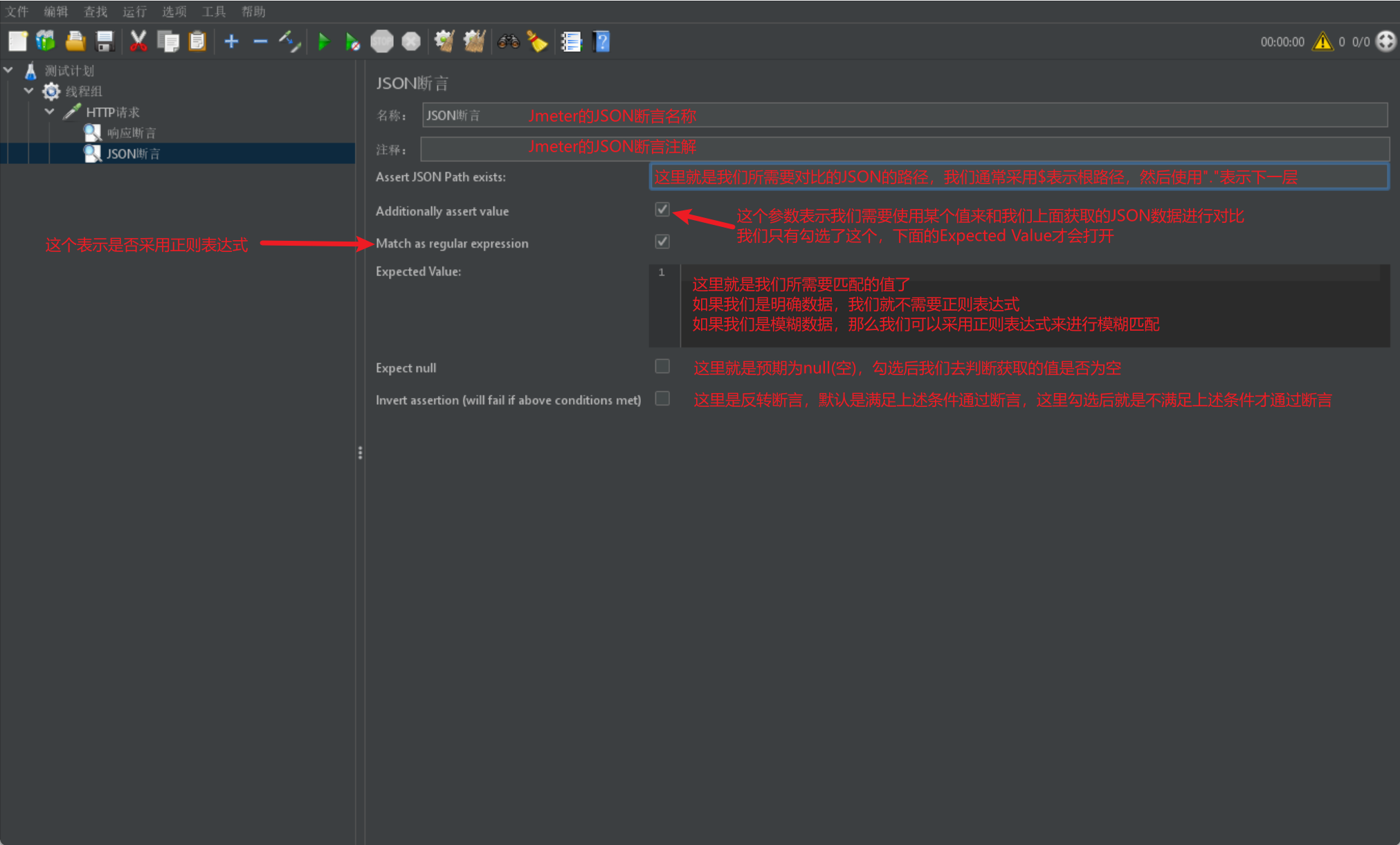
JSON斷言
下面我們來介紹JSON斷言,同樣我們直接給出一張圖片:
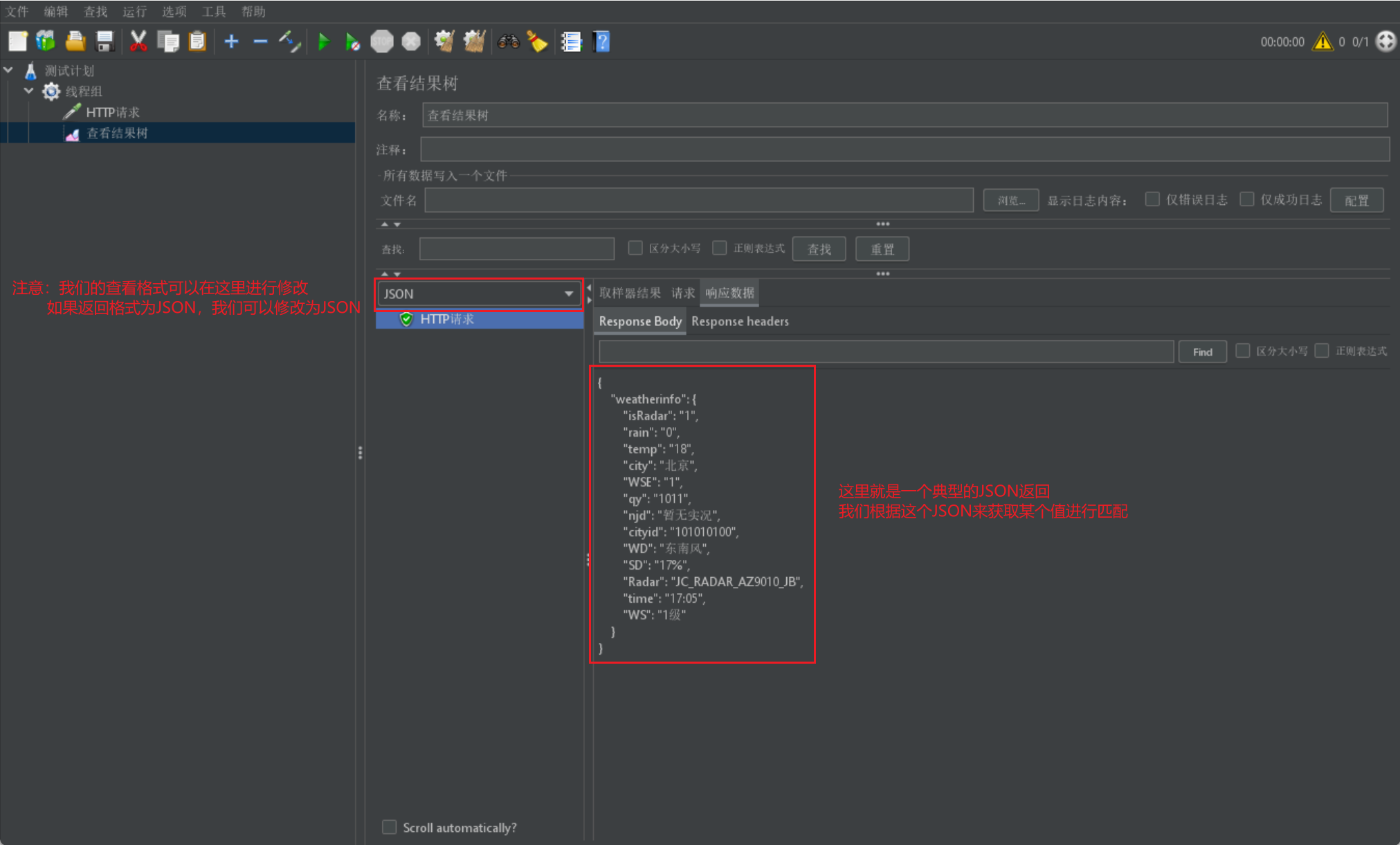
我們已經介紹過上述概念了,我們首先給出一個請求所獲取的返回結果:
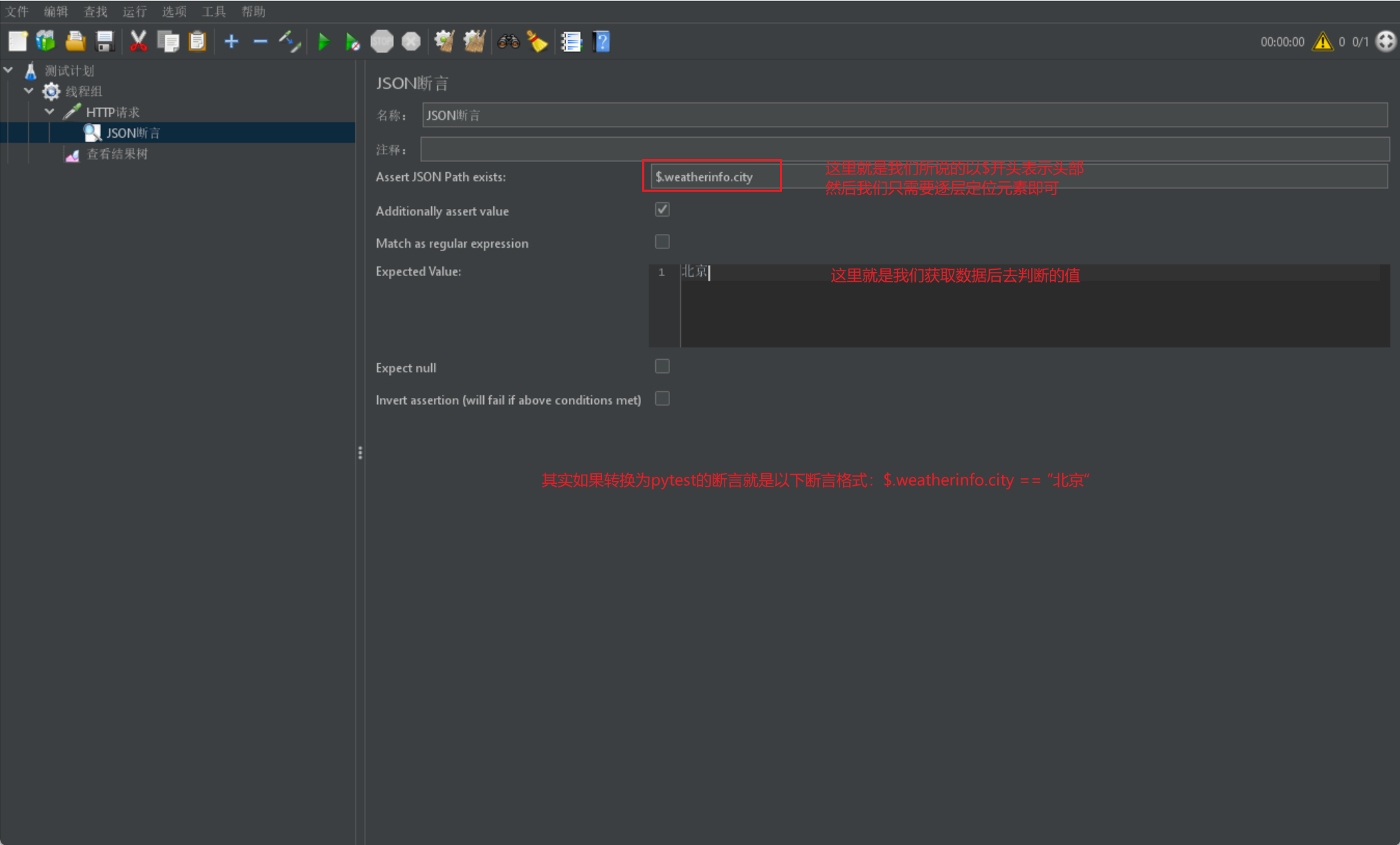
下面我們來獲取上述JSON中的某個欄位來進行匹配判斷:
時間斷言
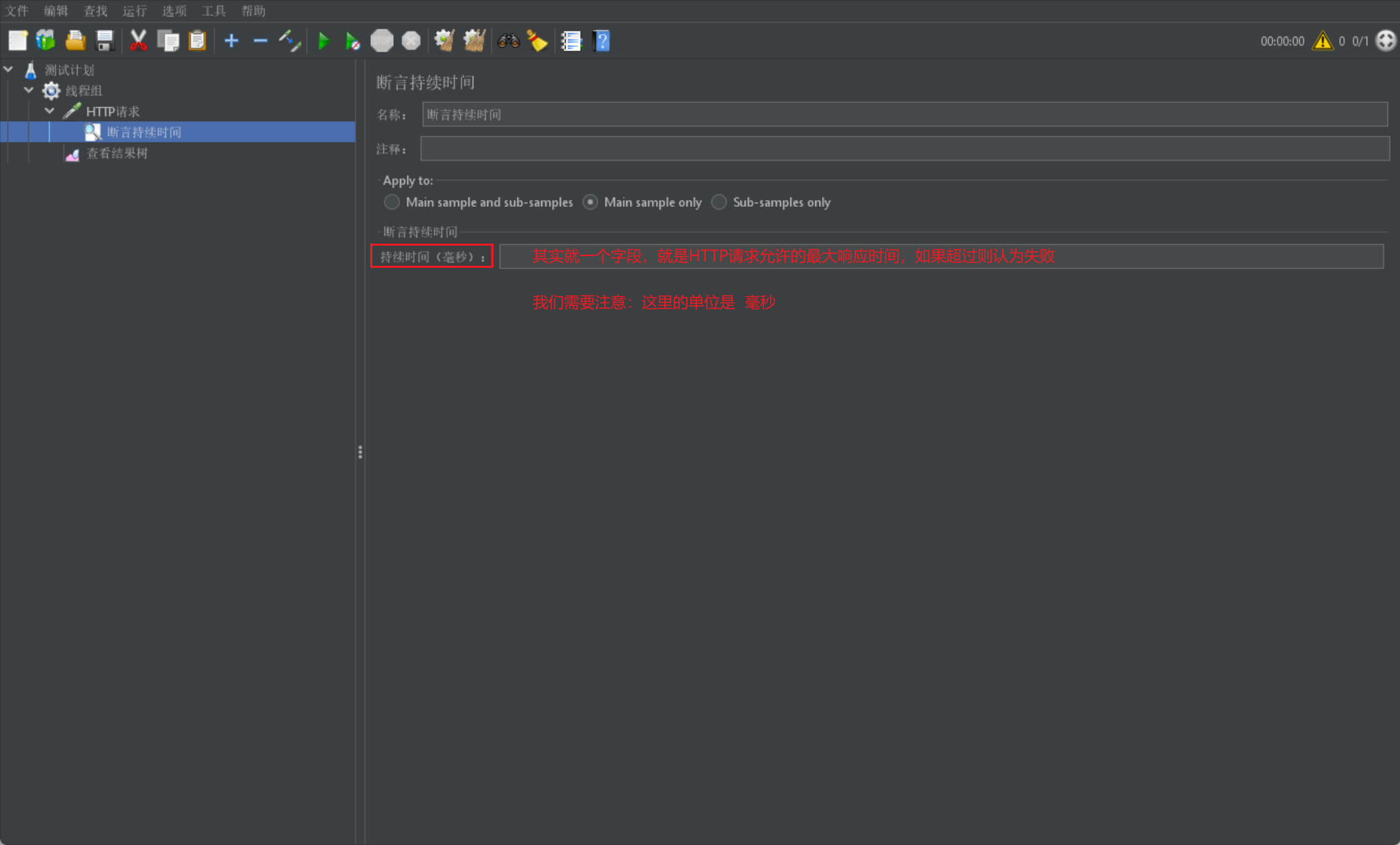
除了上述我們對結果進行斷言判斷外,我們有時還需要進行效能測試,我們就需要判斷在規定時間內是否滿足條件:
- 」斷言持續時間」就是專門用來進行時間判斷的斷言
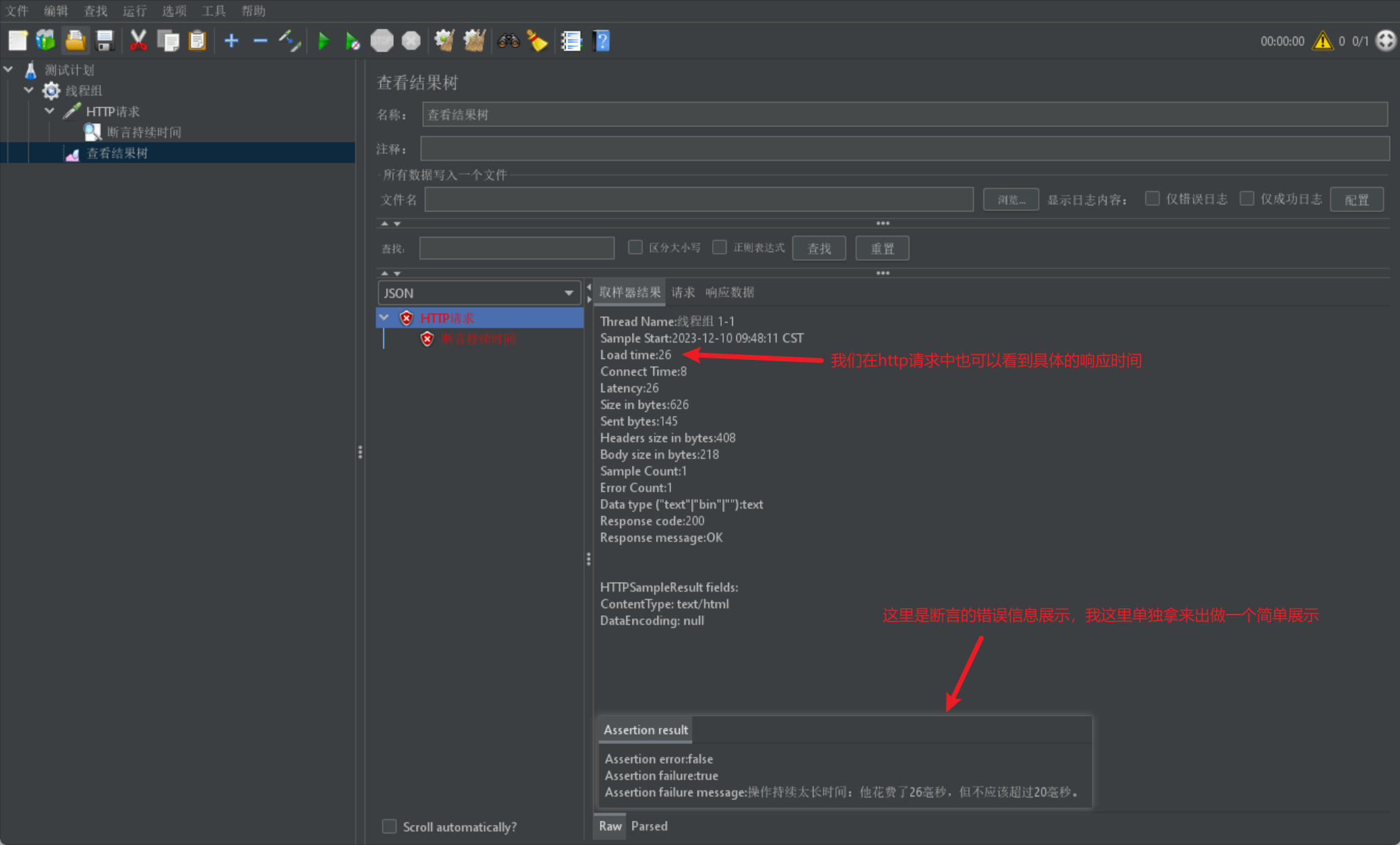
我們直接給出一張斷言持續時間介面圖:
我們同樣給出一個簡單的結果範例展示:
Jmeter關聯介紹
我們在使用Jmeter時難免會遇到關聯關係:
- 當請求之間有依賴關係,就被稱為關聯
- 例如一個請求的請求引數是另一個請求的請求響應結果
正規表示式提取器
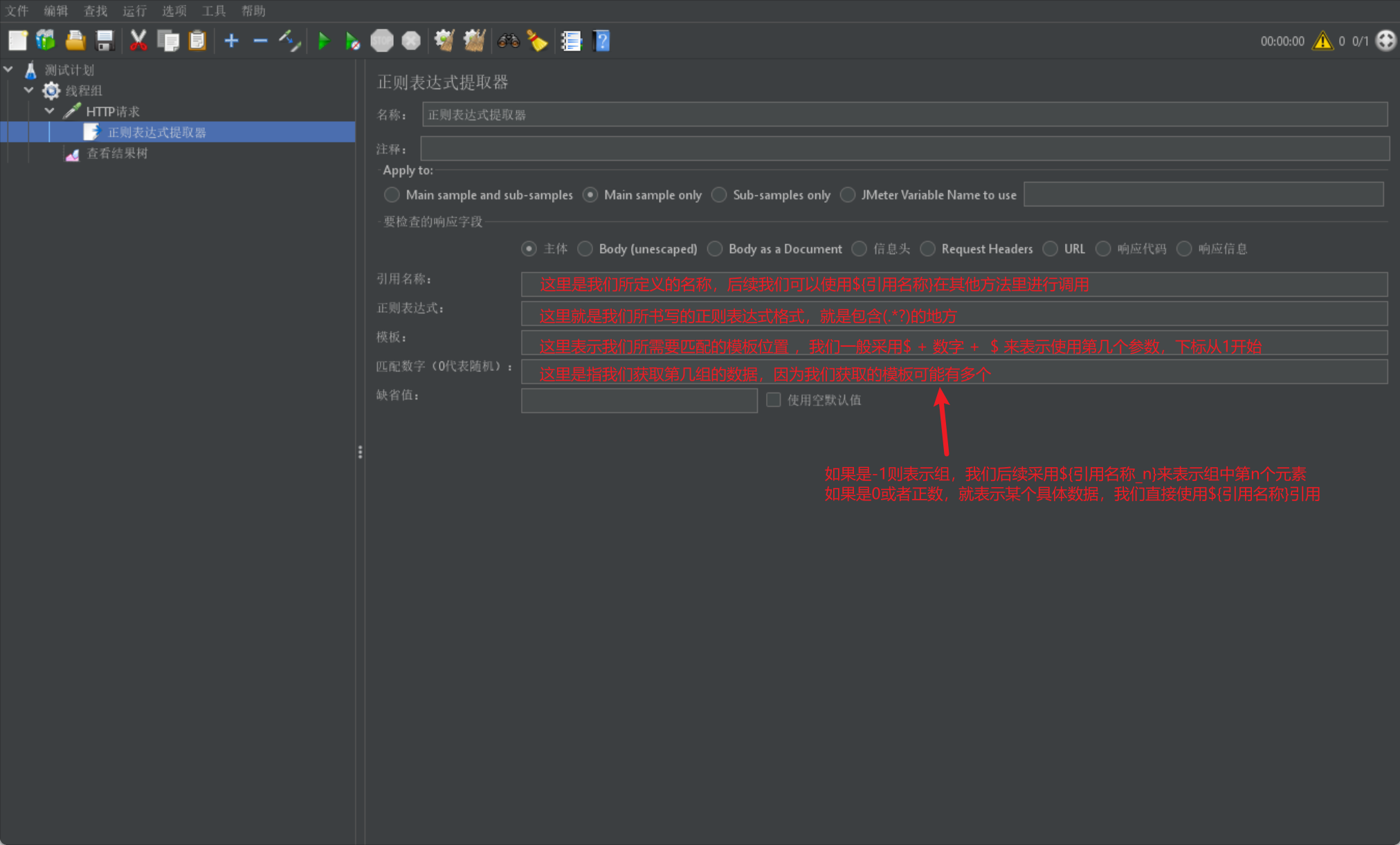
我們首先來介紹正規表示式提取器:
# 正規表示式我這裡給出簡單定義,因為大部分人之前應該已經學習過這部分知識
# 就是一個公式,或者說一套規則,使用這套規則可以從任意字串中提取出想要的資料內容
# 公式格式:左邊界 + (匹配符號) + 右邊界
# 我們可以通過該公式進行其部分資料內容的提取
# 我們常用的匹配符號主要包含以下三種:
# .:是萬用字元,可以代表任意字元(除換行回車)
# *: 代表前面的字元出現0次或者多次
# .