python爬蟲-網頁解析-xpath/lxml實戰
2020-08-08 14:14:53
python爬蟲-網頁解析-xpath/lxml實戰
通過requests請求,返回的數據還是比較粗糙的,我們需要從中找到我們需要儲存的資訊,這需要對網頁內容進行解析。解析方式有正則表達式、xpath、beautiful soup等,這裏介紹xpath。
xpath介紹
xpath是一種在xml文件中定位元素的工具,使用xpath對html程式碼解析前先用lxml庫將html轉爲xml。
xml與html的比較
| 格式 | 全稱 | 描述 |
|---|---|---|
| XML | Extensible Markup Language (可延伸標示語言) | 傳輸和儲存數據,其焦點是數據內容 |
| HTML | HyperText Markup Language (超文件標示語言) | 顯示數據,其焦點是數據顯示 |
| HTML DOM | Document Object Model for HTML (文件物件模型) | 定義了存取和操作HTML文件的標準方法,將文件表達爲一個樹狀結構物件,可以對其中的元素和內容進行增刪改查 |
節點選取
使用路徑表達式來選取XML文件中的節點或者節點集。
支援選取屬性,在文件樹中遍歷等豐富的功能,具體用法參見Python爬蟲之Xpath語法
實戰
爬取廣東教育系統零散採購競價結果
網址:http://gdedulscg.cn/home/bill/billresult?page=1
先給出原始碼再對其進行解釋
UserAgent
瀏覽器身份僞裝,也可以通過faker_useragent或faker庫生成
user_agents.py:
agents = ['Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1',
'MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1',
'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10',
'Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13',
'Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+',
'Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0',
'Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)',
'UCWEB7.0.2.37/28/999',
'NOKIA5700/ UCWEB7.0.2.37/28/999',
'Openwave/ UCWEB7.0.2.37/28/999',
'Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; InfoPath.2; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; 360SE)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Linux; U; Android 2.2.1; zh-cn; HTC_Wildfire_A3333 Build/FRG83D) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; TencentTraveler 4.0; .NET CLR 2.0.50727)',
'MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Androdi; Linux armv7l; rv:5.0) Gecko/ Firefox/5.0 fennec/5.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Android 2.3.4; Linux; Opera mobi/adr-1107051709; U; zh-cn) Presto/2.8.149 Version/11.10',
'UCWEB7.0.2.37/28/999',
'NOKIA5700/ UCWEB7.0.2.37/28/999',
'Openwave/ UCWEB7.0.2.37/28/999',
'Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999', ]
代理
如果執行程式碼沒有反應,很可能是代理已經失效。
代理失效很快,爲了提高通用性,可以維護一個代理池(後面再寫一篇)。暫時的解決方案可以百度一下免費代理把它替換。
proxy.py:
proxies = {
"https": [
"60.179.201.207:3000",
"60.179.200.202:3000",
"60.184.110.80:3000",
"60.184.205.85:3000",
"60.188.16.15:3000",
"60.188.66.158:3000",
"58.253.155.11:9999",
"60.188.9.91:3000",
"60.188.19.174:3000",
"60.188.11.226:3000",
"60.188.17.23:3000",
"61.140.28.228:4216",
"60.188.1.27:3000"
]
}
執行入口
crawler.py:
import re
import time
import random
import threading
import requests
import pandas as pd
from lxml import etree # 將html轉爲文件樹物件的庫
from proxy import proxies
from user_agents import agents
class GDEduCrawler:
