Python爬蟲實戰之招聘網站職位資訊
2020-08-08 13:14:45
目的
完成對目標招聘網站的崗位資訊一級分類,二級分類,三級分類的獲取.
網址
- boss直聘
https://www.zhipin.com/shenzhen/?sid=sem_pz_bdpc_dasou_title
- 58同城
https://sz.58.com/job.shtml?utm_source=market&spm=u-2d2yxv86y3v43nkddh1.BDPCPZ_BT&PGTID=0d100000-0000-46df-ce26-33cb2d595bf2&ClickID=2
- 51job
https://search.51job.com/list/040000,000000,0000,32,9,99,%25E5%2589%258D%25E7%25AB%25AF%25E5%25BC%2580%25E5%258F%2591,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
- 智聯招牌
https://www.zhaopin.com/
具體需求
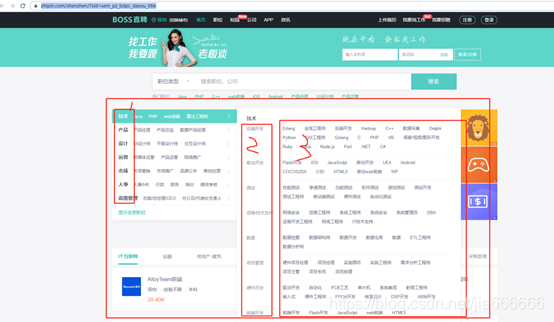
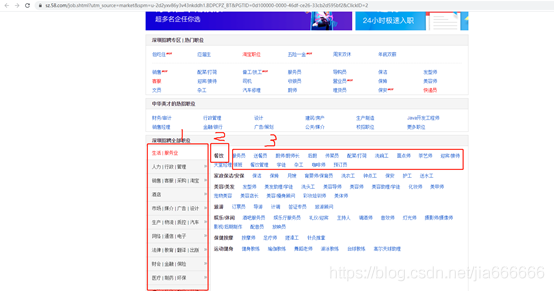
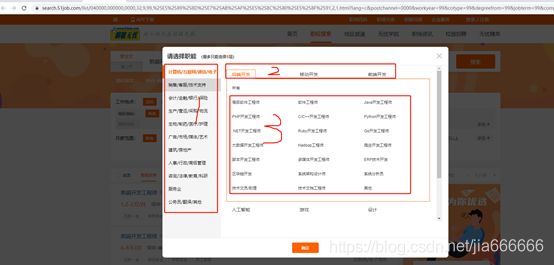
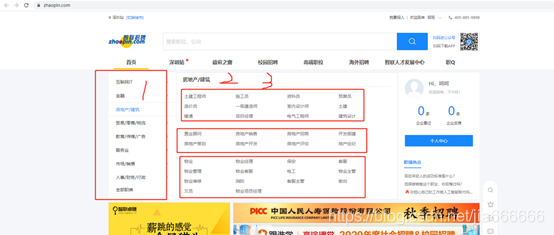
原始檔
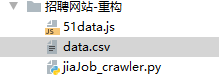
51data.js包含有51所有的崗位資訊
data.csv是爬蟲程式執行建立的檔案,裏面包含所有獲取到的崗位資訊
jiajob是爬蟲程式原始碼
原始碼
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : jia666
# @Time : 2020/8/6 10:43
import re
import requests
import time
from sqlalchemy import create_engine
class BOSS_position(object):
"""完成boss直聘崗位的分類資訊獲取"""
def __init__(self): # 初始化
self.url = 'https://www.zhipin.com/shenzhen/?sid=sem_pz_bdpc_dasou_title'
self.header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
}
self.time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 格式化成2016-03-20 11:45:39形式
def get_boss(self):
"""獲取目標網頁"""
response = requests.get(self.url, self.header)
if response.status_code == 200:
self.html = response.text
else:
print('獲取網頁失敗,請排除錯誤後再次嘗試')
def extract_information(self):
"""完成三級職業分類資訊的獲取與本地儲存"""
SXFW = re.findall('<div class="job-menu">(.*?)<div class="home-main"', self.html, re.S)[0] # 縮小範圍
XDFW = re.findall('<p class="menu-article">(.*?)</dl', SXFW, re.S) # 縮小範圍
with open('data.csv', 'a+', encoding='utf-8') as f: # a+模式開啓檔案
for INF in XDFW:
YJFL = re.findall('.*?(.*?)</p>', INF, re.IGNORECASE)[0] # 匹配一級文字
EJ_content = re.findall('<li>(.*?)</li', INF, re.S) # 縮小範圍至二級內容塊
for EJ in EJ_content:
EJFL = re.findall('<h4>(.*?)<', EJ, re.S)[0] # 匹配二級文字
SJ_content = re.findall(' <a.*>(.*?)</', EJ, re.IGNORECASE) # 獲取二級塊內的三級文字內容
