Linux效能優化實戰學習筆記-Linux記憶體是怎麼工作的
目錄
記憶體管理也是操作系統最核心的功能之一。記憶體主要用來儲存系統和應用程式的指令、數據、快取等
記憶體對映
我們通常所說的記憶體容量指的是實體記憶體。實體記憶體也稱爲主記憶體,大多數計算機用的主記憶體都是動態隨機存取記憶體(DRAM)。只有內核纔可以直接存取實體記憶體。
進程如何存取記憶體?
Linux 內核給每個進程都提供了一個獨立的虛擬地址空間,並且這個地址空間是連續的。進程存取記憶體其實存取的虛擬記憶體。
虛擬地址空間的內部又被分爲內核空間和使用者空間
不同字長(也就是單個CPU指令可以處理數據的最大長度)的處理器,地址空間的範圍也不同。比如最常見的 32 位和 64 位系統

- 32位元系統的內核空間佔用 1G,位於最高處,剩下的3G是使用者空間。
- 64位元系統的內核空間和使用者空間都是 128T,分別佔據整個記憶體空間的最高和最低處,剩下的中間部分是未定義的
進程的使用者態和內核態
進程在使用者態時,只能存取使用者空間記憶體;只有進入內核態後,纔可以存取內核空間記憶體
雖然每個進程的地址空間都包含了內核空間,但這些內核空間,其實關聯的都是相同的實體記憶體。這樣,進程切換到內核態後,就可以很方便地存取內核空間記憶體。
每個進程都有一個這麼大的地址空間,那麼所有進程的虛擬記憶體加起來,自然要比實際的實體記憶體大得多。所以,並不是所有的虛擬記憶體都會分配實體記憶體,只有那些實際使用的虛擬記憶體才分配實體記憶體,並且分配後的實體記憶體,是通過記憶體對映來管理的。
什麼是記憶體對映?
其實就是將虛擬記憶體地址對映到實體記憶體地址。爲了完成記憶體對映,內核爲每個進程都維護了一張頁表,記錄虛擬地址與實體地址的對映關係。
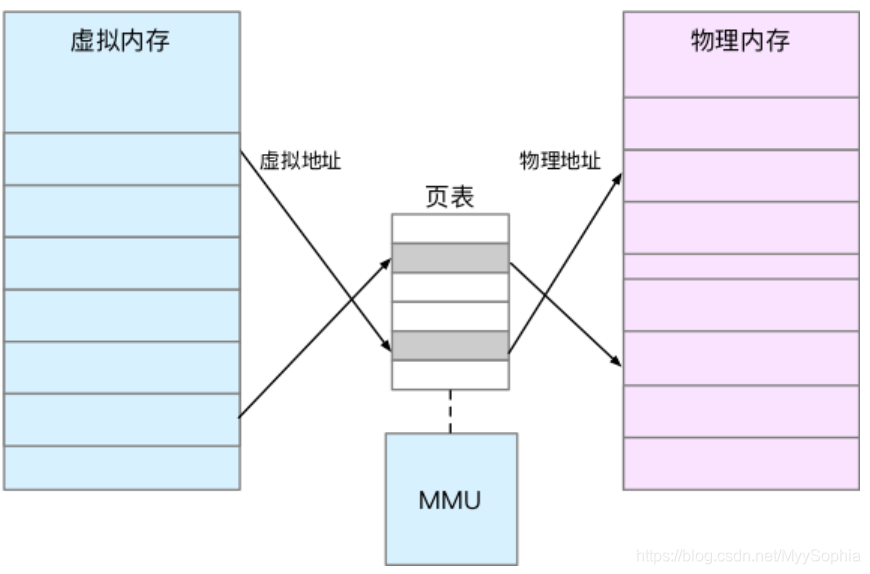
頁表實際上儲存在 CPU 的記憶體管理單元 MMU中,這樣,正常情況下,處理器就可以直接通過硬體,找出要存取的記憶體。
什麼是缺頁異常
當進程存取的虛擬地址在頁表中查不到時,系統會產生一個缺頁異常,進入內核空間分配實體記憶體、更新進程頁表,最後再返回使用者空間,恢復進程的執行。
TLB(Translation Lookaside Buffer,轉譯後備緩衝器)會影響 CPU 的記憶體存取效能,TLB 其實就是 MMU 中頁表的快取記憶體。由於進程的虛擬地址空間是獨立的,而 TLB 的存取速度又比 MMU 快得多,所以,通過減少進程的上下文切換,減少TLB的重新整理次數,就可以提高TLB 快取的使用率,進而提高CPU的記憶體存取效能。
MMU全稱就是記憶體管理單元,管理地址對映關係(也就是頁表)。但MMU的效能跟CPU比還是不夠快,所以又有了TLB。TLB實際上是MMU的一部分,把頁表快取起來以提升效能。
MMU 如何管理記憶體
MMU 並不以位元組爲單位來管理記憶體,而是規定了一個記憶體對映的最小單位,也就是頁,通常是 4 KB大小。這樣,每一次記憶體對映,都需要關聯 4 KB 或者 4KB 整數倍的記憶體空間。
多級頁表和大頁
頁的大小隻有4 KB ,導致的另一個問題就是,整個頁表會變得非常大。比方說,僅 32 位系統就需要 100 多萬個頁表項(4GB/4KB),纔可以實現整個地址空間的對映。爲了解決頁表項過多的問題,Linux 提供了兩種機制 機製,也就是多級頁表和大頁(HugePage)