def __init__(self):
self.page = 1 # 起始頁碼
self.page_url = "http://www.gdedulscg.cn/home/bill/billresult?page={}" # 頁碼
self.detail_url = "http://gdedulscg.cn/home/bill/billdetails/billGuid/{}.html" # 填入see_info的值
self.detail_patt = re.compile(r"see_info\((\d+)\)")
self.columns = ["採購單位", "專案名稱", "聯繫人", "聯繫電話", "成交單位"] # 定義好儲存結構
self.result_df = pd.DataFrame(columns=self.columns) # 用dataframe儲存結果,方便轉爲excel
self.lock = threading.Lock() # 儲存檔案時加鎖,保證一次只能一個執行緒寫檔案
def crawl(self):
while 1:
try:
self.get_page()
self.page += 1
time.sleep(random.random())
# 頁面中沒有「下一頁」時,退出
if self.page > 1829:
break
if self.page >= 100 and self.page % 100 == 0: # 每100頁儲存一次,防止程式碼中斷需要從頭爬取(也可以儲存已爬取url,待爬取url,實現斷點續爬,好像scrapy-redis就是這麼幹的)
self.result_df.to_excel("./results/競價結果(前{}頁).xlsx".format(self.page))
print("page {} saved.".format(self.page))
except Exception as e:
print(e)
self.result_df.to_excel("./results/競價結果.xlsx")
def send_request(self, url, referer):
user_agent = random.choice(agents)
# method = random.choice(["http", "https"])
method = random.choice(["https"])
proxy_url = random.choice(proxies[method])
proxy = {method: proxy_url}
headers = {
"User-Agent": user_agent,
"Referer": referer
}
try:
response = requests.get(url, headers=headers, proxies=proxy)
except Exception as e:
print(e)
return ""