*匹配規則:找到左邊界值後,往右查詢有邊界,找到最後面的右邊界,中間的所有資料都被記錄下來
# ?: 代表非貪婪匹配,找到左邊界後,往右查詢匹配右邊界,只要有匹配的右邊界就停止繼續查詢;再次查詢
# 1. 正常響應結果查詢
# 公式格式:左邊界(.*)右邊界
# 這種就是獲取結果的一種表達,但是該公式會導致如果存在多個標籤符號,可能會出現跨越多個標籤的結果
# 例如如果我們使用 <title>(.*)</title>
# 如果我們尋找的文字是"<title>百度一下,你就知道</title><title>百度一下,你就知道</title>"
# 上述情況我們就會提取到 "百度一下,你就知道</title><title>百度一下,你就知道"
# 公式格式:左邊界(.*?)右邊界
# 經過上述版本的優化非貪婪匹配,我們獲取到第一個右邊界就停止匹配
# 例如如果我們使用 <title>(.*?)</title>
# 如果我們尋找的文字是"<title>百度一下,你就知道</title><title>百度一下,你就知道</title>"
# 上述情況我們就會提取到 "百度一下,你就知道"
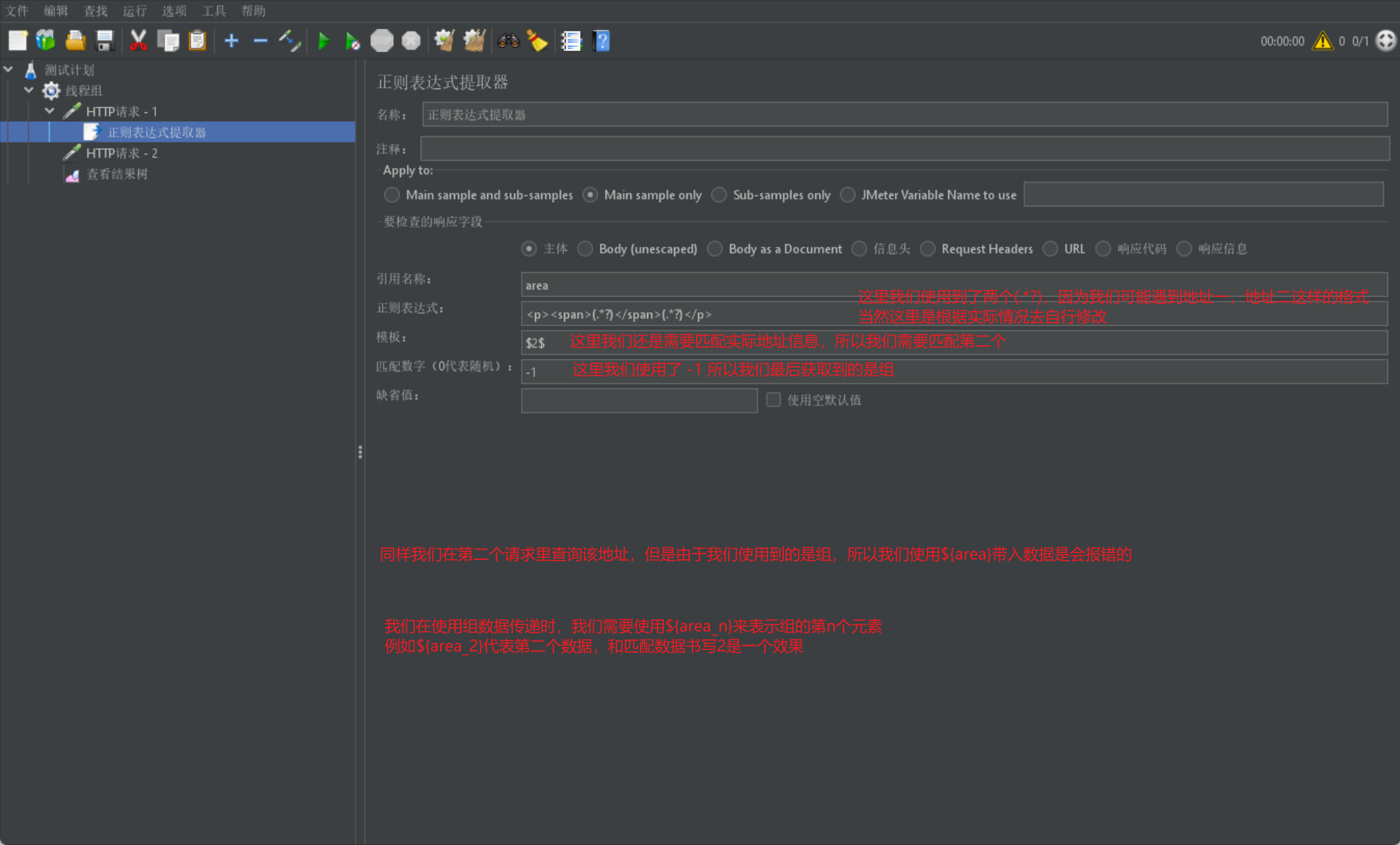
# 2. 文字資料結果查詢
# 我們在使用過程中也可能出現以下格式:(分別表示 城市號、地區號、個人號碼)
021-1234-1234
022-1234-1235
023-1234-1236
024-1234-1237
025-1234-1238
026-1234-1239
027-1234-1230
# 那麼我們在匹配時就可以採用多個正規表示式進行匹配
# 我們可以使用:(.*?)-(.*?)-(.*?)\n 進行匹配,需要注意\n,因為我們的資料是存在換行的
# 最後我們還需要注意,我們這裡由於是多行資料,所以最後我們的獲取的資料其實也是多行的,我們後續是需要進行處理的
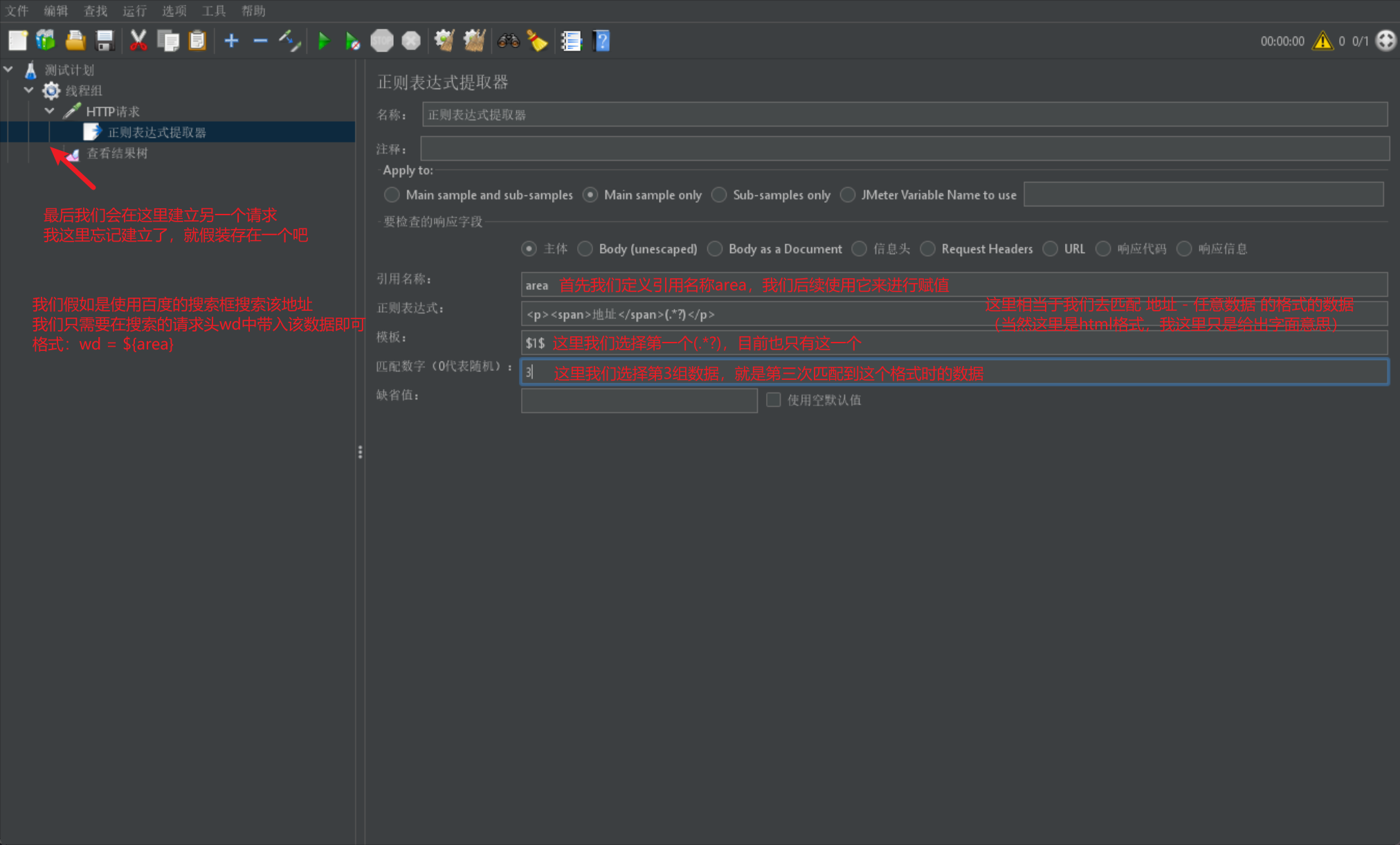