- 多級頁表
把記憶體分成區塊來管理,將原來的對映關係改成區塊索引和區塊內的偏移。由於虛擬記憶體空間通常只用了很少一部分,那麼,多級頁表就只儲存這些使用中的區塊,這樣就可以大大地減少頁表的項數。
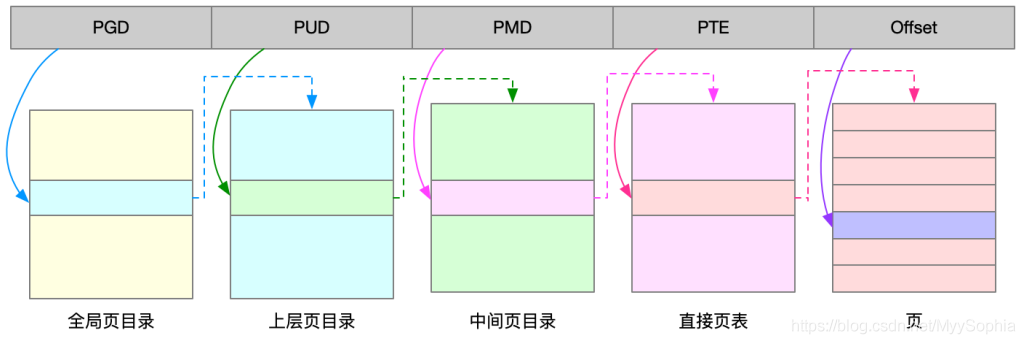
Linux 用的正是四級頁表來管理記憶體頁,如下圖所示,虛擬地址被分爲5個部分,前4個表項用於選擇頁,而最後一個索引表示頁內偏移。
- 大頁
比普通頁更大的記憶體塊,常見的大小有 2MB 和 1GB。大頁通常用在使用大量記憶體的進程上,比如 Oracle、DPDK 等。GP是否可以也使用大頁呢?
虛擬記憶體空間分佈
在頁表的對映下,進程就可以通過虛擬地址來存取實體記憶體了。那麼具體到一個Linux 進程中,這些記憶體又是怎麼使用的呢?
3.1 虛擬記憶體空間的分佈情況
以32位元系統爲例
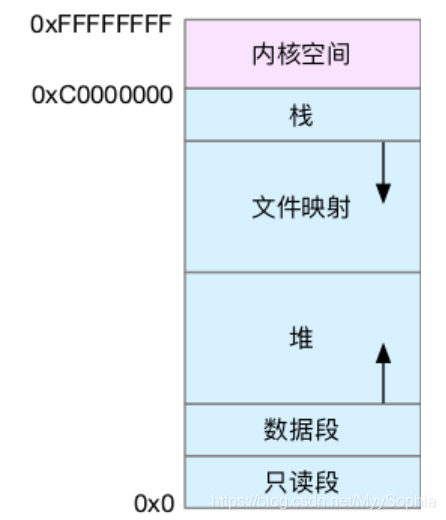
1. 只讀段,包括程式碼和常數等。
2. 數據段,包括全域性變數等。
3. 堆,包括動態分配的記憶體,從低地址開始向上增長。
4. 檔案對映段,包括動態庫、共用記憶體等,從高地址開始向下增長。
5. 棧,包括區域性變數和函數呼叫的上下文等。棧的大小是固定的,一般是 8 MB。
堆和檔案對映段的記憶體是動態分配的。比如說,使用 C 標準庫的 malloc()或者 mmap() ,就可以分別在堆和檔案對映段動態分配記憶體。64位元系統的記憶體分佈也類似,只不過記憶體空間要大得多。
記憶體分配與回收
malloc() 是 C 標準庫提供的記憶體分配函數,對應到系統呼叫上,有兩種實現方式,即 brk() 和mmap()。對小塊記憶體(小於128K),C 標準庫使用 brk() 來分配,也就是通過移動堆頂的位置來分配記憶體。這些記憶體釋放後並不會立刻歸還系統,而是被快取起來,這樣就可以重複使用。而大塊記憶體(大於 128K),則直接使用記憶體對映 mmap() 來分配,也就是在檔案對映段找一塊
空閒記憶體分配出去。
這兩種方式,自然各有優缺點。
- brk() 方式的快取,可以減少缺頁異常的發生,提高記憶體存取效率。不過,由於這些記憶體沒有歸還系統,在記憶體工作繁忙時,頻繁的記憶體分配和釋放會造成記憶體碎片。
- mmap() 方式分配的記憶體,會在釋放時直接歸還系統,所以每次 mmap 都會發生缺頁異常。在記憶體工作繁忙時,頻繁的記憶體分配會導致大量的缺頁異常,使內核的管理負擔增大。這也是malloc 只對大塊記憶體使用 mmap 的原因。如果太小的記憶體也使用mmap分配內核的管理負擔會更大。
當這兩種呼叫發生後,其實並沒有真正分配記憶體。這些記憶體,都只在首次存取時才分配,也就是通過缺頁異常進入內核中,再由內核來分配記憶體。
Linux 使用夥伴系統來管理記憶體分配。前面我們提到過,這些記憶體在MMU中以頁爲單位進行管理,夥伴系統也一樣,以頁爲單位來管理記憶體,並且會通過相鄰頁的合併,減少記憶體碎片化(比如brk方式造成的記憶體碎片)
比頁(4KB)還小的記憶體如何分配?