# print(response.text)
print(response.url)
# print(response.encoding)
print(response.status_code)
# print(response.content)
# print("=" * 80)
return response.text
def get_page(self): # 分頁發送請求,獲取詳情頁url列表
url = self.page_url.format(self.page)
referer = self.page_url.format(self.page - 1)
content = self.send_request(url=url, referer=referer)
self.parse_page(content)
def get_detail(self, detail_id): # 頁內詳情解析
url = self.detail_url.format(detail_id)
referer = self.page_url
content = self.send_request(url=url, referer=referer)
self.parse_detail(content)
def parse_page(self, content):
"""
:param content: response.content,是html
:return:
"""
html = etree.HTML(content)
html_data = html.xpath('//*/div[@class="list_title_num_data fl"]/@onclick')
html_ids = set()
for h in html_data:
html_ids.add(self.detail_patt.match(h).group(1))
# print(html_ids)
# html_ids = set(self.detail_patt.findall(content))
for detail_id in html_ids:
t = threading.Thread(target=self.get_detail, args=(detail_id,))
t.start()
def parse_detail(self, content):
"""
:param content: response.content,是html
:return:
"""
# xpath: //*/div[@class="bill_info_l2"]/text()
html = etree.HTML(content)
html_data = html.xpath('//*/div[@class="bill_info_l2"]')
# print(html_data)
data = {}
for key_value in html_data:
key_value = key_value.text
if not key_value:
continue