我們首先給出案例圖來進行介紹:
我們首先給出正規表示式的正常使用範例圖:
然後我們通過一張圖來展示模板和匹配數位組的格式:
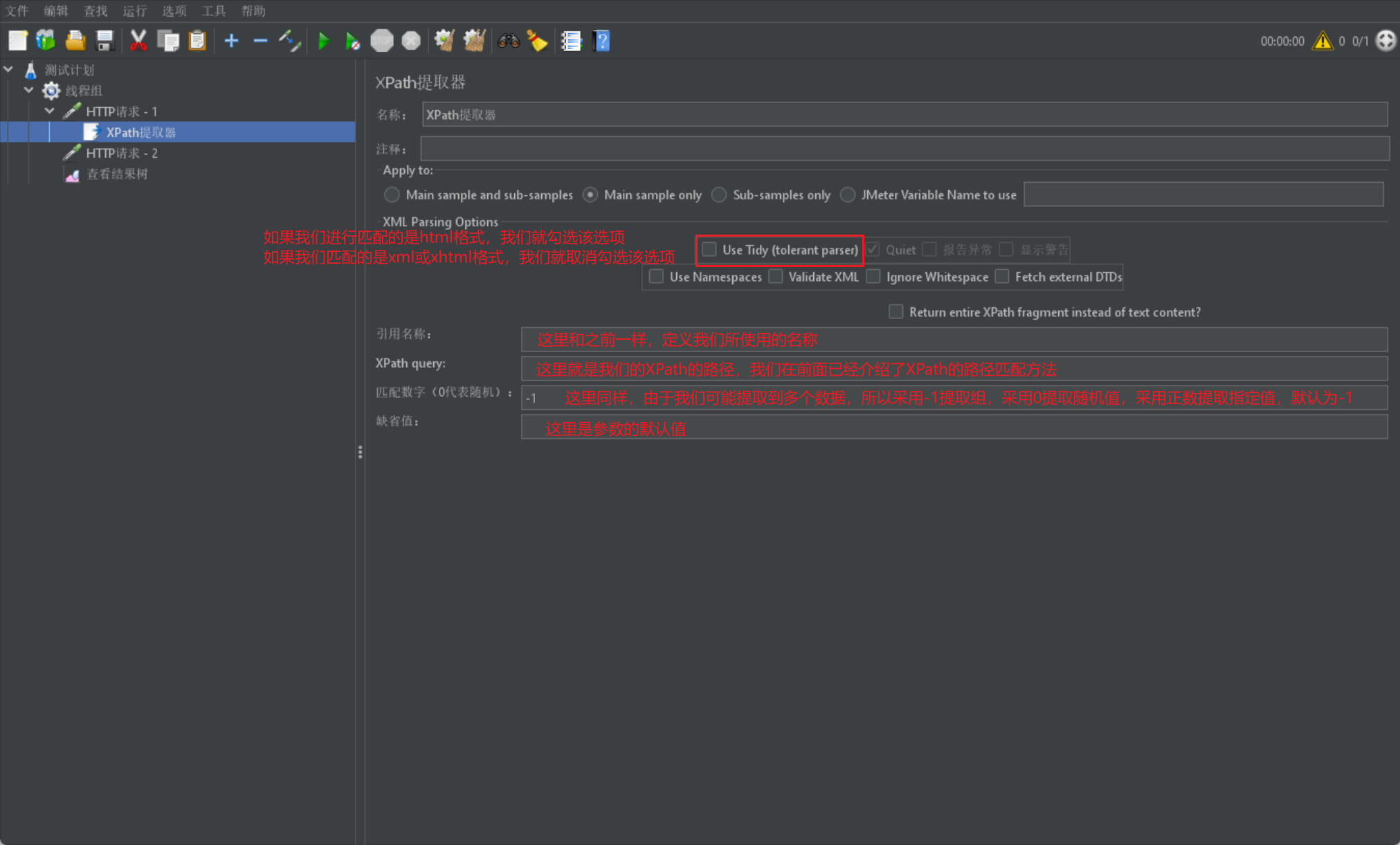
XPath提取器
下面我們來介紹XPath提取器,其實就是一個html提取器:
- XPath提取器主要針對HTML格式的響應結果資料進行提取
我們在Selenium的介紹文章裡已經介紹過XPath的具體匹配原則,這裡我把介紹文字貼上了一下方便大家檢視:
# 首先我們還是給出XPath的使用格式
element = driver.find_element(By.XPATH,xpath)
# XPath一般分為四種定位方法,我們會在下面一一展示
# 1. 路徑-定位
# 路徑定位一般劃分為絕對路徑定位和相對路徑定位
# 絕對路徑定位:以 /html根節點 開始,使用/來分隔元素層級
# 例如/html/body/div/fieldset/p[1]/input,表示html層級下的body層級下的....的第一個p下的input元素
# 需要注意我們的html元素是以1開頭,並不是以0開頭,這裡的1就是指一組p標籤的第一個元素
driver.find_element(By.XPATH,"/html/body/form/div/fieldset/p[1]/input").send_keys("admin")