如果爲它們也分配單獨的頁,那就太浪費記憶體了
所以
- 在使用者空間,malloc 通過 brk() 分配的記憶體,在釋放時並不立即歸還系統,而是快取起來重複利用。
- 在內核空間,Linux 則通過 slab 分配器來管理小記憶體。你可以把slab 看成構建在夥伴系統上的一個快取,主要作用就是分配並釋放內核中的小物件。(malloc本身不會使用slab只有內核中使用kmalloc纔回通過slab分配記憶體) 因此需要注意對於內核空間纔會用slab 分配記憶體
對記憶體來說,如果只分配而不釋放,就會造成記憶體漏失,甚至會耗盡系統記憶體。所以,在應用程式用完記憶體後,還需要呼叫 free() 或 unmap() ,來釋放這些不用的記憶體。
記憶體緊張時觸發記憶體回收機制 機製
- 回收快取,比如使用 LRU(Least Recently Used)演算法,回收最近使用最少的記憶體頁面;
- 回收不常存取的記憶體,把不常用的記憶體通過交換分割區直接寫到磁碟中;
Swap 其實就是把一塊磁碟空間當成記憶體來用。它可以把進程暫時不用的數據儲存到磁碟中(這個過程稱爲換出),當進程存取這些記憶體時,再從磁碟讀取這些數據到記憶體中(這個過程稱爲換入)。
Swap 把系統的可用記憶體變大了。不過要注意,通常只在記憶體不足時,纔會發生 Swap 交換。並且由於磁碟讀寫的速度遠比記憶體慢,Swap 會導致嚴重的記憶體效能問題
- 殺死進程,記憶體緊張時系統還會通過 OOM(Out of Memory),直接殺掉佔用大量記憶體的進程
OOM killer是內核的一種保護機制 機製。它監控進程的記憶體使用情況,並且使用 oom_score 爲每個進程的記憶體使用情況進行評分:
- 一個進程消耗的記憶體越大,oom_score 就越大;
- 一個進程執行佔用的 CPU 越多,oom_score 就越小。
這樣,進程的 oom_score 越大,代表消耗的記憶體越多,也就越容易被 OOM 殺死,從而可以更好保護系統。
管理員可以通過 /proc 檔案系統,手動設定進程的 oom_adj ,從而調整進程的 oom_score。oom_adj 的範圍是 [-17, 15],數值越大,表示進程越容易被 OOM 殺死;數值越小,表示進程越不容易被 OOM 殺死,其中 -17 表示禁止 OOM。
echo -16 > /proc/$(pidof watch)/oom_adj
如何檢視記憶體使用情況
free
第一列,total 是總記憶體大小;
第二列,used 是已使用記憶體的大小,包含了共用記憶體;
第三列,free 是未使用記憶體的大小;
第四列,shared 是共用記憶體的大小;
第五列,buff/cache 是快取和緩衝區的大小;
top
主要列含義:
VIRT 是進程虛擬記憶體的大小,只要是進程申請過的記憶體,即便還沒有真正分配實體記憶體,也會計算在內。
RES 是常駐記憶體的大小,也就是進程實際使用的實體記憶體大小,但不包括 Swap 和共用記憶體。
SHR 是共用記憶體的大小,比如與其他進程共同使用的共用記憶體、載入的動態鏈接庫以及程式的程式碼段等。
%MEM 是進程使用實體記憶體佔系統總記憶體的百分比。
第一,虛擬記憶體通常並不會全部分配實體記憶體。
第二,共用記憶體 SHR 並不一定是共用的,比方說,程式的程式碼段、非共用的動態鏈接庫,也都算在 SHR 裡。當然,SHR 也包括了進程間真正共用的記憶體。所以在計算多個進程的記憶體使用時,不要把所有進程的 SHR 直接相加得出結果。
問題:如何統計所有進程的實體記憶體使用量?
grep Pss /proc/[1-9]*/smaps | awk '{total+=$2}; END {printf "%d kB\n", total }'