con = key_value.split(":")
key = con[0].strip()
if len(con) < 2 or key not in self.columns:
continue
value = con[1].strip()
data[key] = value
project_name = html.xpath('//*/div[@class="bill_info_l2"]/div/text()')[1]
data["專案名稱"] = project_name
self.save_information(**data)
def save_information(self, **kwargs):
"""
儲存到xls
:return:
"""
self.lock.acquire()
self.result_df = self.result_df.append(kwargs, ignore_index=True)
self.lock.release()
if __name__ == '__main__':
crawler = GDEduCrawler()
crawler.crawl()
程式碼邏輯
爬取時共1829頁,
- get_page()分頁爬取,呼叫parse_page()獲取每頁的詳情鏈接列表
- get_detail()對詳情鏈接列表再次請求,並帶上get_page的鏈接作爲referer
- parse_deatil將get_detail()返回的詳情頁面進行解析,獲取需要的資訊並儲存到dataframe中
- 最後由pandas將dataframe儲存爲excel檔案
- get_page()和get_detail()請求數據時都是get方法,請求發送統一呼叫send_request,send_request帶上referer,隨機選取user agent和代理地址
用到的xpath表達式及其來源
用到的三個表達式分別在parse_page和parse_detail中:
def parse_page(self, content):
"""
:param content: response.content,是html
:return:
"""
html = etree.HTML(content)
html_data = html.xpath('//*/div[@class="list_title_num_data fl"]/@onclick')
html_ids = set()
for h in html_data:
html_ids.add(self.detail_patt.match(h).group(1))
# html_ids = set(self.detail_patt.findall(content)) # 也可以直接用re搜尋
for detail_id in html_ids:
t = threading.Thread(target=self.get_detail, args=(detail_id,))
t.start()
def parse_detail(self, content):