# 相對路徑定位:以 //確定元素 開始,後續使用/來分隔元素層級
# 例如//p[@id='p1']/input,表示id為p1的p標籤元素下的input元素
# 我們通常使用//來表示第一個可以確認的相對路徑的元素,而這個元素通常採用標籤名開頭,我們可以使用[]來加上其對應的屬性來確定元素
# 我們通常在[]裡新增單個屬性或多個屬性來確定元素,我們通常使用@屬性名=屬性值的格式來表示,例如@id='p1'
driver.find_element(By.XPATH,"//p[@id='p1']/input").send_keys("123")
# 2. 利用元素屬性-定位
# 一個元素通常會有多個屬性,包括id,name以及自定義屬性等
# 例如//input[@id='passwordA'],表示該id為passwordA的input元素
driver.find_element(By.XPATH,"//input[@id='passwordA']").send_keys("123")
# 3. 屬性與邏輯結合-定位
# 如果我們出現元素內含有多個屬性,且每個屬性都有多個元素共用,我們就不能使用單個屬性進行元素定位
# 所以我們需要使用邏輯方法來進行多屬性判定,例如and,or等方法
driver.find_element(By.XPATH,"//input[@id='passwordA' and @placeholder='密碼A']").send_keys("123")
# 4. 層級與屬性結合-定位
# 如果通過元素自身的資訊不方便直接定位到該元素,則可以先定位到其父級元素,然後再找到該元素
# 例如我們所需要定位的input上沒有任何獨立的屬性,但是它的父類別有獨立屬性,那麼我們就可以根據父元素去定位子元素
driver.find_element(By.XPATH,"//*[@id='p1']/input").send_keys("123")