for k in SJ_content:
SJFL = k # 三級文字
word = str(YJFL) + ',' + str(EJFL) + ',' + str(SJFL) + ',' + self.time + ',' + 'boss直聘' + '\n'
f.write(word)
class z58_position(object):
"""完成58同城崗位的分類資訊獲取"""
def __init__(self): # 初始化
self.url = 'https://sz.58.com/job.shtml?utm_source=market&spm=u-2d2yxv86y3v43nkddh1.BDPCPZ_BT&PGTID=0d100000-0000-46df-ce26-33cb2d595bf2&ClickID=2'
self.header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
}
self.time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 格式化成2016-03-20 11:45:39形式
def get_58(self):
"""獲取目標網頁"""
response = requests.get(self.url, self.header)
if response.status_code == 200:
self.html = response.text
else:
print('獲取網頁失敗,請排除錯誤後再次嘗試')
def extract_information(self):
"""完成三級職業分類資訊的獲取與本地儲存"""
SXFW = re.findall('<div class="posCont clearfix" id="posCont">(.*?)</div', self.html, re.S)[0]
YL_content = re.findall('<ul class="sidebar-left fl" id="sidebar-left">(.*?)</ul>', SXFW, re.S)[0]
# print(YL_content)
YJ_list = re.findall('<a.*?>(.*?)</a', YL_content, re.S) # 一級文字列表
with open('data.csv', 'a+', encoding='utf-8') as f: # 開啓檔案
for YJ in YJ_list:
YJFL = YJ
EJ_content = re.findall('<li.*?><strong><a.*?>(.*?)<\/li>', SXFW, re.S)
for EJ in EJ_content:
EJFL = re.findall('(.*?)</a></strong>', EJ, re.S)[0] # 二級文字
SJ_list = re.findall('<a.*?>(.*?)<\/a', EJ, re.S)
for SJ in SJ_list:
SJFL = SJ
word = str(YJFL) + ',' + str(EJFL) + ',' + str(SJFL) + ',' + self.time + ',' + '58同城' + '\n'
f.write(word)
class ZHILIAN_position(object):
"""完成智聯崗位的分類資訊獲取"""
def __init__(self): # 初始化
self.url = 'https://www.zhaopin.com/'
self.header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
}
self.time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 格式化成2016-03-20 11:45:39形式
def get_zhilian(self):
"""獲取目標網頁"""
response = requests.get(self.url, self.header)
if response.status_code == 200:
self.html = response.text
else:
print('獲取網頁失敗,請排除錯誤後再次嘗試')
def extract_information(self):
"""完成三級職業分類資訊的獲取與本地儲存"""
SXFW = re.findall('<div class="zp-jobNavigater__pop--container">(.*?)<\/li>', self.html, re.S) # 縮小範圍