"""
:param content: response.content,是html
:return:
"""
# xpath: //*/div[@class="bill_info_l2"]/text()
html = etree.HTML(content)
html_data = html.xpath('//*/div[@class="bill_info_l2"]')
# print(html_data)
data = {}
for key_value in html_data:
key_value = key_value.text
if not key_value:
continue
con = key_value.split(":")
key = con[0].strip()
if len(con) < 2 or key not in self.columns:
continue
value = con[1].strip()
data[key] = value
project_name = html.xpath('//*/div[@class="bill_info_l2"]/div/text()')[1]
data["專案名稱"] = project_name
self.save_information(**data)
- parse_page
html.xpath(’//*/div[@class=「list_title_num_data fl」]/@onclick’)
從列表頁獲取詳情地址時,是通過onclick傳遞參數到js程式碼的,獲取詳情地址,
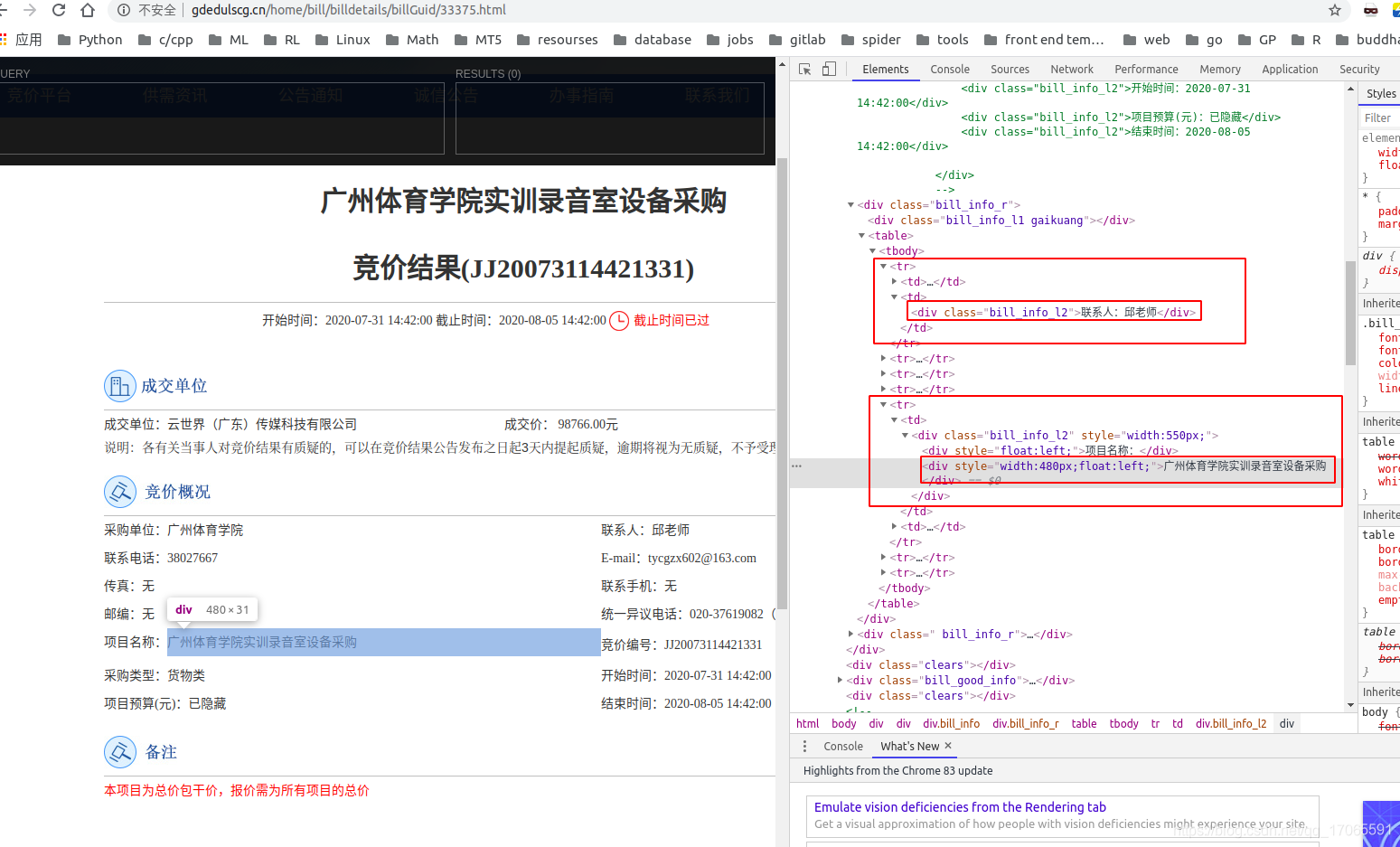
可以先用chrome的xpathhelper外掛(參考https://www.cnblogs.com/MyFlora/archive/2013/07/26/3216448.html)在頁面上直觀的獲取:
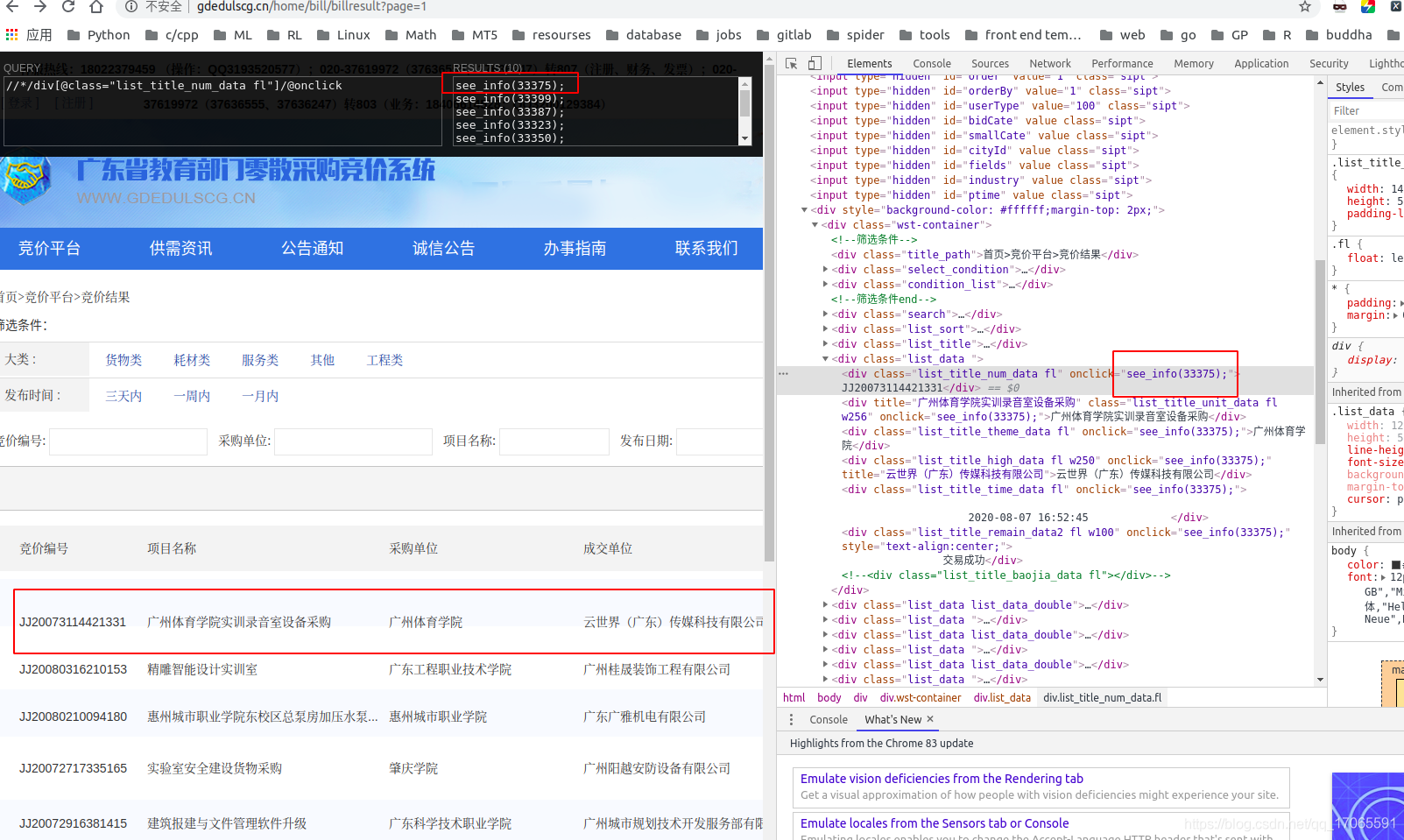
詳情頁面的地址就是see_info()裡的值
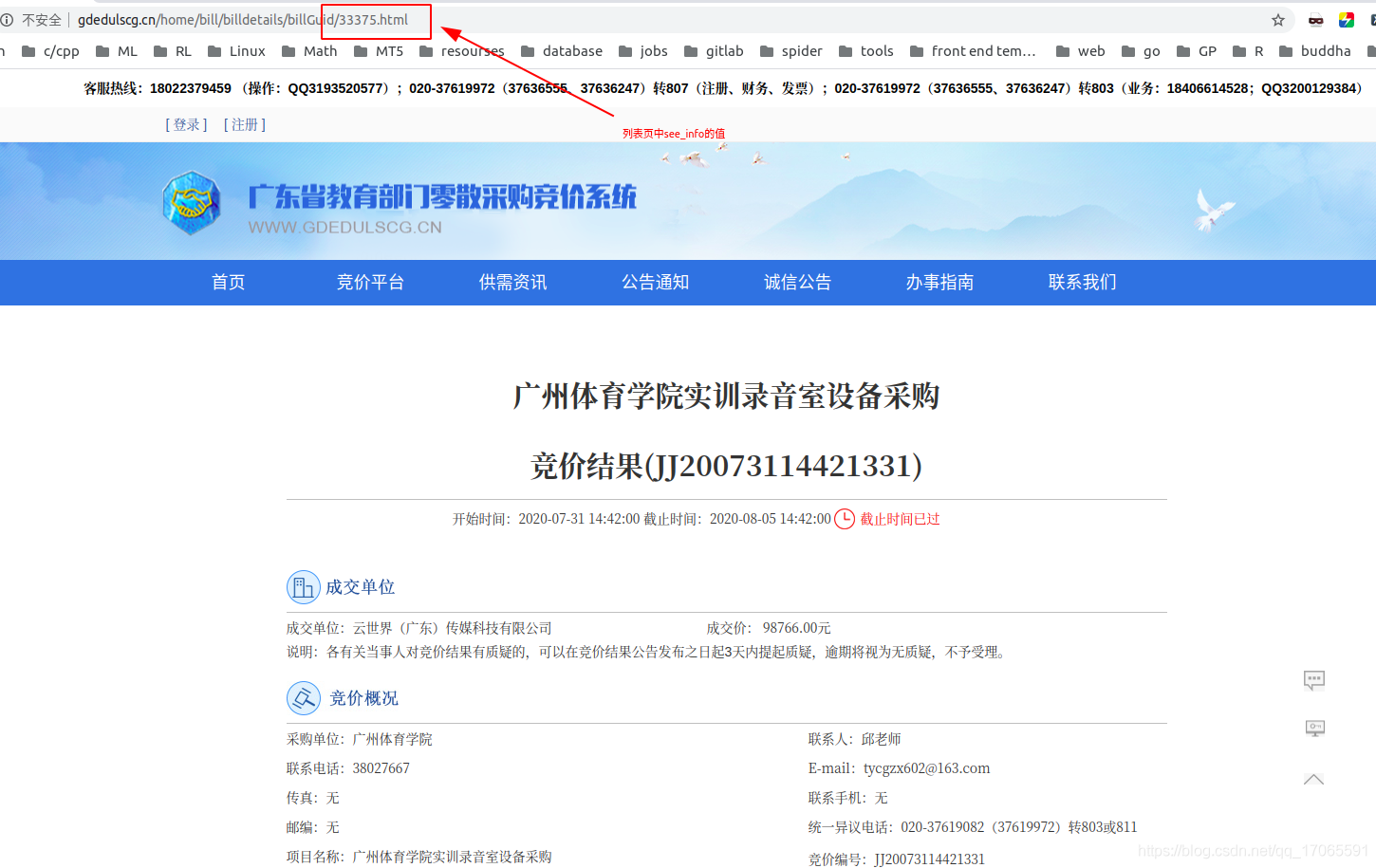
- parse_deatil
- html.xpath(’//*/div[@class=「bill_info_l2」]’)
除「專案名稱」外,其他四個資訊可以統一由這個表達式拿到
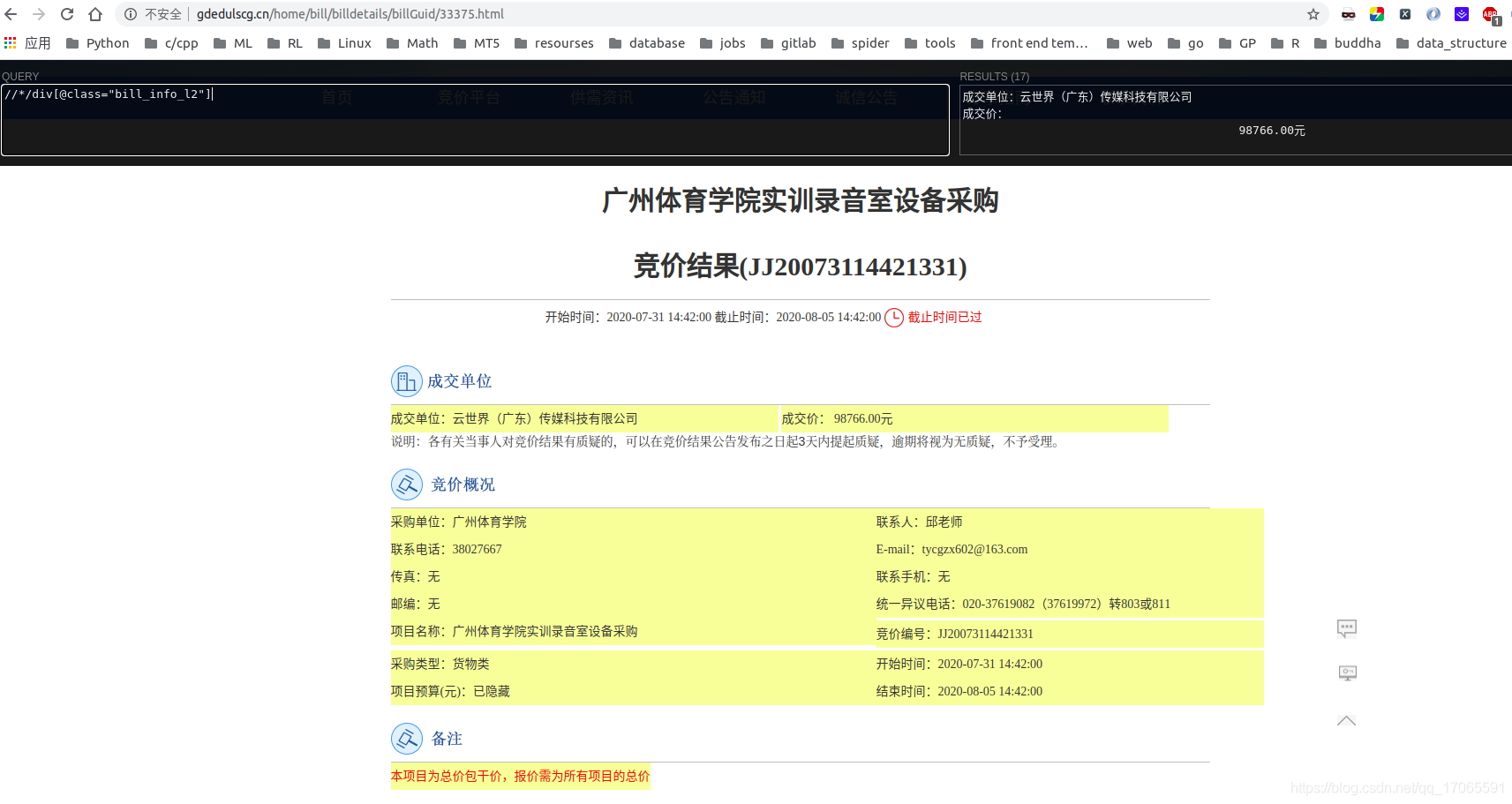
- html.xpath(’///div[@class=「bill_info_l2」]/div/text()’)[1]
"專案名稱」通過上面的表達式是拿不到的,因爲它的結構不一樣,「專案名稱」和「廣州體育學院實訓錄音室裝置採購」分別在兩個div,而其他四個資訊都全在同一個div中
html.xpath(’///div[@class=「bill_info_l2」]/div/text()’)返回的是列表:[「專案名稱:」,「廣州體育學院實訓錄音室裝置採購」],取1即可