# 最後我們介紹幾個XPATH的常用的延申內建屬性方法
# 下面的*表示任意元素,這個是HTML中所定義的內容
# 文字內容是xxx的元素
driver.find_element(By.XPATH,"//*[text()="xxx"]")
# 屬性中含有xxx的元素
driver.find_element(By.XPATH,"//*[contains(@attribute,'xxx')]")
# 屬性以xxx開頭的元素
driver.find_element(By.XPATH,"//*[starts-with(@attribute,'xxx')]")
那麼我們首先還是給出XPath的展示圖:
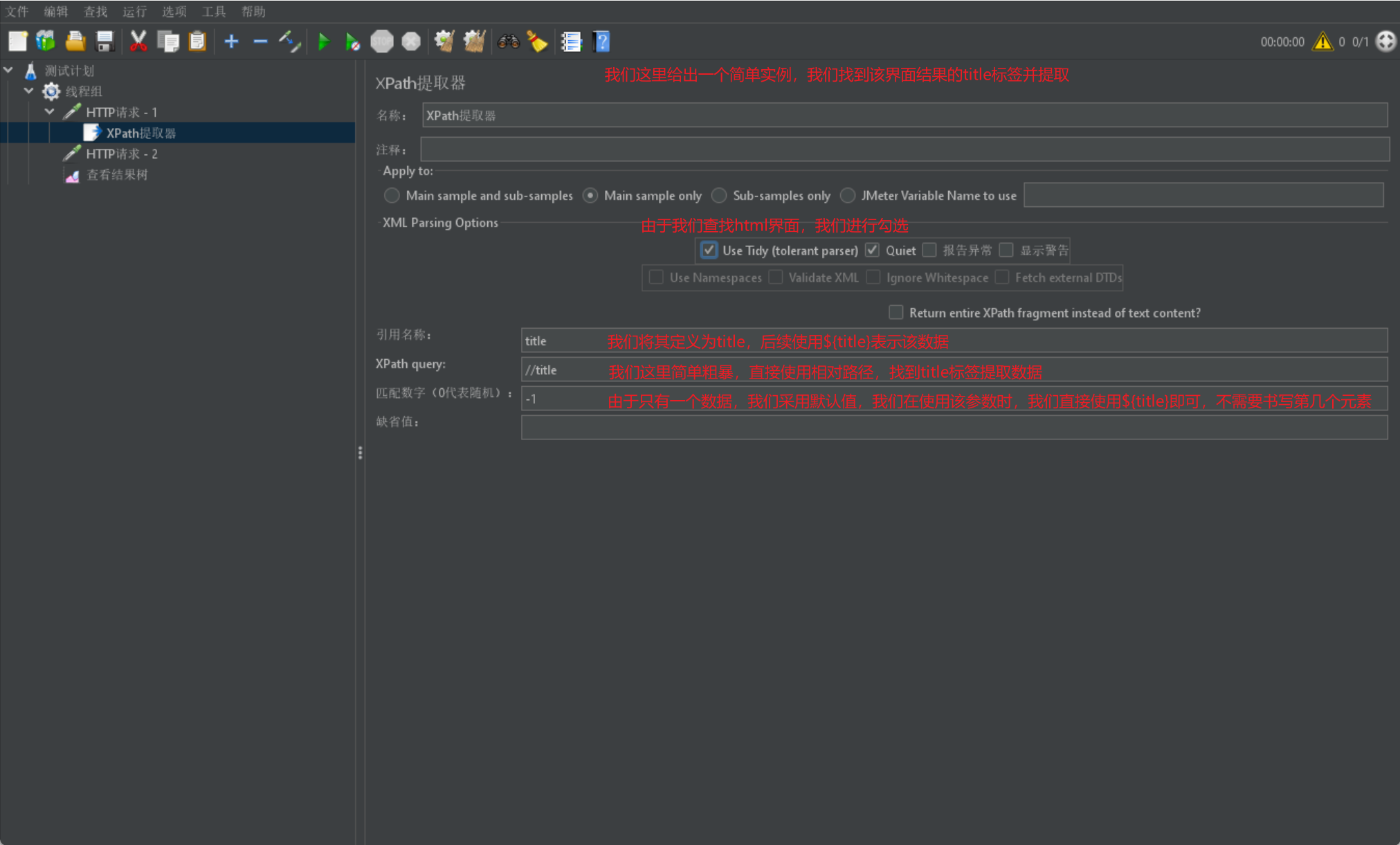
我們同樣給出一張簡單範例圖:
JSON提取器
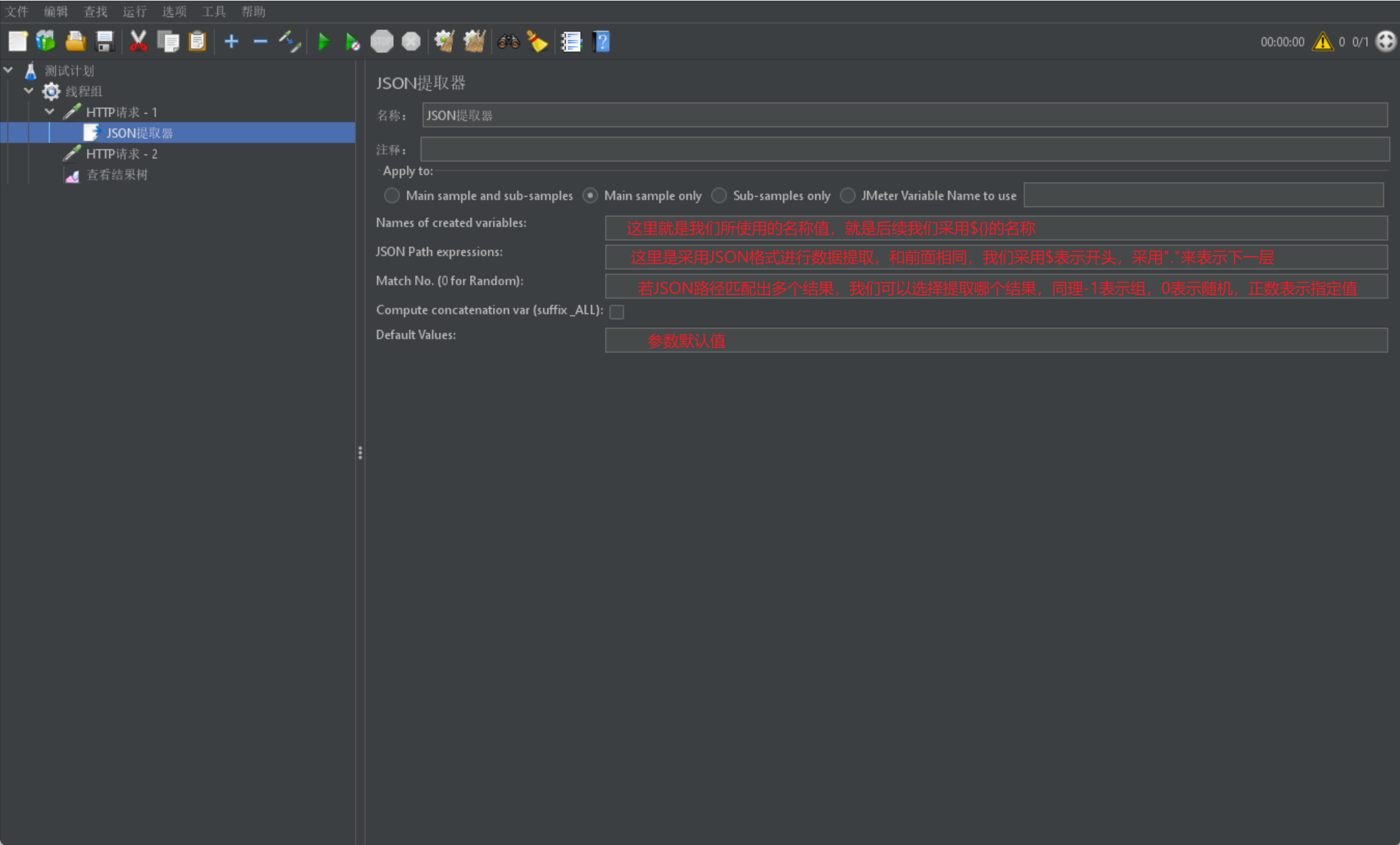
最後我們再來介紹一個JSON提取器,同樣也是很簡單的格式:
- JSON提取器主要針對返回結果是JSON的響應結果資料進行提取
我們同樣首先給出一張展示圖並進行解釋:
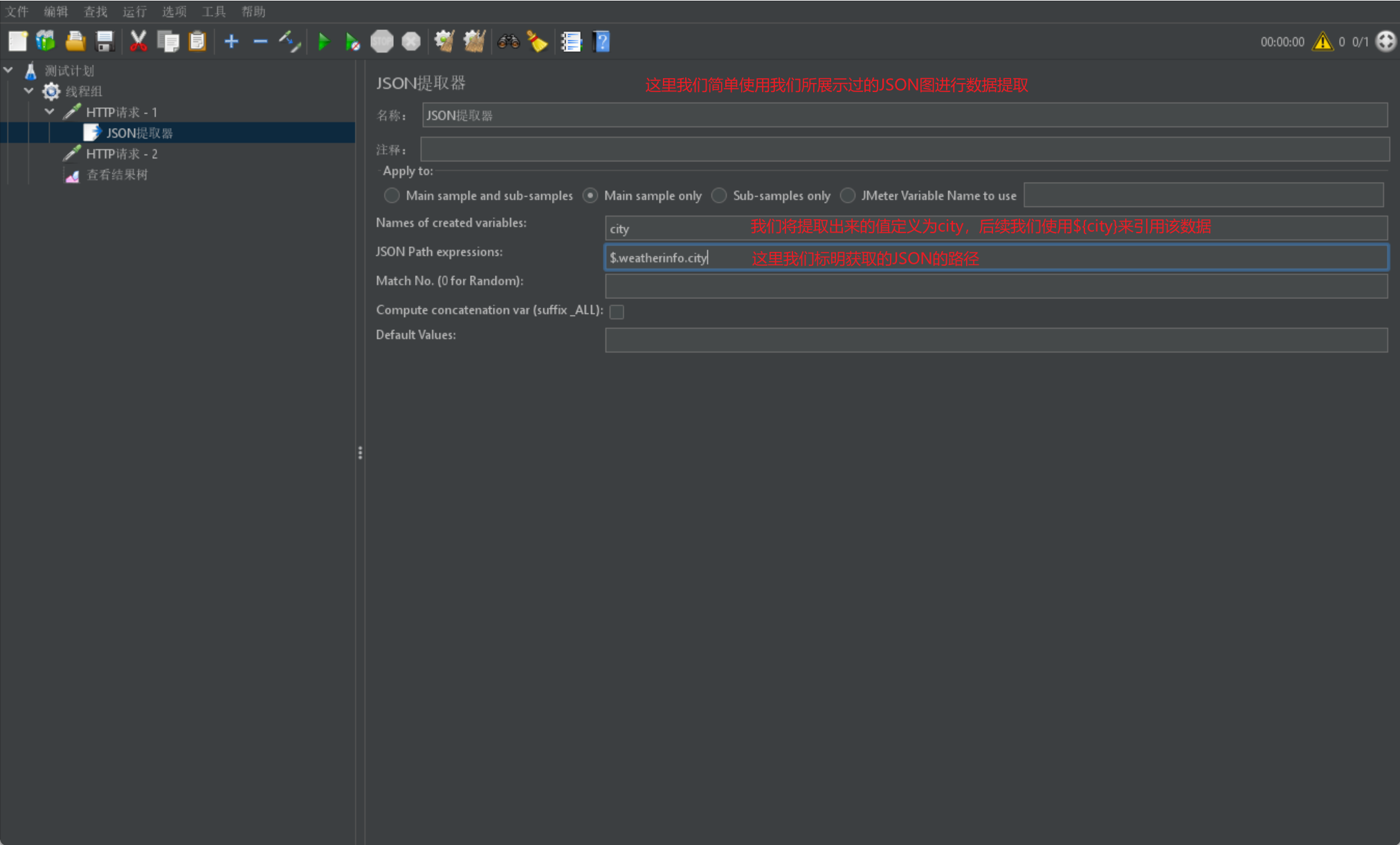
我們給出一張簡單範例圖解釋:
Jmeter屬性介紹
下面我們來介紹Jmeter的屬性相關資訊:
- 我們前面使用的關聯僅僅能在同一個執行緒組中進行使用,若我們想在不同執行緒組中使用就需要採用屬性
- 我們需要將我們所需要使用到的資料定義成Jmeter的全域性變數,然後我們才能在不同執行緒組中使用該屬性
Jmeter屬性的設定同樣需要函數來進行set和get操作:
- 首先我們需要有一個執行緒組1,然後執行緒組1裡呼叫請求,我們採取JSON取樣器獲得請求中的city屬性:
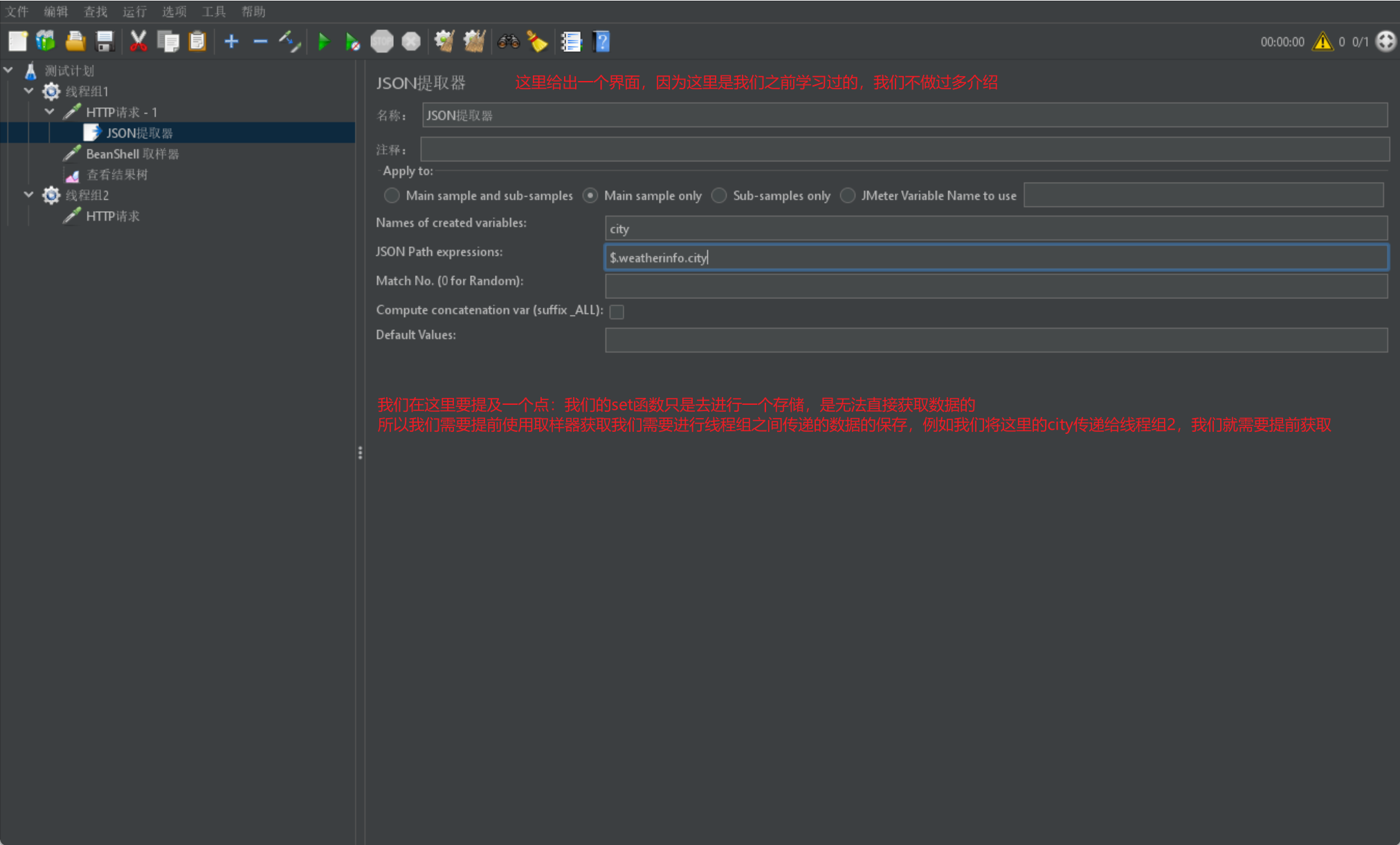