with open('data.csv', 'a+', encoding='utf-8') as f:
for YJ in SXFW:
# 一級文字
YJFL = re.findall('<div class="zp-jobNavigater__pop--title">(.*?)<\/div> ', YJ, re.S)
EJ_content = re.findall('<div class="zp-jobNavigater__pop--list">(.*?)<\/div>', YJ, re.S)
for i, EJ in enumerate(EJ_content):
EJFL = '分割區' + str(i + 1)
SJ_Content = re.findall('<a.*?>(.*?)</a>', EJ, re.S)
for SJ in SJ_Content:
SJFL = SJ
word = str(YJFL) + ',' + str(EJFL) + ',' + str(SJFL) + ',' + self.time + ',' + '智聯招聘' + '\n'
f.write(word)
class Job_position(object):
"""完成對51job崗位資訊的分類獲取"""
def __init__(self): # 讀取本地數據源
with open('51data.js', 'r', encoding='utf-8') as f:
self.html = f.read()
self.time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 格式化成2016-03-20 11:45:39形式
def parse_information(self):
"""本地檔案數據提取"""
"""獲取一級分類,寫入一級列表"""
image_pattern = re.compile('c: "(.*?)"', re.S) # 正則一級分類
YJFL = re.findall(image_pattern, self.html)[:11] # 對獲取的一級分類切片取前11個一級
self.YJFL_LIST = [] # 一級分類列表
for i in YJFL:
self.YJFL_LIST.append(i)
"""獲取二級鍵值key"""
image_pattern = re.compile('category: \[(.*?)\]', re.S)
result = re.findall(image_pattern, self.html)[:11]
self.EJFL_LIST = []
for index in result:
k = str(index).replace('"', '').split(',') # 獲取當前二級分類index
self.EJFL_LIST.append(k)
"""正則獲取所有的鍵值對錶"""
image_pattern = re.compile('window.ft = {(.*?)}', re.S)
SJFL = re.search(image_pattern, self.html).groups()[0].replace('\n', '').replace('"', '').replace(' ',
'').split(',')
self.FL_DICT = {} # 字典
for i in SJFL:
index, name = i.split(':') # 8016: "網站運營專員" 分割爲序號,值
index = str(index).replace('e3', '000') # 提換8e3型別爲8000
B = int(int(index) / 100) # 取整數值,用於字典key值
if int(index) % 100 == 0:
sjfl = [name] # 二級分類文字
elif int(index) % 100 != 0:
sjfl.append(name) # 三級分類文字
self.FL_DICT[B] = sjfl # 更新字典
def save_data(self):
"""格式整理與本地檔案寫入"""
with open('data.csv', 'a+', encoding='utf-8') as f:
for i, j in enumerate(self.YJFL_LIST):
yjfl = j # 一級文字
for index in self.EJFL_LIST[i]:
index = (index.split('\n'))
for key in index:
sjfl_list = self.FL_DICT[int(int(key) / 100)]
erjifenlei = sjfl_list[0] # 二級文字
for i in sjfl_list[1:]:
word = str(yjfl) + ',' + str(erjifenlei) + ',' + str(i) + ',' + self.time + ',' + '51job' + '\n'
f.write(word)
class IMPORT_MYSQL(object):
"""
實現mysql的本地連線,建立表,將本地數據匯入表
"""
def __init__(self):
"""初始化連線數據庫"""
USERNAME = 'root' # 數據庫使用者名稱稱
PASSWORD = '123456' # 數據庫使用者密碼
MYSQL_IP = '127.0.0.1' # 數據庫IP
MYSQL_PORT = '3306' # 數據庫埠
DB_NAME = 'test' # 數據庫名稱
self.ENGINE_STR = "mysql+pymysql://%s:%s@%s:%s/%s?charset=utf8" % (
USERNAME, PASSWORD, MYSQL_IP, MYSQL_PORT, DB_NAME)
self.engine = create_engine(self.ENGINE_STR) # MySQL範例e
def CREATE_TABLE(self):
sql = """
CREATE TABLE if not exists `NewTable` (
`YJFL` varchar(255) CHARACTER SET utf8mb4 NULL COMMENT '一級分類' ,
`EJFL` varchar(255) CHARACTER SET utf8mb4 NULL COMMENT '二級分類' ,
`SJFL` varchar(255) CHARACTER SET utf8mb4 NULL COMMENT '三級分類' ,
`time` datetime NULL COMMENT '時間' ,
`source` varchar(255) CHARACTER SET utf8mb4 NULL COMMENT '數據來源'
)
;
"""
self.engine.execute(sql) # 執行SQL語句,建立表
def IMPORT_DATA(self):
with open('data.csv', 'r', encoding='UTF-8', )as f:
line = f.readlines() # 讀取一行檔案,包括換行符
for i in line:
k = i.split(',')
try:
InsertSql = '''insert into NewTable values("{0}","{1}","{2}","{3}","{4}");'''.format(k[0], k[1],
k[2], k[3],
k[4])
self.engine.execute(InsertSql)
except Exception as e:
print(e)
if __name__ == '__main__':
print('正在獲取BOSS直聘資訊')
boss = BOSS_position()
boss.get_boss()
boss.extract_information()
print('BOSS直聘資訊解析完成')
print('正在獲取58同城資訊')
z58 = z58_position()
z58.get_58()
z58.extract_information()
print('58同城資訊解析完成')
print('正在獲取智聯招聘資訊')
zhilian = ZHILIAN_position()
zhilian.get_zhilian()
zhilian.extract_information()
print('智聯招聘資訊解析完成')
print('正在獲取前程無憂資訊')
qian= Job_position()
qian.parse_information()
qian.save_data()
print('前程無憂資訊解析完成')
print('正在執行數據匯入操作')
EXAMPLE = IMPORT_MYSQL() # 範例化
EXAMPLE.CREATE_TABLE() # 建表函數呼叫
EXAMPLE.IMPORT_DATA() # 本地數據匯入呼叫
print('數據匯入完成')
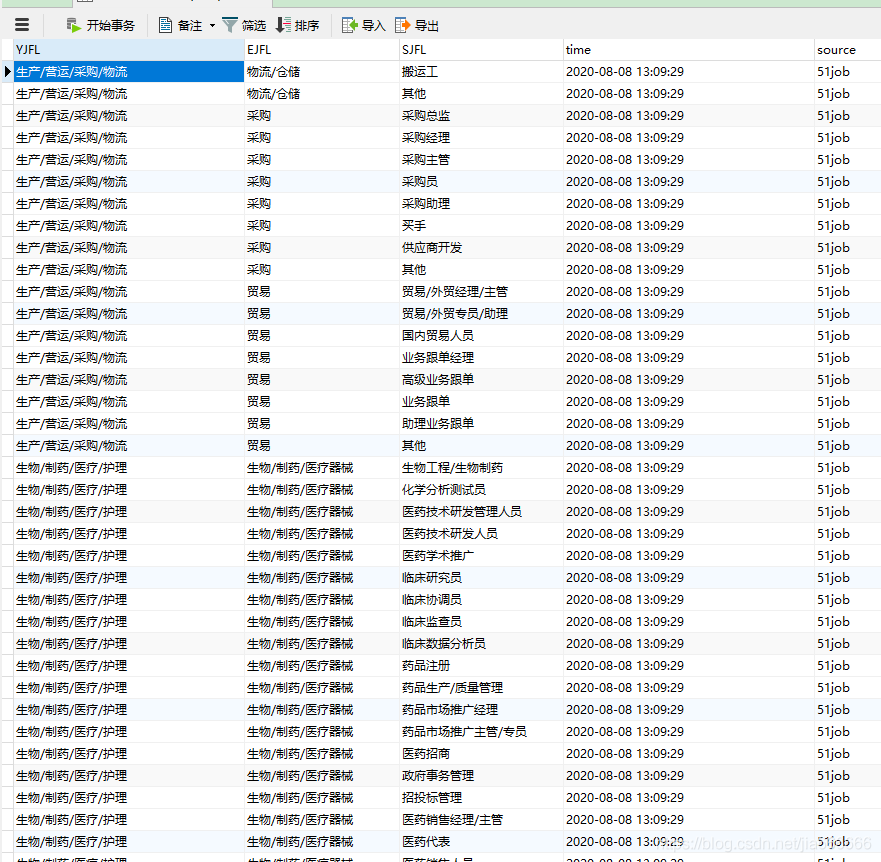
結果
data.csv

mysql