- 我們在獲取資料之後,我們首先需要去建立函數,我們可以直接書寫函數,也可以採用工具書寫:
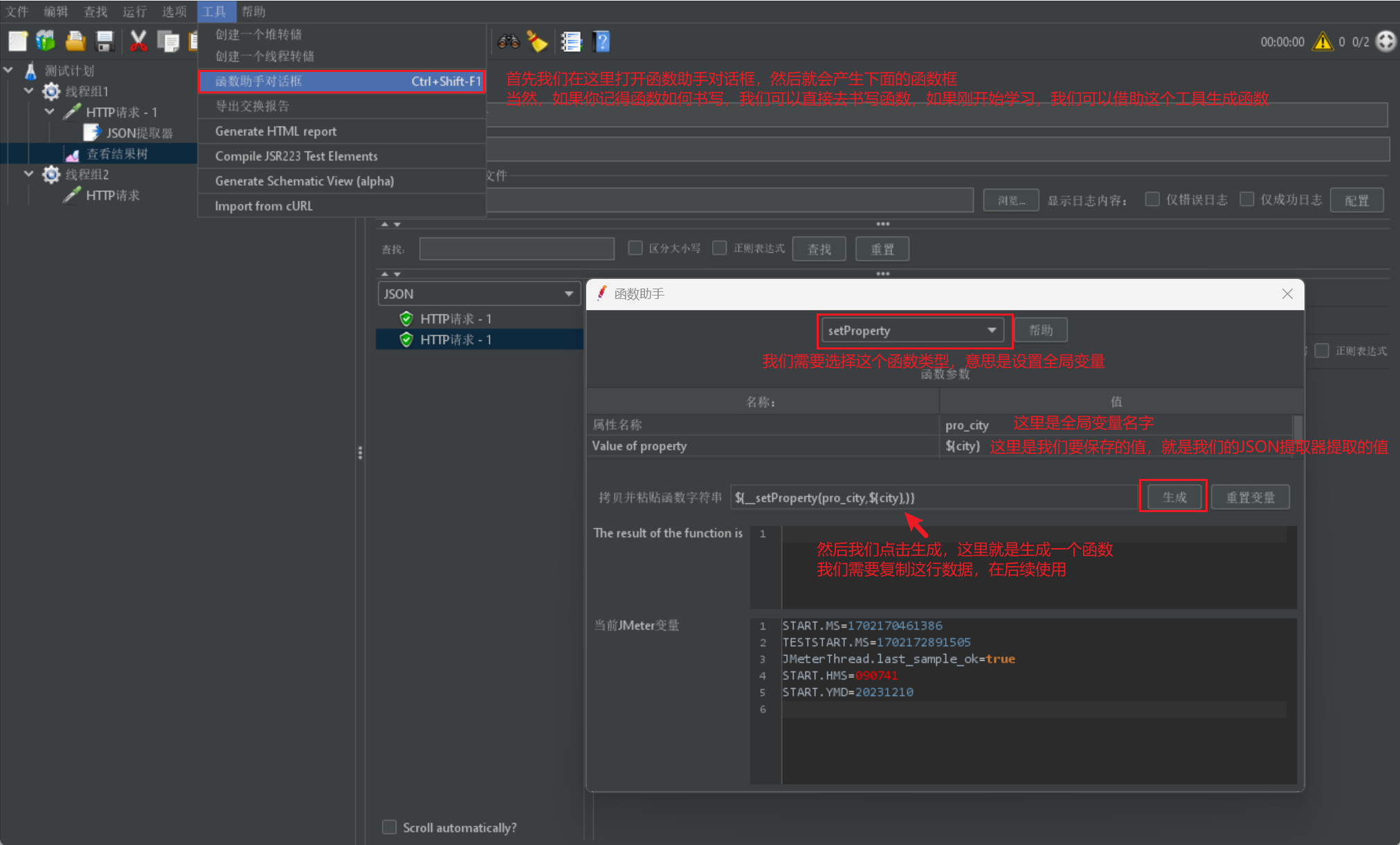
- 然後我們需要採用一個BeanShell取樣器來進行函數執行:
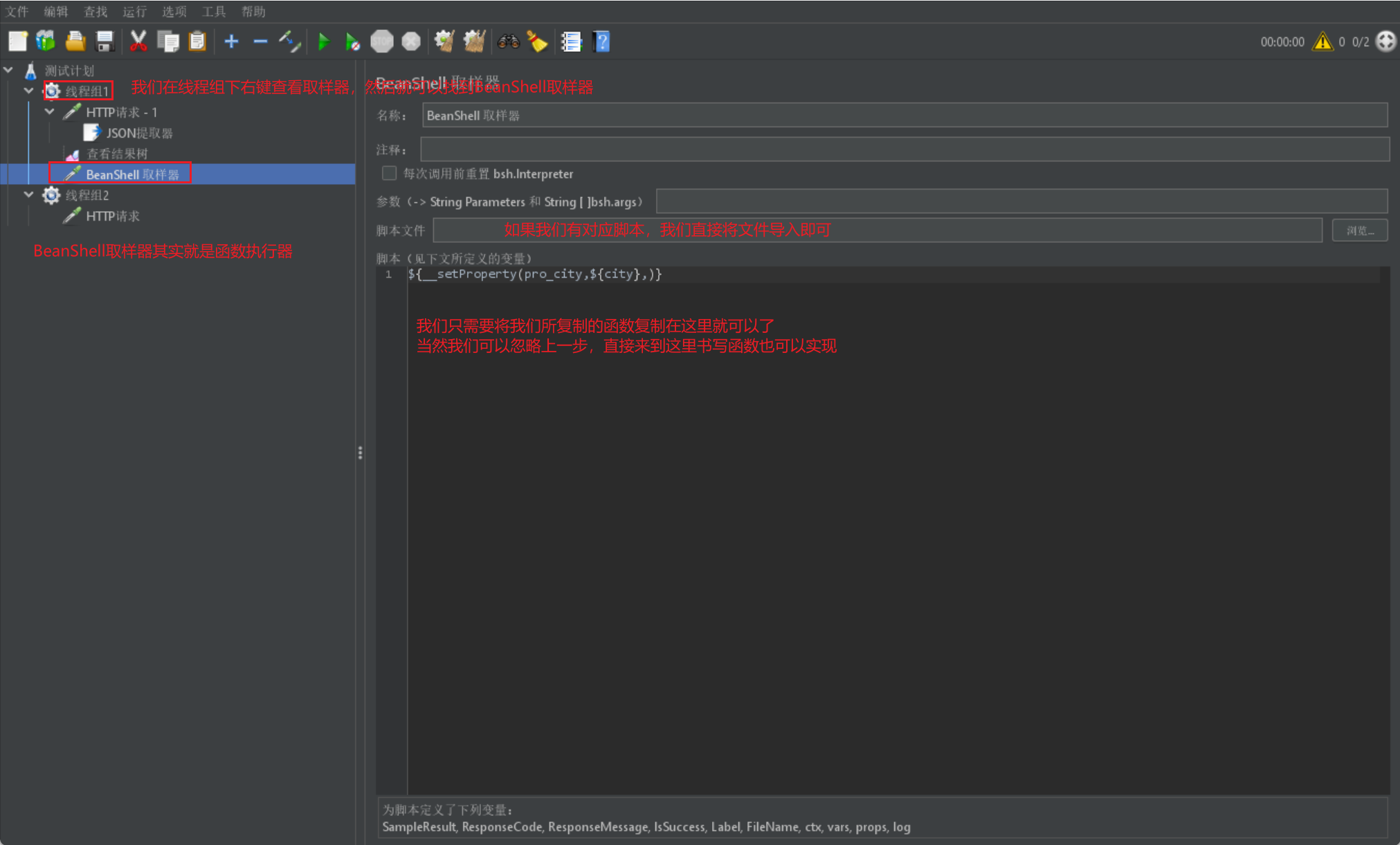
- 如果我們希望呼叫我們定義的全域性變數,我們同樣需要使用函數,我們同樣去獲取函數:
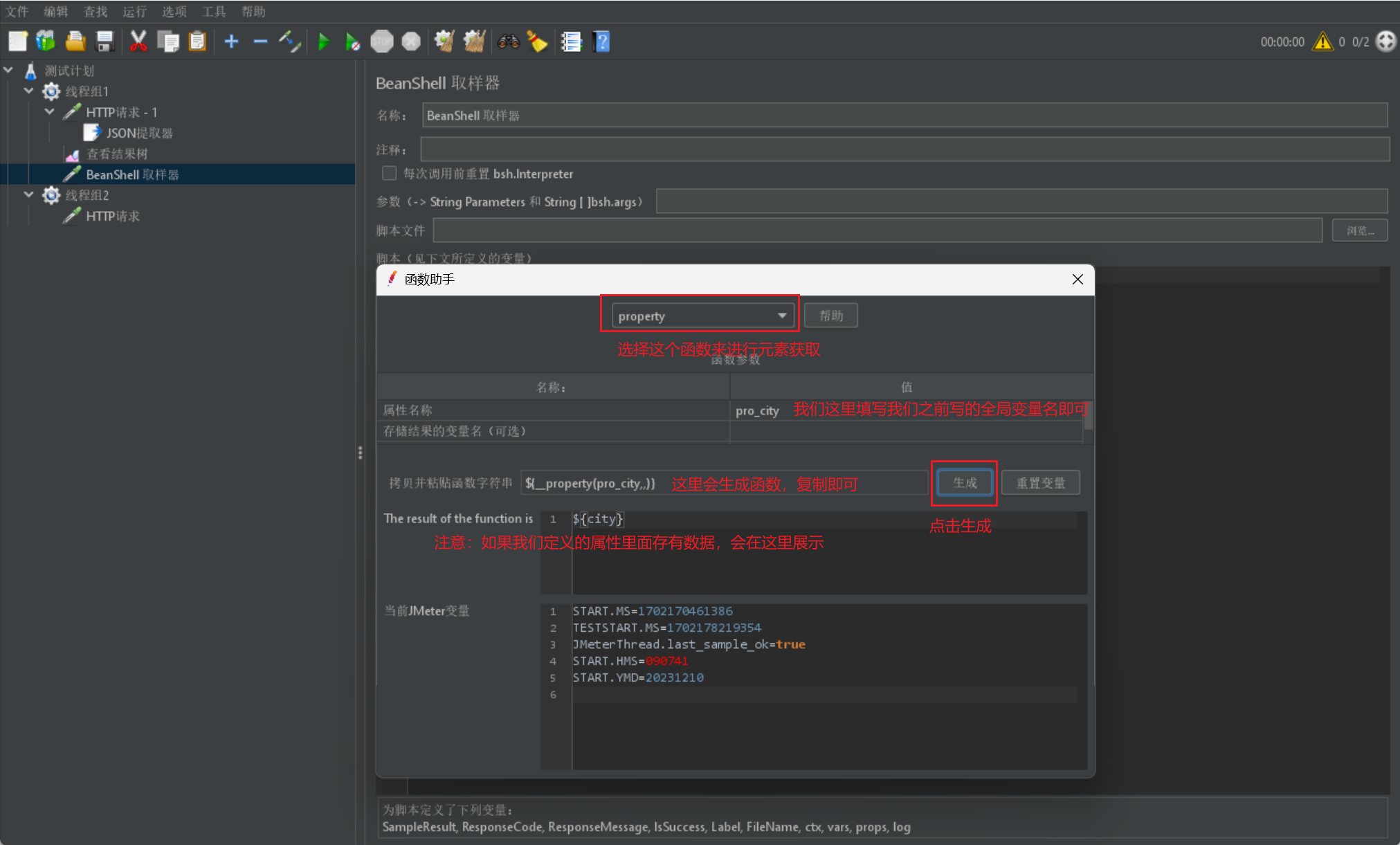
- 最後我們只需要在另一個執行緒組裡的請求裡直接使用該函數即可,不需要額外操作:
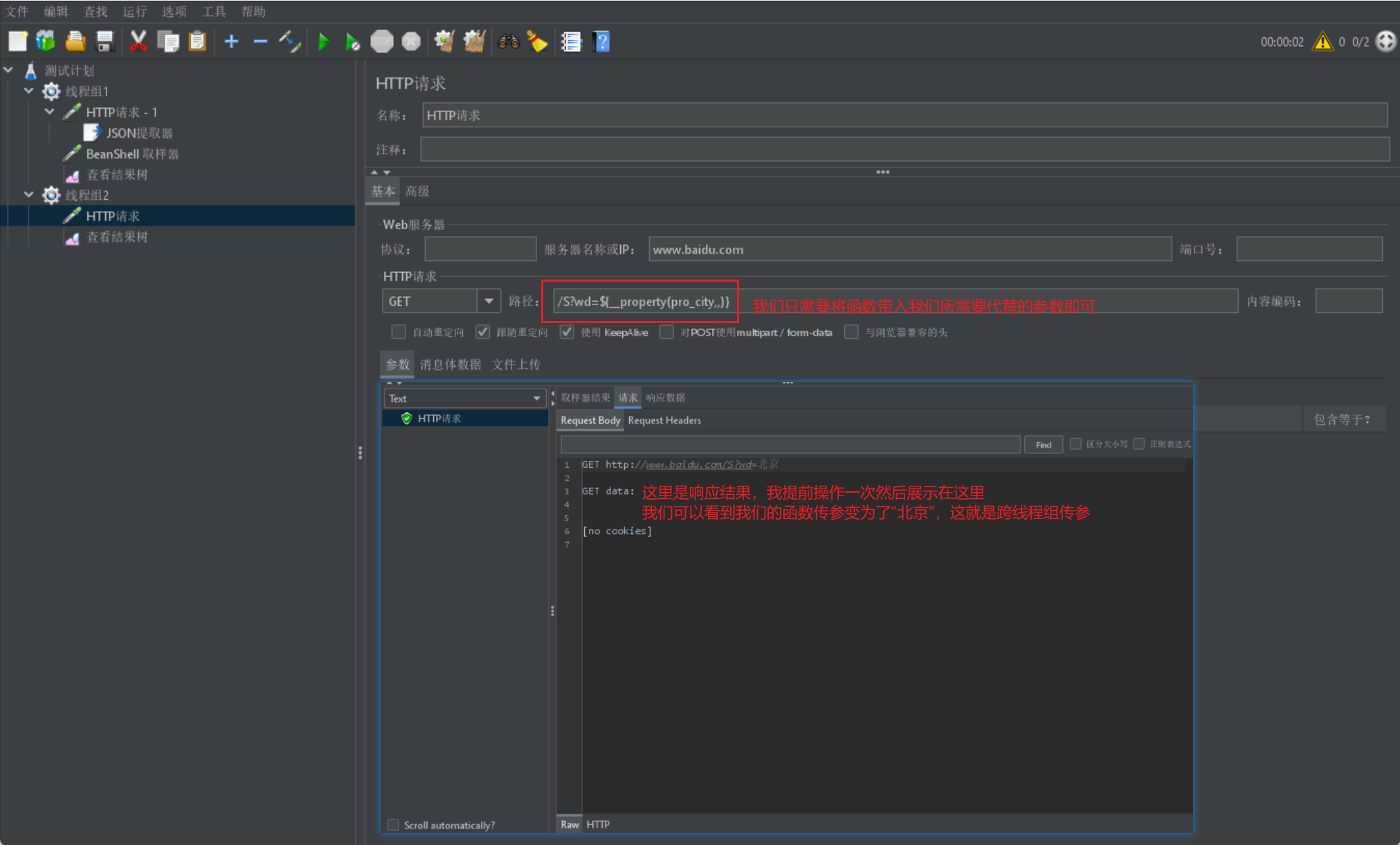
Jmeter資料庫連線
首先我們介紹一下Jmeter連線資料庫的主要作用:
- 用作請求引數化:例如登入介面所需賬號密碼,可以直接從資料庫獲取
- 用作結果的斷言:例如我們通過查詢獲取的資料,我們可以判斷該資料是否真實存在,與資料庫資訊進行比較
- 用作清除無用資料:當我們重複使用某功能時,可能存在某個欄位不能重複使用,那麼我們就需要在呼叫該功能之前刪除該欄位
- 用作準備測試資料:當我們需要大量資料時,我們可以直接從資料庫中獲取大量資料進行呼叫
接下來我們就來講解如何進行資料庫連線:
- 首先我們需要對Jmeter新增對應的資料庫jar包,下載後放在lib目錄的ext目錄下即可(下載方法在末尾):
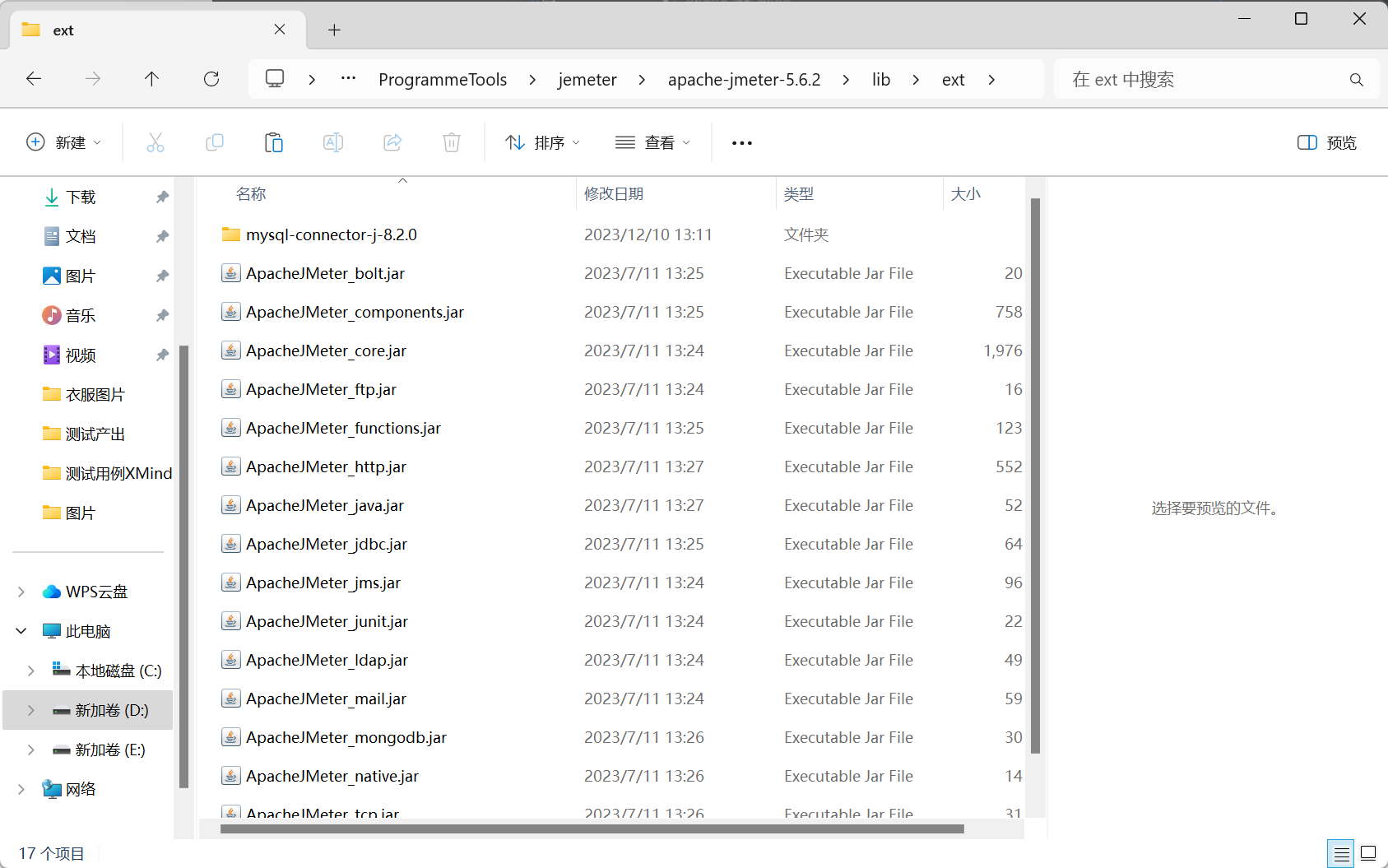
- 然後我們在Jmeter裡面設定JDBC Connection Configuration資訊:
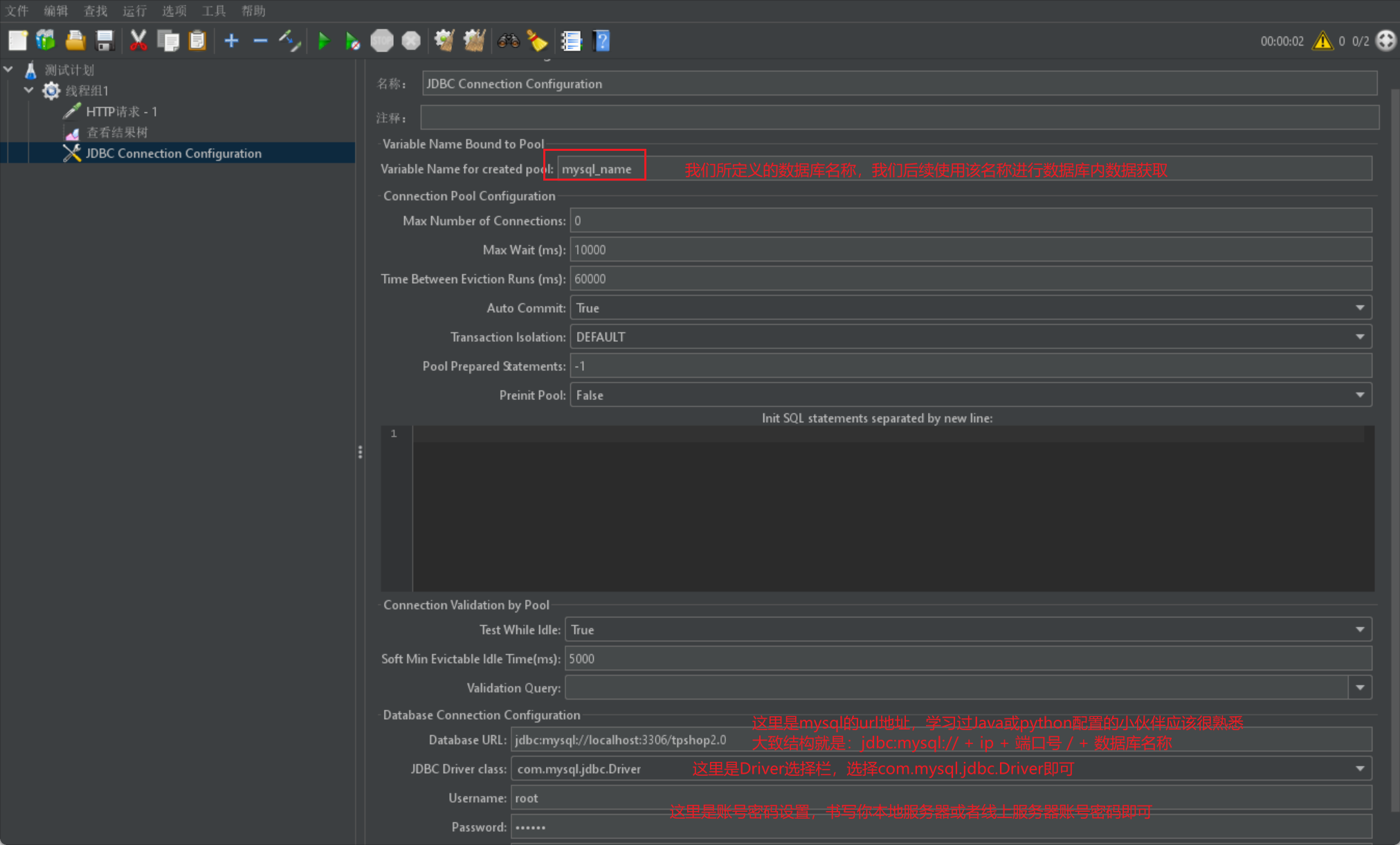
- 然後我們就可以通過JDBC請求來書寫資料庫程式碼來進行資料獲取:
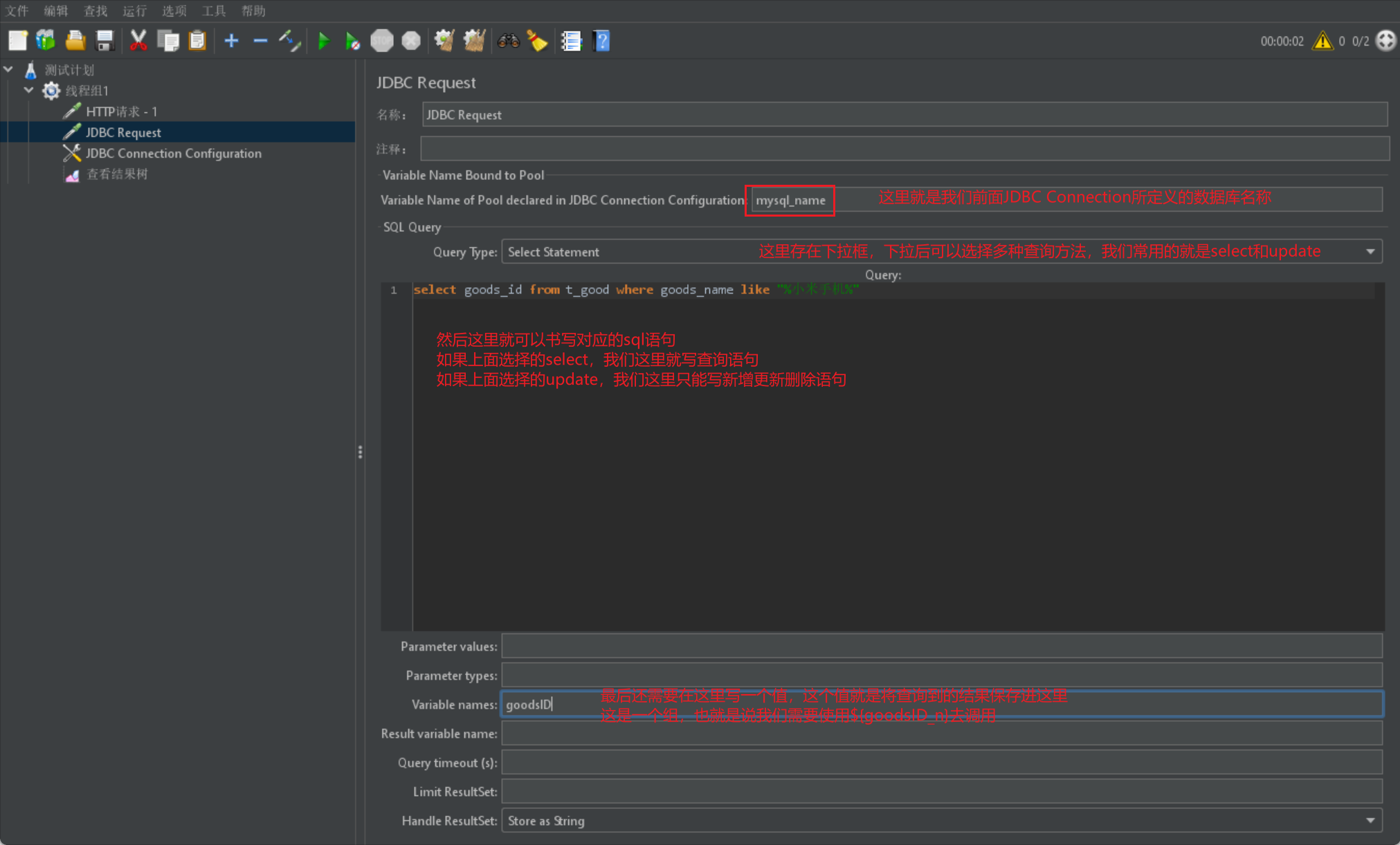
- 最後我們就可以採用這個JDBC Request去做一些斷言之類的操作:
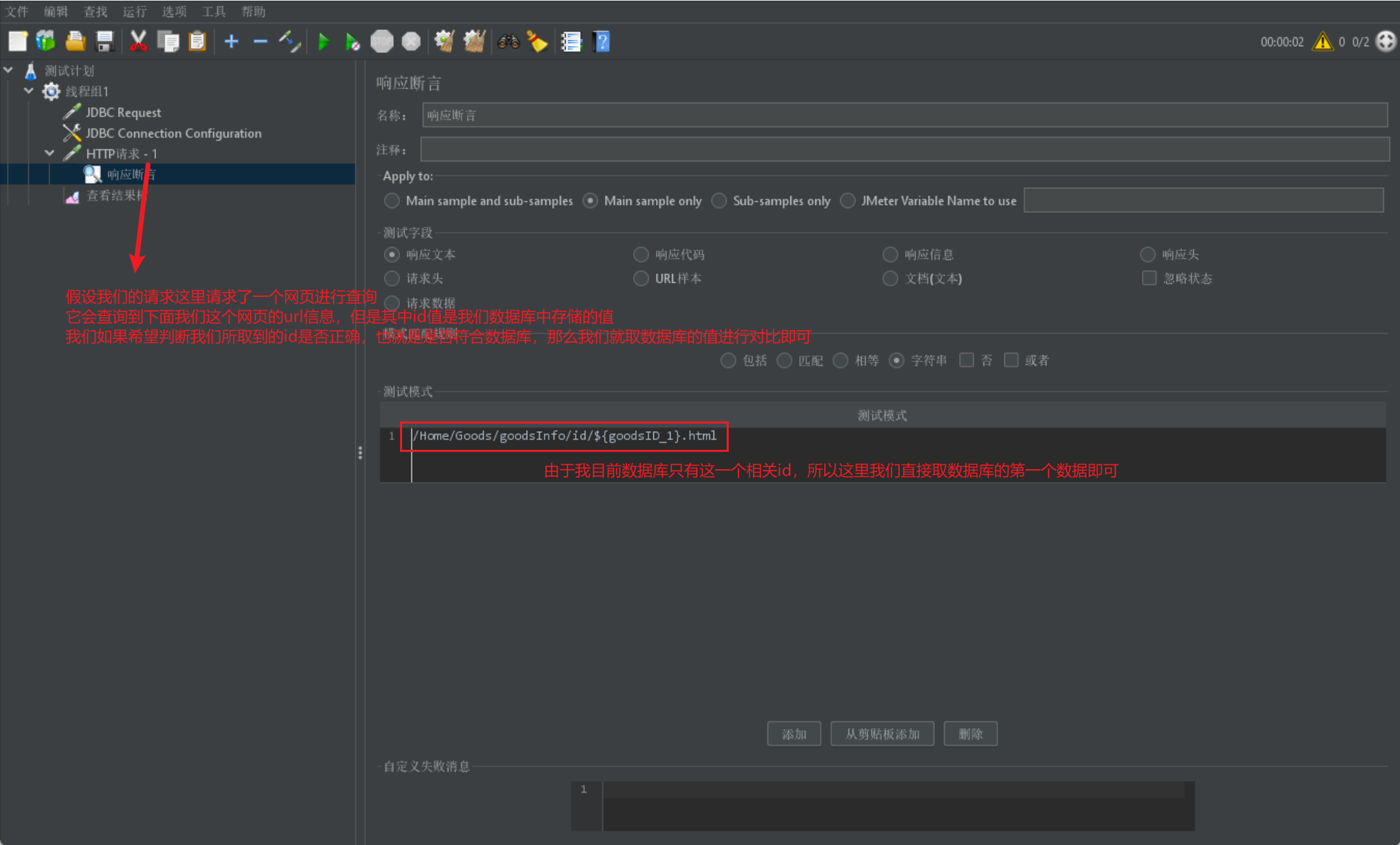
Jmeter邏輯控制器
我們在進行Jmeter操作的時候可能會進行過濾或者重複操作等,我們就會使用到邏輯控制器
If邏輯控制器
首先我們來介紹if邏輯控制器:
- If邏輯控制器用來控制它下面的測試元素是否執行
然後我們給出一張if邏輯控制器的展示圖進行引數介紹:
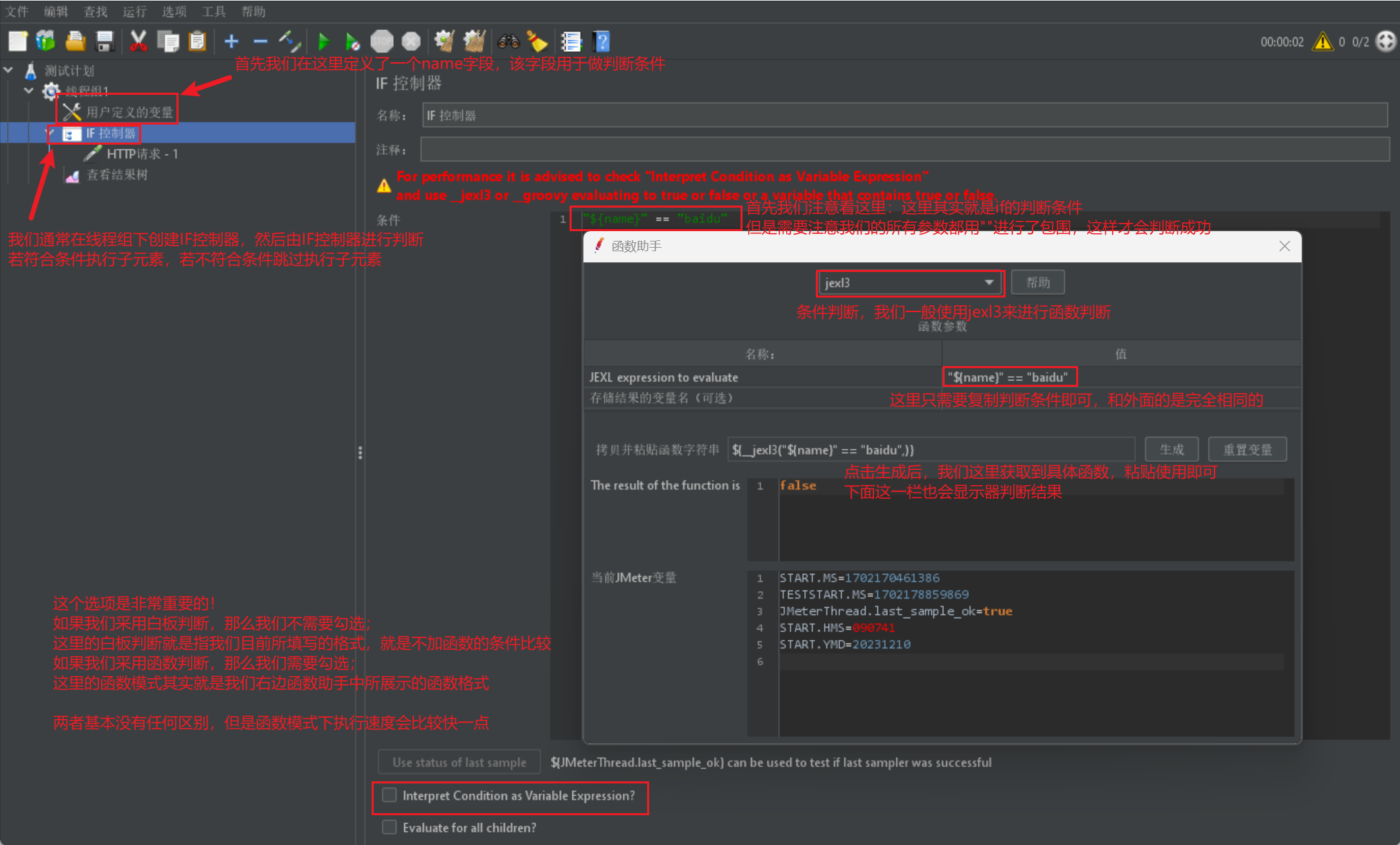
while邏輯控制器
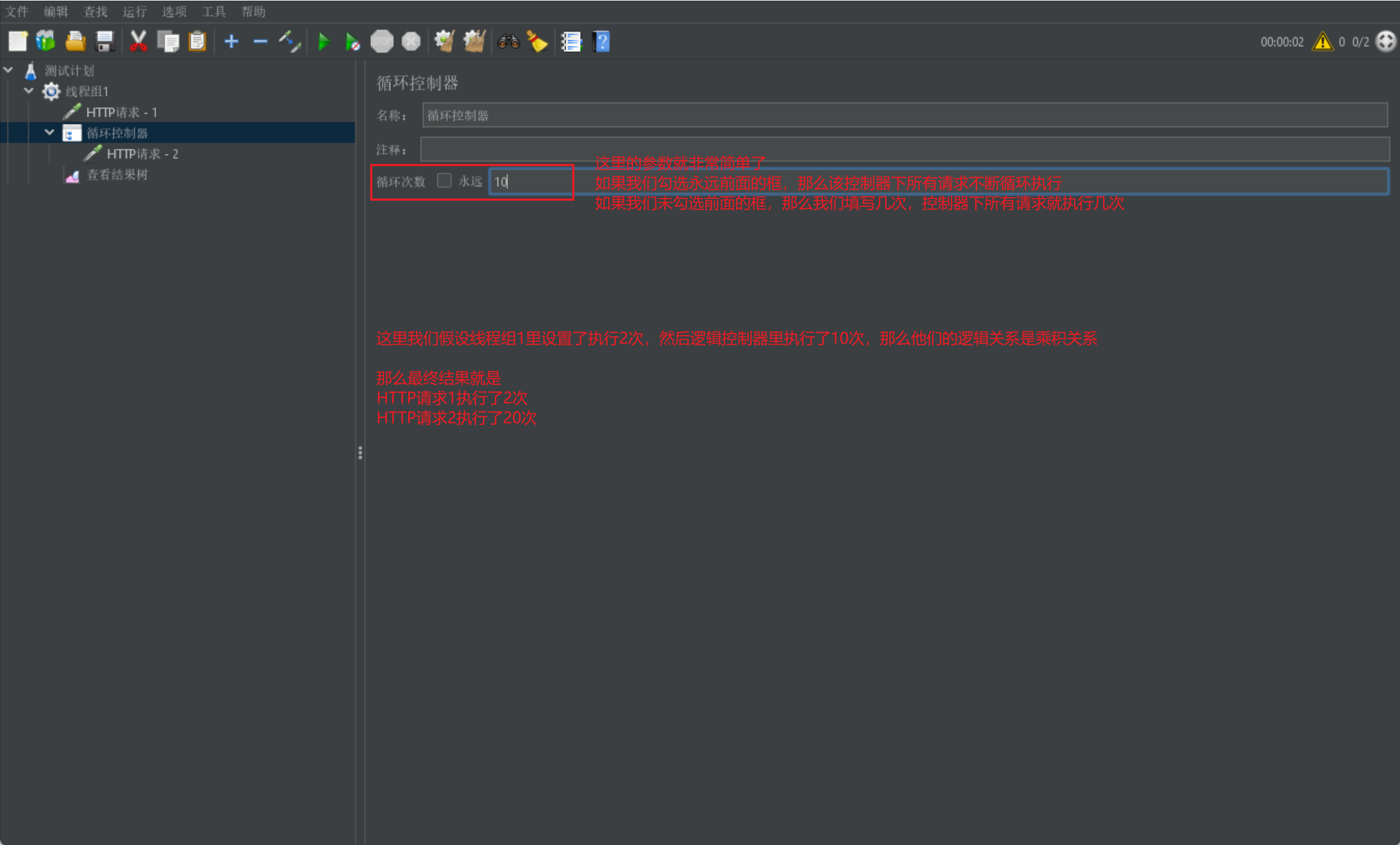
下面我們來介紹while邏輯控制器:
- 當我們需要某些特定語句去進行多次執行時,我們可以採用迴圈邏輯控制器
- 如果我們該執行緒組下所有請求都在while邏輯控制器內,那麼和執行緒組中控制迴圈次數的效果是一樣的,這裡就是為了單個請求做重複操作而設定的
我們直接給出邏輯控制器的展示圖進行引數介紹:
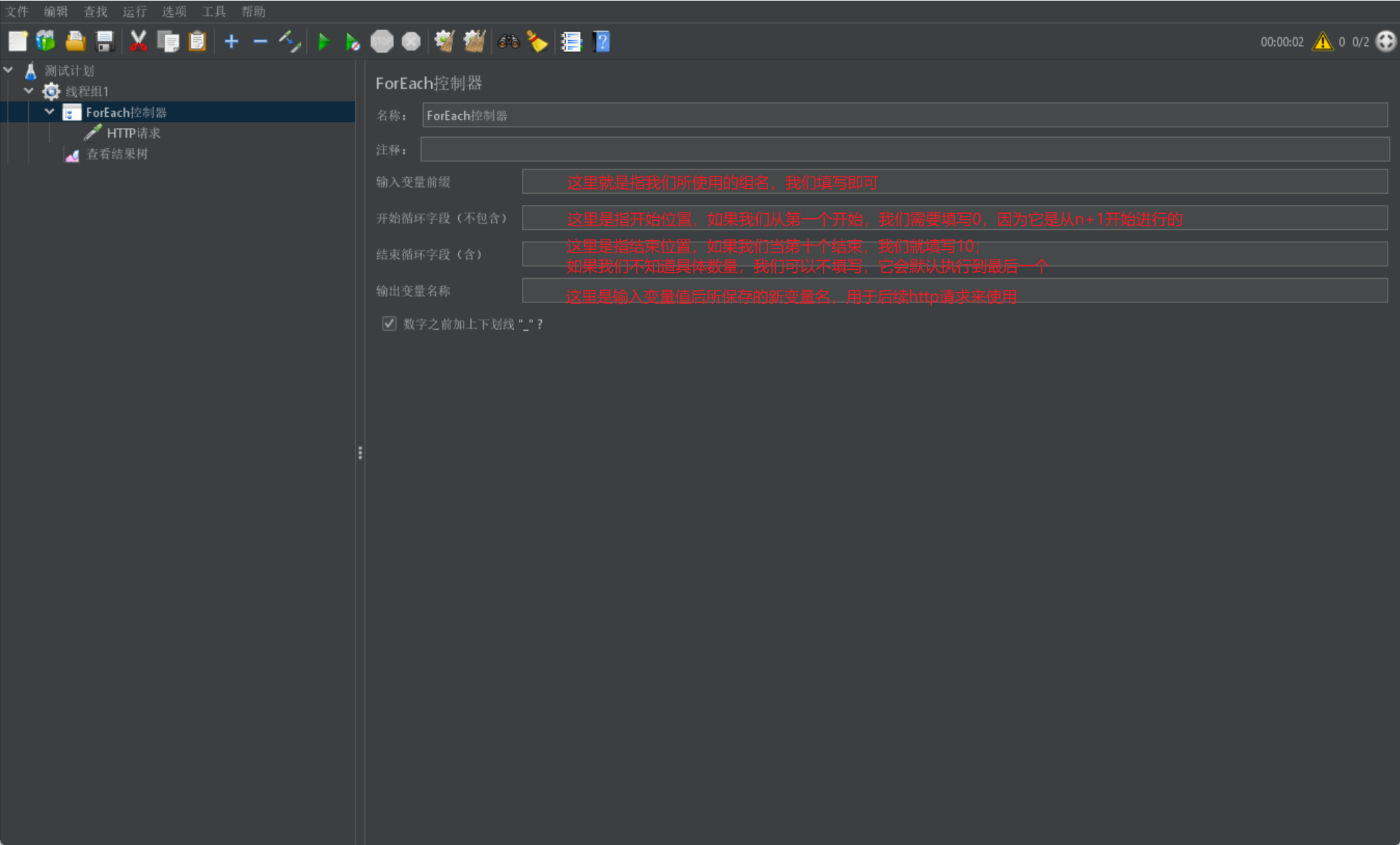
Foreach邏輯控制器
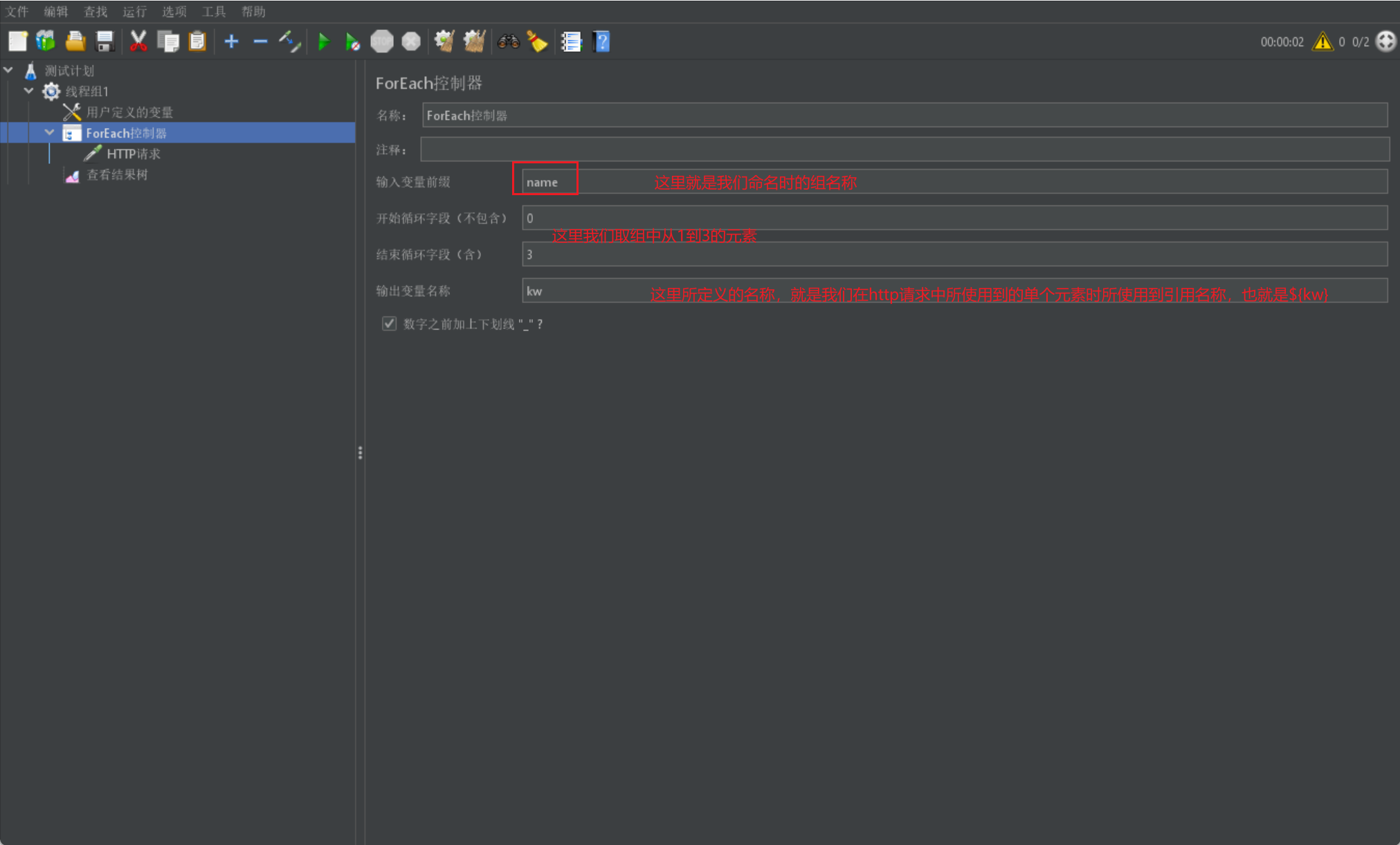
最後我們介紹一個ForEach邏輯控制器,它是用於對組中元素均執行所建立的控制器:
- 一般和使用者自定義變數和正規表示式一同使用,用於使用該組中所有元素去執行請求
我們首先給出Foreach邏輯控制器的展示介面:
我們這裡只介紹foreach如何與使用者自定義變數來結合使用,其實原理都是相同的,針對組我們都可以採用foreach進行遍歷操作:
- 定義使用者自定義變數:
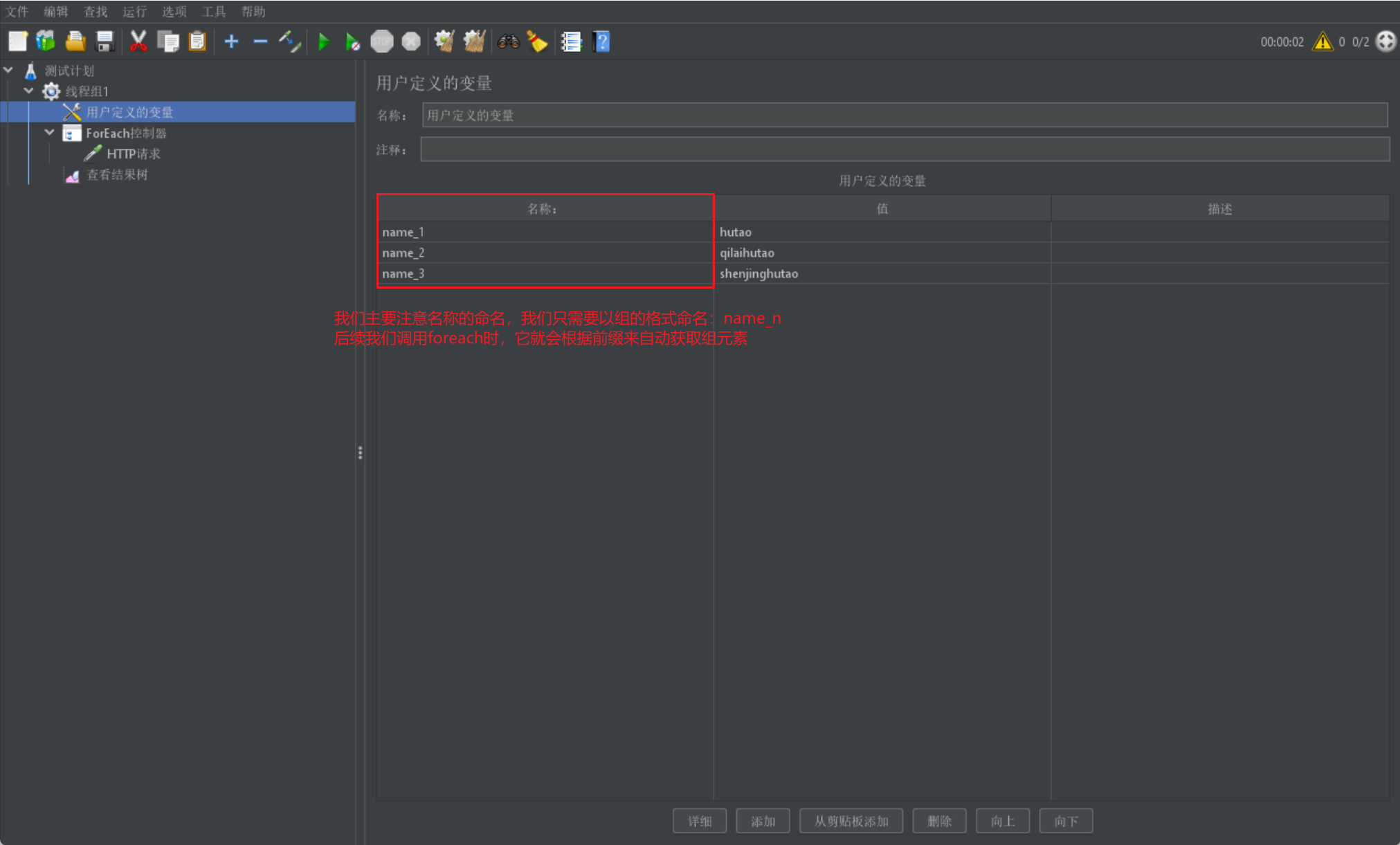
- 書寫foreach控制器:
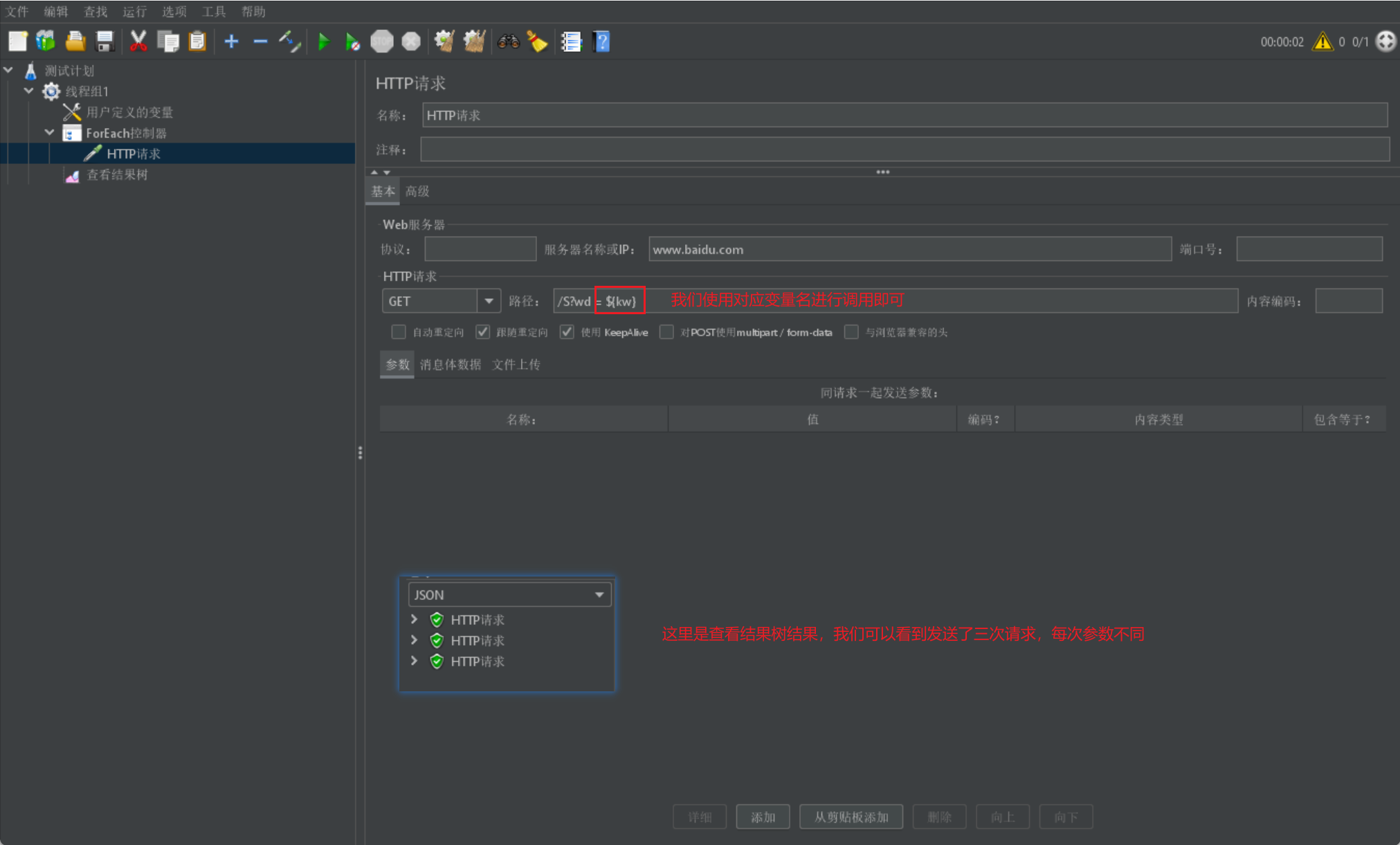
- 最後我們在HTTP請求中呼叫我們的kw即可,我們會在結果樹中檢視到三個結果:
Jmeter定時器介紹
最後我們來介紹Jmeter中最常用的三種定時器:
- 定時器主要是方便我們通過控制dps和time來進行壓力測試或效能測試等
同步定時器
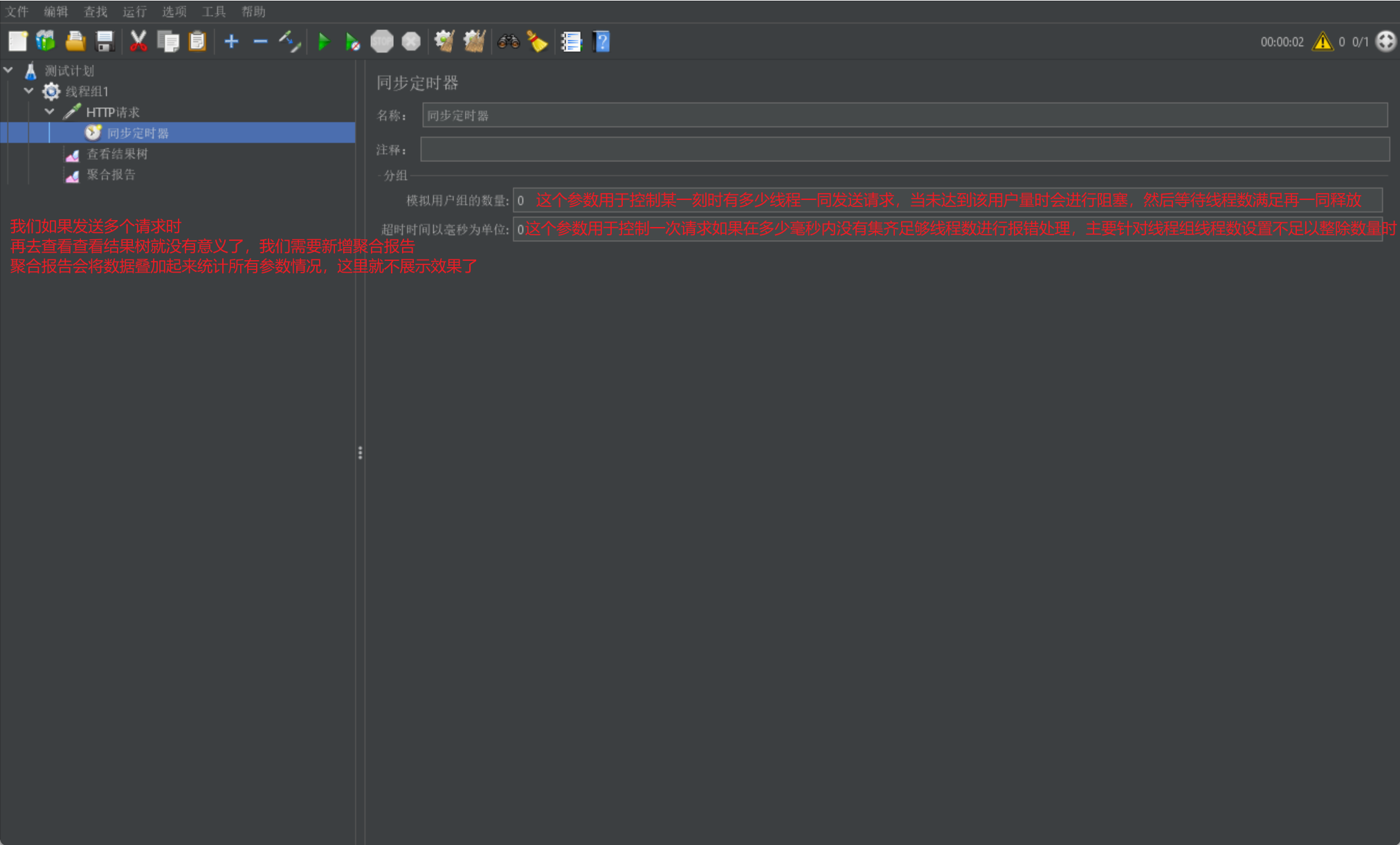
我們首先來介紹同步定時器:
- 阻塞執行緒,當在規定時間內達到一定執行緒數後,將這些執行緒一同釋放,主要用於進行並行壓力測試
我們直接介紹同步定時器的展示介面:
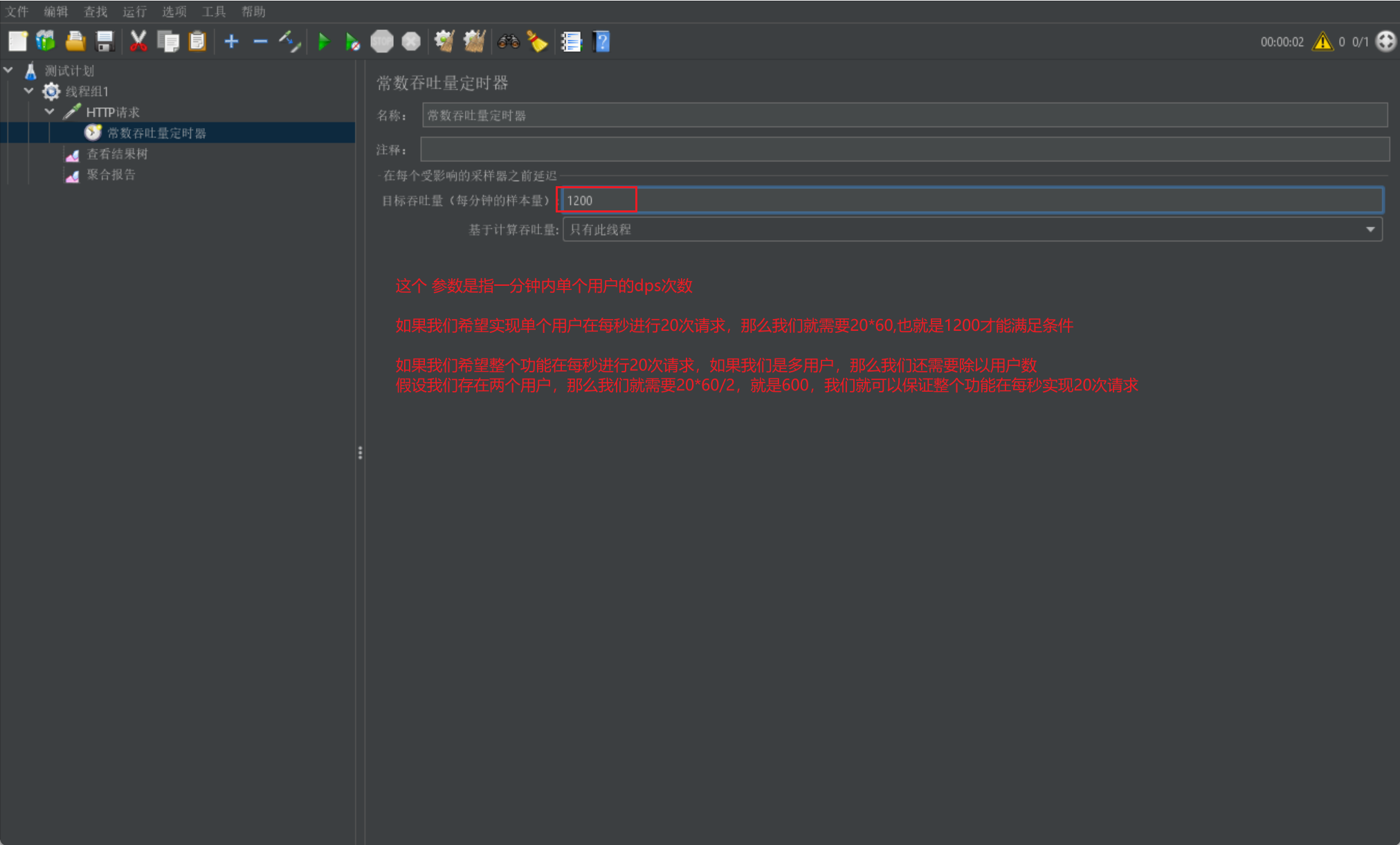
常數吞吐量定時器
下面我們來介紹常數吞吐量定時器:
- 用於控制單個使用者的dps查詢速度,常用於進行穩定測試或長時間壓力測試
我們直接給出常數吞吐量定時器的展示介面:
固定定時器
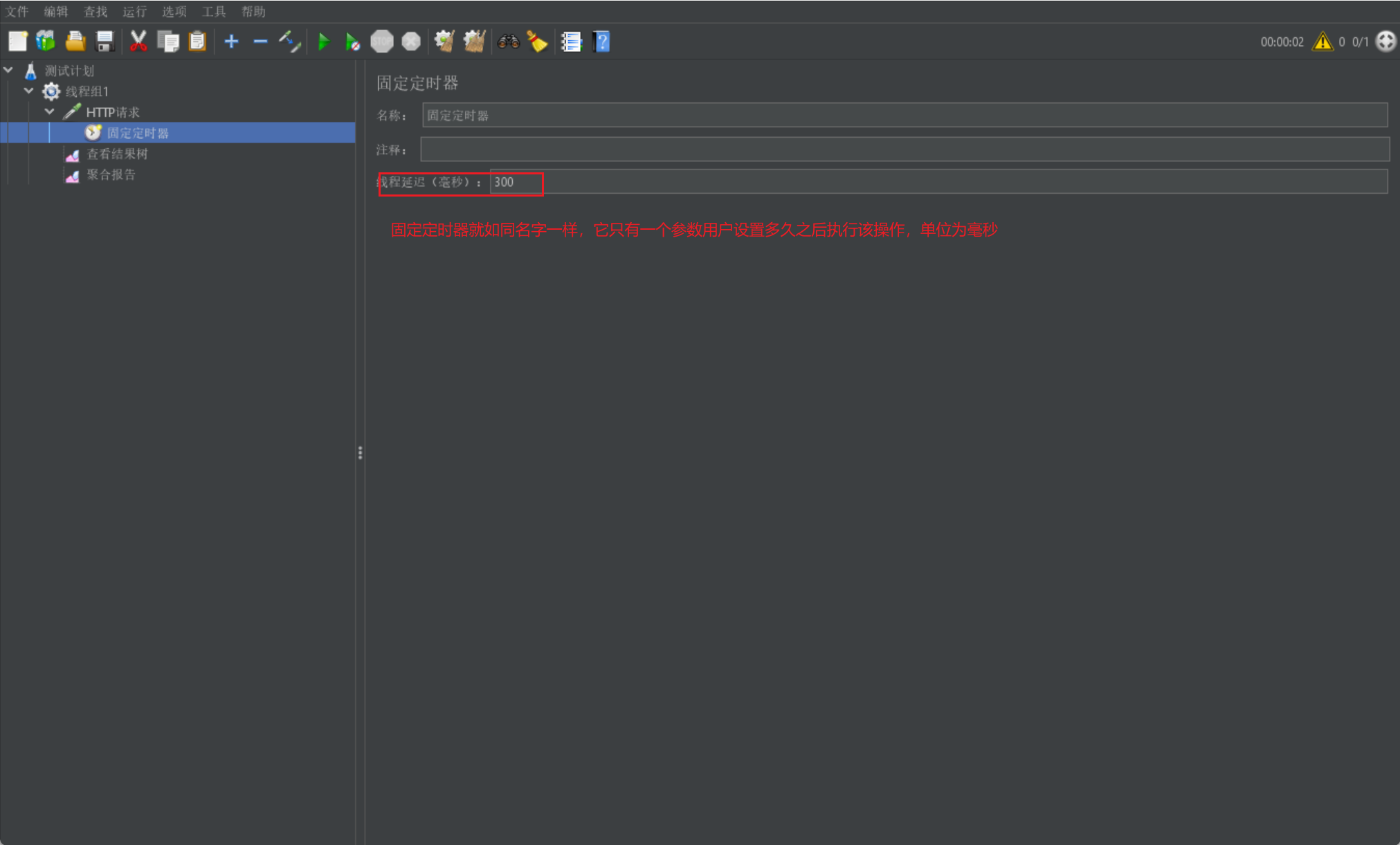
最後我們來介紹固定定時器:
- 用於控制該請求在多久之後進行執行,用於驗證一些時間關係
我們直接給出固定定時器的展示介面:
結束語
這篇文章中詳細介紹了效能測試以及效能測試工具Jmeter的詳情使用,希望能為你帶來幫助
下面給出我學習和書寫該篇文章的一些參考文章,大家也可以去查閱:
- 黑馬課程:01.效能測試_階段總體目標和課程安排_嗶哩嗶哩_bilibili
- CSDN下載攻略:mysql資料庫連結驅動jar包的下載(Jmeter中使用為例)_mysql驅動jar包下載-CSDN部落格